
- 1Python 学习 ---> 函数、函数式编程、高阶函数、匿名函数、偏函数
- 2git clone 报错过早的文件结束符(EOF)_git clone eof
- 3Spring6入门_使用spring6的话spring-test的maven版本应该是多少
- 4java实现excel导入与导出(总结与实现)_java excel 导出
- 5如何在JMeter中玩懂KAFKA_jmeter kafka
- 63D绘图 WebGl引擎----ThreeJS 3D渲染引擎_webgl 图片转成3d
- 7利用docker-compose 安装 flowable-ui 工作流_docker-compose flowable
- 8基于FPGA的五子棋(论文+源码)_基于fpga的五子棋游戏论文
- 928岁从事功能测试被辞,面试2个月都找不到工作吗?
- 106月13日 植物大战僵尸杂交版 v2.1 Mac版下载 新增商店/背包
原理到实战手摸手带你掌握K近邻算法【机器学习入门必备】_knn算法有三要素,分别为距离度量、k值的选择和分类决策规则。
赞
踩
前言
k近邻法 (k-nearest neighbor, k-NN) 是一种基本分类与回归方法,是数据挖掘技术中原理最简单的算法之一,核心功能是解决有监督的分类问题。
KNN能够快速高效地解决建立在特殊数据集上的预测分类问题,但其不产生模型。
k近邻法的输入为实例的特征向量,对应与特征空间的点;输出为实例的类别,可以取多类。
k近邻法三个基本要素:k 值的选择、距离度量及分类决策规则。

算法过程
1 计算训练样本和测试样本中每个样本点的距离;
2 对上面所有的距离值进行排序;
3 选前k个最小距离的样本;
4 根据这k个样本的标签进行投票,得到最后的分类类别。

距离度量
特征空间中两个实例点的距离是两个实例点相似程度的反映。
在距离类模型,例如KNN中,有多种常见的距离衡量方法。如欧几里得距离、曼哈顿距离、闵科夫斯基距离、切比雪夫距离及余弦距离。其中欧几里得距离为最常见。
- 欧几里得距离(Euclidean Distance)
在欧几里得空间中,两点之间或多点之间的距离表示又称欧几里得度量。

- 曼哈顿距离(Manhattan Distance)
曼哈顿距离,正式意义为城市区块距离,也被称作街道距离,该距离在欧几里得空间的固定直角坐标所形成的线段产生的投影的距离总和。其计算方法相当于是欧式距离的1次方表示形式,其基本计算公式如下:

- 闵科夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义,是对多个距离度量公式的概括性的表述。无论是欧式距离还是曼哈顿距离,都可视为闵可夫斯基距离的一种特例。
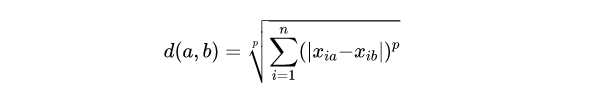
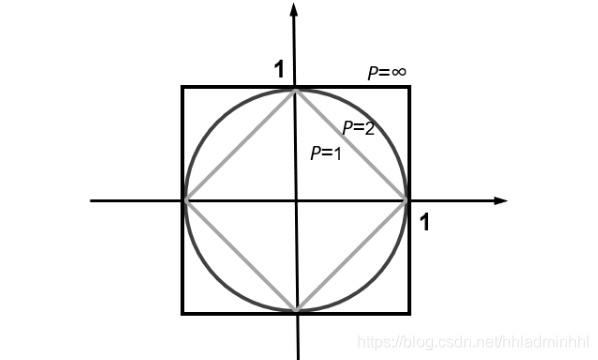
其中p是一个变参数:
- 当p=1时,就是曼哈顿距离;
- 当p=2时,就是欧氏距离;
- 当p→∞时,就是切比雪夫距离。
因此,根据变参数的不同,闵氏距离可以表示某一类 / 种的距离。
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
e.g. 二维样本(身高[单位:cm],体重[单位:kg]), 现有三个样本:a(180,50),b(190,50),c(180,60)。那么a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身高的10cm并不能和体重的10kg划等号。
闵氏距离的缺点:
(1)将各个分量的量纲(scale),也就是"单位"相同的看待了;
(2)未考虑各个分量的分布(期望,方差等)可能是不同的。
- 切比雪夫距离 (Chebyshev Distance)
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(xa,ya)走到格子(xb,yb)最少需要多少步?这个距离就叫切比雪夫距离。
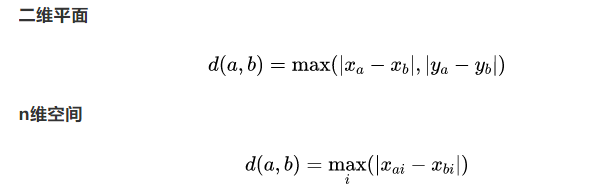
- 余弦距离(Cosine Distance)
