
- 1Hadoop的简介、安装配置和集群搭建(hadoop2.7.7)_hadoop 2.7.7
- 2Java中文分词组件 - word分词_jiqingyyzhou
- 3swift 之 mustache模板引擎
- 4RocketMQ的消费者消息重试和生产者消息重投_maxreconsumetimes
- 5华为云API对话机器人CBS的魅力—实现简单的对话操作_华为云问答机器人接口调用与对话体验不一致
- 6利用JavaScript控制单选框
- 7RocketMQ篇二(消息重试、死信队列、死信消息、消息幂等、延迟消息、顺序消息、消息过滤)
- 8双非怎么保研哈工大计算机,针对双非学生计算机保研信息分享
- 9Verilog中常见Warnning或error
- 10Geth搭建私链的一些错误尝试_transaction pool tip threshold updated tip=1,000,0
RANSAC算法理解
赞
踩
最早应该是十四讲上见过,在第九章的project中src中的visual_odometry.cpp中,最核心的求解3d-2d的变换中:
//整个核心就是用这个cv::solvePnPRansac()去求解两帧之间的位姿变化
cv::solvePnPRansac( pts3d, pts2d, K, Mat(), rvec, tvec, false, 100, 4.0, 0.99, inliers );- 1
- 2
当时只是简单的认为是PNP求解,没有注意这个Ransac(不求甚解。。。)。后面直到大伟哥面试趟坑被问到:
特征匹配要是遇到误匹配时,如何筛选处理?
答案就是用ransac算法进行过滤。
下面介绍一下ransac算法,下面为摘抄自:http://blog.csdn.net/fandq1223/article/details/53175964
RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法——它有一定的概率得出一个合理的结果;为了提高概率必须提高迭代次数。
RANSAC的基本假设是:
(1)数据由“局内点”组成,例如:数据的分布可以用一些模型参数来解释;
(2)“局外点”是不能适应该模型的数据;
(3)除此之外的数据属于噪声。
局外点产生的原因有:噪声的极值;错误的测量方法;对数据的错误假设。
RANSAC也做了以下假设:给定一组(通常很小的)局内点,存在一个可以估计模型参数的过程;而该模型能够解释或者适用于局内点。
一、示例
一个简单的例子是从一组观测数据中找出合适的2维直线。假设观测数据中包含局内点和局外点,其中局内点近似的被直线所通过,而局外点远离于直线。简单的最小二乘法不能找到适应于局内点的直线,原因是最小二乘法尽量去适应包括局外点在内的所有点。相反,RANSAC能得出一个仅仅用局内点计算出模型,并且概率还足够高。但是,RANSAC并不能保证结果一定正确,为了保证算法有足够高的合理概率,我们必须小心的选择算法的参数。
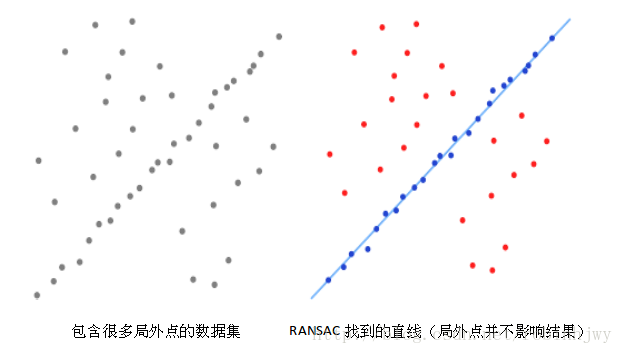
二、概述
RANSAC算法的输入是一组观测数据,一个可以解释或者适应于观测数据的参数化模型,一些可信的参数。
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
1.首先我们先随机假设一小组局内点为初始值。然后用此局内点拟合一个模型,此模型适应于假设的局内点,所有的未知参数都能从假设的局内点计算得出。
2.用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点,将局内点扩充。
3.如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
4.然后,用所有假设的局内点去重新估计模型,因为此模型仅仅是在初始的假设的局内点估计的,后续有扩充后,需要更新。
5.最后,通过估计局内点与模型的错误率来评估模型。
整个这个过程为迭代一次,此过程被重复执行固定的次数,每次产生的模型有两个结局:
1、要么因为局内点太少,还不如上一次的模型,而被舍弃,
2、要么因为比现有的模型更好而被选用。
三、算法
伪码形式的算法如下所示:
输入:
data —— 一组观测数据
model —— 适应于数据的模型
n —— 适用于模型的最少数据个数
k —— 算法的迭代次数
t —— 用于决定数据是否适应于模型的阀值
d —— 判定模型是否适用于数据集的数据数目
输出:
best_model —— 跟数据最匹配的模型参数(如果没有找到好的模型,返回null)
best_consensus_set —— 估计出模型的数据点
best_error —— 跟数据相关的估计出的模型错误
iterations = 0
best_model = null
best_consensus_set = null
best_error = 无穷大
while ( iterations < k )
maybe_inliers = 从数据集中随机选择n个点
maybe_model = 适合于maybe_inliers的模型参数
consensus_set = maybe_inliers
for ( 每个数据集中不属于maybe_inliers的点 )
if ( 如果点适合于maybe_model,且错误小于t )
将点添加到consensus_set
if ( consensus_set中的元素数目大于d )
已经找到了好的模型,现在测试该模型到底有多好
better_model = 适合于consensus_set中所有点的模型参数
this_error = better_model究竟如何适合这些点的度量
if ( this_error < best_error )
我们发现了比以前好的模型,保存该模型直到更好的模型出现
best_model = better_model
best_consensus_set = consensus_set
best_error = this_error
增加迭代次数
返回 best_model, best_consensus_set, best_error
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
RANSAC算法的可能变化包括以下几种:
(1)如果发现了一种足够好的模型(该模型有足够小的错误率),则跳出主循环。这样可能会节约计算额外参数的时间。
(2)直接从maybe_model计算this_error,而不从consensus_set重新估计模型。这样可能会节约比较两种模型错误的时间,但可能会对噪声更敏感。
其实核心就是随机性和假设性。随机性用于减少计算了,那个循环次数就是利用正确数据出现的概率。所谓的假设性,就是说随机抽出来的数据我都认为是正确的,并以此去计算其他点,获得其他满足变换关系的点,然后利用投票机制,选出获票最多的那一个变换。
四、参数
我们不得不根据特定的问题和数据集通过实验来确定参数t和d。然而参数k(迭代次数)可以从理论结果推断。当我们从估计模型参数时,用p表示一些迭代过程中从数据集内随机选取出的点均为局内点的概率;此时,结果模型很可能有用,因此p也表征了算法产生有用结果的概率。用w表示每次从数据集中选取一个局内点的概率,如下式所示:
w = 局内点的数目 / 数据集的数目
通常情况下,我们事先并不知道w的值,但是可以给出一些鲁棒的值。假设估计模型需要选定n个点,
我们对上式的两边取对数,得出:

