
- 1openai接口调用-如何接入openai获取 api key_获取 openai key
- 2嵌入式软件开发工程师就业发展前景怎么样?
- 3禁用el-tabs组件自带的键盘切换功能_element-plus 禁止键盘上下左右
- 4机器视觉三维点云分析系统3DPCAgent_3d点云数据测量系统架构
- 5ggplot 图像的保存_error in usemethod("grid.draw") : no applicable me
- 6120款超浪漫❤HTML5七夕情人节表白网页源码❤ HTML+CSS+JavaScript_浪漫网页
- 7Pytorch下查看各层名字及根据layers的name冻结层进行finetune训练;_model = net().cuda() for name, param in model.name
- 8《Python从入门到实践》外星人入侵学习笔记_python外星人入侵 求助 不按play键 一直处于活动状态
- 9Dump分析模式1: Multiple Exceptions(多线程异常)_multipe exceptions
- 10PyQtChart进行柱状图、饼图的基本设置_pyqt5 炫酷饼状图
干货! CVPR:基于VDB的高效神经辐射渲染场
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者介绍
严 涵
上海交通大学2019级人工智能专业本科生,研究兴趣主要是与NeRF相关的三维重建算法。

报告题目
基于VDB高效神经辐射渲染场
内容简介
01
NeRF
NeRF的提出起初主要是为了解决新视⻆生成的任务,根据一些在不同视⻆下拍出的照片,希望能够获得未⻅过的视⻆下的图像。NeRF提出用隐函数来建模场景,即MLP,输入一个空间点的坐标和视⻆方向,可以输出这个点的密度和对应的颜色,通过体渲染技术对一条射线上的颜色进行加权积分,得到对应的像素值,从而建立3D到2D的关系,实现仅通过2D图像便可以监督3D场景的生成。使用MLP来连续的建模场景,相比于传统的点云或者体素等方法,渲染的分辨率不受限,并且存储占用小。
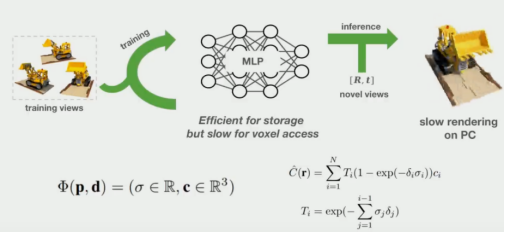
02
Limitation
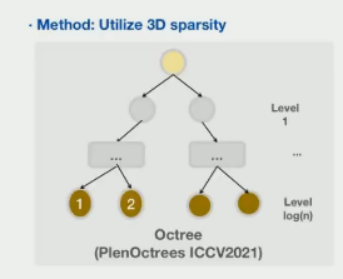
但是基于MLP的方法也存在一些局限性,比如会导致NeRF的训练和渲染速度较慢。主要的原因在于渲染一个像素值对应了一条射线,同时对应于要渲染射线上的上百个采样点,即要访问神经网络上百次。这种昂贵的时间成本导致了NeRF的应用受到限制,所以很多工作都开始探索NeRF加速的方法。一类方法利用了场景的稀疏性,比如在真实世界的场景中很大一部分都是空气,而位于空气中的采样点实际上不需要进行神经网络访问。于是,研究者们将有意义的场景信息预先存储在稀疏的数据结构中,比如下图工作中采用了八叉树,只将有意义的点的数据保存在树的叶子节点上,从而实现高效的存储和渲染,但是这种方法往往需要先训练一个NeRF,再将NeRF转化为这些稀疏数据结构,因此训练效率不够理想。
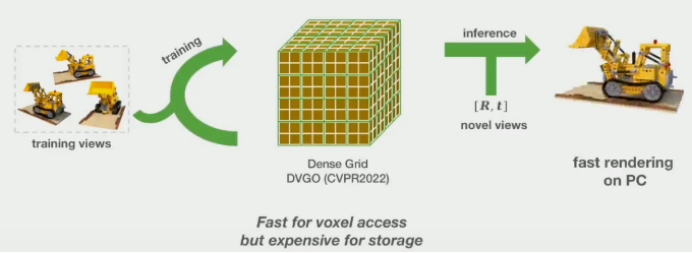
为了加速训练,人们采用3D网格来保存信息,比如DVGO,直接在Dense Grid上学习场景信息,这种方式可以将耗时的神经网络访问变为快速的内存访问,从而实现快速的训练和渲染。但是,Dense Grid的缺点是空间占用太大,并且随分辨率呈立方级的增⻓,因此很难将其应用于移动设备中。
由于算力资源等限制,目前,对于在移动设备端运行NeRF的问题仍然没有很好的解决方法。MobileNeRF通过将NeRF表示为一组有纹理的多边形,使得可以直接应用于传统的渲染管道,从而实现在移动设备端的实时渲染。但是,它的训练过程仍然很慢,并且由于是假设为mesh的表征,无法处理透明物体。