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个样本差异的大小。余弦值越接近1, 说明两个向量夹角越接近0度,表明两个向量越相似。几何中,夹角余弦可用来衡量两个向量方向的差异;机器学习中,借用这一概念来衡量样本向量之间的差异。
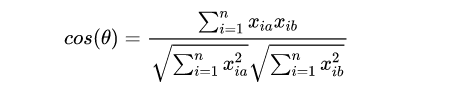
K值选择
k 值的选择会对KNN 算法的结果产生重大影响。
- k 值的减小就意味着整体模型变得复杂,学习器容易受到由于训练数据中的噪声而产生的过分拟合的影响。
- k 值的的增大就意味着整体的模型变得简单。如果k太大,最近邻分类器可能会将测试样例分类错误,因为k个最近邻中可能包含了距离较远的,并非同类的数据点。
在应用中,k 值一般选取一个较小的数值,通常采用交叉验证来选取最优的k 值。
分类决策规则
根据 “少数服从多数,一 点算一票” 的原则进行判断,数量最多标签类别就是x的标签类别。其中涉及到的原理是"越相近越相似",这也是KNN的基本假设。
算法不足
KNN算法作为一种较简单的算法,存在不足之处。
- 没有明显的训练过程,它是 "懒惰学习"的典型代表,它在训练阶段所做的仅仅是将样本保存起来,如果训练集很大,必须使用大量的存储空间,训练时间开销为零。
- KNN必须对每一个测试点来计算到每一个训练数据点的距离, 并且这些距离点涉及到所有的特征,当数据的维度很大,数据量也很大的时候,KNN的计算会成为诅咒。
kd树
由于上述的不足,为了提高KNN搜索的速度,可以利用特殊的数据存储形式来减少计算距离的次数。kd树就是一种以二叉树的形式存储数据的方法。
kd树就是对k维空间的一个划分。构造kd树相当于不断用垂直于坐标轴的超平面将k维空间切分,构成一系列k维超矩阵区域。kd树的每一个节点对应一个超矩阵区域。
代码实现
# 从sklearn.neighbors里导入 KNN分类器的类
from sklearn.neighbors import KNeighborsClassifier
# 通过类实例化一个knn分类器对象
# 类中的具体参数
# KNeighborsClassifier(n_neighbors=5,weights='uniform',algorithm='auto',leaf_size=30,p=2, metric='minkowski',metric_params=None,n_jobs=None,**kwargs,)
knn_clf = KNeighborsClassifier(n_neighbors=k)
# 通过对象调fit()方法, 传入训练集, 训练模型
knn_clf.fit(X_train, y_train)X
# 训练好的模型, 通过其他接口, 传入测试集查看模型效果
knn_clf.score(X_test, y_test)
# 预测结果
knn_clf.predict(X_test)
knn_clf.predict_proba(X_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
实现无监督最近邻KNN学习。它充当了三种不同的最近邻(nearest neighbors)算法的统一接口:BallTree、KDTree和基于sklear. metrics.pairwise例程的暴力算法。
邻居搜索算法的选择是通过关键字’algorithm’来控制的,它必须是 [‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’] 之一。 当默认值’auto’时,算法尝试从训练数据中确定最佳方法。
案例实战
1、鸢尾花
数据:鸢尾花数据集
