
热门标签
热门文章
- 1大模型应用开发-LangChain入门教程_大模型langchain
- 2Hexo博客重新部署与Git配置
- 312 个好用且不花钱的网络监控工具_deep flow监控需要购买吗_网络状态监控软件
- 4安装importlib_metadata模块后,依旧显示No module named ‘importlib_metadata’_importlib.metadata安装
- 5centos 7 oracle 监听,CentOS 7下oracle 11g配置监听
- 62020应届毕业生进沪就业满72分可落户上海!申请指南详见→_非户籍上海高校应届生落户政策
- 7大数据Spark实战第七集 机器学习和数据处理_setstages函数功能
- 8【SpringBoot3+Vue3】四【基础篇】-前端(vue基础)_springboot html vue3
- 9混合A*流程与理解_深蓝学院混合a星
- 10ORACLE12C 问题 - 远程访问显示 ORA-12541:TNS:无监听程序_oracle12c客户端没有监听程序
当前位置: article > 正文
机器学习—正则化方法—L1正则化、L2正则化_稀疏权值矩阵
作者:Gausst松鼠会 | 2024-05-15 19:36:08
赞
踩
稀疏权值矩阵

1、L1正则化(稀疏矩阵)
权值向量w中各个元素的绝对值之和:
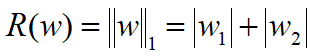
2、L2正则化(权重衰减)
权值向量w中各个元素的平方和:
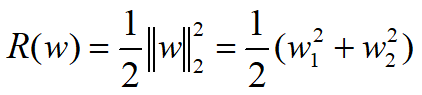
3、L1正则化 VS L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合(overfitting)
问:为什么 L1 正则可以产生稀疏模型(很多参数=0),而 L2 正则不会出现很多参数为0的情况?
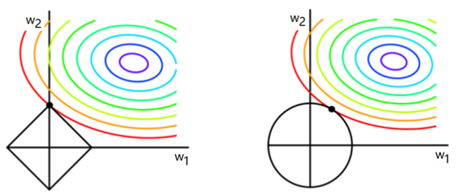
对于 L1 来说,限定区域是正方形(图左),同时使得经验风险尽可能小,方形与环形区域相交的交点是顶点的概率很大,这从视觉和常识上来看是很容易理解的。也就是说,方形的凸点会更接近最优参数对应的位置,而凸点处必有 w1 或 w2 为 0。这样,得到的解 w1 或 w2 为零的概率就很大了。所以,L1 正则化的解具有稀疏性。
扩展到高维,同样的道理,L2 的限定区域是平滑的,与中心点等距;而 L1 的限定区域是包含凸点的,尖锐的。这些凸点更接近 Ein 的最优解位置,而在这些凸点上,很多 wj 为 0。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/574664
推荐阅读
相关标签