03
Pipline
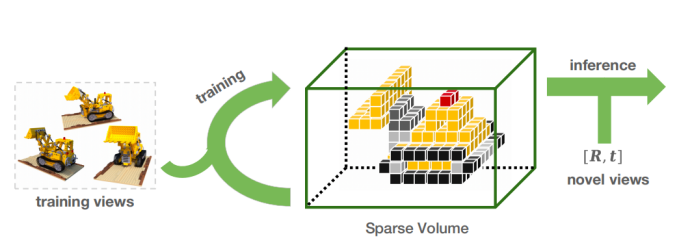
所以,我们就提出了基于VDB的高效数据表征,通过设计一个训练策略,直接在VDB数据结构上学习场景信息,不仅可以加速训练和渲染,而且由于其具有稀疏性的良好性能,存储占用不大。此外,因为VDB是在影视界经过验证的成熟数据结构,拥有丰富的生态,能够在手机端高效运行。
04
VDB
我们采用VDB数据结构主要是因为它具有两个优势,它既有Dense Grid的灵活性,又有稀疏数据的存储高效性。对于使用者来说,它可以完全被看作一个Dense Grid,输入任意的坐标,它可以快速地返回对应值甚至邻居值。
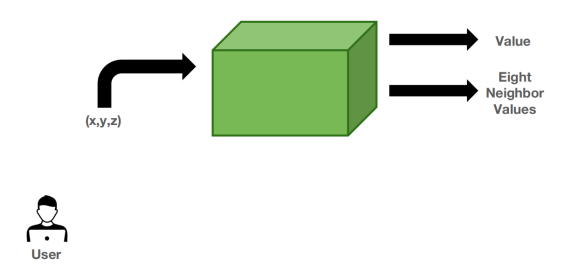
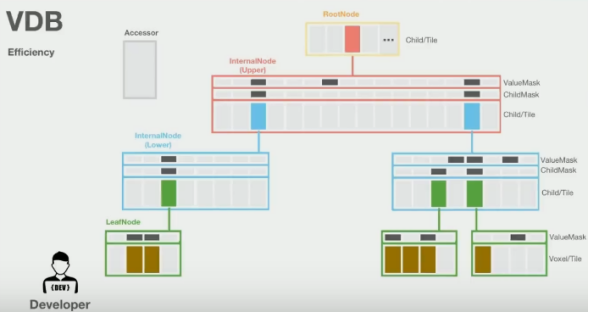
而对于开发者来说,它实际上是一个4层的B+树,简单来说,有两个概念,一个是值,一个是状态。值就相当于我们所需要的数据,它只存储在叶子结点上,比如下图中的棕色部分;状态类似于Mask,反映这个结点的值是否是感兴趣的,在一定程度上反映了稀疏性。因为它是固定的四层树,所以对叶子结点的访问很快,此外,为了支持快速的邻居访问,它设计了缓存机制,即图中的accessor,它的容量和树的深度相同,它会缓存单次搜索中所有被访问的节点,并且在下一次访问时,会先自底向上地检查其中的节点,对于邻居节点的访问,往往在第一次检查时便命中,于是节省了从根节点重新搜索的时间。这个特性也意味着它非常适合执行三线性插值和ray marching等算法。
05
PlenVDB
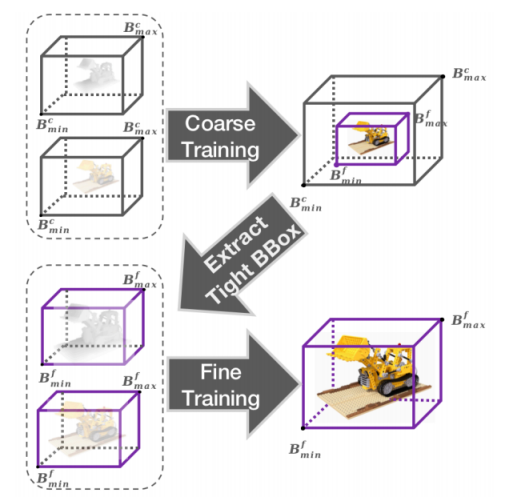
基于上述优势,我们以DVGO作为baseline,将它的Dense Grid改为VDB。总体来讲,即用两个VDB分别存储密度和颜色,通过coarse-to-fine的训练策略来学习精细的场景信息。
具体来说,一方面,我们设计了三类VDB,分别储存数据,梯度和优化器参数,来支持直接在VDB上优化场景,得益于VDB在随机访问和三线性插值上的优势,可以实现训练过程的加速。
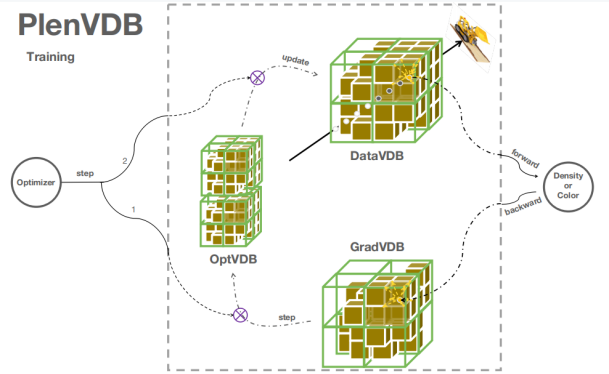
另一方面,基于Cuda编程,我们将DVGO的渲染方法改为两次ray marching算法,第一次访问存储密度的VDB,来筛选出包含场景信息的有效点,第二次访问存储颜色的VDB,获得对应的颜色特征向量,最后通过轻量的MLP得到最终的像素值,以此来加速渲染。
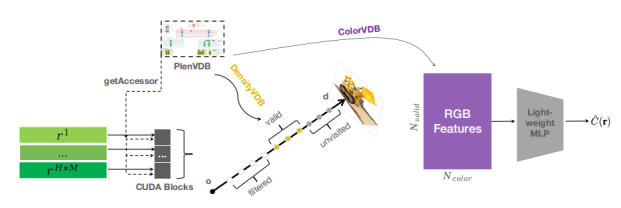
此外,我们进一步压缩,将两个VDB合并,用一个VDB存储索引值来指向对应的密度和颜色,从而减少拓扑上的冗余,以实现高效的存储。

