
- 1奇偶校验位学习理解
- 2【网络编程】TCP流套接字编程(TCP实现回显服务器)
- 3深入解析Hadoop生态核心组件:HDFS、MapReduce和YARN
- 4数据结构——根据后序遍历结果和中序遍历结果画出二叉树_知道二叉树的中序和后序怎么画出该二叉树
- 5Java代码导出数据库百万数据生成sql脚本_java实现列表选中数据导出sql脚本
- 6YOLOv5模型改进策略源码示例_yolov5源码改进策略
- 7Zero-Shot跨语态抽取式文摘_中英文混合的文本摘要抽取
- 8求数据绝对值的verilog_systemverilog 绝对值
- 9自适应网站页面实现_(function (win, doc) { var resize = 'orientationch
- 10【日常】Transformer要点记录及实现demo(PyTorch与Tensorflow)_transformer pytorch demo
本地化部署Fastgpt+One-API+ChatGLM3-6b知识库_fastgpt本地部署接入oneapi 知识库_one-api 配置 chatgpt
赞
踩
) logger.debug(f"==== request ====\n{gen_params}") if request.stream: # Use the stream mode to read the first few characters, if it is not a function call, direct stram output predict_stream_generator = predict_stream(request.model, gen_params) output = next(predict_stream_generator) if not contains_custom_function(output): return EventSourceResponse(predict_stream_generator, media_type="text/event-stream") # Obtain the result directly at one time and determine whether tools needs to be called. logger.debug(f"First result output:\n{output}") function_call = None if output and request.functions: try: function_call = process_response(output, use_tool=True) except: logger.warning("Failed to parse tool call") # CallFunction if isinstance(function_call, dict): function_call = FunctionCallResponse(**function_call) """ In this demo, we did not register any tools. You can use the tools that have been implemented in our `tool_using` and implement your own streaming tool implementation here. Similar to the following method: function_args = json.loads(function_call.arguments) tool_response = dispatch_tool(tool_name: str, tool_params: dict) """ tool_response = "" if not gen_params.get("messages"): gen_params["messages"] = [] gen_params["messages"].append(ChatMessage( role="assistant", content=output, )) gen_params["messages"].append(ChatMessage( role="function", name=function_call.name, content=tool_response, )) # Streaming output of results after function calls generate = predict(request.model, gen_params) return EventSourceResponse(generate, media_type="text/event-stream") else: # Handled to avoid exceptions in the above parsing function process. generate = parse_output_text(request.model, output) return EventSourceResponse(generate, media_type="text/event-stream") # Here is the handling of stream = False response = generate_chatglm3(model, tokenizer, gen_params) # Remove the first newline character if response["text"].startswith("\n"): response["text"] = response["text"][1:] response["text"] = response["text"].strip() usage = UsageInfo() function_call, finish_reason = None, "stop" if request.functions: try: function_call = process_response(response["text"], use_tool=True) except: logger.warning("Failed to parse tool call, maybe the response is not a tool call or have been answered.") if isinstance(function_call, dict): finish_reason = "function_call" function_call = FunctionCallResponse(**function_call) message = ChatMessage( role="assistant", content=response["text"], function_call=function_call if isinstance(function_call, FunctionCallResponse) else None, ) logger.debug(f"==== message ====\n{message}") choice_data = ChatCompletionResponseChoice( index=0, message=message, finish_reason=finish_reason, ) task_usage = UsageInfo.model_validate(response["usage"]) for usage_key, usage_value in task_usage.model_dump().items(): setattr(usage, usage_key, getattr(usage, usage_key) + usage_value) return ChatCompletionResponse(model=request.model, choices=[choice_data], object="chat.completion", usage=usage)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
async def predict(model_id: str, params: dict):
global model, tokenizer
choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(role="assistant"), finish_reason=None ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) previous_text = "" for new_response in generate_stream_chatglm3(model, tokenizer, params): decoded_unicode = new_response["text"] delta_text = decoded_unicode[len(previous_text):] previous_text = decoded_unicode finish_reason = new_response["finish_reason"] if len(delta_text) == 0 and finish_reason != "function_call": continue function_call = None if finish_reason == "function_call": try: function_call = process_response(decoded_unicode, use_tool=True) except: logger.warning( "Failed to parse tool call, maybe the response is not a tool call or have been answered.") if isinstance(function_call, dict): function_call = FunctionCallResponse(**function_call) delta = DeltaMessage( content=delta_text, role="assistant", function_call=function_call if isinstance(function_call, FunctionCallResponse) else None, ) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=delta, finish_reason=finish_reason ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(), finish_reason="stop" ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) yield '[DONE]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
def predict_stream(model_id, gen_params):
“”"
The function call is compatible with stream mode output.
The first seven characters are determined. If not a function call, the stream output is directly generated. Otherwise, the complete character content of the function call is returned. :param model_id: :param gen_params: :return: """ output = "" is_function_call = False has_send_first_chunk = False for new_response in generate_stream_chatglm3(model, tokenizer, gen_params): decoded_unicode = new_response["text"] delta_text = decoded_unicode[len(output):] output = decoded_unicode # When it is not a function call and the character length is> 7, # try to judge whether it is a function call according to the special function prefix if not is_function_call and len(output) > 7: # Determine whether a function is called is_function_call = contains_custom_function(output) if is_function_call: continue # Non-function call, direct stream output finish_reason = new_response["finish_reason"] # Send an empty string first to avoid truncation by subsequent next() operations. if not has_send_first_chunk: message = DeltaMessage( content="", role="assistant", function_call=None, ) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=message, finish_reason=finish_reason ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) send_msg = delta_text if has_send_first_chunk else output has_send_first_chunk = True message = DeltaMessage( content=send_msg, role="assistant", function_call=None, ) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=message, finish_reason=finish_reason ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) if is_function_call: yield output else: yield '[DONE]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
async def parse_output_text(model_id: str, value: str):
“”"
Directly output the text content of value
:param model_id: :param value: :return: """ choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(role="assistant", content=value), finish_reason=None ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) choice_data = ChatCompletionResponseStreamChoice( index=0, delta=DeltaMessage(), finish_reason="stop" ) chunk = ChatCompletionResponse(model=model_id, choices=[choice_data], object="chat.completion.chunk") yield "{}".format(chunk.model_dump_json(exclude_unset=True)) yield '[DONE]'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
def contains_custom_function(value: str) -> bool:
“”"
Determine whether ‘function_call’ according to a special function prefix.
For example, the functions defined in "tool_using/tool_register.py" are all "get_xxx" and start with "get_"
[Note] This is not a rigorous judgment method, only for reference.
:param value:
:return:
"""
return value and 'get_' in value
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
if name == “main”:
tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True) model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True) if torch.cuda.is_available(): total_vram_in_gb = get_device_properties(0).total_memory / 1073741824 print(f'\033[32m显存大小: {total_vram_in_gb:.2f} GB\033[0m') with torch.cuda.device(f'cuda:{0}'): torch.cuda.empty_cache() torch.cuda.ipc_collect() if total_vram_in_gb > 13: model = model.half().cuda() print(f'\033[32m使用显卡fp16精度运行\033[0m') elif total_vram_in_gb > 10: model = model.half().quantize(8).cuda() print(f'\033[32m使用显卡int8量化运行\033[0m') elif total_vram_in_gb > 4.5: model = model.half().quantize(4).cuda() print(f'\033[32m使用显卡int4量化运行\033[0m') else: model = model.float() print('\033[32m使用cpu运行\033[0m') else: model = model.float() print('\033[32m使用cpu运行\033[0m') model = model.eval()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
#bilibili@十字鱼 https://space.bilibili.com/893892 感谢参考——秋葉aaaki、大江户战士
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
- 1
## 2.部署One-Api
用于调用各种模型的节点,技术文档建议docker部署,可以用ubuntu20.04,windows程序里开启虚拟化。这里用VirtualBox,开启VT-x/AMD-V,需要在BIOS开启虚拟化功能,有些主板在安全设置里。网络端口转发添加3000、13000等,看需要增加规则。
打开ubuntu20,更新software可能需要一些时间,安装Code,Terminator用于之后的操作。首先解决权限问题。docker及docker守护程序的检查会涉及到权限问题。可将用户名添加到docker组,建议使用管理员权限操作。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
sudo usermod -aG docker 用户名
打开code,新建terminal,拉取one-api的镜像,端口为13000
- 1
- 2
- 3
- 4
- 5
docker run --name one-api -d --restart always -p 13000:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api
进入localhost:13000,登录root,密码123456 chatglm3的Base URL:http//localhost:8000 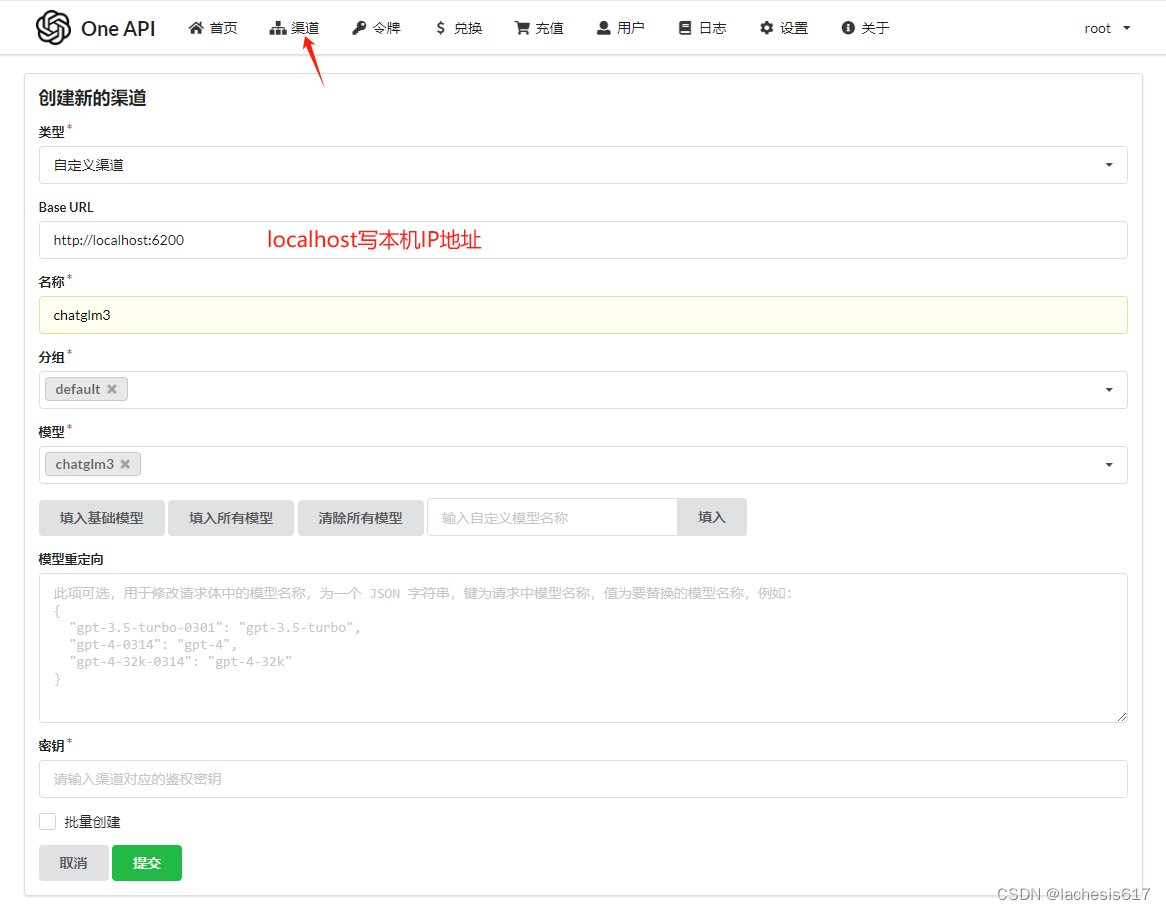 继续添加m3e渠道,Base URL:http://localhost:6200 添加新令牌,提交。复制箭头下第一个到txt黏贴,例如:[https://chat.oneapi.pro/#/?settings={"key":"sk-fAAfFClsyVXxvAgp57Ab758260124a958aF00a2d49CcB625","url":"http://localhost:3000"}]( ) 用docker部署m3e模型,默认用CPU运行: docker run -d -p 6200:6008 --name=m3e-large-api [registry.cn-hangzhou.aliyuncs.com/fastgpt\_docker/m3e-large-api:latest]( ) 使用GPU运行: docker run -d -p 6200:6008 --gpus all --name=m3e-large-api [registry.cn-hangzhou.aliyuncs.com/fastgpt\_docker/m3e-large-api:latest]( ) 原镜像: docker run -d -p 6200:6008 --name=m3e-large-api stawky/m3e-large-api:latest 成功运行后测试,会反馈一组嵌入向量数据,说明成功部署
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
curl --location --request POST ‘http://localhost:6200/v1/embeddings’
–header ‘Authorization: Bearer sk-aaabbbcccdddeeefffggghhhiiijjjkkk’
–header ‘Content-Type: application/json’
–data-raw ‘{
“model”: “m3e”,
“input”: [“laf是什么”]
}’
## 3.部署FastGPT
FastGPT也是Linux部署,这里就用Ubuntu20,打开Code,新建Terminal
下载docker-compose文件:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
下载config文件:
- 1
- 2
- 3
- 4
- 5
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
拉取镜像:docker-compose pull
在后台运行容器:docker-compose up -d
FastGPT 4.6.8后mango副本集需要手动初始化操作
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
查看 mongo 容器是否正常运行
docker ps
进入容器
docker exec -it mongo bash
连接数据库
mongo -u myname -p mypassword --authenticationDatabase admin
初始化副本集。如果需要外网访问,mongo:27017 可以改成 ip:27017。但是需要同时修改 FastGPT 连接的参数(MONGODB_URI=mongodb://myname:mypassword@mongo:27017/fastgpt?authSource=admin => MONGODB_URI=mongodb://myname:mypassword@ip:27017/fastgpt?authSource=admin)
rs.initiate({
_id: “rs0”,
members: [
{ _id: 0, host: “mongo:27017” }
]
})
检查状态。如果提示 rs0 状态,则代表运行成功
rs.status()
docker-compose文件修改OPENAI\_BASE\_URL:http://localhost:13000/v1
连接到One-API的端口,localhost改为本地地址
docker-compose文件修改CHAT\_API\_KEY:填入从OneAPI令牌复制的key
config文件修改,直接复制
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
{
“systemEnv”: {
“openapiPrefix”: “fastgpt”,
“vectorMaxProcess”: 15,
“qaMaxProcess”: 15,
“pgHNSWEfSearch”: 100
},
“llmModels”: [
{
“model”: “chatglm3”,
“name”: “chatglm3”,
“maxContext”: 4000,
“maxResponse”: 4000,
“quoteMaxToken”: 2000,
“maxTemperature”: 1,
“vision”: false,
“defaultSystemChatPrompt”: “”
},
{
“model”: “gpt-3.5-turbo-1106”,
“name”: “gpt-3.5-turbo”,
“maxContext”: 16000,
“maxResponse”: 4000,
“quoteMaxToken”: 13000,
“maxTemperature”: 1.2,
“inputPrice”: 0,
“outputPrice”: 0,
“censor”: false,
“vision”: false,
“datasetProcess”: false,
“toolChoice”: true,
“functionCall”: false,
“customCQPrompt”: “”,
“customExtractPrompt”: “”,
“defaultSystemChatPrompt”: “”,
“defaultConfig”:{}
},
{
“model”: “gpt-3.5-turbo-16k”,
“name”: “gpt-3.5-turbo-16k”,
“maxContext”: 16000,
“maxResponse”: 16000,
“quoteMaxToken”: 13000,
“maxTemperature”: 1.2,
“inputPrice”: 0,
“outputPrice”: 0,
“censor”: false,
“vision”: false,
“datasetProcess”: true,
“toolChoice”: true,
“functionCall”: false,
“customCQPrompt”: “”,
“customExtractPrompt”: “”,
“defaultSystemChatPrompt”: “”,
“defaultConfig”:{}
},
{
“model”: “gpt-4-0125-preview”,
“name”: “gpt-4-turbo”,
“maxContext”: 125000,
“maxResponse”: 4000,
“quoteMaxToken”: 100000,
“maxTemperature”: 1.2,
“inputPrice”: 0,
“outputPrice”: 0,
“censor”: false,
“vision”: false,
“datasetProcess”: false,
“toolChoice”: true,
“functionCall”: false,
“customCQPrompt”: “”,
“customExtractPrompt”: “”,
“defaultSystemChatPrompt”: “”,
“defaultConfig”:{}
},
{
“model”: “gpt-4-vision-preview”,
“name”: “gpt-4-vision”,
“maxContext”: 128000,
“maxResponse”: 4000,
“quoteMaxToken”: 100000,
“maxTemperature”: 1.2,
“inputPrice”: 0,
“outputPrice”: 0,
“censor”: false,
“vision”: false,
“datasetProcess”: false,
“toolChoice”: true,
“functionCall”: false,
“customCQPrompt”: “”,
“customExtractPrompt”: “”,
“defaultSystemChatPrompt”: “”,
“defaultConfig”:{}
}
],
“vectorModels”: [
{
“model”: “m3e”,
“name”: “m3e”,
“price”: 0.1,
“defaultToken”: 500,
“maxToken”: 1800
},
{
“model”: “text-embedding-ada-002”,
“name”: “Embedding-2”,
“inputPrice”: 0,
“outputPrice”: 0,
“defaultToken”: 700,
“maxToken”: 3000,
“weight”: 100,
“defaultConfig”:{}
}
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Linux运维工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Linux运维知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)

最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新*
如果你觉得这些内容对你有帮助,可以添加VX:vip1024b (备注Linux运维获取)
[外链图片转存中…(img-dg3i0mrV-1713074920950)]
最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
[外链图片转存中…(img-azlmyh0a-1713074920950)]
给大家整理的电子书资料:
[外链图片转存中…(img-Nmbs15Ml-1713074920951)]
如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-TQQpx88Q-1713074920951)]