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib as mpl from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from matplotlib.colors import ListedColormap #导入iris数据 from sklearn.datasets import load_iris iris = load_iris() X=iris.data[:,:2] #只取前两列 y=iris.target X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,random_state=42) #划分数据,random_state固定划分方式 #导入模型 from sklearn.neighbors import KNeighborsClassifier #训练模型 n_neighbors = 5 knn = KNeighborsClassifier(n_neighbors=n_neighbors) knn.fit(X_train, y_train) y_pred = knn.predict(X_test) #查看各项得分 print("y_pred",y_pred) print("y_test",y_test) print("score on train set", knn.score(X_train, y_train)) print("score on test set", knn.score(X_test, y_test)) print("accuracy score", accuracy_score(y_test, y_pred)) # 可视化 # 自定义colormap def colormap(): return mpl.colors.LinearSegmentedColormap.from_list('cmap', ['#FFC0CB','#00BFFF', '#1E90FF'], 256) x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 axes=[x_min, x_max, y_min, y_max] xp=np.linspace(axes[0], axes[1], 500) #均匀500的横坐标 yp=np.linspace(axes[2], axes[3],500) #均匀500个纵坐标 xx, yy=np.meshgrid(xp, yp) #生成500X500网格点 xy=np.c_[xx.ravel(), yy.ravel()] #按行拼接,规范成坐标点的格式 y_pred = knn.predict(xy).reshape(xx.shape) #训练之后平铺 # 可视化方法一 plt.figure(figsize=(15,5),dpi=100) plt.subplot(1,2,1) plt.contourf(xx, yy, y_pred, alpha=0.3, cmap=colormap()) #画三种类型的点 p1=plt.scatter(X[y==0,0], X[y==0, 1], color='blue',marker='^') p2=plt.scatter(X[y==1,0], X[y==1, 1], color='green', marker='o') p3=plt.scatter(X[y==2,0], X[y==2, 1], color='red',marker='*') #设置注释 plt.legend([p1, p2, p3], iris['target_names'], loc='upper right',fontsize='large') #设置标题 plt.title(f"3-Class classification (k = {n_neighbors})", fontdict={'fontsize':15} ) # 可视化方法二 plt.subplot(1,2,2) cmap_light = ListedColormap(['pink', 'cyan', 'cornflowerblue']) cmap_bold = ListedColormap(['darkorange', 'c', 'darkblue']) plt.pcolormesh(xx, yy, y_pred, cmap=cmap_light) # Plot also the training points plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=20) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.title(f"3-Class classification (k = {n_neighbors})" ,fontdict={'fontsize':15}) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
输出结果:
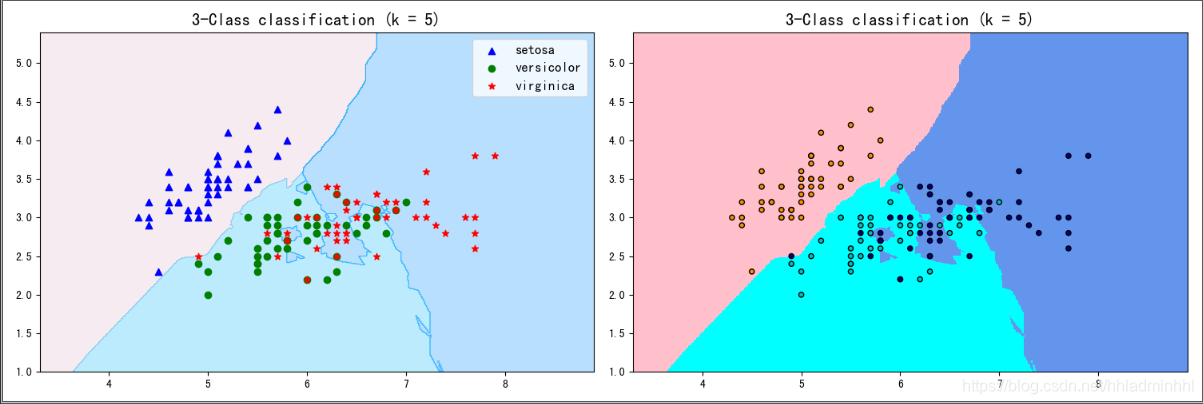
2、乳腺癌
数据:乳腺癌数据集
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html
- 获取数据
# 导入乳腺癌数据集的类及其他包 from sklearn.datasets import load_breast_cancer from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split # 实例化一份乳腺癌数据集对象 breast_cancer= load_breast_cancer() # 查看数据 breast_cancer # 数据的特征, 返回一个二维数组 X = breast_cancer['data'] X = pd.DataFrame(X) name = ['平均半径','平均纹理','平均周长','平均面积','平均光滑度','平均紧凑度','平均凹度','平均凹点','平均对称','平均分形维数','半径误差','纹理误差','周长误差','面积误差','平滑度误差','紧凑度误差','凹度误差','凹点误差','对称误差','分形维数误差','最差半径','最差纹理','最差的边界','最差的区域','最差的平滑度','最差的紧凑性','最差的凹陷','最差的凹点','最差的对称性','最差的分形维数'] X.columns = name # 数据的标签, 返回一个一维数组 y = breast_cancer['target'] # 划分数据,random_state固定划分方式 X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y,random_state=42)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 建立、训练及测试模型
# 实例化一个5个最近邻的knn分类器
knn_clf = KNeighborsClassifier(n_neighbors=5)
# 训练模型
knn_clf.fit(X_train, y_train)
# 测试模型的准确率
knn_clf.score(X_test, y_test)
# 0.9590643274853801
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里的最近邻k, 选取的是5,结果为0.9590643274853801。
下面我们需要思考两个问题:
1、前面提到 k值的大小将会影响模型效果,如何选择合适的k 值?
2、模型得分是否可以进一步其他,受哪些因素影响?
- 数据预处理
我们所用数据是sklearn.datasets 数据集,均是 ‘完美’ 数据,并不需要常规数据预处理(包括缺失值、异常值、重复值等)。
但 KNN是距离类模型,数据的量纲不统一将会严重影响其效果。在模型中,欧式距离的计算公式中存在着特征上的平方和:
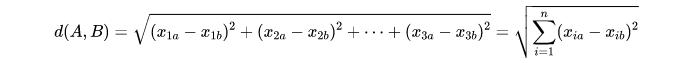
若某个特征取值非常大而导致其掩盖了特征之间的距离对总距离的影响,这样距离模型便不能很好地将不同类别的特征区分开。
因此在使用KNN分类器,则需要先对数据集进行去量纲处理。即是将所有的数据压缩到同一个范围内。
数据的归一化或者标准化,主要目的是消除量纲对距离类模型的影响,并加速梯度下降等算法的迭代速度,使其更快找到最优解。
# 导入归一化类
from sklearn.preprocessing import MinMaxScaler
mms = MinMaxScaler() # 实例化对象
mms.fit(X_train) # 这一步是在学习训练集,生成训练集上的极小值和极差
X_train = mms.transform(X_train) # 用训练集上的极小值和极差归一化训练集
X_test = mms.transform(X_test) # 用训练集上的极小值和极差归一化测试集
- 1
- 2
- 3
- 4
- 5
- 6
归一化前:
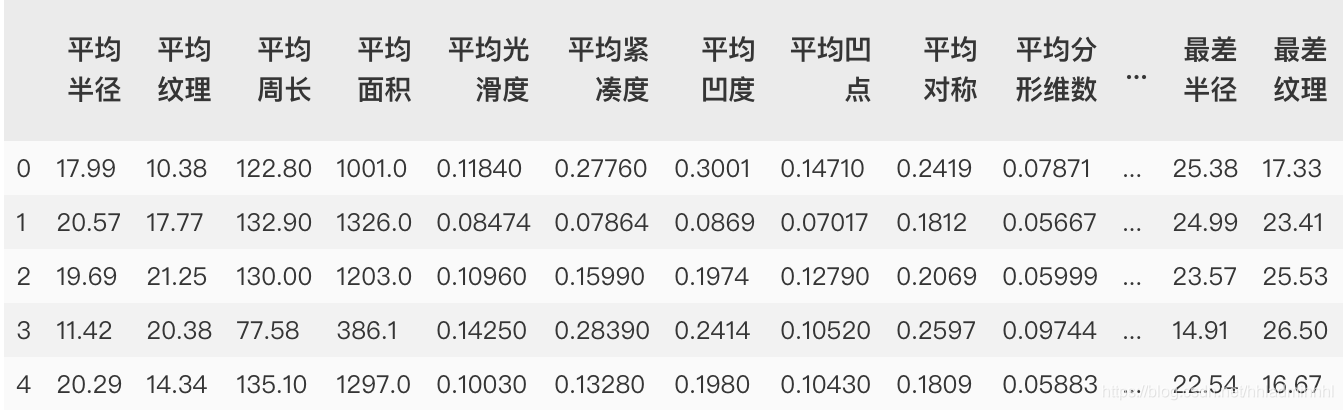
归一化后:

归一化后等数据带入模型训练后得分:0.986013986013986 相比于归一化前模型的得分提高不少。
- 模型调参
K折交叉验证
是最长用交叉验证方法,其将数据划分为n份,依次使用其中一份作为测试集,其他n-1份作为训练集,这样就会出现n个准确率, 我们再对这n个准确率求平均值。如果平均准确率高的, 就说明泛化能力更强。
K折交叉验证对数据的分割方式是按顺序的,因此在使用交叉验证之前需要排查数据的标签本身是否有顺序,若有顺序则需要打乱原有的顺序,或者更换交叉验证方法,像ShuffleSplit就完全不在意数据本身是否是有顺序的。
所有的交叉验证都是在分割训练集和测试集,只不过侧重的方向不同:
- KFold就是按顺序取训练集和测试集。
- ShuffleSplit就侧重于让测试集分布在数据的全方位之内。
- StratifiedKFold则是认为训练数据和测试数据必须在每个标签分类中占有相同的比例。
from sklearn.model_selection import cross_val_score as cvs
L = []
for k in range(1, 21):
knn_clf = KNeighborsClassifier(n_neighbors=k)
result = cvs(knn_clf,X_train, # 使用训练集
y_train,
cv = 5) # 5折交叉验证
result_mean = result.mean()
result_var = result.var()
L.append((k, result_mean, result_var))
score = pd.DataFrame(L)
score.columns = ['k', '平均准确率', '方差']
score
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出结果:
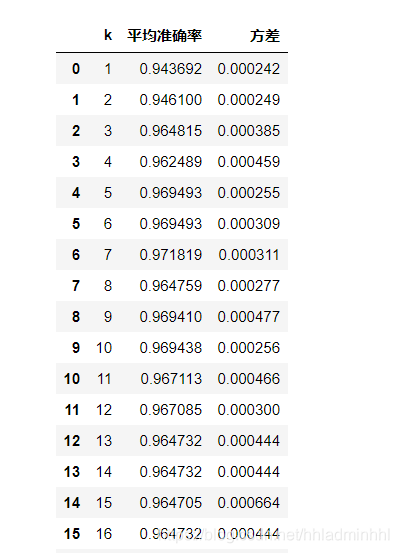
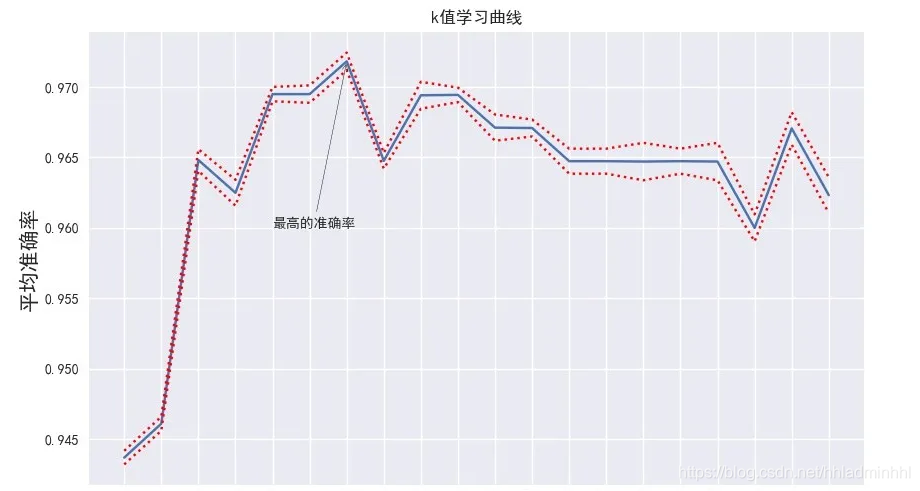
- 画学习曲线
参数学习曲线是一条以不同的参数取值为横坐标,不同参数取值下的模型结果为纵坐标的曲线,并选择模型表现最佳点的参数取值作为这个参数的取值。
import matplotlib.pyplot as plt
plt.style.use('seaborn')
plt.rcParams['font.sans-serif']=['Simhei'] #显示中文
plt.rcParams['axes.unicode_minus']=False #显示负号
plt.figure(figsize=(8, 6), dpi=100)
plt.plot(score.k, score.平均准确率)
# 再画两条偏离均值2倍方差的曲线
plt.plot(score.k, score.平均准确率+2*score.方差, linestyle='**', color='r')
plt.plot(score.k, score.平均准确率-2*score.方差, linestyle='--', color='r')
plt.xticks(score.k)
plt.xlabel('k值', fontsize=20)
plt.ylabel('平均准确率', fontsize=20)
plt.title("k值学习曲线")
# plt.savefig('learning_curve_picture.jpeg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出结果:
- 重要参数
