- 1CRM客户关系管理系统UI设计作品_crm ui
- 2次世代手游美术资源优化干货分享_pc移植手游怎么压缩美术资源
- 3Prometheus监控K8S
- 4win10 快捷键大全(集合)_win10快捷键大全表
- 5【学习】FaceForensics++: Learning to Detect Manipulated Facial Images
- 6OpenCV安装_安装opencv
- 7OpenAI开发系列(二):大语言模型发展史及Transformer架构详解_迎接大模型时代:大模型发展简史及攻略
- 8win+快捷键(常用)
- 9cassandra java 例子_Cassandra教程:Java API 简单例子
- 10.net core 图片合并,图片水印,等比例缩小,SixLabors.ImageSharp
2023年 20篇神经架构搜索(Neural Architecture Search) CVPR ICLR AAAI Survey 笔记 (持续更新)_hotnas: hierarchical optimal transport for neural
赞
踩
目录
1.1 PA&DA: Jointly Sampling PAth and DAta for Consistent NAS
1.2. DisWOT: Student Architecture Search for Distillation WithOut Training
1.3. EMT-NAS:Transferring architectural knowledge between tasks from different datasets
1.4. HOTNAS: Hierarchical Optimal Transport for Neural Architecture Search
1.5. Meta-prediction Model for Distillation-Aware NAS on Unseen Datasets
1.6 Equivariance-Aware Architectural Optimization Of Neural Networks
1.7 Λ-Darts: Mitigating Performance Collapse By Harmonizing Operation Selection Among Cells
1.8 Improving Differentiable Neural Architecture Search By Encouraging Transferability
1.9 The Dark Side Of AutoML: Towards Architectural Backdoor Search
1.10 Transfer Nas With Meta-Learned Bayesian Surrogates
1.11 PASHA: Efficient HPO And NAS With Progressive Resource Allocation
1.12 GeNAS: Neural Architecture Search with Better Generalization
1.13 NAS-LID: Effificient Neural Architecture Search with Local Intrinsic Dimension
2.1 Adversarially Robust Neural Architecture Search for Graph Neural Networks
2.2 AutoTransfer: AutoML with knowledge transfer - an application to graph neural networks
3.1. MDL-NAS: A Joint Multi-domain Learning Framework for Vision Transformer
4.1 EA-HAS-BENCH: Energy-aware hyperparameter and architecture search benchmark
5.1. Learning A Data-Driven Policy Network For Pre-Training Automated Feature Engineering
1、CNN专题
1.1 PA&DA: Jointly Sampling PAth and DAta for Consistent NAS
| Aim: | 提升超网权重共享时,内部子网排序的一致性(正确性)。 |
| Abstract: | 权重共享机制: One-shot NAS方法训练一个超级网络,然后继承预先训练的权重来评估子模型,从而大大降低了搜索成本。然而,一些研究指出共享权重在训练过程中存在梯度下降方向不同的问题。在超网络训练过程中会出现较大的梯度方差,从而降低了超网络排序的一致性。 |
| Methods: | 为了缓解这一问题,作者提出通过联合优化PAth和DAta(PA&DA)的采样分布来显式地最小化超网训练的梯度方差。作者从理论上推导出梯度方差与采样分布之间的关系,并发现最优采样概率与路径和训练数据的归一化梯度范数成正比。 因此,作者将归一化梯度法作为路径和训练数据的重要性指标,并采用重要性采样策略进行超网训练。该方法只需要微小的计算成本来优化路径和数据的采样分布,但在超网训练过程中获得了较低的梯度方差和较好的泛化效果。 |
| Conclusion: | 通过重要路径采样,和重要数据采样,来优化Ktau大小,提升超网内部子模型的一致性。 |
| Keyresults: | CVPR 、Sampling、SuperNet Training 、Evolutionary Search、采样专题、中科院计算所 |
| Code: |
https://github.com/ShunLu91/PA-DA
|


1.2. DisWOT: Student Architecture Search for Distillation WithOut Training
| Aim: | 解决师生之间,较大的架构差异带来对蒸馏的增益的限制 |
| Abstract: | 知识蒸馏(KD)是一种在笨重教师指导下改进轻量级学生模式的有效培训策略。 然而,师生对之间的巨大架构差异限制了蒸馏的增益。与以往的自适应蒸馏方法来减少师生差距相比,作者探索了一种新的无训练框架来为给定的教师寻找最佳的学生架构。 |
| Methods: | 工作首先通过经验表明,vanilla训练下的最优模型不能成为蒸馏的赢家。 其次,作者发现随机初始化的师生网络之间的特征语义的相似性和样本关系与最终的蒸馏性能有很好的相关性。因此,作者有效地度量了基于语义激活映射的相似性矩阵,通过一个没有任何训练的进化算法来选择最优的学生。通过这种方式,Student architecture search for Distillation WithOut Training(DisWOT)显著提高了模型在至少180×训练加速的蒸馏阶段的性能。此外,作者将DisWOT中的相似性度量扩展为新的蒸馏器和基于kd的零代理。 |
| Conclusion: | 在CIFAR、ImageNet和NAS-Bench-201上进行的实验表明,我们的技术在不同的搜索空间上取得了最先进的结果。 |
| Keyresults: |
CVPR 、Knowledge distillation、zero-shot、withOut Train、进化搜索、国防科技大学
|
| Code: | DisWOT: Student Architecture Search for Distillation WithOut Training | DisWOT-CVPR2023 (lilujunai.github.io) |


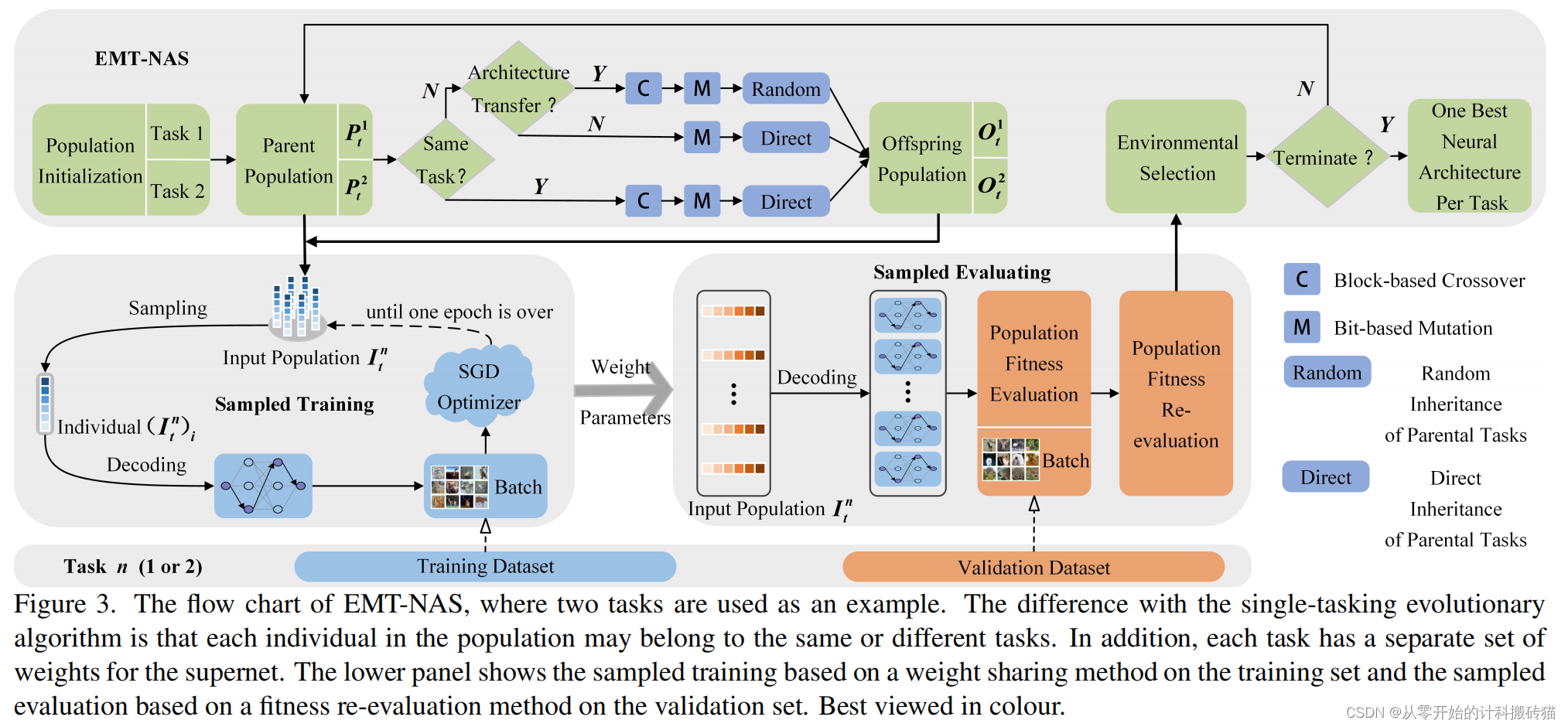
1.3. EMT-NAS:Transferring architectural knowledge between tasks from different datasets
| Aim: | 探索同时在多数据集上搜索的好处。 |
| Abstract: | 多任务学习(MTL)的成功在很大程度上归因于相关任务的共享表示,从而使模型能够更好地通用化。在深度学习中,这通常是通过共享一个共同的神经网络体系结构和共同训练权值来实现的。然而,在多个相关任务上联合训练加权参数可能会导致性能下降,称为负转移。 |
| Methods: | 为了解决这一问题,本工作提出了一种进化的多任务神经体系结构搜索(EMT-NAS)算法,通过在多个相关任务之间转移体系结构知识来加速搜索过程。 在EMT-NAS中,与传统的MTL不同,每个任务的模型都有一个个性化的网络体系结构和它自己的权重(就是一个超网对应一个数据集),从而提供了有效减轻负转移的能力。 提出了一种适应度重评估方法,以缓解参数共享和小批量梯度下降训练方法导致的性能评估波动,从而避免在搜索过程中丢失有希望的解决方案。 |
| Conclusion: | 为了严格验证EMT-NAS的性能,在实证评估中使用的分类任务来自不同的数据集,包括CIFAR-10和CIFAR-100,以及四个MedMNIST数据集。在不同任务数量上进行的大量比较实验表明,EMT-NAS在CIFAR和MedMNIST上分别花费8%和40%,比单任务对应找到竞争神经结构的时间更少。 |
| Keyresults: | CVPR 、多任务、多数据集、进化搜索、没有做B201、对比算法较旧 |
| Code: | PengLiao12/EMT-NAS (github.com) |