06
Result
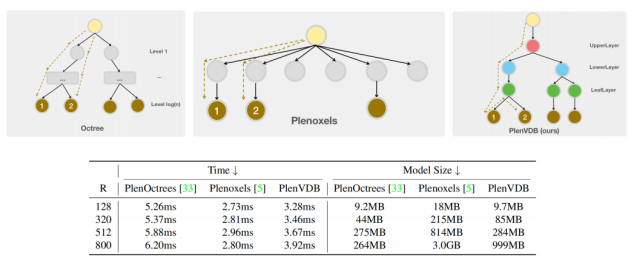
在实验部分,我们首先做了不同数据结构的对比,分别是PlenOctrees的八叉树、Plenoxels的近似于Dense Grid的表示方式,和我们的基于VDB的表示。虚线反映了对邻居节点访问时的搜索路径,由于accessor的存在,VDB可以免于从根结点重新搜索的冗余。对于不同分辨率的场景,我们用ray marching的方式在一条射线上通过三线性插值来访问800个点并计算耗时。为了公平起⻅,我们首先训练好一个Plenoxels的模型,然后将他转化为octree和VDB的形式。实验结果显示,VDB在时间和存储效率上都进行了平衡。
下图是本文方法和其他方法在训练速度上的对比,可以看出我们的方法相比Nerf有很大提升,仍然在第一梯队。

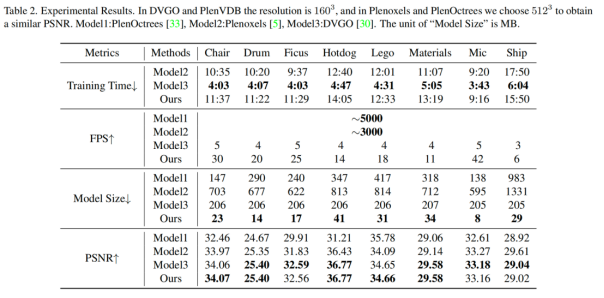
下图反映了我们的方法与不同模型在训练时间、渲染速度、模型大小和渲染质量上的对比。相比baseline DVGO来说都有一定程度上的提升。值得说明的是,PlenOctrees和Plenoxels采用的是球谐系数的方式,从而无需MLP,因此在渲染速度上能够达到很快。但是在渲染质量和模型大小上不如我们所提方法渲染出来的模型。此外,如果用我们的模型来存储球谐系数,也能达到如此高的渲染速度。
下表是消融实验的结果,可以看出通过将两个VDB合并为一个的方式可以进一步减小存储占用以及加快渲染速度。经过可视化的结果显示,与DVGO相比,渲染速度和内存占用都有4-5倍的提升。

07
Conclusion
1.我们提出了PlenVDB,它建立在VDB的基础上,是一种层级的稀疏体数据结构;
2. 实验结果表明,我们的模型在训练速度,渲染速度和存储开销上达到了较好的平衡效果;
3. 我们提出了一种直接从输入图像中学习VDB数据的训练策略,这使得训练的速率加快;
4. 训练好的VDB模型可以导出为NanoVDB格式用于传统的图形渲染管线。
08
Reference
[1] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In Proc. ECCV, 2020.
[2] Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. PlenOctrees for real-time rendering of neural radiance fields. In ICCV, 2021.
[3] Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In CVPR, 2022.
[4] Zhiqin Chen, Thomas Funkhouser, Peter Hedman, Andrea Tagliasacchi. MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures. In arXiv:2208.00277.
[5] Ken Museth. 2021. NanoVDB: A GPU-Friendly and Portable VDB Data Structure For Real-Time Rendering And Simulation. In ACM SIGGRAPH 2021 Talks.
[6] Ken Museth. Vdb: High-resolution sparse volumes with dynamic topology. ACM Trans. Graph., 2013.
[7] Sara Fridovich-Keil and Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. In CVPR, 2022.
整理:陈研
审核:严涵
提
醒
点击“阅读原文”跳转到20:38可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1000多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!

