
- 1解决UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xce in position 130: invalid continuation byt_invalid continuation byte
- 2python基本概念——标识符_数据库中my_name是正确的标识符吗
- 3初识flash芯片----写之前为什么要先擦除_flash擦除原理
- 4黑客必备的操作系统——kali linux安装_kelly linux
- 5阿里Java面经大全(整合版)
- 63DGS 其二:Street Gaussians for Modeling Dynamic Urban Scenes
- 7Kafka详解(四)多线程消费者实践_kafka 多线程
- 8B站小甲鱼python学习笔记_b站extend函数
- 9隐私安全保护:用技术守护个人信息的安全_网络技术进步也为隐私保护提供了新的手段
- 10echarts中树节点样式的修改方法_echarts树状图调整根节点样式
ElasticSearch入门篇
赞
踩
第一节 ElasticSearch概述
1.1 ElasticSearch是一个基于Lucene的搜索服务器
它提供了一个分布式多用户能力的全文搜索引擎,基于RESTfulweb接口。ElasticSearch是用Java开发的, 并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。构建在全 文检索开源软件Lucene之上的Elasticsearch,不仅能对海量规模的数据完成分布式索引与检索,还能提供数据聚合分析。据国际权威的 数据库产品评测机构DBEngines的统计,在2016年1月,Elasticsearch已超过Solr等,成为排名第一的搜索引擎类应用 概括:基于Restful标准的高扩展高可用的实时数据分析的全文搜索工具。
1.2 ElasticSearch的基本概念
Index
类似于mysql数据库中的database
Type
类似于mysql数据库中的table表,es中可以在Index中建立type(table),通过mapping进行映射
Document
由于es存储的数据是文档型的,一条数据对应一篇文档即相当于mysql数据库中的一行数据row, 一个文档中可以有多个字段也就是mysql数据库一行可以有多列
Field
es中一个文档中对应的多个列与mysql数据库中每一列对应
Mapping
可以理解为mysql或者solr中对应的schema,只不过有些时候es中的mapping增加了动态识别功能,感觉很强大的样子, 其实实际生产环境上不建议使用,最好还是开始制定好了对应的schema为主
indexed
就是名义上的建立索引。mysql中一般会对经常使用的列增加相应的索引用于提高查询速度,而在es中默认都是会加 上索引的,除非你特殊制定不建立索引只是进行存储用于展示,这个需要看你具体的需求和业务进行设定了
Query DSL
类似于mysql的sql语句,只不过在es中是使用的json格式的查询语句,专业术语就叫:QueryDSL
GET/PUT/POST/DELETE
分别类似与mysql中的select/update/delete......

