
- 1威纶通导入图库_威纶通图库
- 2pyautogui自动化操作脚本_pyautogui.getwindowswithtitle
- 3vs2015启动网站调试提示 HTTP 错误 403.14 - Forbidden Web 服务器被配置为不列出此目录的内容。 解决方法
- 4激光雷达与组合贯导(imu)联合标定方案三(含源码)_激光雷达和惯导标定
- 5【目标检测】FastRCNN算法详解_rcnn中n=2 r=128中的r是什么含义
- 6Element-Ui组件(三)Button 按钮_el-button
- 7element-ui - 解决el-select数据量过大卡顿问题_elementui select数据过多
- 8Bootstrap使用总结
- 9YOLOv7改进之实验结果:新增mAP75的值
- 10微信小程序开发学习笔记《8》tabBar_微信小程序tabbar
YOLOv8 : 网络结构_yolov8网络结构详解
赞
踩
一. YOLOv8网络结构
1. Backbone
YOLOv8的Backbone同样参考了CSPDarkNet-53网络,我们可以称之为CSPDarkNet结构吧,与YOLOv5不同的是,YOLOv8使用C2f(CSPLayer_2Conv)代替了C3模块(如果你比较熟悉YOLOv5的网络结构,那YOLOv8的网络结构理解起来就easy了)。
如图1所示为YOLOv8网络结构图(引用自MMYOLO),对比图2的YOLOv5结构图,可以看到基本的架构是类似的。
这里值得注意的是,很多博文中写到YOLOv8使用了CSPDarkNet53作为backbone,当然是可以用的,但是官方代码中明显不是套用的CSPDarkNet53网络结构。事实上,YOLOv5的主干也并非是CSPDarkNet53网络。
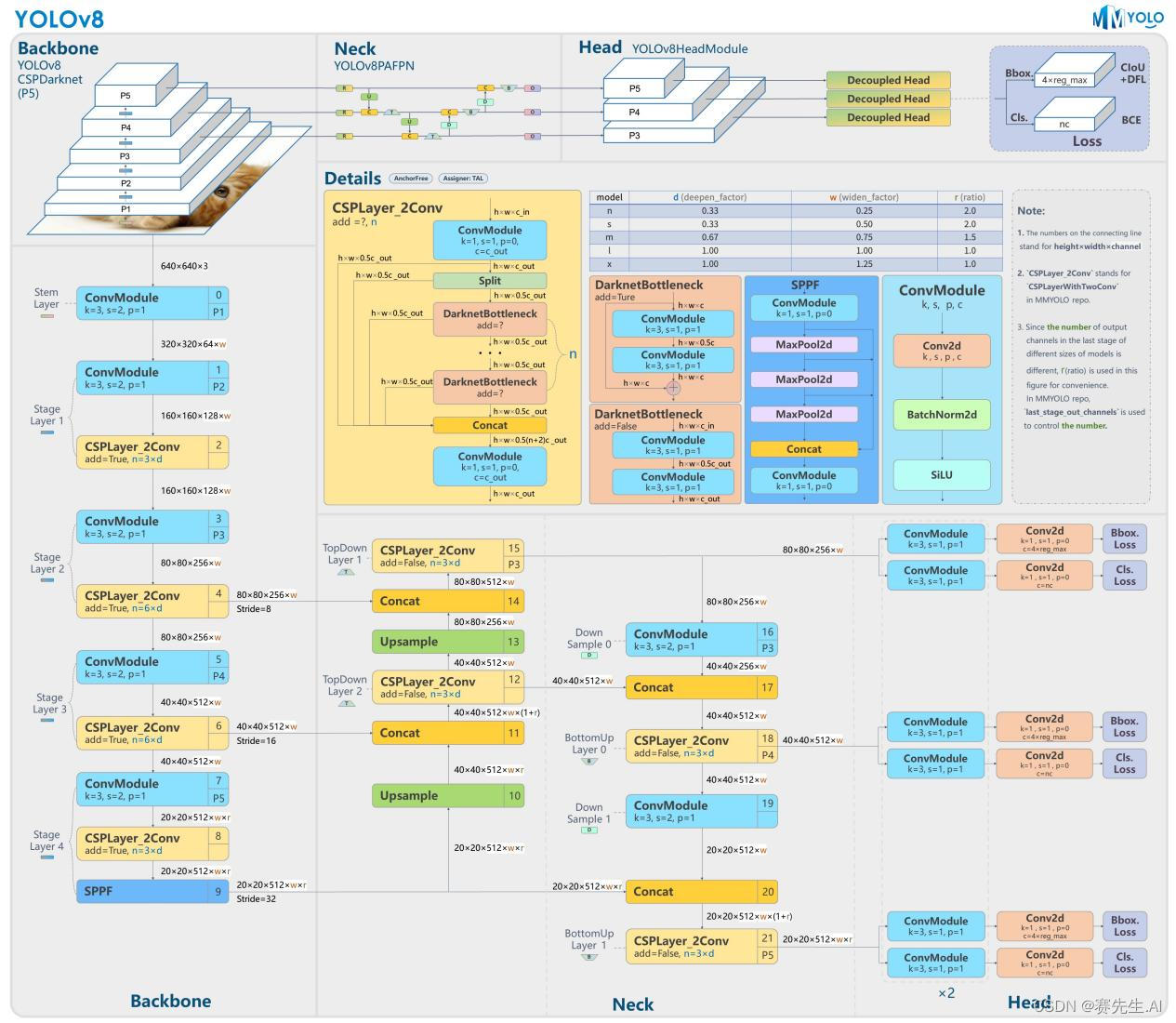
图1 YOLOv8网络架构

