
- 1探秘《数学之美在机器学习》:深入理解ML基石
- 2【头歌-Python】Python第三章作业(初级)(13~17)_python存款买房b答案
- 3论文AI率多少正常:揭秘学术写作中的AI使用边界
- 4Synthesizer V Studio Pro快速使用教程
- 5压缩感知常用的测量矩阵_压缩感知观测矩阵
- 6面试官问你什么B树和B+树,把这篇文章丢给他
- 7Python学习笔记(十三)——编译错误和异常处理_如果python程序中包括零除运算
- 8[开题报告]Springboot电子商城的设计与实现710y1计算机毕业设计_基于springboot的球鞋商城的开题报告
- 9算法导论17.1-3_算法导论17.3-3
- 10Gpt详解_gpt操作手册
Quivr 基于GPT和开源LLMs构建本地知识库 (更新篇)_quivr本地知识库
赞
踩
一、前言
自从大模型被炒的越来越火之后,似乎国内涌现出很多希望基于大模型构建本地知识库的需求,大概在5月底的时候,当时Quivr发布了第一个0.0.1版本,第一个版本仅仅只是使用LangChain技术结合OpenAI的GPT模型实现了一个最基本的架子,功能并不够完善,但可以研究研究思路,当时 Quivr 通过借助于GPT的模型能力,选择Supabase构建向量数据库来实现个人知识库还算是一个不错的选择,自此一直有在关注 Quivr 的进展,基本上Quivr的更新频率还是比较高的,5月底写了一篇关于如何在本地基于Quivr构建知识库的文章之后,陆陆续续基本上都有一些朋友私聊询问有关Quivr构建的一些问题,也有一些对于Quivr未来功能规划方向的建议和期望,如果Quivr发展的比较成熟,对于个人或者中小企业或许也是一个低成本的选择。
随着这两个多月的更新,Quivr已经陆续发布了五十多个版本,不管是对原来功能的改进,代码的重构,还是扩展了很多新功能,都让Quivr看起来没有原来那么弱小了,基础的功能基本上也覆盖到了。感兴趣的可以尝试一下。
对于原来发布的文章和视频,有感兴趣的可以从下面的链接进去,因为Quivr一直在更新,在部署方面可能有些许变化,如果想部署最新版本的Quivr,可以直接看这篇最新的升级篇即可。
二、功能特性
2.1、大脑扩展能力
从单个账号只支持一个大脑,到现在可以支持多个大脑(具体数量可以配置,默认为5个),这样部署一套Quivr系统就可以创建多个大脑来对知识库进行分开维护,减少数据的检索范围和数据权限隔离。
用户可以根据偏好来自定义知识库,比如针对产品的智能客服、针对交付的Q&A助理、产品经理助手等等。
2.2、大脑权限控制
支持对单个知识库根据[浏览]、[编辑]、[所有者]三个角色来设置对应的访问权限,同时也支持通过链接和邮件的方式分享个人大脑给其他用户。
这样就可以很方便的实现个人私有知识库,或者是公司团队共享的知识库,而避免了以前每个用户都需要重复上传相同的知识,导致Key的浪费和知识的冗余。
2.3、LLM扩展能力
原来的版本只支持集成GPT和Claude模型,现在扩展了对本地开源模型的支持,如GPT4All,后续还将支持更多的开源模型。
2.4、开放API接口
Quivr采用前后端分离的独立架构,Quivr 使用 FastAPI 为后端提供 RESTful API,后端服务可以独立使用,不需要前端应用程序,我们的第三方应用也可以很方便的通过API接口集成Quivr大脑的我们自己的产品中
三、基础环境准备
3.1、先决条件
为了减少部署过程中不必要的麻烦,建议操作系统选择Ubuntu 22或更高版本,至于服务器只要能正常访问OpenAI的接口都可以,我在GCP/AWS/阿里云上都安装过,主要解决网络问题,选对服务器所在区域即可。
系统内存:如果只是个人用来部署玩一下,建议不少于1GB,2GB比较合适,如果想用于正式环境,则需根据具体的业务访问量配置。
系统硬盘:仅仅部署演示,建议不少于30GB。
接下来将演示在 Ubuntu 22 版本上快速部署Quivr来构建本地知识库系统。
3.2、安装Docker & Docker-Compose
首先安装 Docker 和 Docker Compose ,可以按照以下步骤进行操作:
1、更新系统软件包列表:
sudo apt update
2、安装Docker依赖的软件包:
sudo apt install apt-transport-https ca-certificates curl software-properties-common
3、添加Docker官方的GPG密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
4、添加Docker的软件源:
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
5、更新软件包列表:
sudo apt update
6、安装Docker Engine:
sudo apt install docker-ce docker-ce-cli containerd.io
7、验证Docker是否正确安装:
sudo docker run hello-world
8、安装Docker Compose:
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
9、添加执行权限:
sudo chmod +x /usr/local/bin/docker-compose
10、验证Docker Compose是否正确安装:
docker-compose --version
现在,您已经成功在Ubuntu上安装了Docker和Docker Compose。您可以使用这些命令来管理和运行容器化的应用程序。
错误:failed to update store for object type *libnetwork.endpointCnt: Key not found in store
- Restart docker deamon would fix it.
-
- For ubuntu:
-
- sudo service docker restart
四、创建Supabase项目
Supabase是一个开源的Firebase替代品。使用 Postgres 数据库、身份验证、即时 API、边缘函数、实时订阅、存储和向量嵌入。一个免费账户可以创建2个项目。
1、注册账户
前往https://supabase.com/可以注册免费账户。
2、创建项目

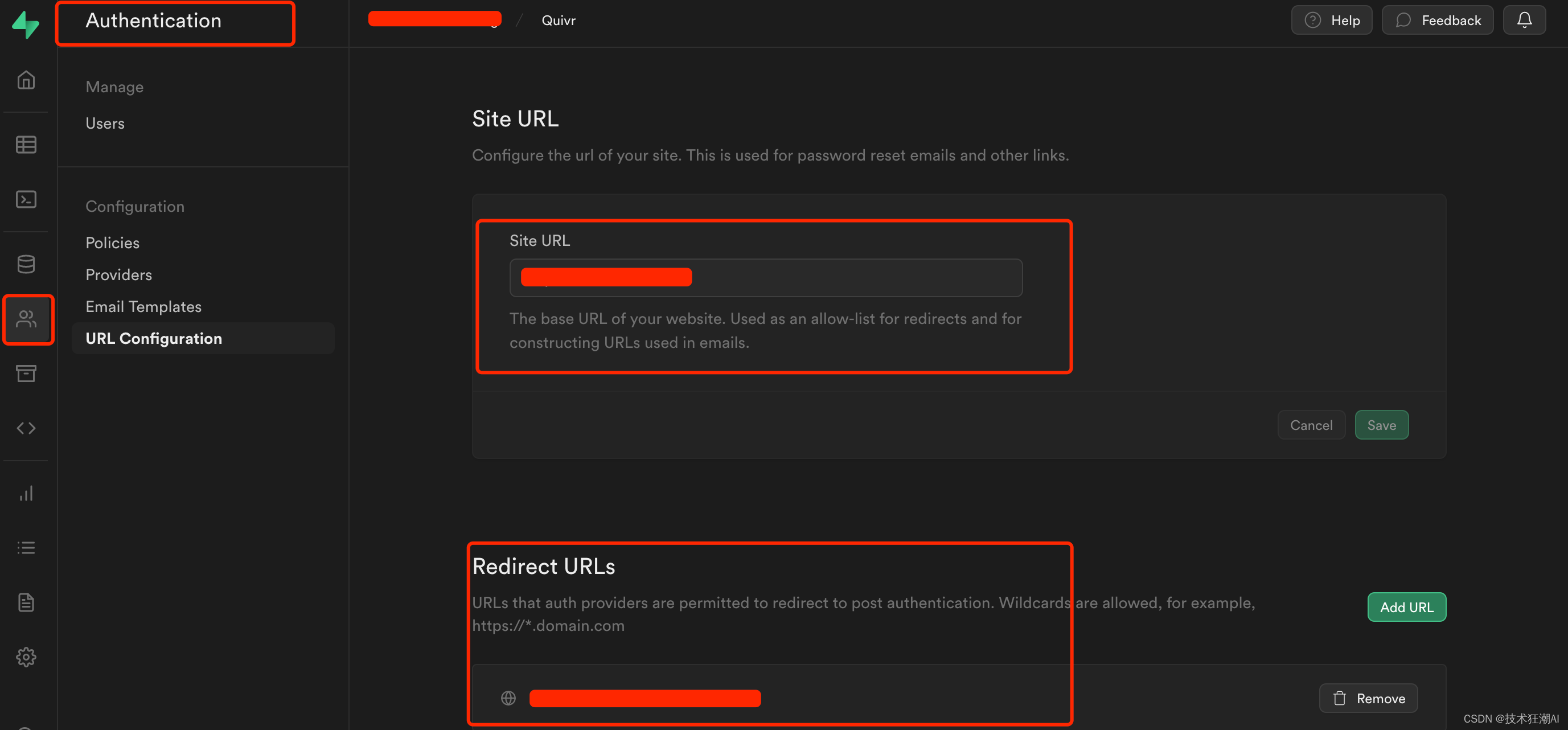
3、配置网站URL和重定向地址
主要用于密码重置和电子邮件重定向跳转链接。地址为系统前端访问地址:http://ip:3000
五、部署Quivr应用
5.1、克隆存储库
git clone https://github.com/StanGirard/Quivr.git && cd Quivr
- 可以使用 ls -alh 命令查看所有文件(包含隐藏文件)
一般Quivr每周都会在主分支更新新的内容,会存在一定未知的bug,建议选择一个最新的release稳定版本进行部署

5.2、复制.XXXXX_env文件
新版本后端代码重构了,新的配置文件注意在backend/core/目录下面。
- cp .backend_env.example backend/core/.env
- cp .frontend_env.example frontend/.env
5.3、更新frontend/.env文件
- NEXT_PUBLIC_ENV=local
- NEXT_PUBLIC_BACKEND_URL=http://你的IP:5050/
- NEXT_PUBLIC_SUPABASE_URL=your supabase project url
- NEXT_PUBLIC_SUPABASE_ANON_KEY=your supabase api key
- NEXT_PUBLIC_JUNE_API_KEY=your june api key
请注意,如果Quivr部署在本机电脑,backend_url直接使用localhost,如果Quivr部署在本地服务器或者云服务器则需要将后端URL修改为你服务器的实际的IP地址。(很多人会忽略这个配置!)