1.3 Elasticsearch的架构

Gateway层
es用来存储索引文件的一个文件系统且它支持很多类型,例如:本地磁盘、共享存储(做snapshot的时候需要用到)、hadoop 的hdfs分布式存储、亚马逊的S3。它的主要职责是用来对数据进行长持久化以及整个集群重启之后可以通过gateway重新恢复数据。
Distributed Lucene Directory
Gateway上层就是一个lucene的分布式框架,lucene是做检索的,但是它是一个单机的搜索引擎,像这种es分布式搜索引擎系 统,虽然底层用lucene,但是需要在每个节点上都运行lucene进行相应的索引、查询以及更新,所以需要做成一个分布式的运 行框架来满足业务的需要。
四大模块组件
districted lucene directory之上就是一些es的模块
1.Index Module是索引模块,就是对数据建立索引也就是通常所说的建立一些倒排索引等;
2.Search Module是搜索模块,就是对数据进行查询搜索;
3.Mapping模块是数据映射与解析模块,就是你的数据的每个字段可以根据你建立的表结构 通过mapping进行映射解析,如果你没有建立表结构,es就会根据你的数据类型推测你 的数据结构之后自己生成一个mapping,然后都是根据这个mapping进行解析你的数据;
4.River模块在es2.0之后应该是被取消了,它的意思表示是第三方插件,例如可以通过一 些自定义的脚本将传统的数据库(mysql)等数据源通过格式化转换后直接同步到es集群里, 这个river大部分是自己写的,写出来的东西质量参差不齐,将这些东西集成到es中会引发 很多内部bug,严重影响了es的正常应用,所以在es2.0之后考虑将其去掉。
Discovery、Script
es4大模块组件之上有 Discovery模块:es是一个集群包含很多节点,很多节点需要互相发现对方,然后组成一个集群包括选 主的,这些es都是用的discovery模块,默认使用的是Zen,也可是使用EC2;es查询还可以支撑多种script即脚本语言,包括 mvel、js、python等等。
Transport协议层
再上一层就是es的通讯接口Transport,支持的也比较多:Thrift、Memcached以及Http,默认的是http,JMX就是java的一个 远程监控管理框架,因为es是通过java实现的。
RESTful接口层
最上层就是es暴露给我们的访问接口,官方推荐的方案就是这种Restful接口,直接发送http请求,方便后续使用nginx做代理、 分发包括可能后续会做权限的管理,通过http很容易做这方面的管理。如果使用java客户端它是直接调用api,在做负载均衡以 及权限管理还是不太好做。
第二节 ElasticSearch基本操作
2.1倒排索引
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
示例:
(1):假设文档集合包含五个文档,每个文档内容如图所示,在图中最左端一栏是每个文档对应的文档编号。我们的任务就是对这个文档集合建立倒排索引。
(2):中文和英文等语言不同,单词之间没有明确分隔符号,所以首先要用分词系统将文档自动切分成单词序列。这样每个文档就转换为由单词序列构成的数据流,为了系统后续处理方便,需要对每个不同的单词赋予唯一的单词编号,同时记录下哪些文档包含这个单词,在如此处理结束后,我们可以得到最简单的倒排索引
“单词ID”一栏记录了每个单词的单词编号,第二栏是对应的单词,第三栏即每个单词对应的倒排列表
(3):索引系统还可以记录除此之外的更多信息,下图还记载了单词频率信息(TF)即这个单词在某个文档中的出现次数,之所以要记录这个信息,是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子,所以将其记录在倒排列表中,以方便后续排序时进行分值计算