图2 YOLOv5网络架构
2. Neck
YOLOv8的Neck使用的也是类似于YOLOv5的PAN-FPN,称作双流FPN,高效,速度快。
3. Head
与之前的YOLOv6,YOLOX类似,使用了Decoupled Head,YOLOv3、YOLOv4、YOLOv5均使用Coupled Head。
YOLOv8也使用3个输出分支,但是每一个输出分支又分为2部分,分别来分类和回归边框(参照图1的Decoupled Head)。
二. 细说Backbone
前面讲到,YOLOv8的Backbone类似于YOLOv5的Backbone,不同点是将C3换成了C2F,以及将第一个Convolution层设置为kernel size等于3,stride为2(YOLOv5的Kernel Size为6,padding为2)。
1. C2F与C3对比
那么C2F与C3单元相比,有什么优势呢?我们先上各自的网络结构图。如图3为C3结构图,图4为C2F结构图。
图4中,每一个Bottleneck的输入Tensor的Channel都只有上一级的0.5倍,因此计算量明显降低。从另一方面讲,梯度流的增加,也能够明显提升收敛速度和收敛效果。
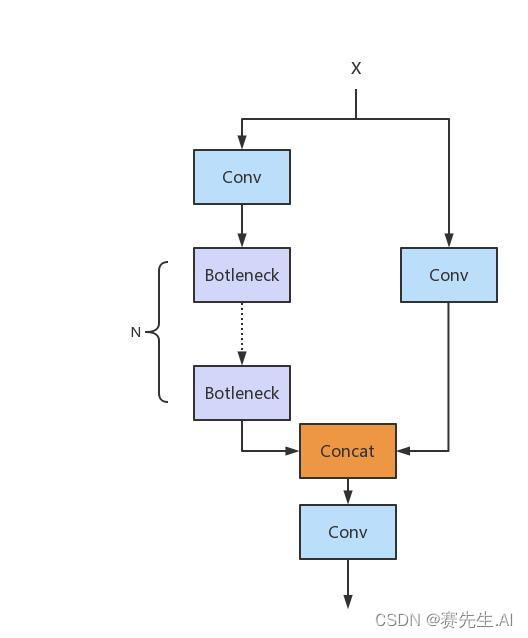
图3 C3单元

图4 C2F单元
2. Bottleneck
YOLOv8的C2F使用了Bottleneck单元,但需要注意的是,Darknet所引入的Bottleneck不同于ResNet的Bottleneck。如图5和图6分别为Darknet的Bottleneck和ResNet的Bottelneck。
由图5和图6可以看出,Darknet的Bottleneck单元并未使用最后的1*1卷积进行通道的恢复,而是直接在中间的3*3卷积中进行了恢复。
此处大家进记住一点即可,Bottleneck可以大大减少参数,降低计算量。
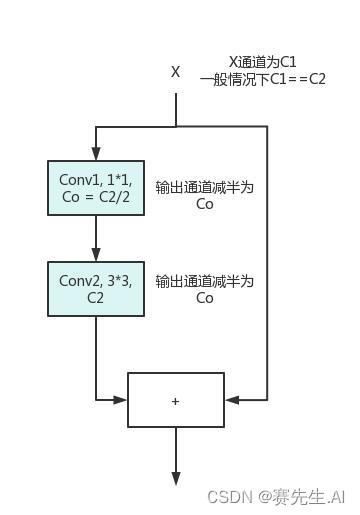
图5 Darknet Bottleneck
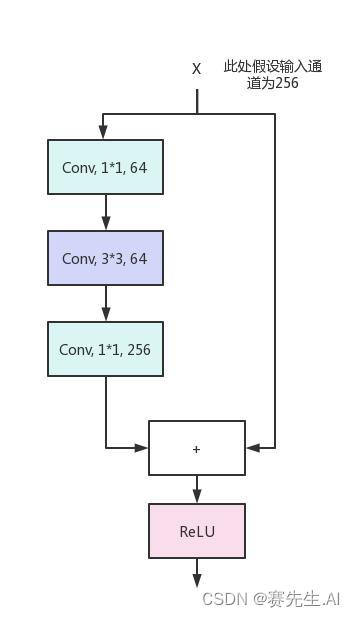
图6 ResNet Bottleneck
三. Neck
YOLOv8的Neck采用了PANet结构。如图7为网络局部图。
由图7可以看出,Backbone最后经过了一个SPPF(SPP Fast,图示Layer9),之后H和W已经经过了32被的下采样。对应的,Layer4经过了8被下采样,Layer6经过了16背的下采样。设定输入为640*640,得到Layer4、Layer6、Layer9的分辨率分别为80*80、40*40和20*20。
Layer4、Layer6、Layer9作为PANnet结构的输入,经过上采样,通道融合,最终将PANet的三个输出分支送入到Detect head中进行Loss的计算或结果解算。
与FPN(单向,自上而下)不同,PANet是一个双向通路网络。与FPN相比,PANet引入了自下向上的路径,使得底层信息更容易传递到高层顶部(红色曲线标注路线)。
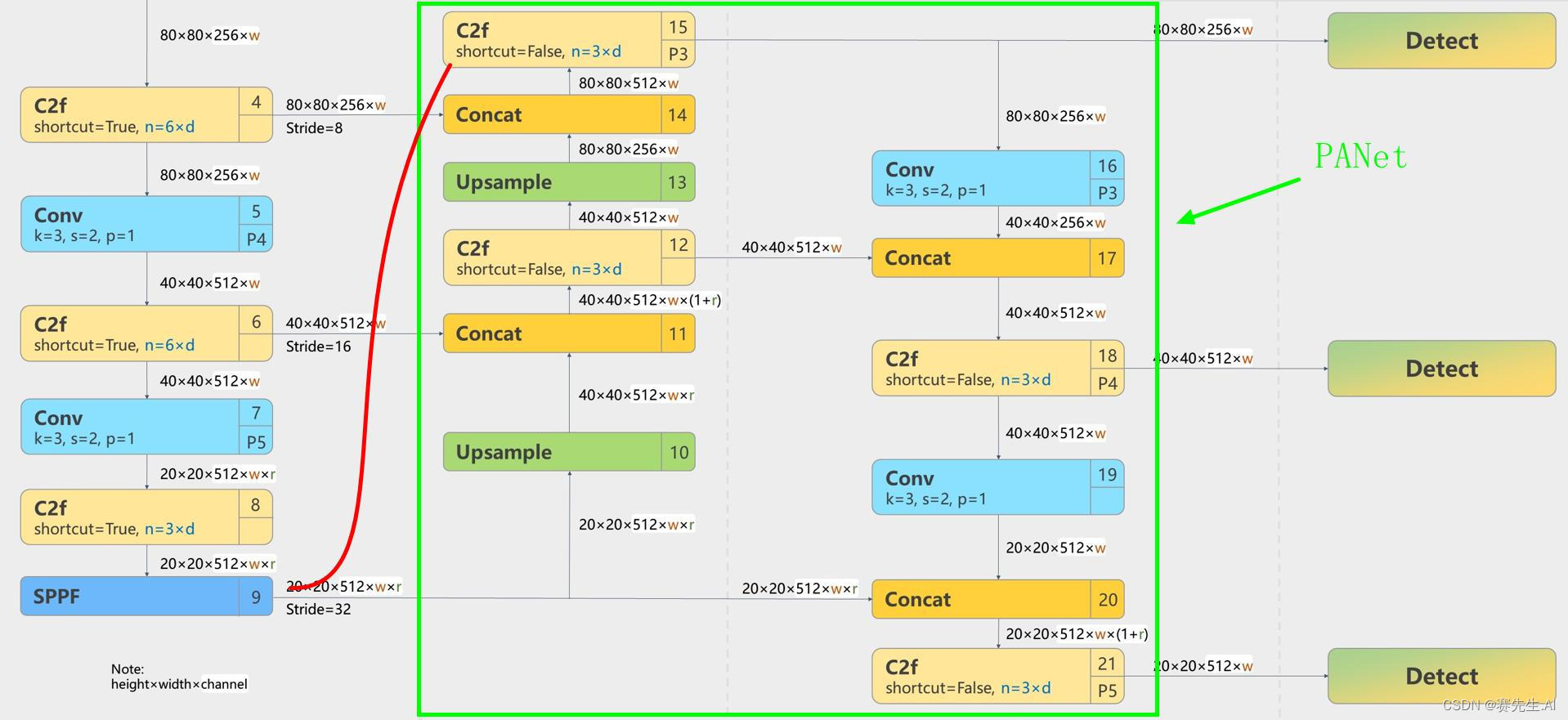
图7 YOLOv8 Neck(PANet)
四. Detect Head
YOLOv8采用了类似于YOLOX的Decoupled Head,将回归分支和预测分支进行分离。Decoupled Head的有点可以参考YOLOX的论文中提到的,收敛更快,效果更好。
需要特别提及的是,YOLOv8的Detect Head中,针对回归分支使用了DFL策略,之前的目标检测网络将回归坐标作为一个确定性单值进行预测,DFL将坐标转变成了一个分布。
DFL理论主要用来解决边界模糊的问题。详细了解可以参考论文“Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection”。