weights {‘uniform’, ‘distance’} or callable, default=’uniform’
KNN分类模型的另一个基本假设:就算是最近邻的K个点,每个点和分类目标点的距离仍然有远近之别,而近的点往往和目标分类点有更大的可能性属于同一类别。
基本的最近邻分类使用统一的权重:分配给查询点的值是从最近邻的简单多数投票中计算出来的。在某些环境下,最好对邻居进行加权,使得越近邻越有利于拟合。
用于决定是否使用距离作为惩罚因子的参数,默认"uniform" 。
“uniform”:表示一点一票
“distance”:表示以每个点到测试点的距离的倒数计算该点的距离所占的权重,使得距离测试点更近的样本点比离测试点更远的样本点具有更大的影响力
关于惩罚因子的选取有很多种方法,最常用的就是根据每个最近邻距离的不同对其作用加权,加权方法为设置的权重,该权重计算公式为:距离的倒数。
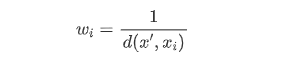
tips:关于模型的优化方法只是在理论上优化会提升模型判别效力,但实际应用过程中最终能否发挥作用,本质上取决于优化方法和实际数据情况的契合程度,如果数据本身存在大量异常值点,则采用距离远近作为惩罚因子则会有较好的效果,反之则不然。
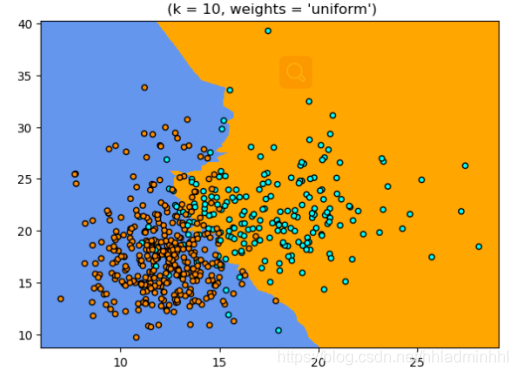
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn import neighbors, datasets n_neighbors = 10 h = .02 breast_cancer= datasets.load_breast_cancer() X = breast_cancer['data'][:, :2] y = breast_cancer['target'] cmap_light = ListedColormap(['orange', 'cornflowerblue']) cmap_bold = ListedColormap([ 'darkblue', 'darkorange']) p1=plt.figure(figsize=(15,5),dpi=100) num = 1 for weights in ['uniform']: ax1=p1.add_subplot(1,2,num) num+=1 clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights) clf.fit(X, y) x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1 y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) Z = clf.predict(np.c_[xx.ravel(), yy.ravel()]) Z = Z.reshape(xx.shape) plt.pcolormesh(xx, yy, Z, cmap=cmap_light) plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=20) plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) plt.title(" (k = %i, weights = '%s')"% (n_neighbors, weights)) plt.show() plt.savefig('weight.tiff')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
输出结果:
至此,恭喜您!您已基本掌握机器学习入门经典算法中的KNN (K-Nearest Neighbour algorithm)算法了。
好了,今天就到这里,明天我们继续努力!

若本篇内容对您有所帮助,请三连点赞,关注,收藏支持下。创作不易,白嫖不好,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
Dragon少年 | 文
如果本篇博客有任何错误,请批评指教,不胜感激 !