1.4. HOTNAS: Hierarchical Optimal Transport for Neural Architecture Search
| Aim: | 探究搜索多个Cell与整个网络之间的关系 |
| Abstract: | 目前的NAS方法不是直接地搜索整个网络,而是越来越多地搜索多个相对较小的细胞,以降低搜索成本。一个主要的挑战是联合测量细胞微结构的相似性和不同的基于细胞的网络之间的宏观结构的差异。 |
| Methods: | 近年来,最优传输(OT)已成功地应用于NAS,因为它可以捕获各种网络之间的操作和结构相似性。不幸的是,现有的NAS方法的OT要么忽略了单元之间的相似性,要么只专注于搜索单个单元的体系结构。为了解决这些问题,作者提出了一个称为HOTNN的层次最优传输度量来度量不同网络的相似度。 在HOTNN中,单元级相似性通过考虑每个节点的相似性以及每个单元内节点对在操作和结构信息方面的信息流成本的差异,来计算不同网络中单元间的OT距离。 网络级相似度通过考虑单元级相似度和每个单元在各自网络中的整体位置的变化来计算网络之间的OT距离。然后,作者在一个称为HOTNAS的贝叶斯优化框架中探索HOTNN,并证明了它在不同任务中的有效性。 |
| Conclusion: | 大量的实验表明,HOTNAS可以在基于多个模块化单元的搜索空间中发现具有更好性能的网络架构。 |
| Keyresults: | CVPR 、分层搜索、整体搜索、信息传输、人民大学 |
| Code: | 没有代码 |

1.5. Meta-prediction Model for Distillation-Aware NAS on Unseen Datasets
| Aim: | 提高架构搜索在:未知数据集、未知教师组成的新任务上的表现,减少计算消耗。 |
| Abstract: | 蒸馏感知神经架构搜索(DaNAS)的目的是搜索最佳学生架构,在从给定的教师模型中提炼知识时,能获得最佳性能和/或效率的最佳学生架构。之前的 DaNAS方法主要是针对固定数据集和教师搜索神经架构,而这种方法并不通用。 这些方法不能很好地概括由未知数据集和未知教师组成的新任务。因此需要对数据集和教师的任何新组合进行代价高昂的搜索。 |
| Methods: | 对于没有 KD 的标准 NAS 任务,有人提出了基于元学习的计算效率高的 NAS 方法。 |
| Conclusion: | 实验结果表明,作者提出的元预测模型成功地泛化到多个未见数据集的任务,在很大程度上优于现有的元 NAS 方法和快速 NAS基线。 |
| Keyresults: | ICLR、元预测、师生网络、韩国科学技术院 |
| Code: |
师生网络(Teacher-Student Networks)是一种模型训练的策略,主要用于知识蒸馏(Knowledge Distillation)技术中。它的主要意义在于将复杂的大模型(教师网络)的知识传递给简化的小模型(学生网络),从而使学生网络能够获得教师网络的知识,同时保持较小的模型大小和计算复杂度。

1.6 Equivariance-Aware Architectural Optimization Of Neural Networks
| Aim: | 探索等变性数据与NAS之间的关系 |
| Abstract: | 在神经网络训练过程中,将对称群的等方差作为约束,可以提高表现出这些对称性的任务的性能和泛化,但这种对称性往往不完美或明确地存在。这促使算法优化由等方差所施加的架构约束。 |
| Methods: | 首先,作者引入了等变性松弛映射(equivariance relaxation morphism),它保持功能性,同时对群等变性层进行重新参数化,使其在一个子群上运行,从而实现对等变性约束的优化。 其次,作者提出了[G]-混合等变性层([G]-mixed equivariant layer),它将受限于不同群组的层混合在一起,以实现在层内进行等变性优化。 在此基础上,作者还提出了应用于等变性感知架构优化的进化算法和可微分神经架构搜索(NAS)算法。这些算法利用上述机制来实现对等变性感知架构的优化。 |
| Conclusion: | 在各种数据集上的实验表明,动态约束等方差对找到具有近似等方差的有效架构的好处。 |
| Keyresults: | ICLR、Incorporating equivariance、symmetries、图卢兹大学 |
| Code: |
None
|
等变性:是指当输入数据经过某种变换后,网络输出的结果也随之进行相应的变换。在一些任务中,数据可能具有某些对称性质,即在进行一些变换后,任务的结果应该保持不变。例如,对于图像分类任务,图像旋转90度或180度后,图像的类别应该保持不变。

对称群是指对某个集合的所有置换组成的群。在数学中,给定一个集合,它的对称群包含了所有可能的置换(排列)方式,即将集合中的元素重新排列的所有可能性。
例如,对于集合{1, 2, 3},它的对称群包含了所有可能的置换方式,如{1, 2, 3}、{1, 3, 2}、{2, 1, 3}、{2, 3, 1}、{3, 1, 2}和{3, 2, 1}。这些置换形成了对称群,因为它们保持了集合中元素之间的关系,即元素之间的相对位置没有改变。
对称群在许多领域都有重要的应用,特别是在几何学、代数学和物理学中。在神经网络的等变性研究中,对称群的概念也被广泛应用,以帮助网络更好地处理具有对称性质的数据和任务。
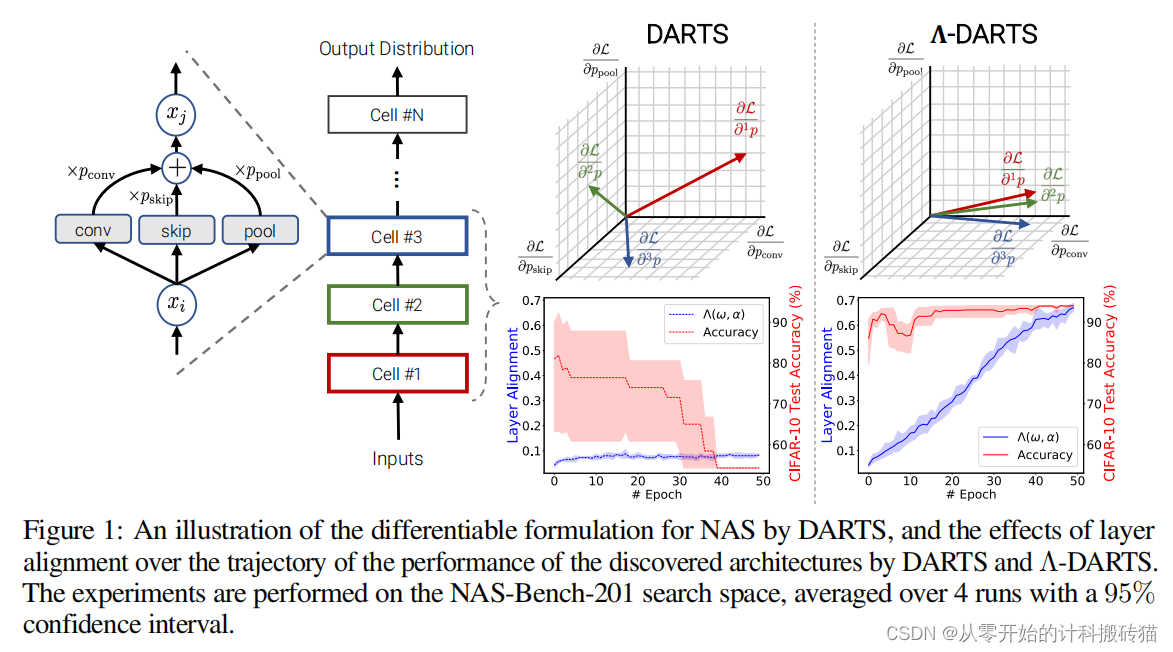
1.7 Λ-Darts: Mitigating Performance Collapse By Harmonizing Operation Selection Among Cells
| Aim: | 通过协调每个Cell之间的操作选择,来缓解性能衰退 |
| Abstract: | 可微神经结构搜索(DARTS)是神经结构搜索(NAS)的一种流行方法,它通过基于梯度的细胞搜索,利用连续松弛优化来提高搜索效率。飞镖的主要缺点是性能崩溃,即被发现的架构在搜索过程中遭受了质量下降的模式。 |
| Methods: | 性能崩溃已经成为一个重要的研究课题,许多方法试图通过正则化或对DARTS的基本改变来解决这个问题。然而,用于DARTS中单元搜索的权重共享框架和架构参数的收敛性尚未得到分析。 本文对DARTS及其收敛点进行了全面的和新的理论和实证分析。作者表明,由于飞镖的权重共享框架限制了一个特定的结构缺陷,使其收敛到softmax函数的饱和点。这种收敛点在选择最优架构时给更接近输出的层提供了不公平的优势,从而导致性能崩溃。 作者提出了两个新的正则化术语,旨在通过对齐层的梯度来协调操作选择来防止性能崩溃。 |
| Conclusion: | 在6个不同的搜索空间和三个不同的数据集上的实验结果表明,该方法(Λ-DARTS)确实防止了性能崩溃,为我们的理论分析和提出的补救方法提供了依据。 |
| Keyresults: |
ICLR、德黑兰大学、慕尼黑大学、Google Brain
|
| Code: |
1.8 Improving Differentiable Neural Architecture Search By Encouraging Transferability
| Aim: | 缓解DARTS的稳定性不足问题 |
| Abstract: | 可微神经结构搜索方法由于其计算效率而越来越受欢迎。然而,这些方法的普遍性和稳定性并不理想。它们搜索的体系结构经常退化为主要数量的跳过连接,并且在测试数据上执行得不令人满意。 |
| Methods: | 现有的解决这一问题的方法有很多的局限性,如不能阻止架构退化的发生,对跳过连接数量的设置限制过多等。为了解决这些限制,作者提出了一种新的方法来提高可微NAS的通用性和稳定性,通过开发一个鼓励可转移性的三级优化框架,该框架通过鼓励辅助模型具有良好的可转移性来改进主模型的体系结构。 框架包括三个端到端阶段: 1)训练主模型的网络权重;2)将知识从主模型转移到辅助模型;3)通过最大限度地提高其对辅助模型的可转移性来优化主模型的体系结构。 其次作者提出了一种基于四重相对相似度匹配的新的知识转移方法。 |
| Conclusion: | 在多个数据集上的实验证明了该方法的有效性。 |
| Keyresults: | ICLR、改善迁移性、宾夕法尼亚大学、加州大学圣地亚哥分校 |
| Code: |
None
|

