
热门标签
热门文章
- 1docker-compose redis_docker-compose redis
- 2MYSQL中的14个神仙功能
- 3PyTorch学习之:深入理解神经网络
- 4win11病毒和防护功能显示‘页面不可用’的解决方法_windows defender页面不可用
- 5LeetCode-994. 腐烂的橘子【广度优先搜索 数组 矩阵】
- 6365天深度学习训练营-第T6周:好莱坞明星识别_label_mode='categorical
- 7openstack运维_查看openstack各个模块服务状态nova-conductor重启不了
- 8【Flutter从入门到实战】 ⑥、Flutter的StatefulWidget的生命周期didUpdateWidget调用机制、基础的Widget-普通文本Text、富文本Rich、按钮、图片的使用_flutter didupdatewidget
- 9决策树之C4.5(详细版终结版)_决策树c4.5代码实现
- 10SpringBoot+消息队列RocketMQ(基于阿里云)_aliyun.openservices onsmessagetrace
当前位置: article > 正文
机器学习笔记--改进KNN算法实现人脸识别_python knn人脸识别orl
作者:Gausst松鼠会 | 2024-04-06 17:37:50
赞
踩
python knn人脸识别orl
目录
1--前言
①sysu模式识别作业
②数据集:ORL Database of Faces
③原理: wk_NNC算法
2--路径总览
3--划分数据集
3.1--数据集介绍:
①ORL数据集采用P5类型的PGM格式进行存储,下图以记事本打开一个样本为例进行说明:
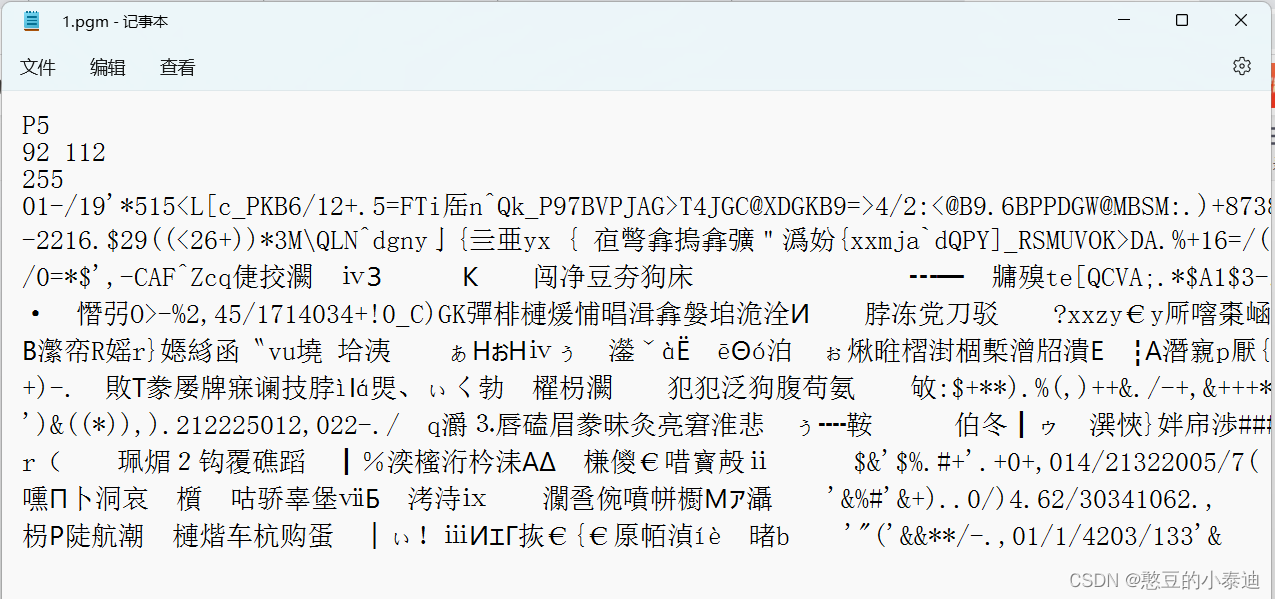
分析:第一行说明图片为P5格式;第二行为图片的宽高数据;第三行为数据的最大值;第四行及之后存储了图片的像素值;
注:需要说明的是,在划分数据集中用到了图片的宽高(H, W)数值,即(92,112),同时使用了min = 0和max = 255进行归一化;
3.2--代码:
- import os
- from PIL import Image
- import numpy as np
- import random
-
- def split_dataset(data_path, proportion):
-
- # 初始化训练集、验证集及其标签
- train_dataset = []
- test_dataset = []
- train_labels = []
- test_labels = []
-
- for i in range(40): # 遍历40类
- sample_list = os.listdir(data_path + '/s' + str(i + 1)) # 10个样本名
- random.shuffle(sample_list) # 随机打乱10个样本
- for j in range(len(sample_list)): # 遍历打乱后的10个样本
- img = Image.open(data_path + '/s' + str(i + 1) + '/' + sample_list[j]) # 读取第j个样本
- if j < (proportion * len(sample_list)): # 前7个划分到训练集
- train_dataset.append(np.array(img, dtype=np.uint8)) # 存储训练数据
- train_labels.append(i) # 存储训练标签
- else:
- test_dataset.append(np.array(img, dtype=np.uint8)) # 存储验证数据
- test_labels.append(i) # 存储验证标签
- return train_dataset, train_labels, test_dataset, test_labels
-
- def process_data(train_dataset, train_labels, test_dataset, test_labels):
-
- # 计算训练集和验证集的数目
- train_sum = len(train_dataset) # 等于 40 * 10 * proportion
- test_sum = len(test_dataset) # 等于 40 * 10 * (1-proportion)
-
- # 初始化处理后的训练集和验证集
- train_data = np.zeros((train_sum, H * W))
- test_data = np.zeros((test_sum, H * W))
- train_label = np.array(train_labels)
- test_label = np.array(test_labels)
-
- for i in range(train_sum): # 遍历每一个样本
- temp = train_dataset[i].reshape(-1) # reshape成单维向量
- train_data[i] = (temp - 0) / (255 - 0) # 归一化
- for j in range(test_sum):
- temp = test_dataset[j].reshape(-1)
- test_data[j] = (temp - 0) / (255 - 0) # 归一化
-
- return train_data, train_label, test_data, test_label
-
- if __name__ == "__main__":
-
- # 参数
- data_path = './dataset/ORL/att_faces/orl_faces' # 数据集路径
- proportion = 0.7 # 划分比例 0.7训练 0.3验证
- H = 92
- W = 112
-
- # 划分数据集
- train_dataset, train_labels, test_dataset, test_labels = split_dataset(data_path = data_path, proportion = proportion)
-
- # 数据集预处理
- train_data, train_label, test_data, test_label = process_data(train_dataset, train_labels, test_dataset, test_labels)
-
- save_name = './dataset/dataset.npz'
- np.savez(save_name, x_train=train_data, y_train=train_label, x_test=test_data, y_test=test_label)

3.3--运行及结果:
python gen_dataset.py4--主函数
4.1--原理分析:
(具体公式参考链接,这里只做原理简述)
①首先计算当前分类样本与训练样本的距离(常用欧式距离),让k个距离最小的训练样本拥有投票权;
②初始化所有类别的概率均为1,即初始化权重得分均为1;
③根据公式计算前k个训练样本的权重得分,并让投票样本的类别作为分类样本的预测类别;
④分类样本被预测为投票样本的概率由投票样本的权重得分决定
⑤最终权重得分和最高的类别为分类样本的预测类别。
4.2--源码:
- import numpy as np
-
- # KNN classifier
- def kNNClassify(test_x, train_x, train_y, k=4):
-
- # 计算与训练集样本的距离(280个),这里用欧几里得距离表示
- distance = np.sum(np.power((train_x - test_x), 2), axis=1) # 280
- sort_inx = np.argsort(distance, kind="quicksort")[:k] # 取前k个最小距离对应的索引,即训练集样本的索引
-
- w = [] # 初始化距离权重
- for i in range(k): # 利用 wk-NNC 算法公式计算k个近邻的权重
- w.append((distance[sort_inx[k - 1]] - distance[sort_inx[i]]) / (distance[sort_inx[k - 1]] - distance[sort_inx[0]]))
-
- score = np.ones(40) # 40个类别的得分
- for inx, data in enumerate(sort_inx):
- vote_label = train_y[data] # 投票类别,即当前邻居k对应的类别 (取值为0~39)
- score[vote_label] += w[inx] # 投票类别的得分 = 原始得分(初始化全为1) + 权重得分
-
- pre_label = np.argmax(score) # 取得分最高的类别作为预测类别
- return pre_label
-
- if __name__ == "__main__":
-
- # 读取数据集
- dataset_path = './dataset/dataset.npz'
- dataset = np.load(dataset_path)
- train_dataset = dataset['x_train']
- train_labels = dataset['y_train']
- test_dataset = dataset['x_test']
- test_labels = dataset['y_test']
-
- # 邻居数
- k = 4
-
- correct_sum = 0 # 预测正确的样本数
- test_sum = test_dataset.shape[0] # 验证集样本数
- string = "test_number: {0}, true_label: {1}, pre_label: {2}------>correct?: {3}" # 定义打印格式
- for i in np.arange(test_sum):
- # 利用KNN进行分类
- label = kNNClassify(test_x = test_dataset[i], train_x = train_dataset, train_y = train_labels, k=k)
-
- if label == test_labels[i]: # 分类正确
- correct_sum = correct_sum + 1
-
- print(string.format(i + 1, test_labels[i], label, label == test_labels[i])) # 打印当前样本分类结果
-
- print("Accuracy: {}%".format((correct_sum / test_sum) * 100)) # 打印最终准确率
4.3--运行及结果:
python knn.py
5--参考
6--问题补充
未完待续!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/373350
推荐阅读

相关标签

