
- 1变配电站配电监控解决方案--变电站综合自动化系统
- 2CAS基本原理和应用_cas 应用管理
- 3企业数字化转型到底是什么?_数智化转型五部曲
- 4JAVA权重算法(如Dubbo的负载均衡权重)_java权重分配算法
- 5Android 滑动菜单(DrawerLayout + NavigationView )_android滑动菜单
- 6PSQL容器带脚本初始化_postgresql基于容器创建表的初始化脚本
- 7eclipse无法启动提示 java.lang.NoClassDefFoundError: org/w3c/dom/stylesheets/StyleSheet问题
- 8VSCode SSH免密登录失败原因 原因分析及解决_vscode设置密钥登陆没有效果
- 9【摘要】抽取式摘要:TextRank和BertSum。
- 10通过包名,直接精确启动一个三方Activity_通过包名启动应用startactivity
Python批量识别图片文字(数字识别模式)大幅度提高数字识别准确率_python读取图片中的文字 数字
赞
踩
目录
二、使用pytesseract库识别图片中数据,并将数据存入txt文件
一、使用beautiful soup库爬取网页图片
该网站中有需要的数据,但是是以图片形式存在。
这样就给我们爬取数据造成了一些困扰,没有办法之间从网站上获取数据,只能先把这些图片爬取下来,之后再进行处理。
按F12,进入开发者模式,在html源码上找到图片所在的位置:
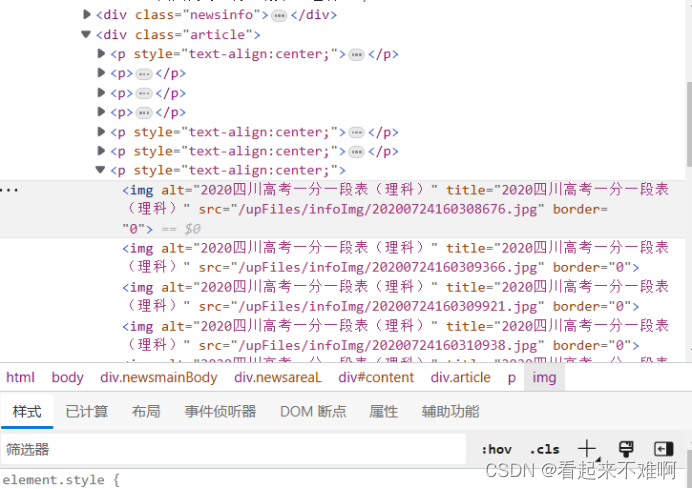
可以看出图片位于“article”类下的第7个p块下,并且观察对应的每张图片的src,可以看出每张图片仅最后的数字不同,所以我们可以进行网址的拼接,进而调用get方法下载这些图片
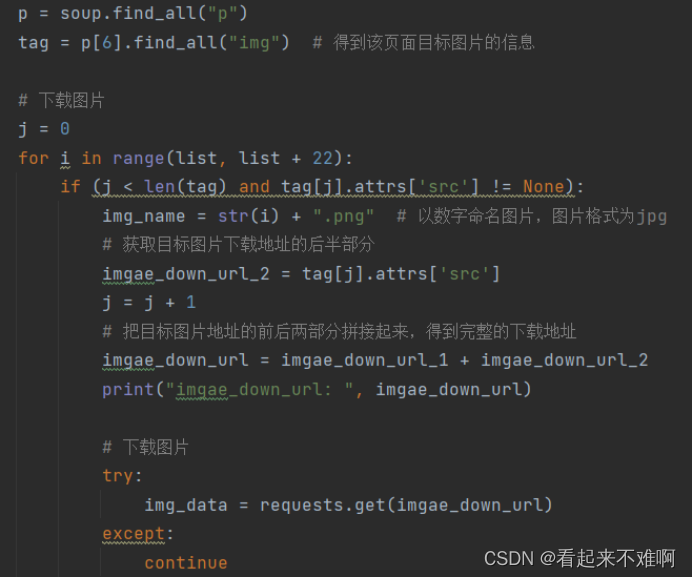
通过beautiful soup库中findall()方法进行定位图片,并下载和重命名所有图片
注意:p中存储的是所有html中p块信息,而我们需要的图片位于第7个p块下,所以p[6]中是我们需要的信息
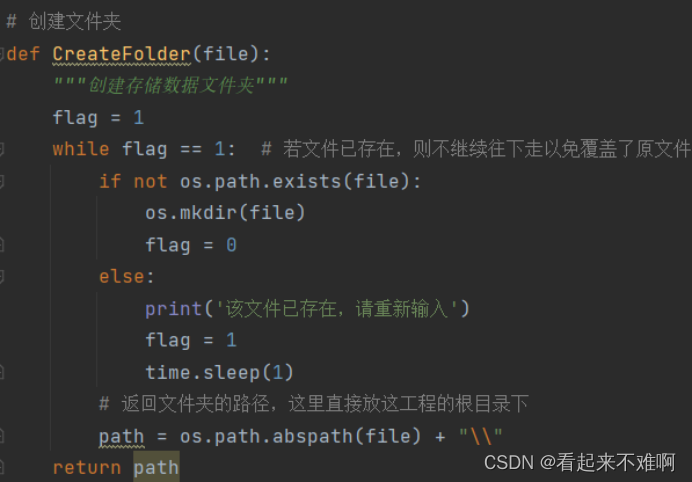
将下载的图片保存在当前目录新创建的文件夹下

爬取过程的源代码如下:
- import os
- import re
- import time
- import requests
- from bs4 import BeautifulSoup
-
- # 手动写入目标套图的首页地址
- download_url = "https://www.dxsbb.com/news/85155.html"
-
- # 手动写入网站中图片的个数
- num = 23
-
- # 创建一个文件夹用来保存图片
- file_name = "2020年四川高考理科一分一段表"
-