关于NEXT_PUBLIC_JUNE_API_KEY属性的配置说明:
Quivr 集成了 June Analytics 提供的API接口,在集成了June Analytics 之后,你只需要在系统中配置正确的June API密钥(即June key),然后June网站会自动开始收集和跟踪系统的数据。
一旦数据开始被收集,你可以登录到June Analytics的仪表板,并在其中查看和分析收集到的数据。June仪表板提供了一个用户友好的界面,用于浏览各种报告、图表和指标,以便你了解用户行为、事件触发和其他关键指标。
通过June仪表板,你可以探索不同的分析视图,如用户活动、事件追踪、转化率等。你可以根据时间范围、特定用户或自定义事件来过滤和细化数据,以获取更具体的见解和洞察。
如果是正式上线的站点,可以按需选择接入,默认可以不用考虑设置此参数,如果需要收集和分析网站的数据,可以去注册June账号,申请一个June Key:
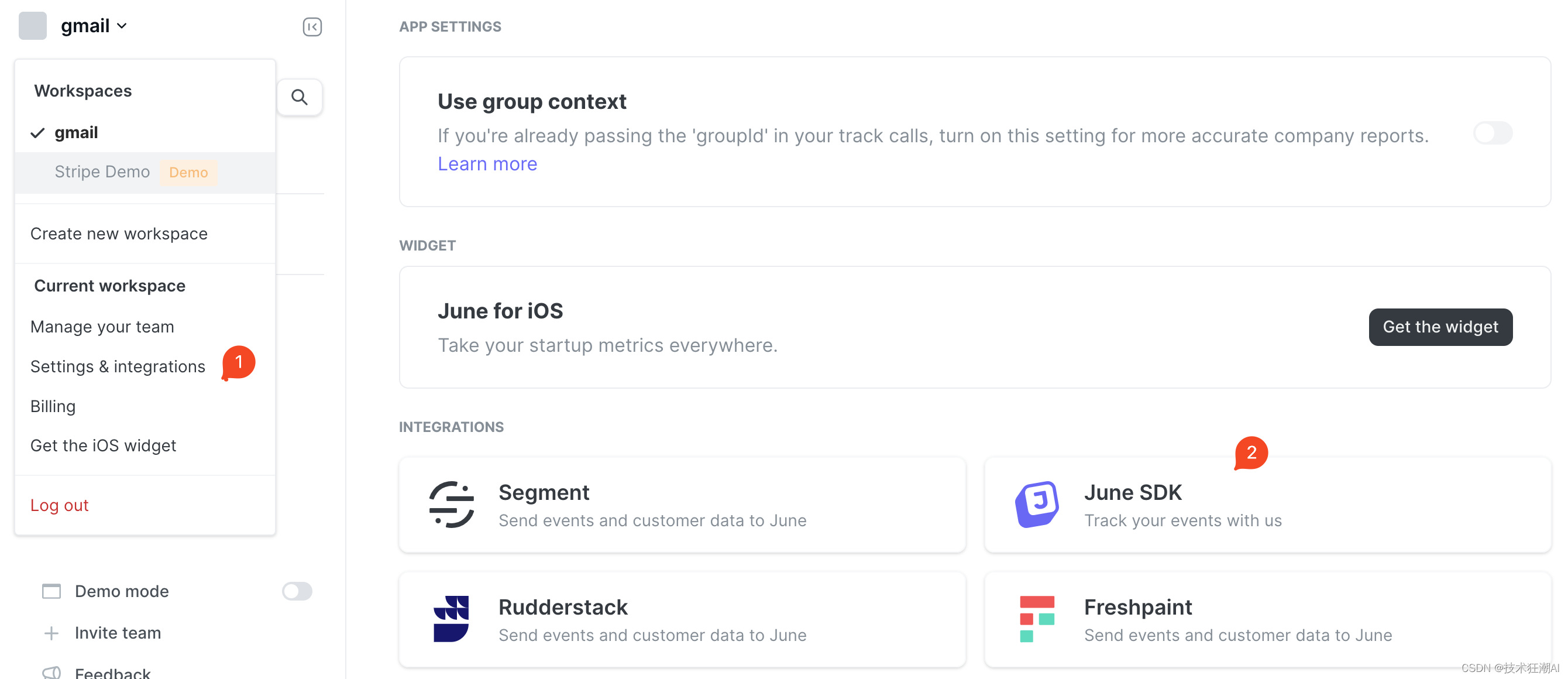
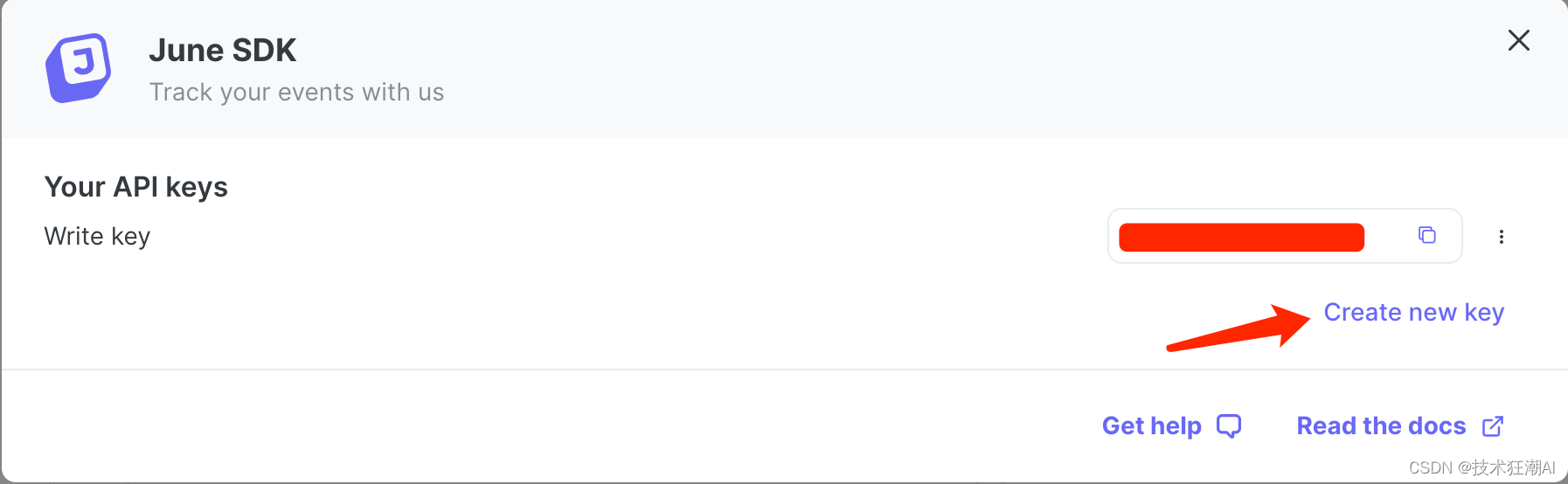 5.4、更新backend/core/.env文件
5.4、更新backend/core/.env文件
- SUPABASE_URL=your supabase project url
- SUPABASE_SERVICE_KEY=your supabase api key
- PG_DATABASE_URL=notimplementedyet
- OPENAI_API_KEY=your openai api key
- ANTHROPIC_API_KEY=null
- JWT_SECRET_KEY=your supabase jwt secret key
-
- AUTHENTICATE=true
- GOOGLE_APPLICATION_CREDENTIALS=<change-me>
- GOOGLE_CLOUD_PROJECT=<change-me>
-
- # 默认50M
- MAX_BRAIN_SIZE=52428800.