1.9 The Dark Side Of AutoML: Towards Architectural Backdoor Search
| Aim: | 利用神经架构搜索(NAS)作为新的攻击载体,发起以前不可能发起的攻击? |
| Abstract: | 本文提出了一个耐人寻味的问题:是否有可能利用神经架构搜索(NAS)作为新的攻击载体,发起以前不可能发起的攻击? |
| Methods: | 具体来说,作者提出了 EVAS,一种利用 NAS 寻找带有固有后门的神经架构,并使用输入感知触发器利用这种漏洞的新攻击。与现有的攻击相比,EVAS 展示了许多有趣的特性:(i) 它不需要污染训练数据或扰乱模型参数;(ii) 它与下游微调甚至从头开始重新训练无关;(iii) 它自然而然地规避了依赖于检查模型参数或训练数据的防御。 |
| Conclusion: | 作者进一步描述了 EVAS 的基本机制,这些机制可能可以通过识别触发模式的架构级 "捷径 "来解释。这项工作表明,NAS 可以被以一种有害的方式,找到具有内在后门漏洞的架构。 |
| Keyresults: | ICLR、安全领域、模型攻击、宾夕法尼亚州立大学、浙江大学 |
| Code: |


1.10 Transfer Nas With Meta-Learned Bayesian Surrogates
| Aim: | 跨越不同数据集的NAS |
| Abstract: | 然神经架构搜索(NAS)是一个研究非常深入的领域,但方法通常仍然面临(i)高计算成本或(ii)缺乏数据集和实验之间的鲁棒性。此外,大多数方法从头开始寻找最优体系结构,忽略先验知识。 |
| Methods: | 这与研究人员和工程师的手工设计过程相反,后者利用以前的深度学习经验,例如,从以前解决的相关问题中转移架构。 作者建议采用这种人工设计策略,并引入一种新的NAS替代物,它是跨不同数据集的先前体系结构评估进行元学习的。 作者利用具有深度核高斯过程的贝叶斯优化(BO),图神经网络来获得架构嵌入和一个基于转换器的数据集编码器。 |
| Conclusion: | 因此,该方法在6个计算机视觉数据集上一致地取得了最先进的结果,同时与One-shot NAS方法一样快 |
| Keyresults: | ICLR、贝叶斯优化、代理模型、元学习、GNN编码、弗莱堡大学、博世AI |
| Code: | https://github.com/TNAS-DCS/TNAS-DCS |

1.11 PASHA: Efficient HPO And NAS With Progressive Resource Allocation
| Aim: | NAS与HPO的能耗优化 |
| Abstract: | 超参数优化(HPO)和神经架构搜索(NAS)是获得一流的机器学习模型的首选方法,但在实践中,它们的运行成本可能很高。当模型在大数据集上进行训练时,使用HPO或NAS调整它们对从业者变得非常昂贵,即使使用高效的多保真度方法。 |
| Methods: | 作者提出了一种方法来解决调整在有限的大型数据集上训练的机器学习模型的挑战。 方法名为PASHA,它扩展了ASHA,并能够根据需要动态地为调优过程分配最大的资源。 |
| Conclusion: | 实验比较表明,PASHA可以识别出性能良好的超参数配置和架构,同时消耗的计算资源明显少于ASHA。 |
| Keyresults: | ICLR、HPO&NAS、能耗优化、爱丁堡大学、AWS |
| Code: |
None
|


1.12 GeNAS: Neural Architecture Search with Better Generalization
| Aim: | NAS训练时排序的正确性,结果的泛化性 |
| Abstract: | 神经架构搜索(NAS)的目标是自动挖掘出具有优越测试性能的最优网络架构。最近的神经结构搜索(NAS)方法依赖于验证损失或准确性来为目标数据找到更好的网络。 |
| Methods: | 在本文中,作者研究了一种新的神经结构搜索措施,以挖掘结构与更好的泛化。作者证明了损失面的平面度可以作为预测神经网络结构泛化能力的一个很有前途的代理。 |
| Conclusion: | 作者在不同的搜索空间上评估了提出的方法,与最先进的NAS方法相比,显示出了相似甚至更好的性能。值得注意的是,通过平坦度度量发现的结果体系结构可以稳健地推广到数据分布中的各种变化(例如,ImageNet-V2、-A、-O),以及各种任务,如对象检测和语义分割。 |
| Keyresults: | IJCAI、代理模型、通用NAS、NAVER Cloud &AI Lab、KAIST |
| Code: |


1.13 NAS-LID: Effificient Neural Architecture Search with Local Intrinsic Dimension
| Aim: | 通过使用局部内在维数评价网络架构的性能,缓解超网的训练困难。 |
| Abstract: | 一次性神经体系结构搜索(NAS)通过训练一个超网来估计每个可能的子体系结构(即子网)的性能,大大提高了搜索效率。然而,子网间特征的不一致性对优化造成了严重的干扰,导致子网的性能排名相关性较差。 |
| Methods: | 后续的探索通过一个特定的准则分解超网权值,如梯度匹配,以减少干扰;但它们存在巨大的计算成本和低空间可分性。在这项工作中,作者提出了一种轻量级和有效的基于局部内在维数(LID)的方法NAS-LID。NAS-LID通过逐层计算低成本的LID特征来评估体系结构的几何特性,以LID为特征的相似性比梯度具有更好的可分性,从而有效地减少了子网之间的干扰。 |
| Conclusion: | 对NASBench-201的大量实验表明,NAS-LID具有优越的性能和更好的效率。具体来说,与梯度驱动的方法相比,NAS-LID可以节省高达86%的费用 |
| Keyresults: | AAAI、香港浸会大学、上海交通大学、NVIDIA |
| Code: |


2、GNN & GCN专题
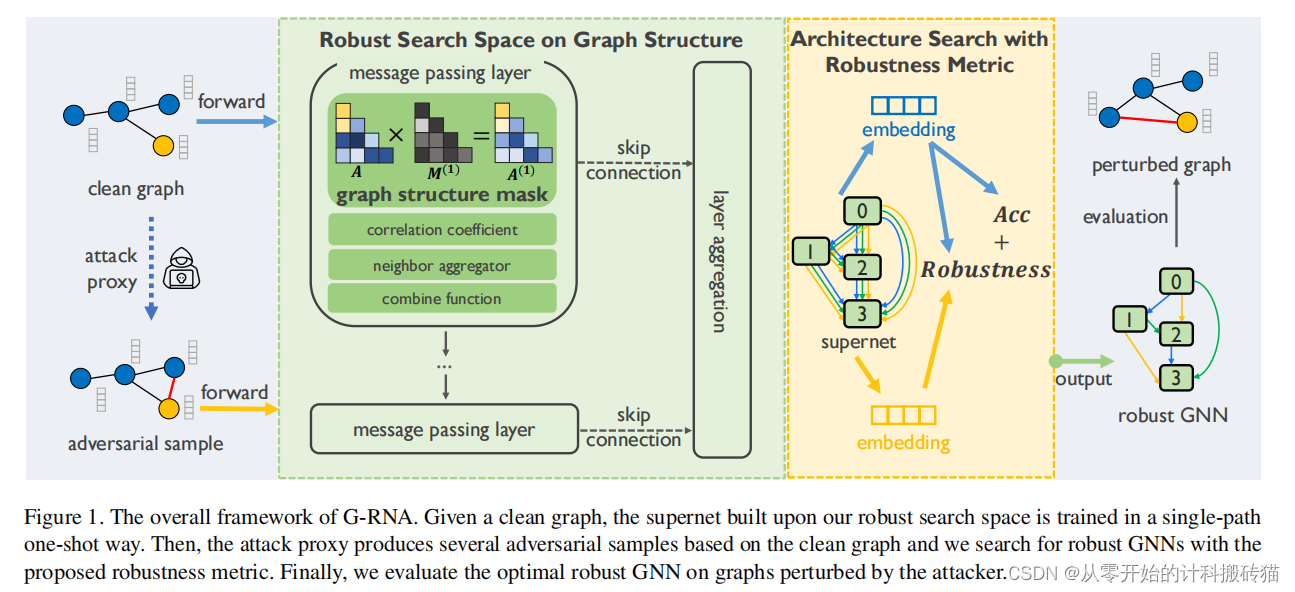
2.1 Adversarially Robust Neural Architecture Search for Graph Neural Networks
| Aim: | 提高GNN的健壮性 |
| Abstract: | 图神经网络(GNNs)在关系数据建模方面取得了巨大的成功。 尽管如此,它们还是容易遭到敌对攻击,这是对将GNN应用于风险敏感领域的巨大威胁。现有的防御方法既不能保证面对新数据/任务或对抗性攻击的性能,也不能提供从架构角度理解GNN健壮性的见解。 |
| Methods: | 神经架构搜索(NAS)有潜力通过自动化GNN架构设计来解决这一问题。然而,目前的图NAS方法缺乏健壮的设计,并且容易受到对抗性攻击。 为了解决这些挑战,作者提出了一种新的GNN的稳健神经结构搜索框架(G-RNA)。 具体来说,通过在搜索空间中添加图结构掩码操作,为消息传递机制设计了一个鲁棒的搜索空间,该空间包含各种防御操作候选操作,允许我们搜索防御性GNN。此外,作者定义了一个鲁棒性度量来指导搜索过程,这有助于过滤鲁棒性体系结构。通过这种方式,G-RNA有助于从架构的角度理解GNN的鲁棒性,并有效地寻找最优的对抗性鲁棒性GNN。 |
| Conclusion: | 在对抗性攻击下,G-RNA显著优于人工设计的robust-GNN和vanilla graph NAS 基线12.1%至23.4%。 |
| Keyresults: | CVPR 、GNN、健壮性、安全领域、清华 &耶鲁 |
| Code: |
无代码
|
2.2 AutoTransfer: AutoML with knowledge transfer - an application to graph neural networks
| Aim: | 现有的AutoML方法(GCN),都是从头开始搜索,导致大计算量的问题。 |
| Abstract: | AutoML 在为特定数据集和评估指标定义的机器学习任务找到有效的神经架构方面取得了显著的成功。然而,目前大多数 AutoML 技术都是将每个任务从头开始独立考虑,这就需要探索许多架构,从而导致高昂的计算成本。 |
| Methods: | 作者提出了 AutoTransfer,这是一种 AutoML 解决方案,它能将先前的架构设计知识转移到新任务中,从而提高搜索效率。 最后,作者发布了GNN-BANK-101,这是一个包含详细 GNN 训练信息的大规模数据集,其中有120,000 个任务-模型组合的详细 GNN 训练信息的数据集,以促进和启发未来的研究。 |
| Conclusion: | 实验证明 (1)提出的任务嵌入可以高效计算,并且具有相似嵌入的任务具有相似的最佳架构; (2)AutoTransfer大大提高了利用转移的设计先验进行搜索的效率,减少了一个搜索数量级(an order of magnitude )。 |
| Keyresults: | ICLR、GCN、先验方法、GNN-BANK-101、斯坦福大学 |
| Code: | https://github.com/snap-stanford/AutoTransfer |



3、transform专题
3.1. MDL-NAS: A Joint Multi-domain Learning Framework for Vision Transformer
| Aim: | 全新的共享策略解决灾难性遗忘 |
| Abstract: | 在这项工作中,作者引入了MDL-NAS,这是一个统一的框架,它将多个视觉任务集成到一个可管理的超级网络中,并在不同的数据集域下集体优化这些任务。 |
| Methods: | MDL-NAS具有存储效率,因为具有大多数共享参数的多个模型可以存储到一个模型中。 从技术上讲,MDLNAS构建了一个从粗到细的搜索空间,其中粗搜索空间为不同的任务提供了各种最优架构,而精细搜索空间提供了细粒度的参数共享来解决多域学习的固有障碍。 在精细搜索空间中,作者提出了两种参数共享策略,即顺序共享策略和掩码共享策略。 与以往的工作相比,这两种共享策略允许在网络的每一层部分共享和不共享参数,从而实现真正的细粒度参数共享。 最后,我们提出了一种联合子网搜索算法,该算法在总资源约束下为每个任务寻找最优架构和共享参数,挑战了下游视觉任务通常配备用于图像分类的主干网络。 |
| Conclusion: | 通过实验,我们证明了与最先进的方法相比,MDL-NAS家族在保持高效的存储部署和计算的同时,在所有任务中都提供了具有竞争力的性能。我们还证明了MDL-NAS允许增量学习,并在归纳到新任务时避免灾难性遗忘。 |
| Keyresults: | CVPR 、多模态、全新的权重共享、电子科技大学 |
| Code: |
无代码
|


4. BenchMark专题
4.1 EA-HAS-BENCH: Energy-aware hyperparameter and architecture search benchmark
| Aim: | 从能量角度出发,开发一种集成超参数和架构自动设计的测试集。 |
| Abstract: | 由于训练数据和模型规模的增长,训练深度学习模型的能量消耗正以惊人的速度增长,从而对碳中和产生了负面影响。对于 AutoML 算法来说,能耗是一个尤为紧迫的问题,因为它通常需要反复训练大量计算密集型深度模型,以搜索最佳配置。 |
| Methods: | 本文通过提供一个基准,使EANAS研究在开发能量感知(EA)NAS方法时采取了最重要的步骤之一,更是可重复的和可访问的。具体来说,我们提出了第一个大规模的能量感知基准,它允许研究AutoML方法,以在性能和搜索能耗之间实现更好的权衡,称为EA-HAS-Bench。 EA-HAS-Bench提供了一个大规模的架构/超参数联合搜索空间,涵盖了与能源消耗相关的多种配置。此外,我们提出了一种新的专为大型联合搜索空间设计的替代模型,提出了一种基于B‘ezier曲线的模型来预测具有无限形状和长度的学习曲线。 |
| Conclusion: | 基于该数据集,我们修改了现有的AutoML算法来考虑搜索的能量消耗,实验表明,改进的能量感知的AutoML方法在能量消耗和模型性能之间实现了更好的权衡。 |
| Keyresults: | ICLR、100亿配置 架构/超参数测试集、同济大学、微软亚洲研究院、(写作很好) |
| Code: |



5. Feature Engineering 专题
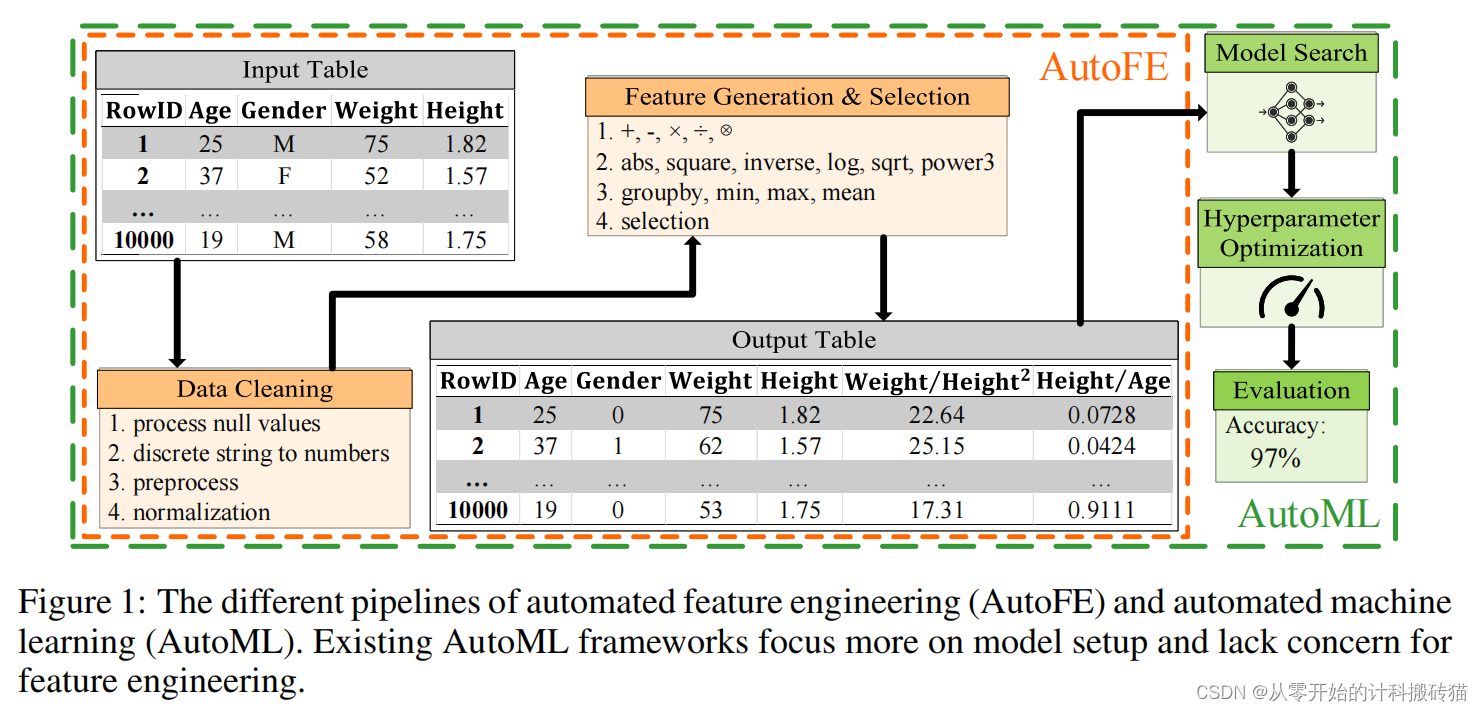
5.1. Learning A Data-Driven Policy Network For Pre-Training Automated Feature Engineering
| Aim: | 基于数据驱动的自动特征工程,并形成较强的可移植性。 |
| Abstract: | 特征工程被广泛认为是表格数据分析和预测的关键。自动化特征工程(AutoFE)出现的自动化这个过程由经验丰富的数据科学家和工程师常规管理。在这一领域,之前的大多数工作都采用了来自神经结构搜索(NAS)方法的相同框架。虽然可行,但我们假设NAS框架与人类专家处理数据的方式非常矛盾,因为固有的马尔可夫决策过程(MDP)设置是不同的。(MDP是决策,NAS是搜索)。 |
| Methods: | 作者指出,它的数据未观察到的设置结果导致无法在不同的数据集上泛化,以及很高的计算成本。 本文提出了一种新的AutoFE框架特征集数据驱动搜索(FETCH),一种主要用于特征生成和选择的方法。值得注意的是,FETCH建立在一个全新的数据驱动的MDP设置上,使用表格数据集作为输入到策略网络中的状态。此外,我们假设FETCH的关键优点是它的可转移性,在各种数据集上训练的生成的策略网络确实能够对不可见的数据实施特征工程,而不需要额外的探索。这是通过AutoFE构建表格数据预训练范式的先驱尝试。 |
| Conclusion: | 大量的实验表明,获取系统地超过了目前最先进的AutoFE方法,并验证了AutoFE预训练的可移植性。 |
| Keyresults: | ICLR、特征工程、浙江大学 |
| Code: |