(4):倒排列表中还可以记录单词在某个文档出现的位置信息
(1,<11>,1),(2,<7>,1),(3,<3,9>,2)
有了这个索引系统,搜索引擎可以很方便地响应用户的查询,比如用户输入查询词“Facebook”,搜索系统查找倒排索引,从中可以读出包含这个单词的文档,这些文档就是提供给用户的搜索结果,而利用单词频率信息、文档频率信息即可以对这些候选搜索结果进行排序,计算文档和查询的相似性,按照相似性得分由高到低排序输出,此即为搜索系统的部分内部流程。
2.1.2 倒排索引原理
1.The quick brown fox jumped over the lazy dog
2.Quick brown foxes leap over lazy dogs in summer
倒排索引:
| Term | Doc_1 | Doc_2 |
|---|---|---|
| Quick | X | |
| The | X | |
| brown | X | X |
| dog | X | |
| dogs | X | |
| fox | X | |
| foxes | X | |
| in | X | |
| jumped | X | |
| lazy | X | X |
| leap | X | |
| over | X | X |
| quick | X | |
| summer | X | |
| the | X |
搜索quick brown :
| Term | Doc_1 | Doc_2 |
|---|---|---|
| brown | X | X |
| quick | X | |
| Total | 2 | 1 |
计算相关度分数时,文档1的匹配度高,分数会比文档2高
问题:
Quick 和 quick 以独立的词条出现,然而用户可能认为它们是相同的词。
fox 和 foxes 非常相似, 就像 dog 和 dogs ;他们有相同的词根。
jumped 和 leap, 尽管没有相同的词根,但他们的意思很相近。他们是同义词。
搜索含有 Quick fox的文档是搜索不到的
使用标准化规则(normalization): 建立倒排索引的时候,会对拆分出的各个单词进行相应的处理,以提升后面搜索的时候能够搜索到相关联的文档的概率
| Term | Doc_1 | Doc_2 |
|---|---|---|
| brown | X | X |
| dog | X | X |
| fox | X | X |
| in | X | |
| jump | X | X |
| lazy | X | X |
| over | X | X |
| quick | X | X |
| summer | X | |
| the | X | X |
2.1.3 分词器介绍及内置分词器
分词器:从一串文本中切分出一个一个的词条,并对每个词条进行标准化
包括三部分:
character filter:分词之前的预处理,过滤掉HTML标签,特殊符号转换等
tokenizer:分词
token filter:标准化
内置分词器:
standard 分词器:(默认的)他会将词汇单元转换成小写形式,并去除停用词和标点符号,支持中文采用的方法为单字切分
simple 分词器:首先会通过非字母字符来分割文本信息,然后将词汇单元统一为小写形式。该分析器会去掉数字类型的字符。
Whitespace 分词器:仅仅是去除空格,对字符没有lowcase化,不支持中文; 并且不对生成的词汇单元进行其他的标准化处理。
language 分词器:特定语言的分词器,不支持中文
第三节 ElasticSearch原理
3.1
云上的集群
如下图:
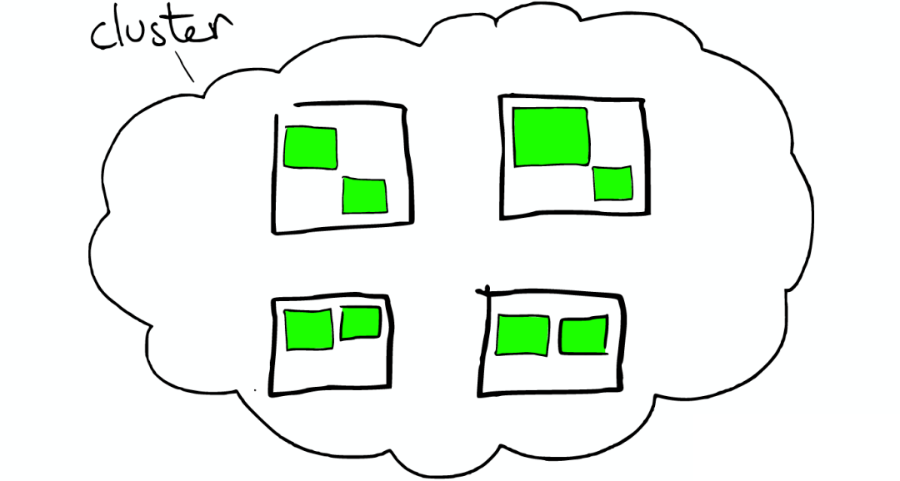
3.2 集群里的盒子
云里面的每个白色正方形的盒子代表一个节点——Node
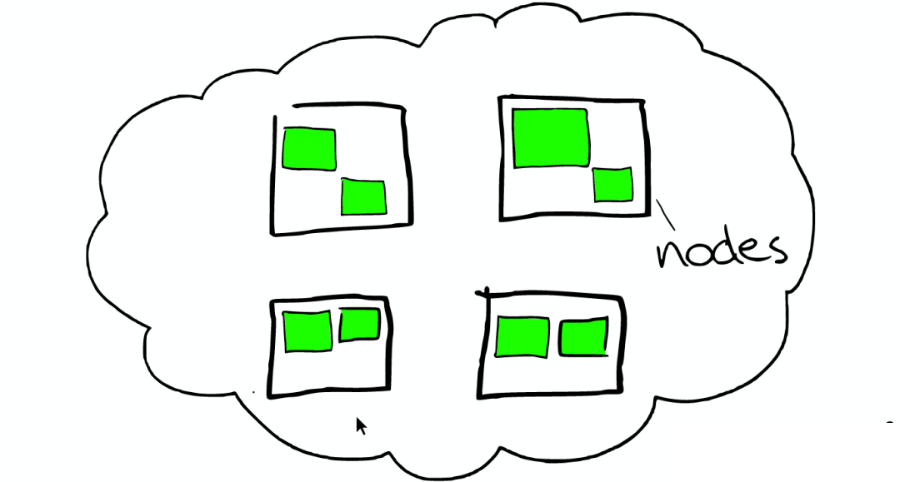
节点之间
在一个或者多个节点直接,多个绿色小方块组合在一起形成一个 ElasticSearch 的索引
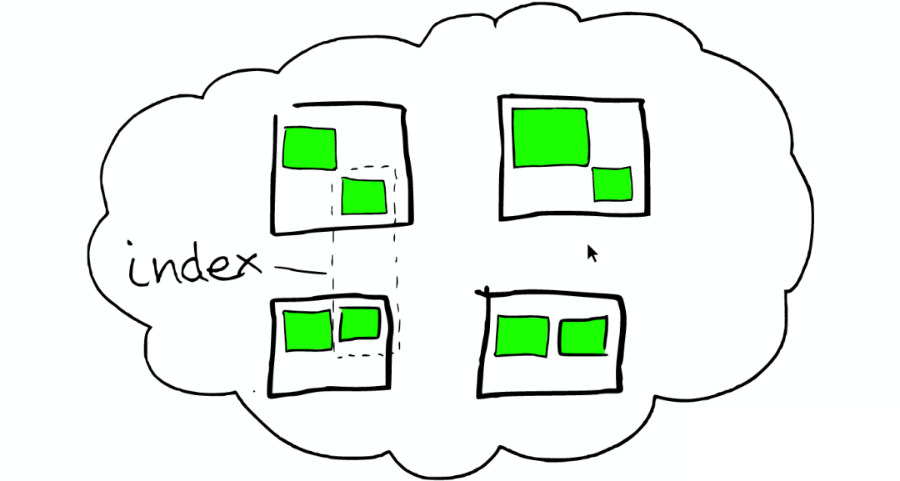
索引里的小方块
在一个索引下,分布在多个节点里的绿色小方块称为分片——Shard。
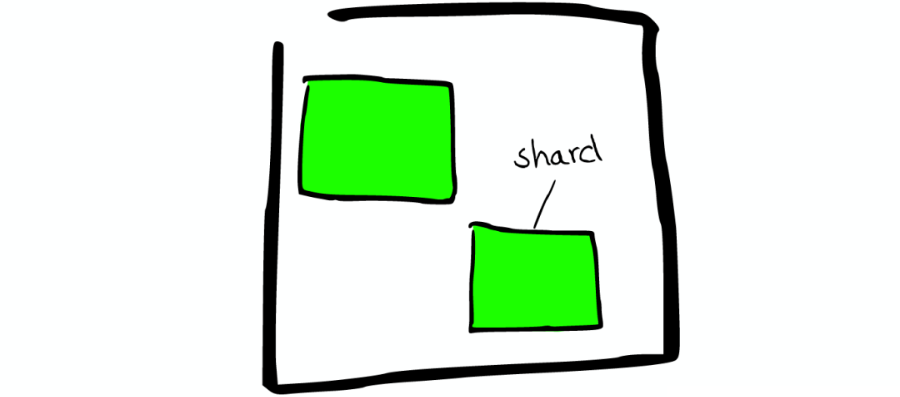
Shard=Lucene Index
一个 ElasticSearch 的 Shard 本质上是一个 Lucene Index

Lucene 是一个 Full Text 搜索库(也有很多其他形式的搜索库),ElasticSearch 是建立在 Lucene 之上的。
接下来的故事要说的大部分内容实际上是 ElasticSearch 如何基于 Lucene 工作的。
3.2 图解 Lucene
Mini 索引:Segment
在 Lucene 里面有很多小的 Segment,我们可以把它们看成 Lucene 内部的 mini-index
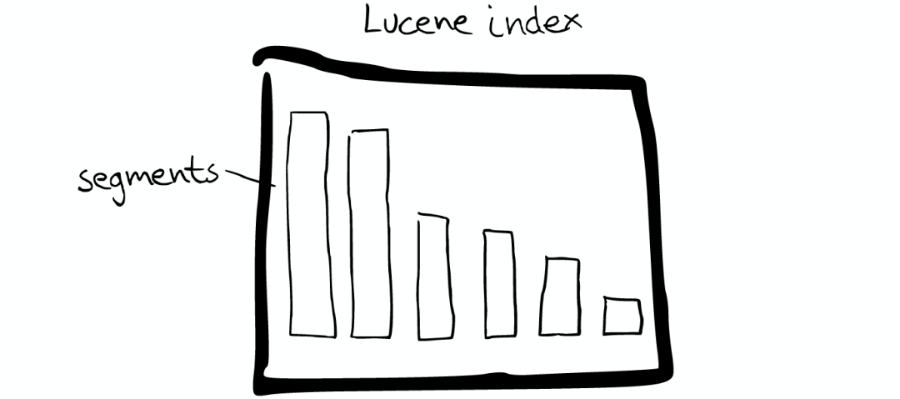
Segment 内部

