
- 1梯度提升树GBDT模型原理及spark ML实现_pyspark gbdt subsamplingrate
- 2C++:继承与派生_c++继承与派生
- 3Springboot 中使用 Redisson+AOP+自定义注解 实现访问限流与黑名单拦截_spring redis 黑名单
- 4如何下载Idea专业版_idea专业版下载
- 5AWS S3 协议对接 minio/oss 等_minio s3协议
- 6Android字体大小多屏幕适配_android字体大小适配屏幕
- 7深入理解package.json中dependencies和devDependencies 的区别_dependencies packge.json会影响其他项目吗
- 8Hive collect_set与collect_list_hive的collect的底层数据结构
- 9基于STM32的ADC采样及各式滤波实现(HAL库,含VOFA+教程)_数据采集滤波算法stm32(2)_vofa+.tabviews
- 10基于51单片机的搬运机器人系统protues仿真_proteus机械臂仿真
Hive基础(建表(内部表,外部表)&插入数据&导出命令&数据查询)_hive建立外部表插入数据
赞
踩
Hive
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行
Hive操作和操作各种关系数据库基本语法很相似,但是也有特别之处,本篇主要讲述Hive操作和你所熟悉的sql语句的不同之处。
建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] tablename
(col_name data_type [COMMENT col_comment])
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type)]
[CLUSTERER BY (col_name,col_name,...)]
[SORTERED BY (col_name[asc|desc],...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
IF NOT exists 如果相同的表名则会抛出异常;用户使用此选项可忽略异常
-
comment 添加说明
-
external 关键字可以让用户创建一个外部表,在建表时同时指定一个实际数据路径(location关键字和此关键字需一起使用)
-
有分区的表可以在创建时使用partitioned by语句,一个表可以拥有一个或多个分区,每个分区可以单独存在一个目录下
-
表和分区都可以对某个列进行clustered by操作,将若干列放入一个桶(bucket)中
-
可以利用sort by对数据进行排序,这样可以提高性能
-
row format 数据中间使用什么符号分割,默认分隔符为ASCII码的控制符\001(^a)
tab分隔符为\t。只支持单个字符的分隔符。

每个字段之间由[ , ]分割----------FIELDS TERMINATED BY ‘,’第二个字段是Array形式,元素与元素之间由[ - ]分割----------COLLECTION ITEMS TERMINATED BY ‘-’
第三个字段是K-V形式,每组K-V对内部由[ : ]分割,每组K-V对之间由[ - ]分割----------MAP KEYS TERMINATED BY ‘:’
-
stored as 指定文本存储格式纯文本使用 stored as textfile,压缩文件使用 stored as sequence
内部表
内部表与关系数据库中的Table在概念上类似。每一个Table在Hive中都有一个相应的目录存储数据。所有的Table数据都保存在这个目录中。
删除表时,元数据与数据都被删除
外部表
外部表指向已经在HDFS中存在的数据,可以创建partition。外部表在创建时只有一个过程,加载数据和创建表同时完成(CREATE EXTERNAL TABLE …LOCATION ),实际数据储存在LOCATION后面指定的HDFS路径中,并不会移动到数据仓库目录中。
当删除一个外部表时,仅删除该链接,不删除链接指定的文件
分区
Partition对应于关系数据库中的Partition列的密集索引,但是Hice中组织方式和数据库中的很不同。在Hive中,表中的一个Partition对应于表下的一个目录,索引的Partition的数据都储存在对应的目录中。
例如:pvs表中包含ds和city两个Partition,则对应于ds=2020-2-26,city=changsha的HDFS子目录为:
/wh/pvs/ds=2020-2-26/city=changsha;
分区键不是表中的列
分桶
Buckets是将表的列通过Hash算法进行一步分解成不同的文件存储。它是指定列计算hash,根据hash值 切分数据,目的是为了并行,每一个Bucket对应一个文件。分区是粗粒度划分,桶是细粒度的划分,这样做为了可以让查询发生在小范围的数据上以提高效率。适合进行表连接查询,适合用于采样分析。
例如:将user列分散至32个bucket,首先对user列的值计算hash,则对应hash值为0的HDFS的目录为:
/wh/pvs/ds=2020-2-26/city=changsha/part-00000;
对应的hash值为20的HDFS目录为:
/wh/pvs/ds=2020-2-26/city=changsha/part-00020;
建表实例
例如:创建人员信息表person(id,name,sex,age),列以 “,” 分割。按city分区,age字段建立5个桶
create table person(id int,name string,sex string,age int)
partitioned by(city string)
clustered by(age) into 5 buckets
row format delimited fields terminated by ','
stored as textfile;
- 1
- 2
- 3
- 4
- 5
打开桶参数:
set hive.enforce.bucketing=true;
- 1
加载数据(需要中间表person1)
//创建中间表(可看下方介绍插入数据)
create table person1(id int,name string,sex string,age int)
partitioned by(city string)
row format delimited fields terminated by ","
//查看下方Hive的导出
insert into table person partition(city="changsha") select * from person1
- 1
- 2
- 3
- 4
- 5
- 6
插入数据
- 在Hive中不建议使用:
insert into table values();
Hadoop作为大数据集群,这样插入数据的效率极其低 - 一般做法为按文件插入(load数据)
LOAD DATA [LOCAL]
INPATH 'dirpath' [OVERWRITE]
INTO TABLE tablename
[PARTITION (ds='name')];
- 1
- 2
- 3
- 4
- local:代表本地文件;(不加则为hadoop集群路径)
- overwrite:覆盖;(不加则为追加数据)
- partition:分区;
Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。如果表中存在分区,则必须指定分区名。
加载本地数据,指定LOCAL关键字,即本地,可以同时给定分区信息 。
load 命令会去查找本地文件系统中的 filepath。如果发现是相对路径,则路径会被解释为相对于当前用户的当前路径。用户也可以为本地文件指定一个完整的 URI,比如:file:///user/hive/project/data1.
例如:加载本地数据,同时给定分区信息( kv2.txt是hive中的examples的案例数据):
CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);
- 1
LOAD DATA LOCAL INPATH '/tmp/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2020-15’);
- 1
加载DFS数据 ,同时给定分区信息:
如果 filepath 可以是相对路径 URI路径,对于相对路径,Hive 会使用在 hadoop 配置文件中定义的 fs.defaultFS 指定的Namenode 的 URI来自动拼接完整路径。
例如:加载数据到hdfs中,同时给定分区信息
LOAD DATA INPATH '/kv2.txt' OVERWRITE INTO TABLE invites
PARTITION (ds='2020-08-15');
- 1
- 2
OVERWRITE
指定 OVERWRITE ,目标表(或者分区)中的内容(如果有)会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代
Hive的导出命令
实例:
- 导出一个表到本地“/MyData”目录,每一列数据以”_”分割
insert overwrite local directory '/MyData'
row format delimited fields terminated by "_"
select * from person1;
- 1
- 2
- 3
- 如导出到Hadoop集群下,则不加local
- 表导出到表
inset into table person partition(city="shanghai") select * from person1;
- 1
Hive的数据查询(MySql语法相似)
例如:查询分区为city=“changsha”的数据
select * from person where city="changsha"
- 1
Limit:限制条数查询
Limit可以限制查询的记录数。查询的结果是随机选择的
例如:从person表中随机查询5条数据
slect * from person limit 5
- 1
Top N查询
查询年龄最大的5个
select * from person sort by age desc limit 5;
- 1
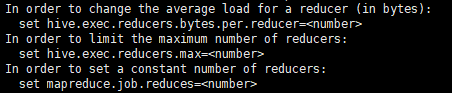
可以按照提示设置mr的参数


