
热门标签
热门文章
- 1div的布局_div布局
- 2数据结构奇妙旅程之深入解析快速排序
- 3嵌入式多媒体播放器的设计与实现
- 4C#进阶--文件操作(创建、写入、读取、删除)_c# 创建文件
- 5ABI detection failed.make sure to use a matching tool chain when building_abi检测失败:确保构建时使用一个匹配的编译器
- 6基于ssm的手机电脑电子产品维修服务微信小程序源码和论文
- 7vue-elementul右侧滚动条不显示,改变滚动条样式。elementul隐藏组件。不显示滚动条还可以滚动_vue右侧滚动条
- 8腾讯开源LaFIn生成网络基于人脸关键点修复人脸_面部关键点热图生成
- 9区块链技术简介_区块链技术资料
- 10flutter安装、配置、no devices等各种问题解决方案_flutter no device
当前位置: article > 正文
训练你自己的自然语言处理深度学习模型,Bert预训练模型下游任务训练:情感二分类_bert接下游任务参与训练
作者:Gausst松鼠会 | 2024-04-03 20:09:32
赞
踩
bert接下游任务参与训练
基础介绍:
Bert模型是一个通用backbone,可以简单理解为一个句子的特征提取工具
更直观来看:我们的自然语言是用各种文字表示的,经过编码器,以及特征提取就可以变为计算机能理解的语言了
下游任务:
提取特征后,我们便可以自定义其他自然语言处理任务了,以下是一个简单的示例(效果可能不好,但算是一个基本流程)
数据格式:
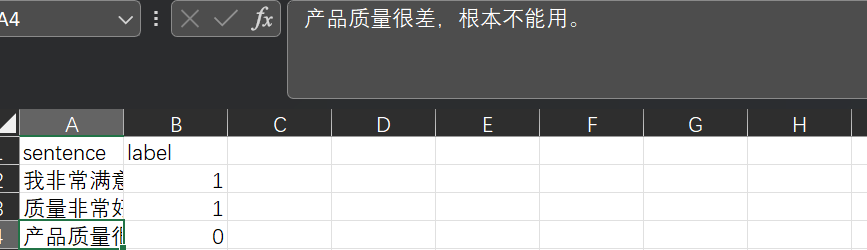
模型训练:
我们来训练处理句子情感分类的模型,代码如下
- import torch
- from tqdm import tqdm # 进度条库
- from transformers import AdamW # 优化器
- import pandas as pd # 文件读取
-
- from transformers import BertTokenizer, BertModel # 导入分词器和模型
-
- # 导入数据
- data = pd.read_csv("data/data.csv")
- # 定义编码器
- token = BertTokenizer.from_pretrained("bert-base-chinese")
- # 加载预训练模型
- pretrained = BertModel.from_pretrained("bert-base-chinese")
-
- # 创建编码集
- encode = []
-
- # 编码句子
- for i in tqdm(data["sentence"]):
- out = token.batch_encode_plus(
- batch_text_or_text_pairs=[i],
- truncation=True,
- padding='max_length',
- max_length=17,
- return_tensors='pt',
- return_length=True
- )
- encode.append(out)
-
-
- # 定义模型
- class MODEL(torch.nn.Module):
- def __init__(self):
- super().__init__() # 确保调用父类构造函数
- self.linear1 = torch.nn.Linear(768, 2)
-
- def forward(self, input_ids, attention_mask, token_type_ids):
- result = pretrained(input_ids=input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)
- result = self.linear1(result.last_hidden_state[:, 0])
- result = result.softmax(dim=1)
- return result
-
-
- # 创建模型对象
- model = MODEL()
- # 定义优化器
- optimizer = AdamW(model.parameters(), lr=5e-4)
- # 定义损失函数
- criterion = torch.nn.CrossEntropyLoss()
-
- # 模型训练
- for i in range(len(encode)):
- out = model(encode[i]["input_ids"], encode[i]["attention_mask"], encode[i]["token_type_ids"])
- loss = criterion(out, torch.LongTensor([data["label"][i]]))
- loss.backward()
- optimizer.step()
- optimizer.zero_grad()
-
-
- # 模型权重保存
- torch.save(model.state_dict(), 'model1_weights.pth')

运行后得到了训练后的模型权重文件
模型使用:
可用以下代码进行判断句子情感
- import torch
- from transformers import BertTokenizer, BertModel
-
- token = BertTokenizer.from_pretrained('bert-base-chinese')
- pretrained = BertModel.from_pretrained('bert-base-chinese')
-
-
- # 定义模型
- class Model(torch.nn.Module):
- def __init__(self):
- super().__init__()
- self.fc = torch.nn.Linear(768, 2)
-
- def forward(self, input_ids, attention_mask, token_type_ids):
- out = pretrained(
- input_ids=input_ids,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids
- )
- out = self.fc(out.last_hidden_state[:, 0])
- out = out.softmax(dim=1)
- return out
-
-
- model = Model()
- # 加载训练好的模型权重
- model.load_state_dict(torch.load('model1_weights.pth'))
-
- sentence = ["衣服一点也不好,差评"]
- # 编码
- o = token.batch_encode_plus(
- batch_text_or_text_pairs=sentence,
- truncation=True,
- padding='max_length',
- max_length=17,
- return_tensors='pt'
- )
-
- out = model(o['input_ids'], o['attention_mask'], o['token_type_ids'])
-
- if out[0][0] > out[0][1]:
- print("好评")
- else:
- print("差评")
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/356536
推荐阅读
相关标签