Segment 内部有着许多数据结构,如上图:
-
Inverted Index
-
Stored Fields
-
Document Values
-
Cache
最最重要的 Inverted Index
如下图:
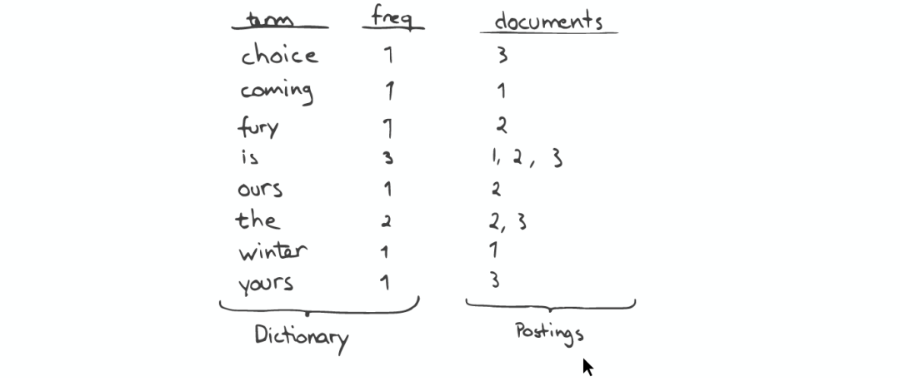
Inverted Index 主要包括两部分:
-
一个有序的数据字典 Dictionary(包括单词 Term 和它出现的频率)。
-
与单词 Term 对应的 Postings(即存在这个单词的文件)。
当我们搜索的时候,首先将搜索的内容分解,然后在字典里找到对应 Term,从而查找到与搜索相关的文件内容。
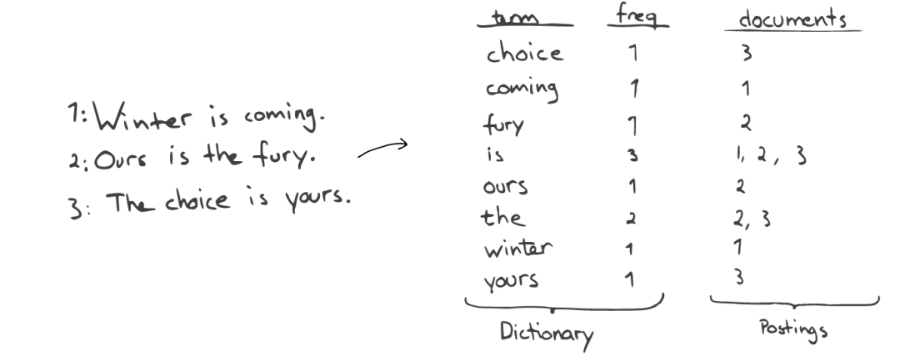
查询“the fury”
如下图:

自动补全(AutoCompletion-Prefix)
如果想要查找以字母“c”开头的字母,可以简单的通过二分查找(Binary Search)在 Inverted Index 表中找到例如“choice”、“coming”这样的词(Term)。

昂贵的查找
如果想要查找所有包含“our”字母的单词,那么系统会扫描整个 Inverted Index,这是非常昂贵的。

在此种情况下,如果想要做优化,那么我们面对的问题是如何生成合适的 Term。
问题的转化
如下图:

对于以上诸如此类的问题,我们可能会有几种可行的解决方案:
-
- * suffix→xiffus *,如果我们想以后缀作为搜索条件,可以为 Term 做反向处理。
-
(60.6384, 6.5017)→ u4u8gyykk,对于 GEO 位置信息,可以将它转换为 GEO Hash。
-
123→{1-hundreds, 12-tens, 123},对于简单的数字,可以为它生成多重形式的 Term。
解决拼写错误
一个 Python 库为单词生成了一个包含错误拼写信息的树形状态机,解决拼写错误的问题。

Stored Field 字段查找
当我们想要查找包含某个特定标题内容的文件时,Inverted Index 就不能很好的解决这个问题,所以 Lucene 提供了另外一种数据结构 Stored Fields 来解决这个问题。
本质上,Stored Fields 是一个简单的键值对 key-value。默认情况下,ElasticSearch 会存储整个文件的 JSON source。

Document Values 为了排序,聚合
即使这样,我们发现以上结构仍然无法解决诸如:排序、聚合、facet,因为我们可能会要读取大量不需要的信息。
所以,另一种数据结构解决了此种问题:Document Values。这种结构本质上就是一个列式的存储,它高度优化了具有相同类型的数据的存储结构。