- # 目标图片下载地址的前半部分(固定不变那部分,后半段是变化的,需要解析网页得到)
- imgae_down_url_1 = "https://www.dxsbb.com"
-
-
- # 创建文件夹
- def CreateFolder(file):
- """创建存储数据文件夹"""
- flag = 1
- while flag == 1: # 若文件已存在,则不继续往下走以免覆盖了原文件
- if not os.path.exists(file):
- os.mkdir(file)
- flag = 0
- else:
- print('该文件已存在,请重新输入')
- flag = 1
- time.sleep(1)
- # 返回文件夹的路径,这里直接放这工程的根目录下
- path = os.path.abspath(file) + "\\"
- return path
-
-
- # 下载图片
- def DownloadPicture(download_url, list, path):
- # 访问目标网址
- r = requests.get(url=download_url, timeout=20)
- r.encoding = r.apparent_encoding
- soup = BeautifulSoup(r.text, "html.parser")
-
- # 解析网址,提取目标图片相关信息,注:这里的解析方法是不固定的,可以根据实际的情况灵活使用
- p = soup.find_all("p") #p中是所有p块的信息
- tag = p[6].find_all("img") # 得到该页面目标图片的信息
-
- # 下载图片
- j = 0
- for i in range(num):
- if (j < len(tag) and tag[j].attrs['src'] != None):
- img_name = str(i) + ".png" # 以数字命名图片,图片格式为jpg
- # 获取目标图片下载地址的后半部分
- imgae_down_url_2 = tag[j].attrs['src']
- j = j + 1
- # 把目标图片地址的前后两部分拼接起来,得到完整的下载地址
- imgae_down_url = imgae_down_url_1 + imgae_down_url_2
- print("imgae_down_url: ", imgae_down_url)
-
- # 下载图片
- try:
- img_data = requests.get(imgae_down_url)
- except:
- continue
- # 保存图片
- img_path = path + img_name
- with open(img_path, 'wb') as fp:
- fp.write(img_data.content)
- print(img_name, " ******下载完成!")
-
-
- # 主函数
- if __name__ == "__main__":
- # 创建保存数据的文件夹
- path = CreateFolder(file_name)
- print("创建文件夹成功: ", path)
- page_url = download_url # 要爬取的网页地址
-
- # 下载图片
- DownloadPicture(page_url, num, path) # 注:这个网站每一页最多是22张图片,每张图片我都用数字命名
-
- print("全部下载完成!", "共" + str(len(os.listdir(path))) + "张图片")

二、使用pytesseract库识别图片中数据,并将数据存入txt文件
有了图片之后就要对图片上的数据进行识别,pytesseract库是一个封装性较好的库,安装之后就可以调用该库进行字符识别。
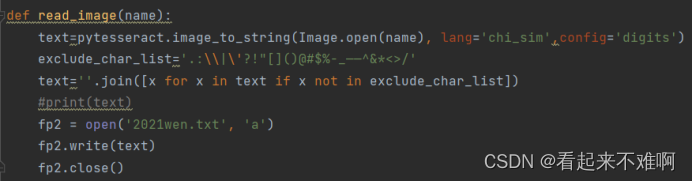
调用pytesseract库进行图片中的数据识别(一开始识别精度并不高,查了一下原因发现默认的识别方法是识别文字的,而本次任务是识别数据,其实并不是很适用。所以我搜索了一下pytesseract库使用方法,发现确实可以使用“只识别数字”模式,这种模式识别的精确度果然提高了很多)
但是识别出的结果中不仅有数字,由于图片上有水印,所以结果中还有很多标点符号和乱码,需要过滤掉这些东西。所以我建立了一个停用词列表,过滤掉这些乱码和标点符号,并将过滤后的数据写入txt文件
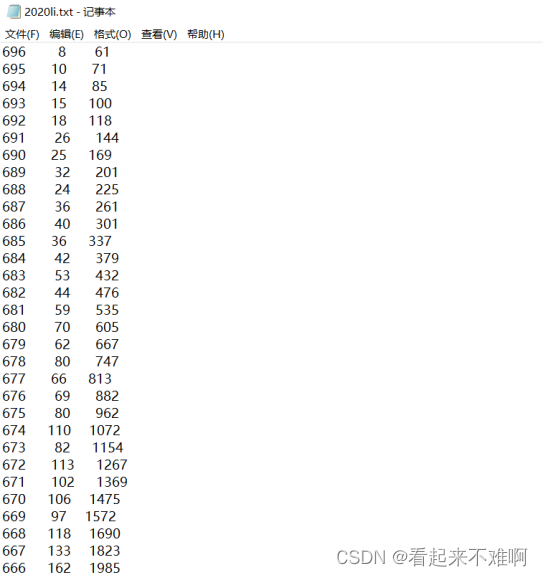
识别后并写入txt文件效果:
图片识别代码如下:
- from PIL import Image
- import pytesseract
- import os
-
-
- def read_image(name):
-
- text=pytesseract.image_to_string(Image.open(name), lang='chi_sim',config=r'-c tessedit_char_whitelist=0123456789 --psm 6')
- exclude_char_list='.:\\|\'?!"[]()@#$%^&*<>/'
- text=''.join([x for x in text if x not in exclude_char_list])
- fp2 = open('2020li.txt', 'a')
-
- fp2.write(text)
- fp2.close()
-
-
- def main():
- path = "./"
- for path, dir, file in os.walk(path):
- break
- pic = []
- for i in file:
- if (".png" in i):
- pic.append(i)
- for j in pic:
- read_image(j)
-
-
- if __name__ == '__main__':
- main()
三、用pandas库实现txt文件到csv文件的转换
最后一步,将txt文件转换成csv文件,前提是数据和数据之间有空格,并且格式正确
(对于识别出的这些数据,我还是进行人工复查了一遍,发现识别的准确率在90%左右,出现的一些小错误要手动修改一下)

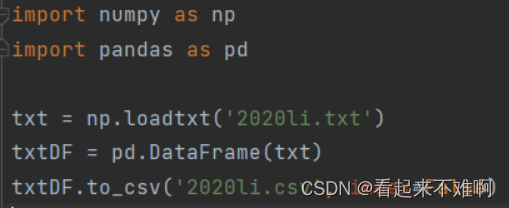
txt数据写入csv文件代码如下:
- import numpy as np
- import pandas as pd
-
- txt = np.loadtxt('2020li.txt')
- txtDF = pd.DataFrame(txt)
- txtDF.to_csv('2020li.csv', index=False)

