
- 1SpringBoot 整合 各种缓存技术_springboot集成缓存
- 2如何实现比PyTorch快6倍的Permute/Transpose算子?_permute torch 性能 oneflow
- 3用Keras和直方图均衡化进行深度学习的图像增强_自适应直方图均衡优化对深度学习的优化
- 4更改pip源的两种方法_pip换源
- 5机器学习模型评价(Evaluating Machine Learning Models)-主要概念与陷阱
- 6配电房轨道式巡检机器人方案
- 7IP地址详解
- 8深度剖析数据库国产化迁移之路
- 9关于ssh启动失败的问题_service sshd start启动不了
- 10数据库系列之SequoiaDB高可用集群部署(一)
[CVPR 2023:3D Gaussian Splatting:实时的神经场渲染]_gaussion splatting
赞
踩
原文地址:https://blog.csdn.net/qq_45752541/article/details/132854115
前言
mesh 和点是最常见的3D场景表示,因为它们是显式的,非常适合于快速的基于GPU/CUDA的栅格化。相比之下,最近的神经辐射场(NeRF)方法建立在连续场景表示的基础上,通常使用体射线行进来优化多层感知器(MLP),以实现捕获场景的新视图合成。类似地,迄今为止最有效的辐射场解决方案建立在连续表示的基础上,通过插值存储的值,例如,体素或哈希[网格或点。虽然这些方法的连续性有助于优化,但渲染所需的随机抽样是昂贵的,并可能导致噪声。我们引入了一种新方法,结合了最好的两个世界:我们的三维高斯表示允许优化与最先进的(SOTA)视觉质量和竞争训练时间,而我们的拼接解决方案确保实时渲染SOTA质量1080p分辨率在几个之前发布的数据集(见下图1)。
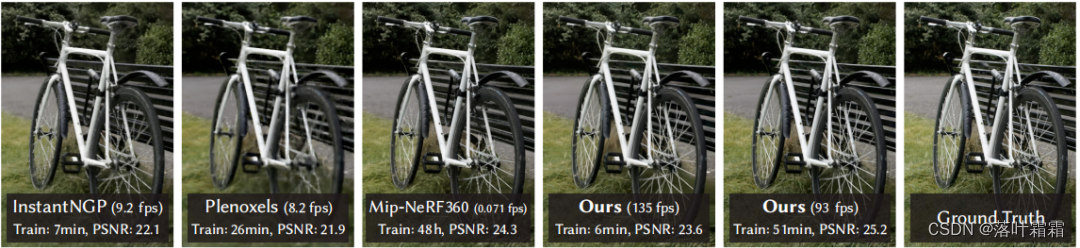
Mip-NeRF360 需要长达48小时的训练时间;快速但质量较低的辐射场方法可以根据场景实现交互式渲染时间(每秒10-15帧),但不能在高分辨率下实现实时渲染。
我们的解决方案有三个主要组件:
首先引入三维高斯分布作为场景表示。与 nerf 方法相同的输入开始,即使用运动结构(SfM)校准的相机,并使用SfM过程中免费产生的稀疏点云初始化三维高斯数集。与大多数需要多视图立体声(MVS)数据的基于点的解决方案相比,仅以SfM点作为输入就获得了高质量的结果。注意,对于nerf合成数据集,我们的方法即使在随机初始化下也能获得高质量。我们证明了三维高斯优点:是可微的体积表示,但它们也可以通过投影到二维,并使用标准
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