- MAX_REQUESTS_NUMBER=2000
- MAX_BRAIN_PER_USER=100
-
- # Private LLM Variables
- PRIVATE=False
- MODEL_PATH=./local_models/ggml-gpt4all-j-v1.3-groovy.bin
-
- # RESEND
- RESEND_API_KEY=your resend api key
- RESEND_EMAIL_ADDRESS=your resend email address

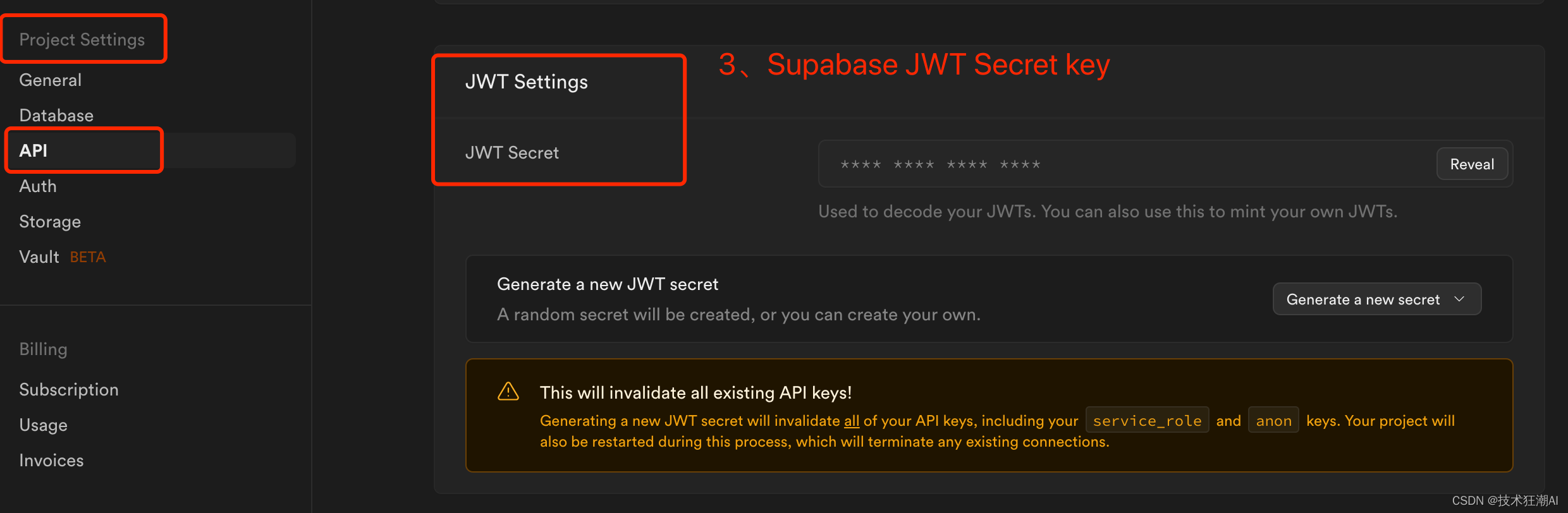
请注意,supabase_url在您的Supabase仪表板下的项目设置-> API中对应的Project URL,supabase_service_key在您的Supabase仪表板下的项目设置-> API中找到。使用“Project API keys”部分中找到的anon public键。您 JWT_SECRET_KEY可以在 Project Settings -> JWT Settings -> JWT Secret 下的 supabase 设置中找到。(注意ANTHROPIC_API_KEY可以不配置值,但key不能删除,否则构建会失败)

5.5、创建Supabase数据库和表
通过Web界面(SQL编辑器->“New Query”)在Supabase数据库上运行以下迁移脚本。
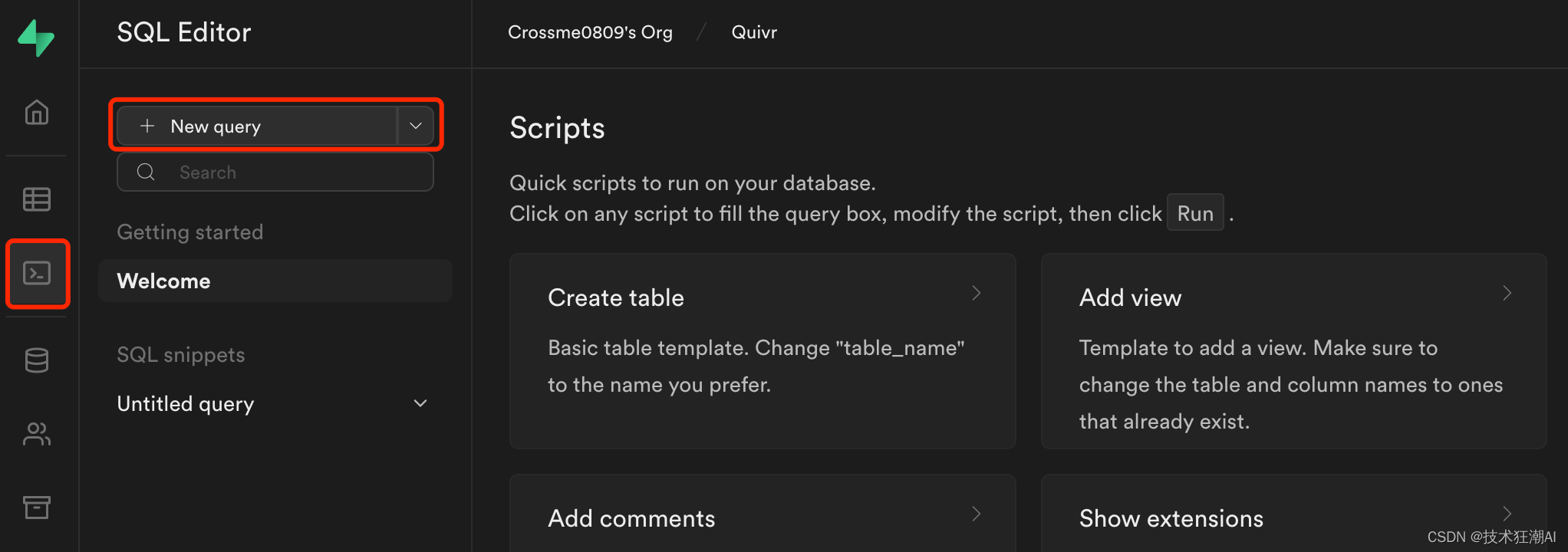
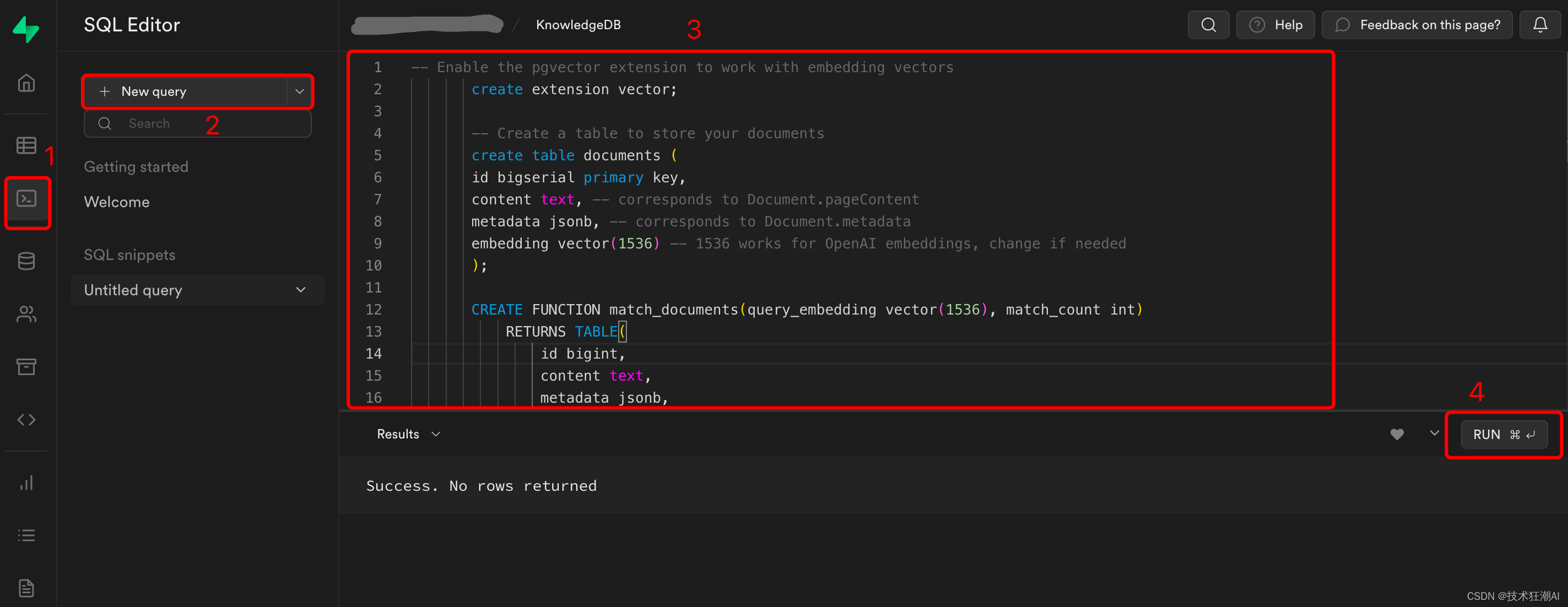
数据库脚本地址:
https://github.com/StanGirard/quivr/blob/main/scripts/tables.sql
- -- Create users table
- CREATE TABLE IF NOT EXISTS users(
- user_id UUID REFERENCES auth.users (id),
- email TEXT,
- date TEXT,
- requests_count INT,
- PRIMARY KEY (user_id, date)
- );
-
- -- Create chats table
- CREATE TABLE IF NOT EXISTS chats(
- chat_id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
- user_id UUID REFERENCES auth.users (id),
- creation_time TIMESTAMP DEFAULT current_timestamp,
- history JSONB,
- chat_name TEXT
- );
-
-
- -- Create vector extension
- CREATE EXTENSION IF NOT EXISTS vector;
-
- -- Create vectors table
- CREATE TABLE IF NOT EXISTS vectors (
- id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
- content TEXT,
- metadata JSONB,
- embedding VECTOR(1536)
- );
-
- -- Create function to match vectors
- CREATE OR REPLACE FUNCTION match_vectors(query_embedding VECTOR(1536), match_count INT, p_brain_id UUID)
- RETURNS TABLE(
- id UUID,
- brain_id UUID,
- content TEXT,
- metadata JSONB,
- embedding VECTOR(1536),
- similarity FLOAT
- ) LANGUAGE plpgsql AS $$
- #variable_conflict use_column
- BEGIN
- RETURN QUERY
- SELECT
- vectors.id,
- brains_vectors.brain_id,
- vectors.content,
- vectors.metadata,
- vectors.embedding,
- 1 - (vectors.embedding <=> query_embedding) AS similarity
- FROM
- vectors
- INNER JOIN
- brains_vectors ON vectors.id = brains_vectors.vector_id
- WHERE brains_vectors.brain_id = p_brain_id
- ORDER BY
- vectors.embedding <=> query_embedding
- LIMIT match_count;
- END;
- $$;
-
- -- Create stats table
- CREATE TABLE IF NOT EXISTS stats (
- time TIMESTAMP,
- chat BOOLEAN,
- embedding BOOLEAN,
- details TEXT,
- metadata JSONB,
- id INTEGER PRIMARY KEY GENERATED ALWAYS AS IDENTITY
- );
-
- -- Create summaries table
- CREATE TABLE IF NOT EXISTS summaries (
- id BIGSERIAL PRIMARY KEY,
- document_id UUID REFERENCES vectors(id),
- content TEXT,
- metadata JSONB,
- embedding VECTOR(1536)
- );
-
- -- Create function to match summaries
- CREATE OR REPLACE FUNCTION match_summaries(query_embedding VECTOR(1536), match_count INT, match_threshold FLOAT)
- RETURNS TABLE(
- id BIGINT,
- document_id UUID,
- content TEXT,
- metadata JSONB,
- embedding VECTOR(1536),
- similarity FLOAT
- ) LANGUAGE plpgsql AS $$
- #variable_conflict use_column
- BEGIN
- RETURN QUERY
- SELECT
- id,
- document_id,
- content,
- metadata,
- embedding,
- 1 - (summaries.embedding <=> query_embedding) AS similarity
- FROM
- summaries
- WHERE 1 - (summaries.embedding <=> query_embedding) > match_threshold
- ORDER BY
- summaries.embedding <=> query_embedding
- LIMIT match_count;
- END;
- $$;
-
- -- Create api_keys table
- CREATE TABLE IF NOT EXISTS api_keys(
- key_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
- user_id UUID REFERENCES auth.users (id),
- api_key TEXT UNIQUE,
- creation_time TIMESTAMP DEFAULT current_timestamp,
- deleted_time TIMESTAMP,
- is_active BOOLEAN DEFAULT true
- );
-
- --- Create prompts table
- CREATE TABLE IF NOT EXISTS prompts (
- id UUID DEFAULT uuid_generate_v4() PRIMARY KEY,
- title VARCHAR(255),
- content TEXT,
- status VARCHAR(255) DEFAULT 'private'
- );
-
- --- Create brains table
- CREATE TABLE IF NOT EXISTS brains (
- brain_id UUID DEFAULT gen_random_uuid() PRIMARY KEY,
- name TEXT NOT NULL,
- status TEXT,
- description TEXT,
- model TEXT,
- max_tokens INT,
- temperature FLOAT,
- openai_api_key TEXT,
- prompt_id UUID REFERENCES prompts(id)
- );
-
-
- -- Create chat_history table
- CREATE TABLE IF NOT EXISTS chat_history (
- message_id UUID DEFAULT uuid_generate_v4(),
- chat_id UUID REFERENCES chats(chat_id),
- user_message TEXT,
- assistant TEXT,
- message_time TIMESTAMP DEFAULT current_timestamp,
- PRIMARY KEY (chat_id, message_id),
- prompt_id UUID REFERENCES prompts(id),
- brain_id UUID REFERENCES brains(brain_id)
- );
-
- -- Create brains X users table
- CREATE TABLE IF NOT EXISTS brains_users (
- brain_id UUID,
- user_id UUID,
- rights VARCHAR(255),
- default_brain BOOLEAN DEFAULT false,
- PRIMARY KEY (brain_id, user_id),
- FOREIGN KEY (user_id) REFERENCES auth.users (id),
- FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
- );
-
- -- Create brains X vectors table
- CREATE TABLE IF NOT EXISTS brains_vectors (
- brain_id UUID,
- vector_id UUID,
- file_sha1 TEXT,
- PRIMARY KEY (brain_id, vector_id),
- FOREIGN KEY (vector_id) REFERENCES vectors (id),
- FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
- );
-
- -- Create brains X vectors table
- CREATE TABLE IF NOT EXISTS brain_subscription_invitations (
- brain_id UUID,
- email VARCHAR(255),
- rights VARCHAR(255),
- PRIMARY KEY (brain_id, email),
- FOREIGN KEY (brain_id) REFERENCES brains (brain_id)
- );
-
- --- Create user_identity table
- CREATE TABLE IF NOT EXISTS user_identity (
- user_id UUID PRIMARY KEY,
- openai_api_key VARCHAR(255)
- );
-
-
- CREATE OR REPLACE FUNCTION public.get_user_email_by_user_id(user_id uuid)
- RETURNS TABLE (email text)
- SECURITY definer
- AS $$
- BEGIN
- RETURN QUERY SELECT au.email::text FROM auth.users au WHERE au.id = user_id;
- END;
- $$ LANGUAGE plpgsql;
-
-
- CREATE OR REPLACE FUNCTION public.get_user_id_by_user_email(user_email text)
- RETURNS TABLE (user_id uuid)
- SECURITY DEFINER
- AS $$
- BEGIN
- RETURN QUERY SELECT au.id::uuid FROM auth.users au WHERE au.email = user_email;
- END;
- $$ LANGUAGE plpgsql;
-
-
-
- CREATE TABLE IF NOT EXISTS migrations (
- name VARCHAR(255) PRIMARY KEY,
- executed_at TIMESTAMPTZ DEFAULT current_timestamp
- );
-
- INSERT INTO migrations (name)
- SELECT '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
- WHERE NOT EXISTS (
- SELECT 1 FROM migrations WHERE name = '20230809154300_add_prompt_id_brain_id_to_chat_history_table'
- );
数据库脚本执行完成后,在Table编辑器中可以看到已经创建完成的表。

5.6、设置yarn的超时时间
在前端容器构建依赖阶段一般会比较慢,部分依赖可能由于网络原因长时间无法完成会导致yarn连接超时,旧版本可以在/frontend/Dockerfile文件中修改yarn install部分的脚本,增加网络超时参数,新版本已增加该参数可忽略此步骤。
RUN yarn install --network-timeout 1000000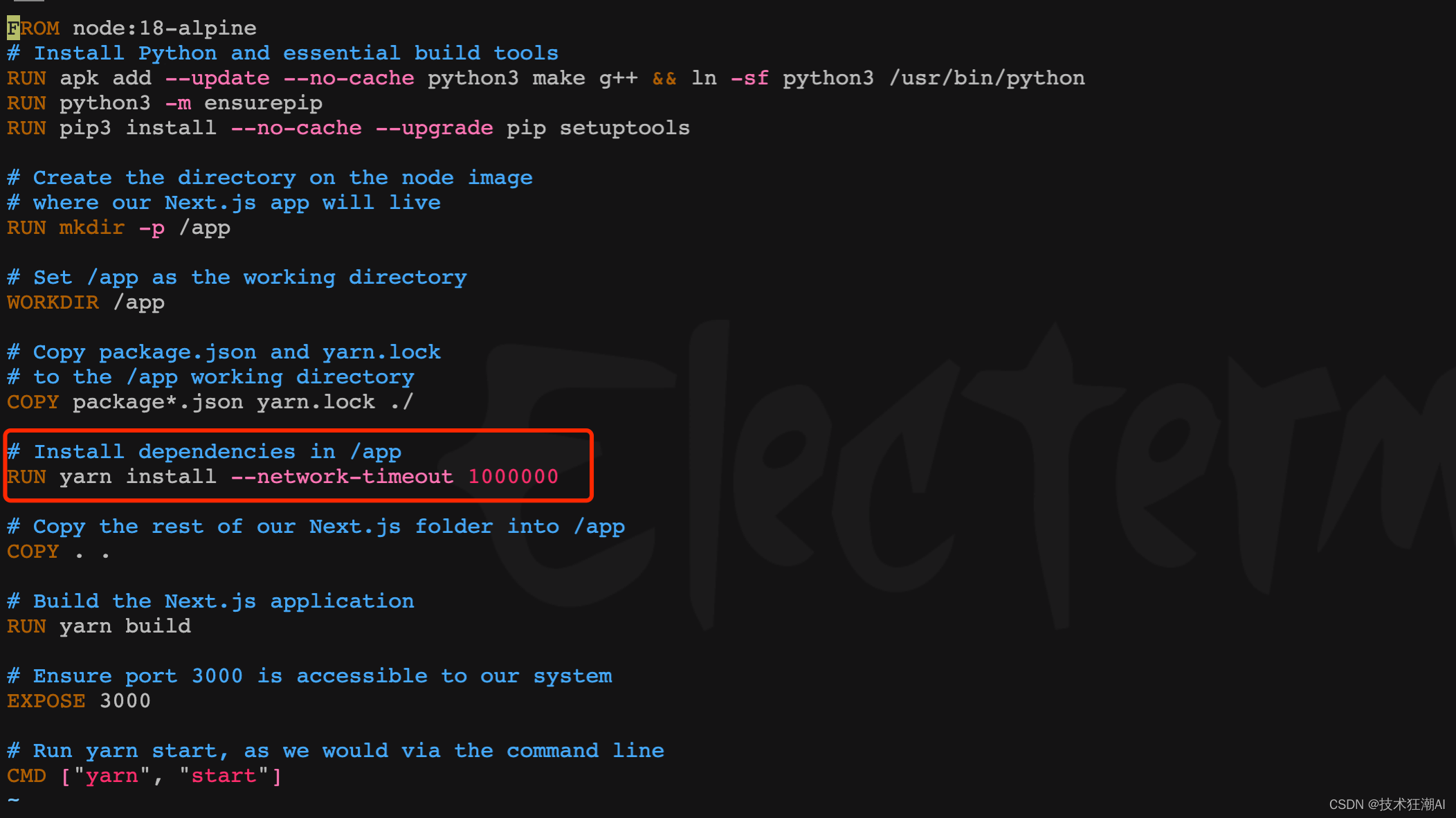
5.7、构建并启动Quivr
docker compose -f docker-compose.yml up --build -dQuivr构建完成启动后如下图所示:

六、访问Quivr
部署完成后,直接访问 http://ip:3000,第一次部署可以通过邮箱注册账号
6.1、添加新大脑
Quivr 有一个“大脑”的概念。它们是封闭的信息体,可用于为大型语言模型 (LLM) 提供上下文,以回答有关特定主题的问题。
LLM接受过各种各样的数据培训,但要回答有关特定主题的问题或用于围绕特定主题进行推论,需要向他们提供该主题的上下文。Quivr 使用大脑作为提供上下文的直观方式。
当在 Quivr 中选择大脑时,LLM将仅获得该大脑的上下文。这允许用户为特定主题构建大脑,然后用它们来回答有关该主题的问题。未来 Quivr 将会有与其他用户共享大脑的功能。
在Quivr新版本中,可以支持创新多个知识库大脑,实现知识库的内容检索隔离,同时还支持对支持库进行授权,只允许授权用户才能访问,也可以通过分享链接的方式共享知识库。比几个月前的版本功能更加完善。
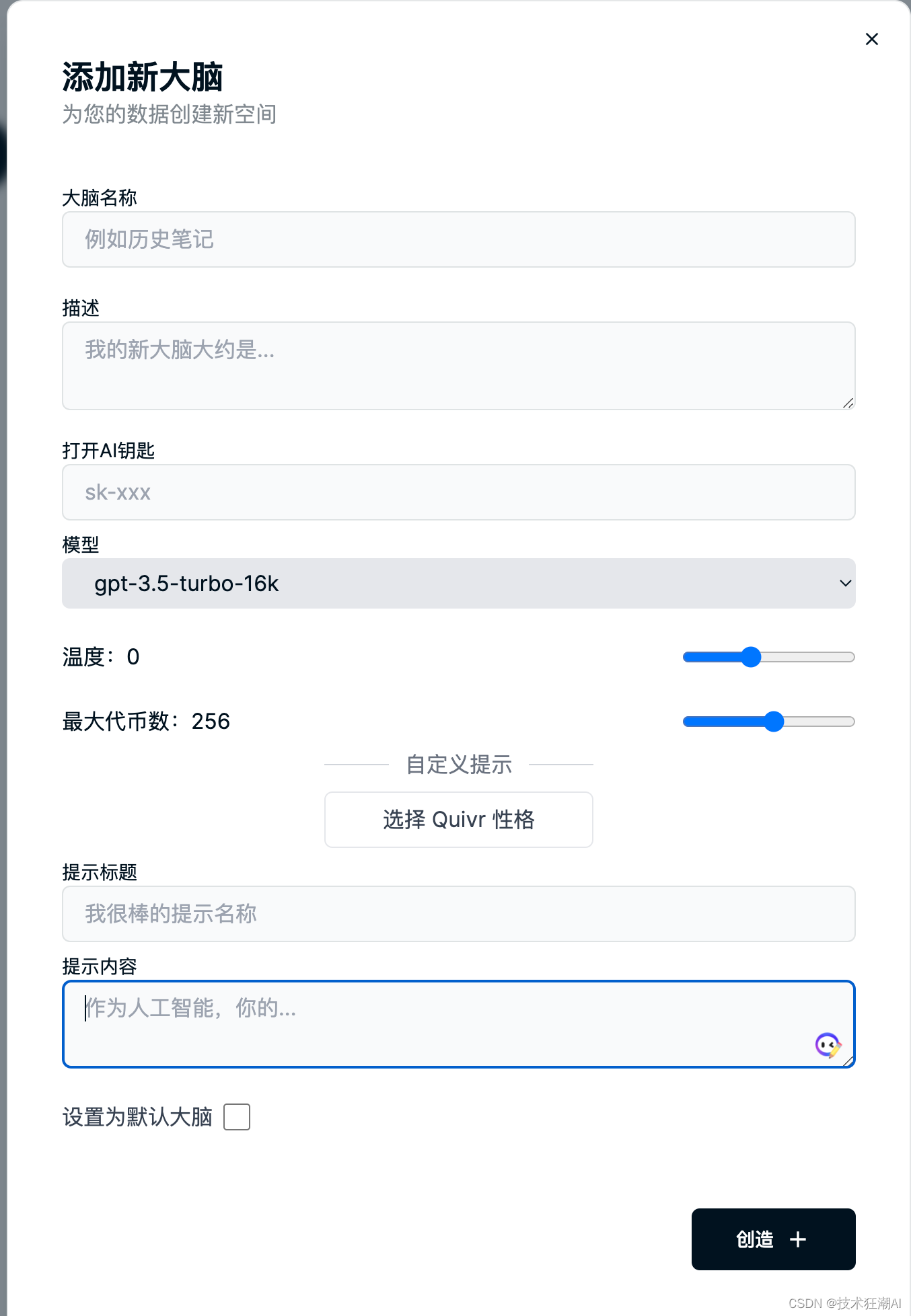
1)、要使用大脑,只需从 Quivr 界面右上角标题中的“使用大脑”图标中选择菜单即可。
2)、我们可以通过单击“创建大脑”按钮来创建一个新的大脑。系统将提示您输入大脑的名称。你也可以使用账户生成的默认大脑。
3)、要切换到不同的大脑,只需单击菜单中的大脑名称并选择您想要使用的大脑即可。
4)、如果你没有选择大脑,则你上传的任何文档都将添加到默认大脑中。
5)、在新建大脑知识库界面中,可以设置使用的模型和模型相关参数,同时也可以针对每个知识库大脑设置独有的Prompt以及所使用的OpenAI API Key,不设置则默认读取配置文件中配置的Key。
注意:如果在使用聊天功能时,需要从菜单中先选择一个大脑才能使用聊天功能。
6.2、共享知识库
在选择大脑界面,我们点击大脑后面的分享按钮,通过URL或者发邮件的方式分享或者邀请其它用户加入大脑,共享知识库。
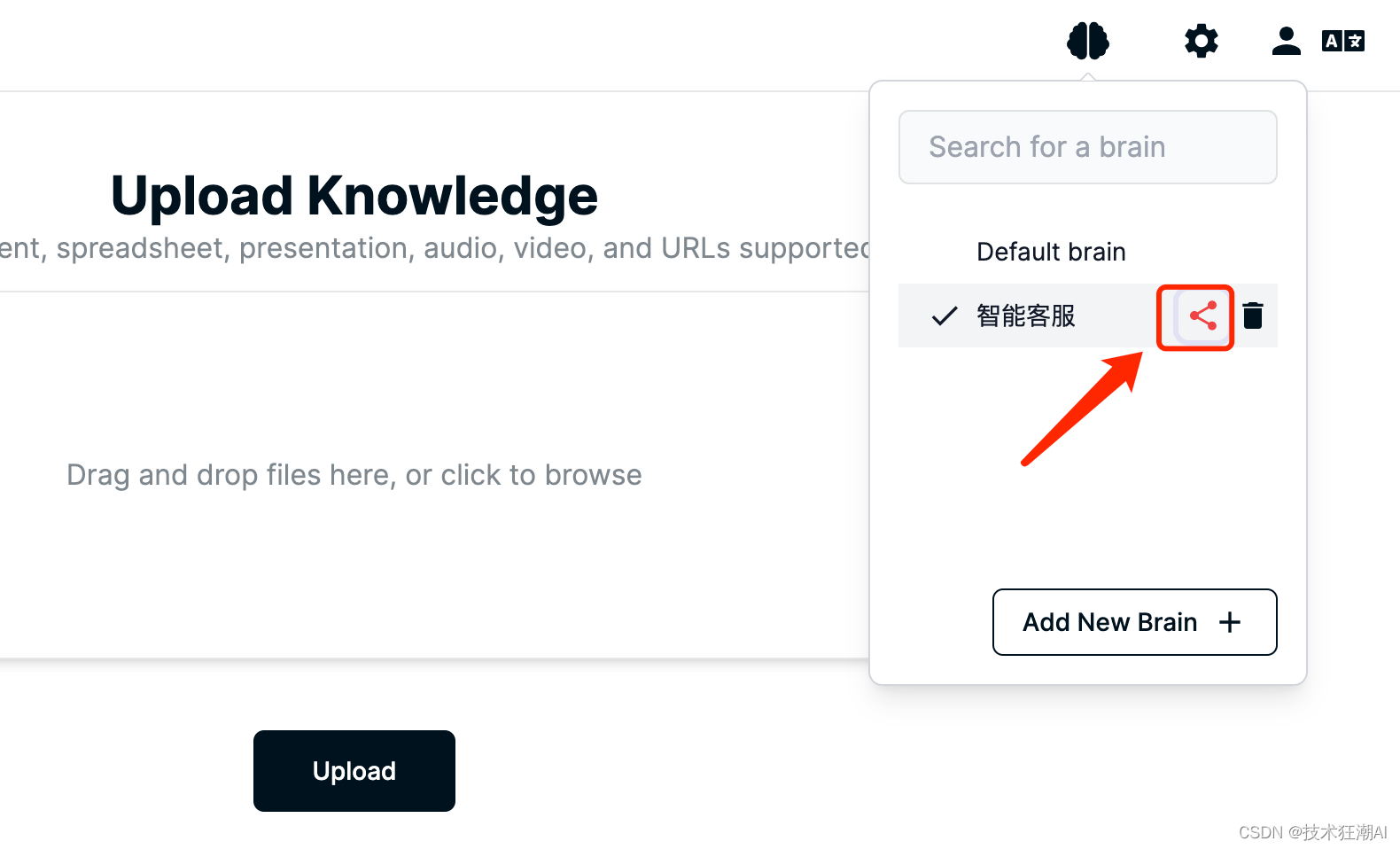

Quivr 中通过集成 Resend API,用于通过电子邮件邀请来处理共享大脑。
在 /backend/core/.env 文件中引入了两个环境变量来配置发送邮件的功能:
-
RESENDAPIKEY:这是 Resend 为我们的应用程序提供的唯一 API 密钥。它使我们能够以安全的方式与 Resend 平台进行通信。
-
RESENDEMAILADDRESS:这是我们通过重新发送发送电子邮件时用作发件人地址的电子邮件地址。
从环境变量中获取 Resend API 密钥和电子邮件地址后,我们使用它通过 resend.Emails.send 方法发送电子邮件。
6.2、上传知识库
新建完知识库大脑后,就可以选择对应的知识库,上传文档构建向量数据了,支持文档、音频、视频和网页链接,所有文件最终都会抽取文件中的文本内容通过调用大模型的API构建向量数据。
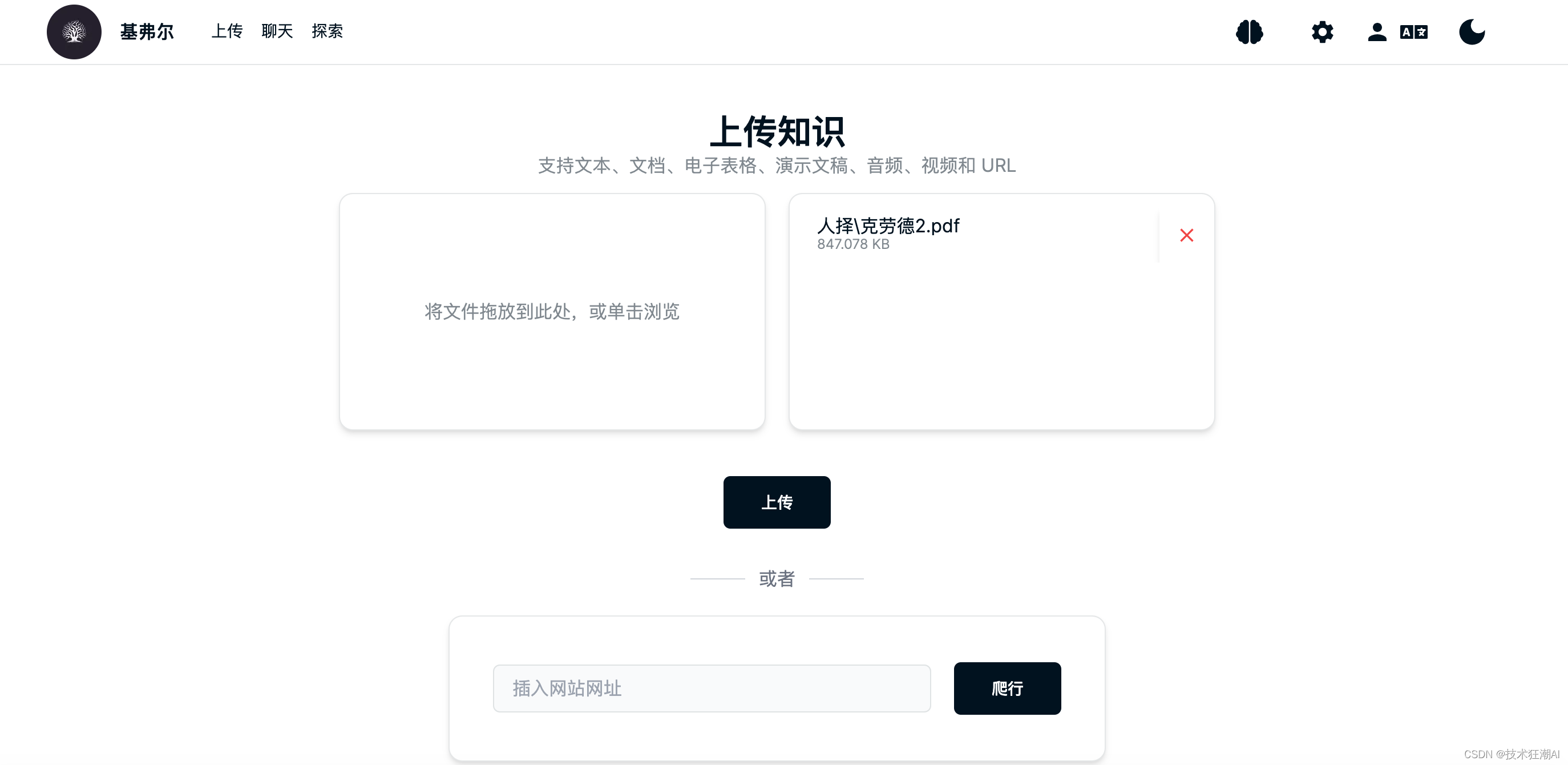
文件上传完成后,会有如下提示信息

6.3、查询知识库
知识库文档构建完成后,就可以对当前选择的知识库大脑进行内容检索了,这里我们以鲁迅先生在日本留学的老师藤野先生为例来测试一下Quivr是否正确识别了知识库文档的内容。 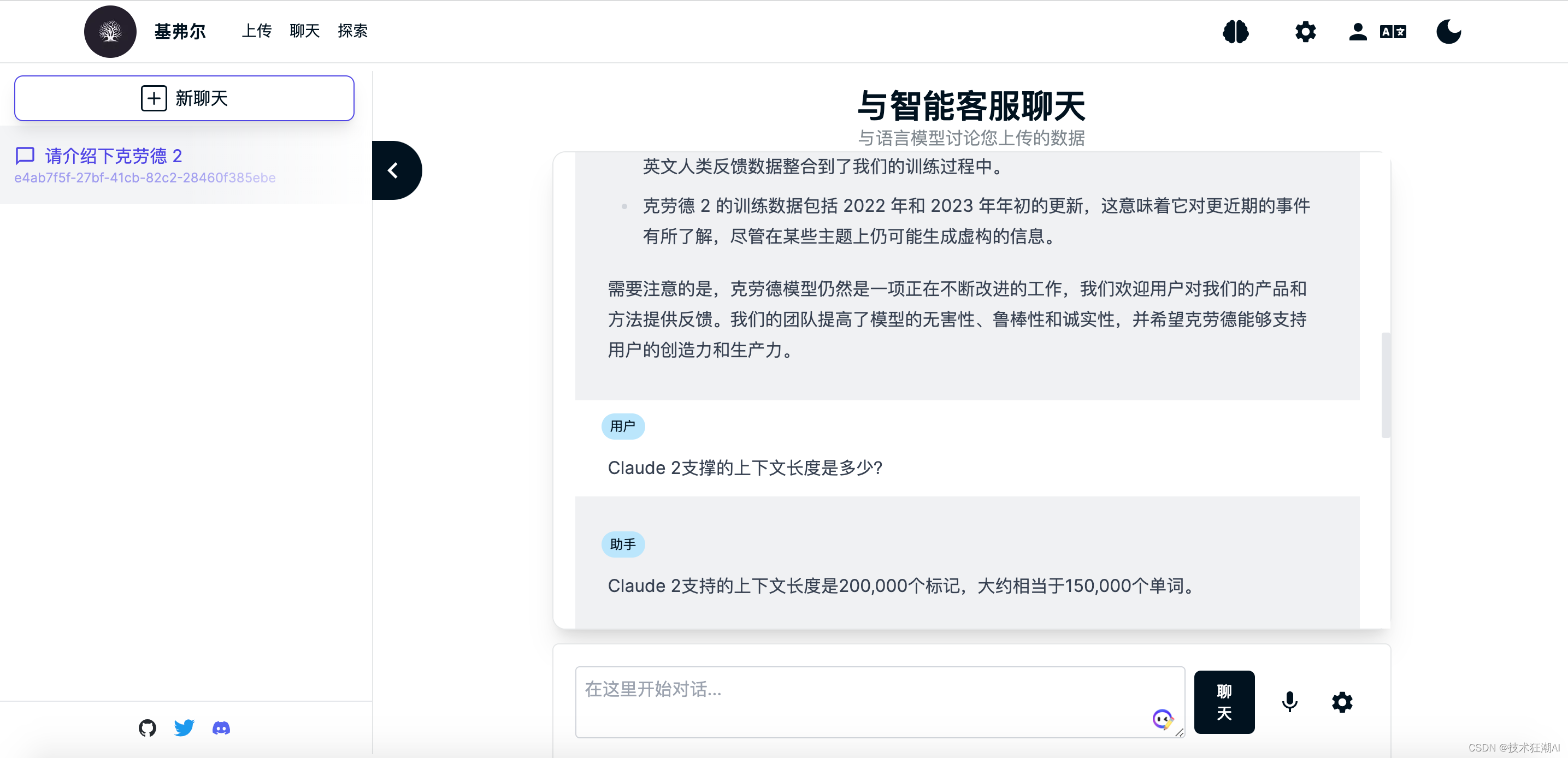
在没学习专有知识之前,GPT模型不知道鲁迅先生在日本学医的老师是谁,一般会胡乱给出一个日本人的名字,而且多次询问,人命还不一致。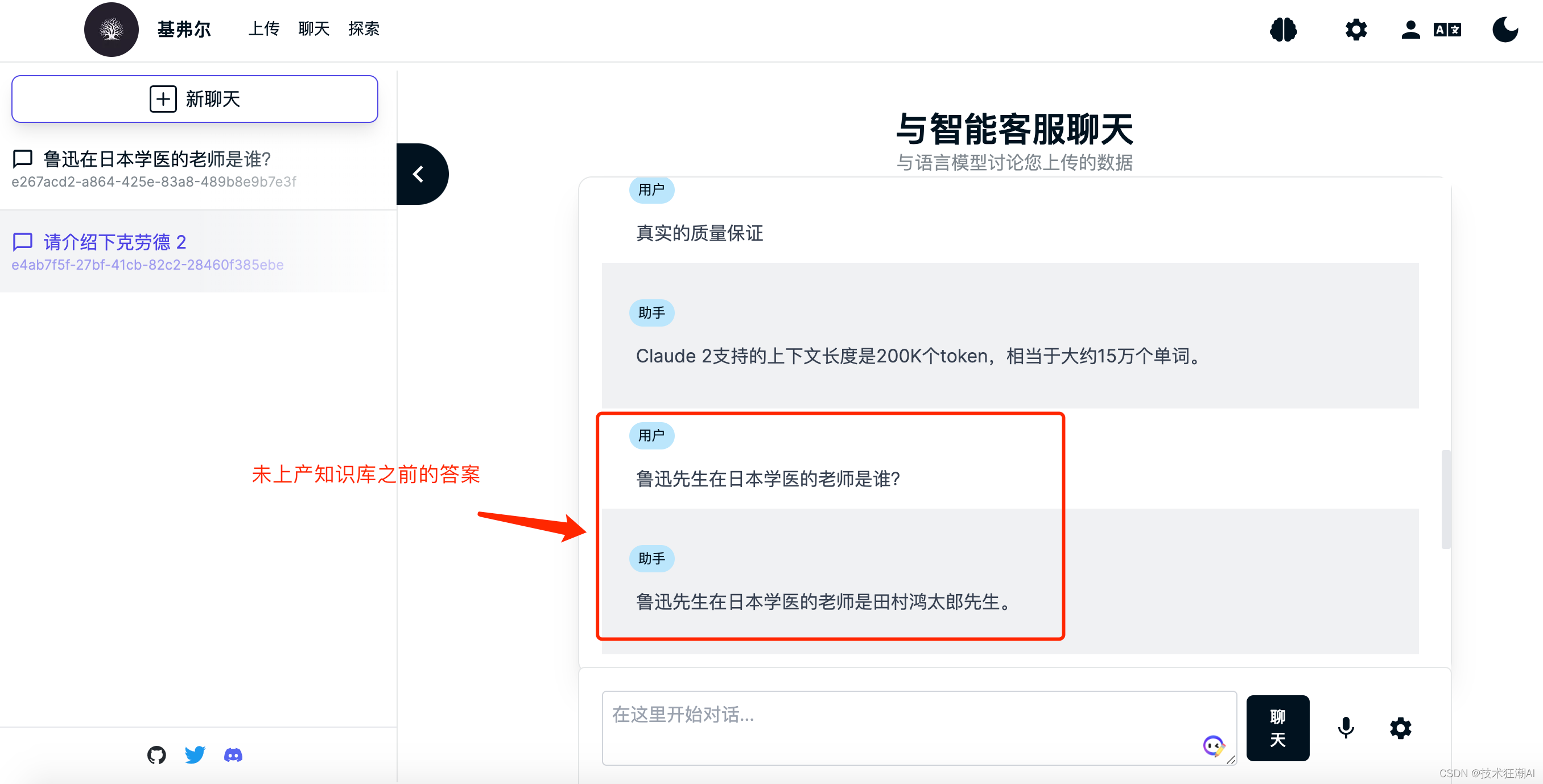 在上传完关于鲁迅先生写的《藤野先生》部分文章内容之后,我们再次询问发现可以成功检索正确的答案了。
在上传完关于鲁迅先生写的《藤野先生》部分文章内容之后,我们再次询问发现可以成功检索正确的答案了。 
七、本地化LLM支持
Quivr 在0.0.46版本可以正式支持接入本地LLM大模型,目前只支持由 GPT4All 提供支持的私有 LLM 模型(其他开源模型即将推出),基本上与 PrivateGPT 项目提供的功能类似。意味着你的数据永远存储在本地。LLM 将下载到服务器并在本地对你的问题运行推理。
7.1、使用方法
-
在 /backend/core/.env 文件中将“private”属性设置为 True。您还可以在 .env 文件中设置其他模型参数。
-
GPT4All 模型下载地址:https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
将下载的 GPT4All 模型放在 /backend/local_models 文件夹中。
GPT4All 是一个开源软件生态系统,允许任何人在日常硬件上训练和部署强大且定制的大型语言模型 (LLM)。 Nomic AI 负责监督对开源生态系统的贡献,确保质量、安全性和可维护性。
GPT4All 软件生态系统与以下 Transformer 架构兼容:
-
Falcon -
LLaMA(includingOpenLLaMA) -
MPT(includingReplit) -
GPT-J -
Replit - 基于 Replit Inc. 的 Replit 架构
-
StarCoder - 基于 BigCode 的 StarCoder 架构
具体支持的模型型号列表可以从 GPT4All 的网站上查看详尽列表,或下载任何支持的模型。使用这些架构之一训练的任何模型都可以量化,并使用所有 GPT4All 绑定在本地运行,并在聊天客户端。您可以通过为 gpt4all 后端做出贡献来添加新变体。
7.2、未来计划
Quivr 计划在本地私有化 LLM 功能中添加更多模型。使用 Hugging Face 的本地嵌入模型来减少对 OpenAI API 的依赖。未来还将添加在前端和 API 中使用私有 LLM 模型的功能。目前的版本只有部署后端才能使用。
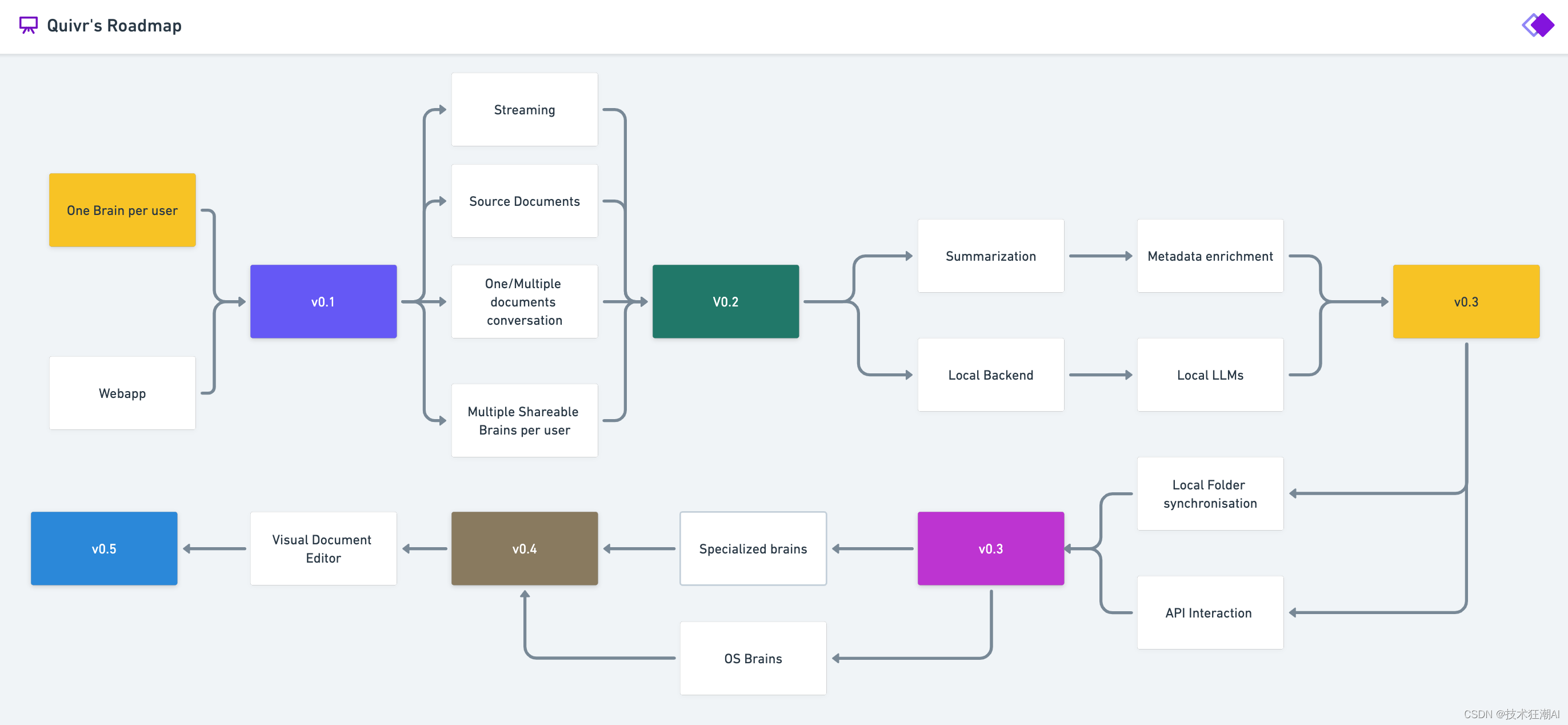
八、Quivr路线图
九、References
- Quivr GitHub
https://github.com/StanGirard/quivr
- Quivr FastAPI
https://api.quivr.app/docs
- Resend API
https://resend.com/overview
- June Analytics
https://analytics.june.so/
- GPT4All WebSite
https://gpt4all.io/index.html
- GPT4All Models
https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin
- GPT4All Supported Models
https://raw.githubusercontent.com/nomic-ai/gpt4all/main/gpt4all-chat/metadata/models.json

