
- 1Ubuntu 18.04 环境下编译Android 源码_ubuntu18.04编译android8
- 2Redhat 8更换yum网络源(aliyun)_redhat8更换yum源
- 3Adobe Media Encoder ME v24.3.0 解锁版 (视频和音频编码渲染工具)
- 4OfficeToolPlus工具分享
- 5[第四课笔记]XTuner 大模型单卡低成本微调实战_大模型微调需要什么配置
- 6Hadoop集群环境搭建与应用回顾_基于hadoop平台的搭建和应用
- 7android studio使用教程_android studio怎么做在线客服
- 8git拉取远程分支到本地(本地不存在的分支)_git切换到本地没有的分支
- 9头歌(educoder)第 4 章 Java入门之方法 Java入门 - 方法的使用_头歌java入门方法的使用答案
- 10考研经验分享
Java刷题知识点之拥塞发生的主要原因、TCP拥塞控制、TCP流量控制、TCP拥塞控制的四大过程(慢启动、拥塞避免、快速重传、快速恢复)...
赞
踩
什么是拥塞?
当大量的分组进入通信子网,超出了网络的处理能力时,就会引起网络局部或整体性能下降,这种现象称为拥塞。拥塞常常使问题趋于恶化。
另一种对拥塞的解释,即对资源的需求超过了可用的资源。若网络中许多资源同时供应不足,网络的性能就要明显变坏,整个网络的吞吐量随之负荷的增大而下降。
拥塞其实是一个动态问题,我们没有办法用一个静态方案去解决,从这个意义上来说,拥塞是不可避免的。
静态解决问题办法1:
例如:增加缓存空间到一定程度时,只会加重拥塞,而不是减轻拥塞,这是因为当数据包经过长时间排队完成转发时,它们很可能早已超时,从而引起源端超时重发,而这些数据包还会继续传输到下一路由器,从而浪费网络资源,加重网络拥塞。事实上,缓存空间不足导致的丢包更多的是拥塞的“症状”而非原因。另外,增加链路带宽及提高处理能力也不能解决拥塞问题。
静态解决问题办法2:
例如:我们有四台主机ABCD连接路由器R,所有链路带宽都是1Gbps,如果A和B同时向C以1Gbps的速率发送数据,则路由器R的输入速率为2Gbps,而输出速率只能为1Gbps,从而产生拥塞。避免拥塞的方法只能是控制AB的速率,例如,都是0.5Gbps,但是,这只是一种情况,倘若D也向R发送数据,且速率为1Gbps,那么,我们先前的修正又是不成立的。
TCP的拥塞控制
为什么需要拥塞控制?
答:由于TCP采用了超时重传机制,如果拥塞不加以控制,将导致大量的报文重传,并再度引起大量的数据报丢弃,直到整个网络瘫痪。这种现象称为拥塞崩溃。
在网络实际的传输过程中,会出现拥塞的现象,网络上充斥着非常多的数据包,但是却不能按时被传送,形成网络拥塞,其实就是和平时的堵车一个性质了。TCP设计中也考虑到这一点,使用了一些算法来检测网络拥塞现象,如果拥塞产生,变会调整发送策略,减少数据包的发送来缓解网络的压力。
拥塞控制:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。拥塞控制所要做的都有一个前提:网络能够承受现有的网络负荷。拥塞控制是一个全局性的过程,涉及到所有的主机、路由器,以及与降低网络传输性能有关的所有因素。
- 早期的TCP协议只有基于窗口的流控制(flow control)机制,我们简单介绍一下,并分析其不足。 在TCP中,为了实现可靠性,发送方发出一个数据段之后要等待接受方相应的确认信息,而不是直接发送下一个分组。
- 具体的技术是采用滑动窗口,以便通信双方能够充分利用带宽。滑动窗口允许发送方在收到接收方的确认之前发送多个数据段。窗口大小决定了在收到目的地确认之前,一次可以传送的数据段的最大数目。窗口大小越大,主机一次可以传输的数据段就越多。当主机传输窗口大小数目的数据段后,就必须等收到确认,才可以再传下面的数据段。例如,若视窗的大小为 1,则传完数据段后,都必须经过确认,才可以再传下一个数据段;当窗口大小等于3时,发送方可以一次传输3个数据段,等待对方确认后,再传输下面三个数据段。
- 窗口的大小在通信双方连接期间是可变的,通信双方可以通过协商动态地修改窗口大小。在TCP的每个确认中,除了指出希望收到的下一个数据段的序列号之外,还包括一个窗口通告,通告中指出了接收方还能再收多少数据段(我们可以把通告看成接收缓冲区大小)。如果通告值增大,窗口大小也相应增大;通告值减小,窗口大小也相应减小。但是我们可以发现,接收端并没有特别合适的方法来判断当前网络是否拥塞,因为它只是被动得接收,不像发送端,当发出一个数据段后,会等待对方得确认信息,如果超时,就可以认为网络已经拥塞了。
- 所以,改变窗口大小的唯一根据,就是接收端缓冲区的大小了。
- 流量控制作为接受方管理发送方发送数据的方式,用来防止接受方可用的数据缓存空间的溢出。
- 流控制是一种局部控制机制,其参与者仅仅是发送方和接收方,它只考虑了接收端的接收能力,而没有考虑到网络的传输能力;
- 而拥塞控制则注重于整体,其考虑的是整个网络的传输能力,是一种全局控制机制。正因为流控制的这种局限性,从而导致了拥塞崩溃现象的发生。
TCP拥塞控制的四大过程(慢启动、拥塞避免、快速重传、快速恢复)
为了方便起见,把发送端叫做client,接收端为server,每个segment长度为512字节,阻塞窗口长度为cwnd(简化起见,下面以segment为单位),sequence number为seq_num,acknowledges number为ack_num。通常情况下,TCP每接收到两个segment,发送一个ack。

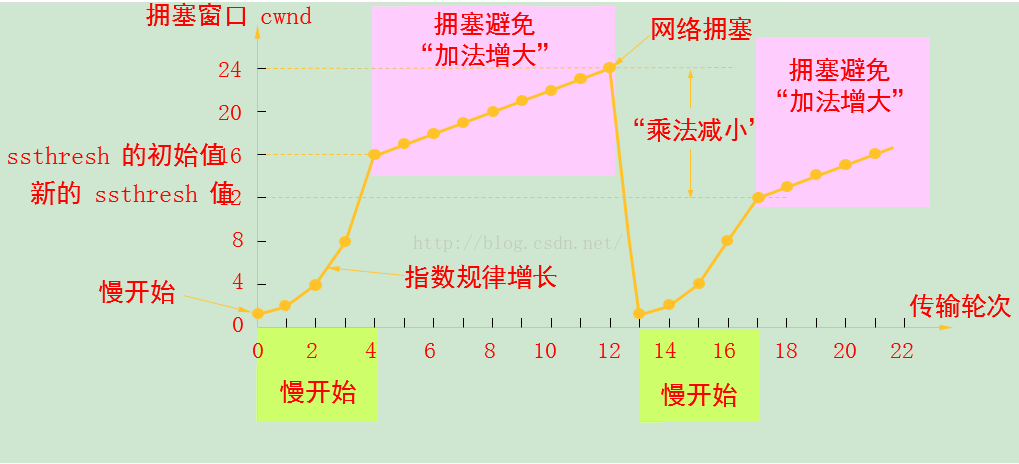
(1)慢启动算法是一个在连接上发起数据流的方法。
(2)慢启动过程:
初始时将拥塞窗口的初始为一个MSS,每次收到一个报文段的确认时发送方将拥塞窗口增大一个MSS,并发送两个最大长度的报文段。两个报文段被确认后,则发送方复每个报文段的确认增加一个MSS,使得拥塞窗口变为4个MSS,这样每过一个RTT,发送速率就翻番。因此,在慢启动阶段以指数增长。
(3)慢启动的结束:
当出现一个由超时指示的丢包事件,TCP发送方将cwnd设置为1,并重新开始慢启动。
(1)拥塞避免算法是一种处理丢失分组的方法。(当到达中间路由器的极限时,分组将被丢弃。)
(2)拥塞避免过程:
进入拥塞避免时,拥塞窗口的值大约是上次遇到拥塞时值的一半,每个RTT只将拥塞窗口的值增加1个MSS.
(3)结束条件:超时或丢包。
(1)执行条件及过程
当收到3个或3个以上的重复ACK时,就非常有可能是一个报文段丢失了。于是我们就重传丢失的数据报文段,而不等待超时定时器溢出。这就是快速重传。接下来执行的不是慢启动,而是拥塞避免,这就是快速恢复。
(2)原因:
没有执行慢启动的原因是由于收到的重复的ACK不仅仅告诉我们一个分组丢失了。由于接收方只有在收到另一个报文段时才会产生重复的ACK,而该报文段已经离开网络并进入了接收方的缓存。也就是说在收发两端之间仍然有流动的数据,而我们不想执行慢启动来突然减少数据流。
真实例子
想想看,能不能把TCP解决拥塞的方法应用到交通拥塞呢? 我们有两个原则:一是拥塞不可避免,单纯增加资源并不能避免拥塞的发生,只能用动态的方法加以解决;二是数据包守恒原则。政府花费很大资金修路,并不能避免堵车,只能从源头控制,例如首先限制车辆进入主路,根据实际情况,再慢慢增加每一个路口的车流量,但是,当达到一个阀值,增加速度要放缓,并不时探测整个主路的拥堵情况,如果情况危急,立刻封闭半个路口,并将车流量降到最低,也就是重新回复到慢启动状态。 呵呵,有趣!
本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/7617819.html,如需转载请自行联系原作者
- pom.xml
org.web3j [详细] 赞
踩

