
- 1java判断日期前后_Java丨时间判断谁前谁后
- 2如何扩展 JPA Annotation 以更好的支持 OR Mapping_jpa annotation mappings require
- 32021-10-074号靶场转自y神的学习笔记(net渗透,sockcap,msf多重网段渗透,os-shell,验证码重放,C#解密,wfuzz穷举subdomain)_http-robots.txt: 1 disallowed entry
- 4update-alternatives: error: no alternatives for g++处理_update-alternatives: error: no alternatives for gc
- 5个人所得税 软件电脑上的安装路径和名字 如何在电脑上找到个人所得税软件程序名称 ServYou\EPPortal_DS3.0_V2.1\EPEvenue_SH.exe_file://d:\epportal_ds3.0\appmodules\itskhd\temp\pa
- 6一个比较完善的httpWebRequest 封装,适合网络爬取及暴力破解
- 7Android开发规范:API接口通用设计规范_安卓 api
- 8android字符串定义,android – 使用现有的字符串定义定义’resValue’
- 9Jetpack Compose入门详解(实时更新)
- 10有效突破的三三原则
Pytorch实现mnist数字手写体识别_手写识别数字 pytorch版本
赞
踩
前言
使用Pytorch实现mnist数字手写体识别
1.mnist数据集
数据集官网:https://yann.lecun.com/exdb/mnist/
数据集全部由0~9的手写数字组成,共有训练集60000张手写数字照片,测试集10000张照片。所有照片均为28*28的灰度图。
2.Pytorch
Pytorch是torch的python版本
3.具体代码实现
首先导入需要的库
import torch
import torchvision
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
设置超参数
在导入库之后,设置将会使用到的超参数,epochs表示训练时候重复的次数,batch_size_train = 64表示每次从60000个样本的训练集中拿出64个进行训练,batch_size_test = 1000为单次测试1000个训练集。learning_rate 和 momentum 是优化器中使用到的参数。神经网络中有两种参数,其中超参数在神经网络中的作用是保证神经网络模型在训练、阶段既不会拟合失败,也不会过度拟合,同时让网络尽可能快地学习数据结构特征。
- n_epochs = 3
- batch_size_train = 64
- batch_size_test = 1000
- learning_rate = 0.01
- momentum = 0.5
- log_interval = 10
- random_seed = 1
- torch.manual_seed(random_seed)
加载数据集
初始化超参数之后, 加载数据集,使用torchvision进行数据集的加载。 train=True or False 如果为true表示下载训练集,false表示测试集。 0.1307和0.3081分别为这组数据的平均值和标准差,由于mnist图像只是灰度图像,所以单通道,平均值和标准差都是只有一个值。在深度学习进行深度学习的时候,一般会对图形进行预处理,最常见的对图像预处理方法有两种,正常白化处理又叫图像标准化处理,另外一种方法叫做归一化处理。这里进行图像标准化处理,将图像中的像素值调整成均值为0,方差为1的分布。
- dataset = torchvision.datasets.MNIST('./data/', train=True, download=True,
- transform=torchvision.transforms.Compose([
- torchvision.transforms.ToTensor(),
- torchvision.transforms.Normalize(
- (0.1307,), (0.3081,))
- ]))
- train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size_train, shuffle=True)
- test_loader = torch.utils.data.DataLoader(
- torchvision.datasets.MNIST('./data/', train=False, download=True,
- transform=torchvision.transforms.Compose([
- torchvision.transforms.ToTensor(),
- torchvision.transforms.Normalize(
- (0.1307,), (0.3081,))
- ])),
- batch_size=batch_size_test, shuffle=True)
data.DataLoader()用法:shuffle=ture表示进行打乱
data.DataLoader(加载的数据集, 单次使用样本的大小, shuffle=True)构建网络
之后开始构建网络,网络中使用两个2d卷积层,之后是两个全连接层。使用rule作为激活函数。为防止训练过拟合,使用dropout进行正则化, dropout 避免过拟合可以理解为我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。同时两个池化层的加入同样可以防止过拟合和减少连接层中的参数大小。
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- #两个2d卷积层
- self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
- self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
- #一个dropout层
- self.conv2_drop = nn.Dropout2d()
- self.fc1 = nn.Linear(320, 50)
- self.fc2 = nn.Linear(50, 10)
-
- def forward(self, x):
- x = F.relu(F.max_pool2d(self.conv1(x), 2))
- x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
- #输入层
- x = x.view(-1, 320)
- #隐藏层
- x = self.fc1(x)
- #隐藏层的激活函数
- x = F.relu(x)
- x = F.dropout(x, training=self.training)
- #输出层
- x = self.fc2(x)
- #输出层的激活函数,返回softmax的计算值
- return F.log_softmax(x, dim=1)

网络结构为
conv2d--maxpool2d--conv2d--maxpool2d--fullyconnect--fullyconnect
输入图片大小为:28*28的单通道图片,即:1*28*28
然后分析经过每一层之后的大小
1.conv2d
- N:输出大小
- W:输入大小 28*28
- F:卷积核大小 5*5
- P:填充值的大小 0默认值
- S:步长大小 1默认值
- N=(W-F+2P)/S+1=(28-5 + 2*0)/1 + 1 = 24
- 输出为:10*24*24
2.maxpool2d
- N:输出大小
- W:输入大小 24*24
- F:卷积核大小 5*5
- P:填充值的大小 0默认值
- S:步长大小 1默认值
- N=(W-F+2P)/S+1=(24-2 + 2*0)/2 + 1 = 12
- 输出为:10*12*12
3.conv2d
- N:输出大小
- W:输入大小 12*12
- F:卷积核大小 5*5
- P:填充值的大小 0默认值
- S:步长大小 1默认值
- N=(W-F+2P)/S+1=(12-5 + 2*0)/1 + 1 = 8
- 输出为:20*8*8
4.maxpool2d
- N:输出大小
- W:输入大小 8*8
- F:卷积核大小 5*5
- P:填充值的大小 0默认值
- S:步长大小 1默认值
- N=(W-F+2P)/S+1=(8-2 + 2*0)/2 + 1 = 4
- 输出为:20*4*4
5.fully-connect Linear(320, 50)
- 输入:20*4*4=320
- 输出:50
6.fully-connect Linear(50, 10)
- 输入:50
- 输出:10
torch.nn.Conv2d使用方法
- torch.nn.Conv2d(in_channels, #输入图像的通道数
- out_channels, #代表卷积核的个数,使用C个卷积核输出的特征矩阵深度即channel就是C
- kernel_size, #代表卷积核的尺寸,输入可以是int类型,例如:3 ,代表卷积核的height
- = width = 3,也可以是tuple类型,例如(3, 5),代表卷积核的height =
- 3,width = 5
- stride=1, 代表卷积核的步距,默认为1,int or tuple(高,宽)
- padding=0, #四周补零,0不补,1补一圈零,tuple(高,宽)
- dilation=1,
- groups=1,
- bias=True,
- padding_mode='zeros'
torch.nn.Linear使用方法
- torch.nn.Linear(in_features, # 输入的神经元个数
- out_features, # 输出神经元个数
- bias=True # 是否包含偏置
- )
模型训练
初始化网络和优化器,我们创建了一个随机梯度下降优化器,并给定learning rate和momentum,learning rate控制步长,momentum用来解决梯度下降时找到局部最小值的情况。
- network = Net()
- optimizer = optim.SGD(network.parameters(), lr=learning_rate,
- momentum=momentum)
进行训练,训练过程中,首先需初始化梯度,将梯度设置为零,之后进行向前计算,计算损失,之后进行反向传播。
- def train(epoch):
- network.train()
- for batch_idx, (data, target) in enumerate(train_loader):#遍历每个batch
- #将梯度设置为零
- optimizer.zero_grad()
- #进行向前计算
- output = network(data)
- #计算损失
- loss = F.nll_loss(output, target)
- #loss.backward(),就是将损失loss 向输入侧进行反向传播,同时对于需要进行梯度计算的所有变量
- #计算梯度 ,并将其累积到梯度x.grad中备用
- loss.backward()
- #optimizer.step()是优化器对x的值进行更新,以随机梯度下降SGD为例:学习率(learning
- #rate,lr)来控制步幅
- optimizer.step()
- if batch_idx % log_interval == 0:
- print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx
- * len(data),
- len(train_loader.dataset),
- 100. * batch_idx / len(train_loader),
- loss.item()))
- train_losses.append(loss.item())
- train_counter.append((batch_idx * 64) + ((epoch - 1) *
- len(train_loader.dataset)))
- #神经网络模块以及优化器能够使用.state_dict()保存和加载它们的内部状态。
- #这样,如果需要,我们就可以继续从以前保存的状态dict中进行训练——只需调用
- #load_state_dict(state_dict)
-
- torch.save(network.state_dict(), './model.pth')
- torch.save(optimizer.state_dict(), './optimizer.pth')
进行测试循环
- def test():
- network.eval()
- test_loss = 0
- correct = 0
- with torch.no_grad():
- for data, target in test_loader:
- output = network(data)
- #计算损失
- test_loss += F.nll_loss(output, target, reduction='sum').item()
- #经过输出层的softmax激活函数之后,寻找输出层中的最大的一个
- pred = output.data.max(1, keepdim=True)[1]
- correct += pred.eq(target.data.view_as(pred)).sum()
- test_loss /= len(test_loader.dataset)
- test_losses.append(test_loss)
- print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
- test_loss, correct, len(test_loader.dataset),
- 100. * correct / len(test_loader.dataset)))
绘制训练和测试曲线
- test()
- for epoch in range(1, n_epochs+1):
- train(epoch)
- test()
- #绘制训练图像
- fig = plt.figure()
- plt.plot(train_counter, train_losses, color='blue')
- plt.scatter(test_counter, test_losses, color='red')
- plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
- plt.xlabel('number of training examples seen')
- plt.ylabel('negative log likelihood loss')
- plt.show()
训练图像
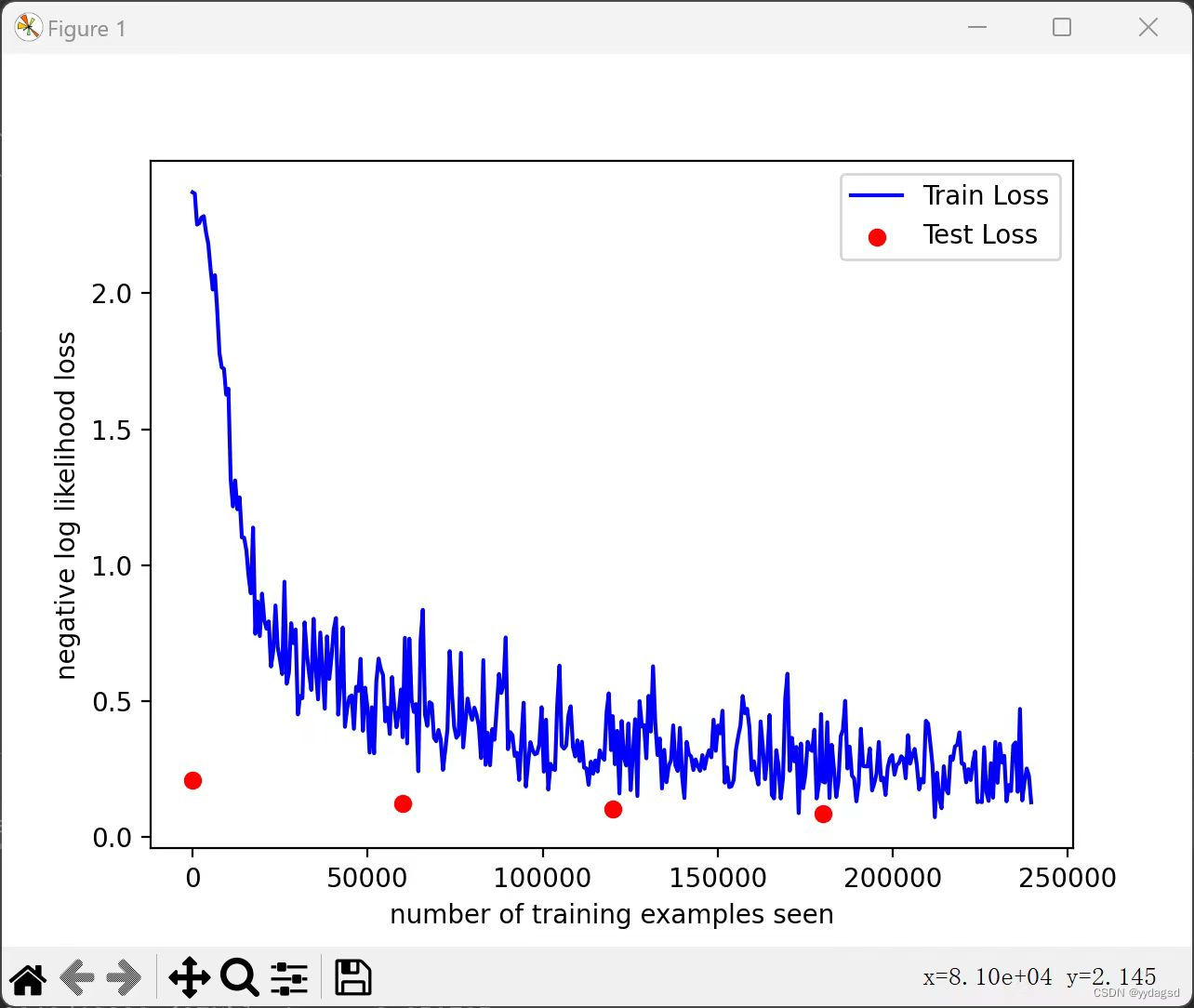
测试结果

神经网络参数固定初始化
在神经网络中,参数默认是进行随机初始化的。如果不设置的话每次训练时的初始化都是随机的,导致结果不确定。如果设置初始化,则每次初始化都是固定的。
-
- def setup_seed(seed):
- random.seed(seed)
- np.random.seed(seed)
- torch.manual_seed(seed)
- torch.cuda.manual_seed_all(seed)
- torch.backends.cudnn.deterministic = True
- torch.backends.cudnn.benchmark = False
- dgl.seed(seed)
- setup_seed(seed)