为了提高效率,ElasticSearch 可以将索引下某一个 Document Value 全部读取到内存中进行操作,这大大提升访问速度,但是也同时会消耗掉大量的内存空间。
总之,这些数据结构 Inverted Index、Stored Fields、Document Values 及其缓存,都在 segment 内部。
搜索发生时
搜索时,Lucene 会搜索所有的 Segment 然后将每个 Segment 的搜索结果返回,最后合并呈现给客户。
Lucene 的一些特性使得这个过程非常重要:
-
Segments 是不可变的(immutable):
-
Delete?当删除发生时,Lucene 做的只是将其标志位置为删除,但是文件还是会在它原来的地方,不会发生改变。
-
Update?所以对于更新来说,本质上它做的工作是:先删除,然后重新索引(Re-index)。
-
-
随处可见的压缩:Lucene 非常擅长压缩数据,基本上所有教科书上的压缩方式,都能在 Lucene 中找到。
-
缓存所有的所有:Lucene 也会将所有的信息做缓存,这大大提高了它的查询效率。
缓存的故事
当 ElasticSearch 索引一个文件的时候,会为文件建立相应的缓存,并且会定期(每秒)刷新这些数据,然后这些文件就可以被搜索到。

随着时间的增加,我们会有很多 Segments,如下图:

所以 ElasticSearch 会将这些 Segment 合并,在这个过程中,Segment 会最终被删除掉。

这就是为什么增加文件可能会使索引所占空间变小,它会引起 Merge,从而可能会有更多的压缩。
举个栗子
有两个 Segment 将会 Merge:

这两个 Segment 最终会被删除,然后合并成一个新的 Segment,如下图:

这时这个新的 Segment 在缓存中处于 Cold 状态,但是大多数 Segment 仍然保持不变,处于 Warm 状态。
以上场景经常在 Lucene Index 内部发生的,如下图:

在 Shard 中搜索
ElasticSearch 从 Shard 中搜索的过程与 Lucene Segment 中搜索的过程类似。

与在 Lucene Segment 中搜索不同的是,Shard 可能是分布在不同 Node 上的,所以在搜索与返回结果时,所有的信息都会通过网络传输。
需要注意的是:1 次搜索查找 2 个 Shard=2 次分别搜索 Shard。

对于日志文件的处理:当我们想搜索特定日期产生的日志时,通过根据时间戳对日志文件进行分块与索引,会极大提高搜索效率。
当我们想要删除旧的数据时也非常方便,只需删除老的索引即可。

在上种情况下,每个 Index 有两个 Shards。
如何 Scale
如下图:

Shard 不会进行更进一步的拆分,但是 Shard 可能会被转移到不同节点上。

所以,如果当集群节点压力增长到一定的程度,我们可能会考虑增加新的节点,这就会要求我们对所有数据进行重新索引,这是我们不太希望看到的。
所以我们需要在规划的时候就考虑清楚,如何去平衡足够多的节点与不足节点之间的关系。
节点分配与 Shard 优化:
-
为更重要的数据索引节点,分配性能更好的机器。
-
确保每个 Shard 都有副本信息 Replica。

路由 Routing:每个节点,每个都存留一份路由表,所以当请求到任何一个节点时,ElasticSearch 都有能力将请求转发到期望节点的 Shard 进一步处理。

一个真实的请求
如下图:

Query
如下图:

Query 有一个类型 filtered,以及一个 multi_match 的查询。
Aggregation
如下图:

根据作者进行聚合,得到 top10 的 hits 的 top10 作者的信息。
请求分发
这个请求可能被分发到集群里的任意一个节点,如下图:

上帝节点
如下图:

这时这个节点就成为当前请求的协调者(Coordinator),它决定:
-
根据索引信息,判断请求会被路由到哪个核心节点。
-
以及哪个副本是可用的。
-
等等。
路由
如下图:

在真实搜索之前
ElasticSearch 会将 Query 转换成 Lucene Query,如下图:

然后在所有的 Segment 中执行计算,如下图:

对于 Filter 条件本身也会有缓存,如下图:

但 Queries 不会被缓存,所以如果相同的 Query 重复执行,应用程序自己需要做缓存。

所以:
-
Filters 可以在任何时候使用。
-
Query 只有在需要 Score 的时候才使用。
返回
搜索结束之后,结果会沿着下行的路径向上逐层返回,如下图:






