
- 1基于STM32与TB6600的机械臂项目(代码开源)_步进电机驱动的机械臂控制系统设计
- 2MFC常规DLL的创建与使用实例_创建mfc dll 串口通信
- 3可解释性人工智能(XAI):揭秘人工智能的“黑匣子”_人工智能黑匣子
- 4给定一个非空的整数数组,返回其中出现频率前 k 高的元素。(PHP)_给定一个非空的整数数组,请编程返回其中出现频率前k高的元素
- 5【转载】flink 在 flink standalone模式下元空间内存溢出排查及问题解决_元空间内存溢出解决问题
- 6简单操作让你的网站不受恶意流量恶意爬虫威胁!Cloudflare防火墙部署指南_cloudflare部署
- 7gStore入选BenchCouncil年度世界开源系统杰出成果
- 8CORS跨域问题(前后端全栈解决方式讲解)_后端在本地运行前端代码cors
- 9rabbitMq确认机制之ConfirmType_publisher-confirm-type
- 10【WFA】【WIFI6】HE-5.31.2_6G Fail_wifi 测试 data capture fail
【python】让世界再无刷的课
赞
踩
本次介绍的是一个公共课的学习网站,通过requests库模拟用户发出的请求达到课程的迅速观看。
打开浏览器控制台进入目标网站尝试登陆发现

发现网站没有对密码进行加密cookie无明显变化直接使用以下代码保存cookie
import requests
requests = requests.session()
- 1
- 2
登陆后查看课程,在控制台搜索开始学习
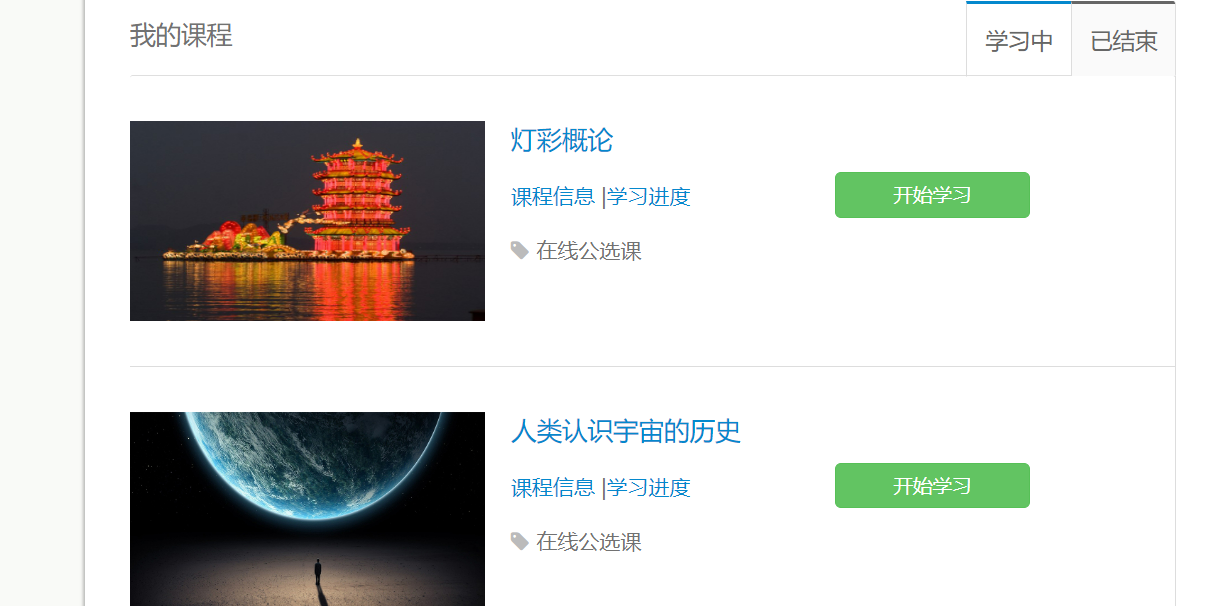

发现前方有个href标签包含地址,其中id和cid这两个参数很重要(后面会用到)点开始学习后会进入到课程页面
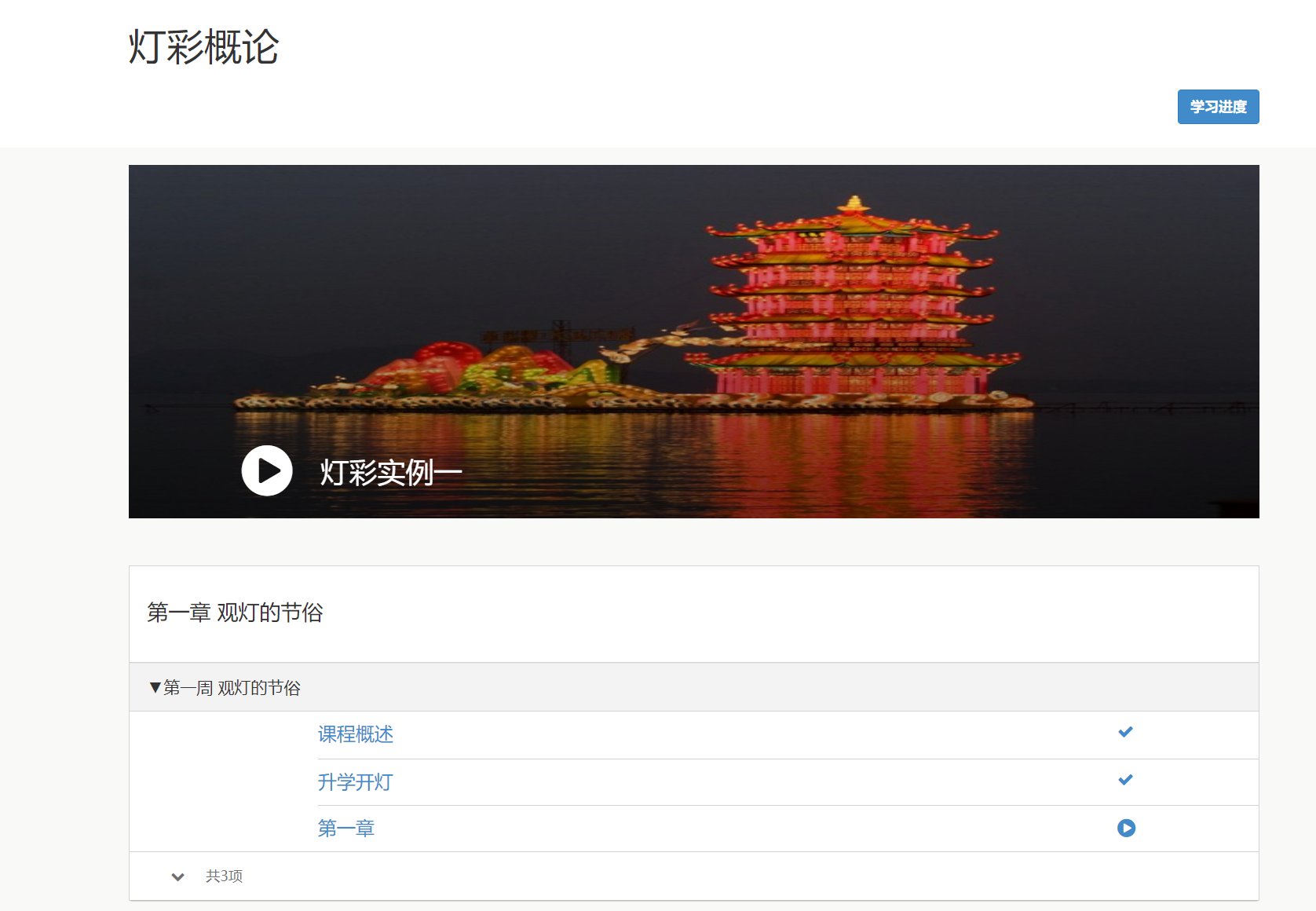
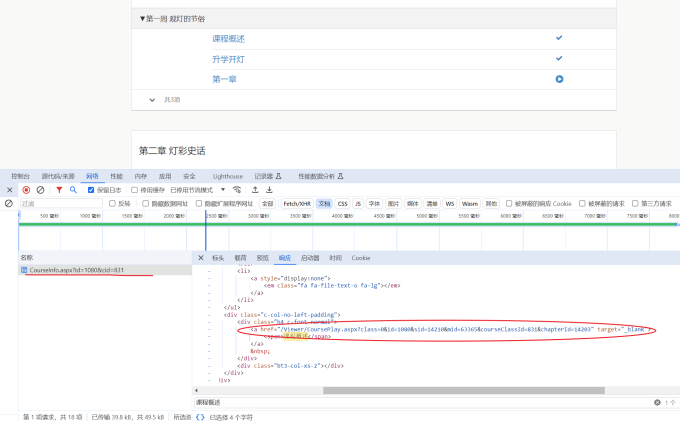
打开F12控制台找到对应链接,我们会发现所有的视频链接都是以这中形式存在。其中有参数id,sid,mid,courseclassid,以及chapterid。
然后我们点击视频,进入视频页面
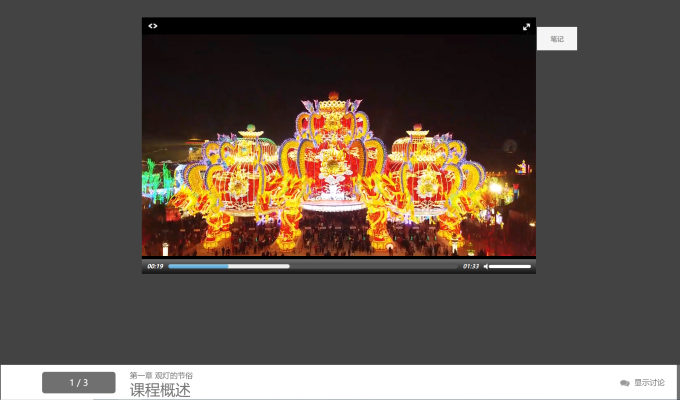
打开F12控制台,随着视频的观看发现请求了一个网址

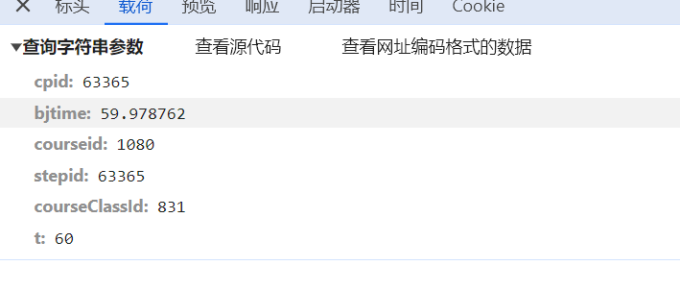
不难发现其中的参数和上面id,sid,mid,courseclassid,以及chapterid对应。响应的值为

写出代码
headers = { 'authority': 'wrggk.whvcse.edu.cn', 'accept': '*/*', 'accept-language': 'zh-CN,zh;q=0.9', # 'content-length': '0', 'origin': 'https://wrggk.whvcse.edu.cn', 'referer': 'https://wrggk.whvcse.edu.cn/Viewer/CoursePlay.aspx?class=0&id=1080&sid=14210&mid=63365&courseClassId=831&chapterId=14203', 'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"', 'sec-ch-ua-mobile': '?0', 'sec-ch-ua-platform': '"Windows"', 'sec-fetch-dest': 'empty', 'sec-fetch-mode': 'cors', 'sec-fetch-site': 'same-origin', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', 'x-requested-with': 'XMLHttpRequest', } params = { 'cpid': '63365', 'bjtime': '59.978762', 'courseid': '1080', 'stepid': '63365 ', 'courseClassId': '831', 't': '60', } response = requests.post('https://wrggk.whvcse.edu.cn/Viewer/timetop.aspx', params=params, headers=headers)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
结果:成功
接下来我们分析网课的考试部分:
找到考试地址
进入课程页面找到试卷的url链接,提取网址中的参数(id,sid,courseClassId,chapterId,pid)
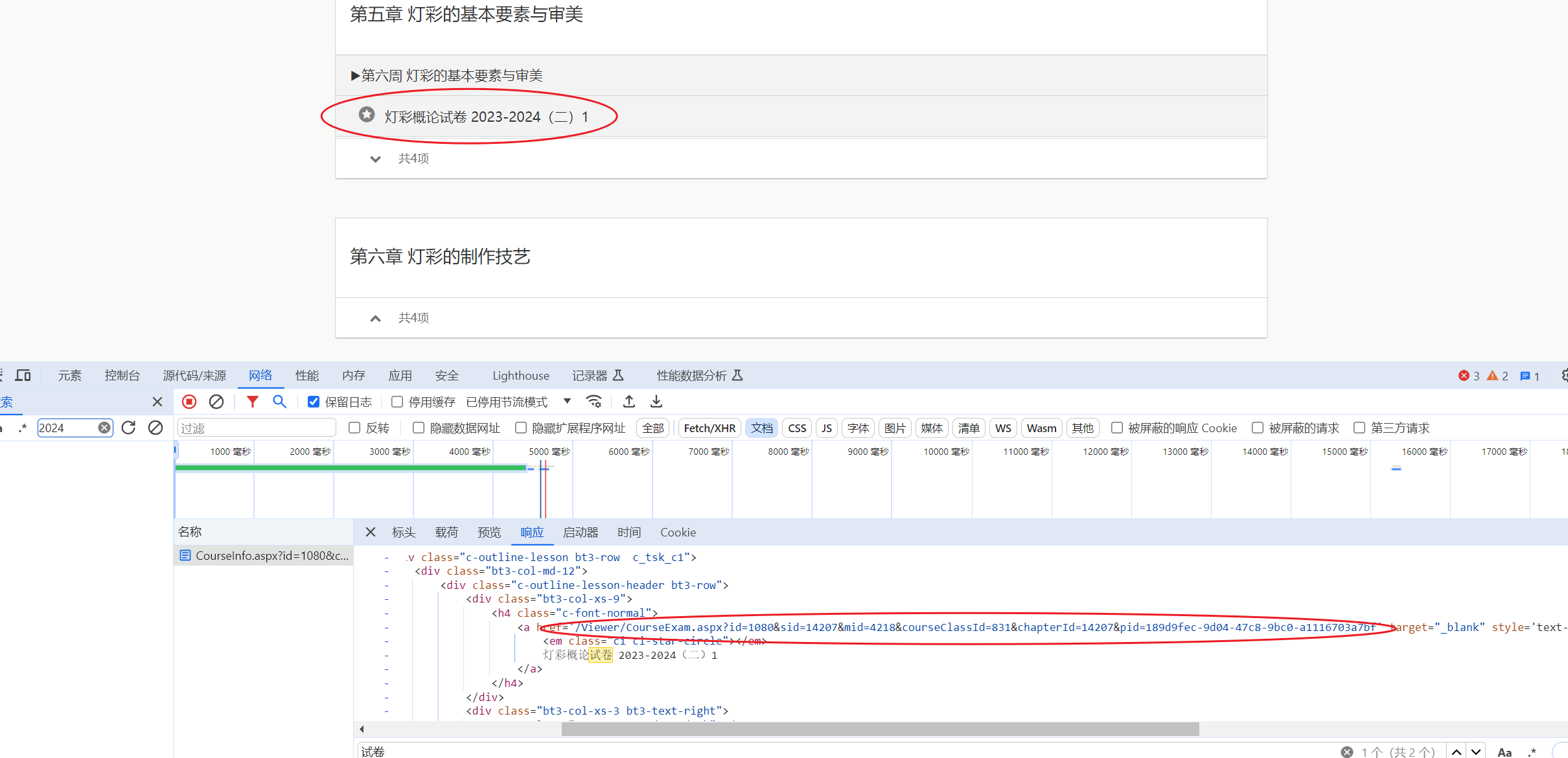
找到查看答案页面
点击考试链接发现查看答案链接(由于本人已经测试完成,显示的是查看答案的链接,初始页面是开始考试的链接,经过考试链接与答案的链接进行比对,发现只需在考试链接后面添加参数View=1就可以提前查看答案)到这里其实已经可以根据答案直接通过考试,但是和我们使用代码完成还是有区别的,如需继续深入请往下看。(参数userid,username需要提取)
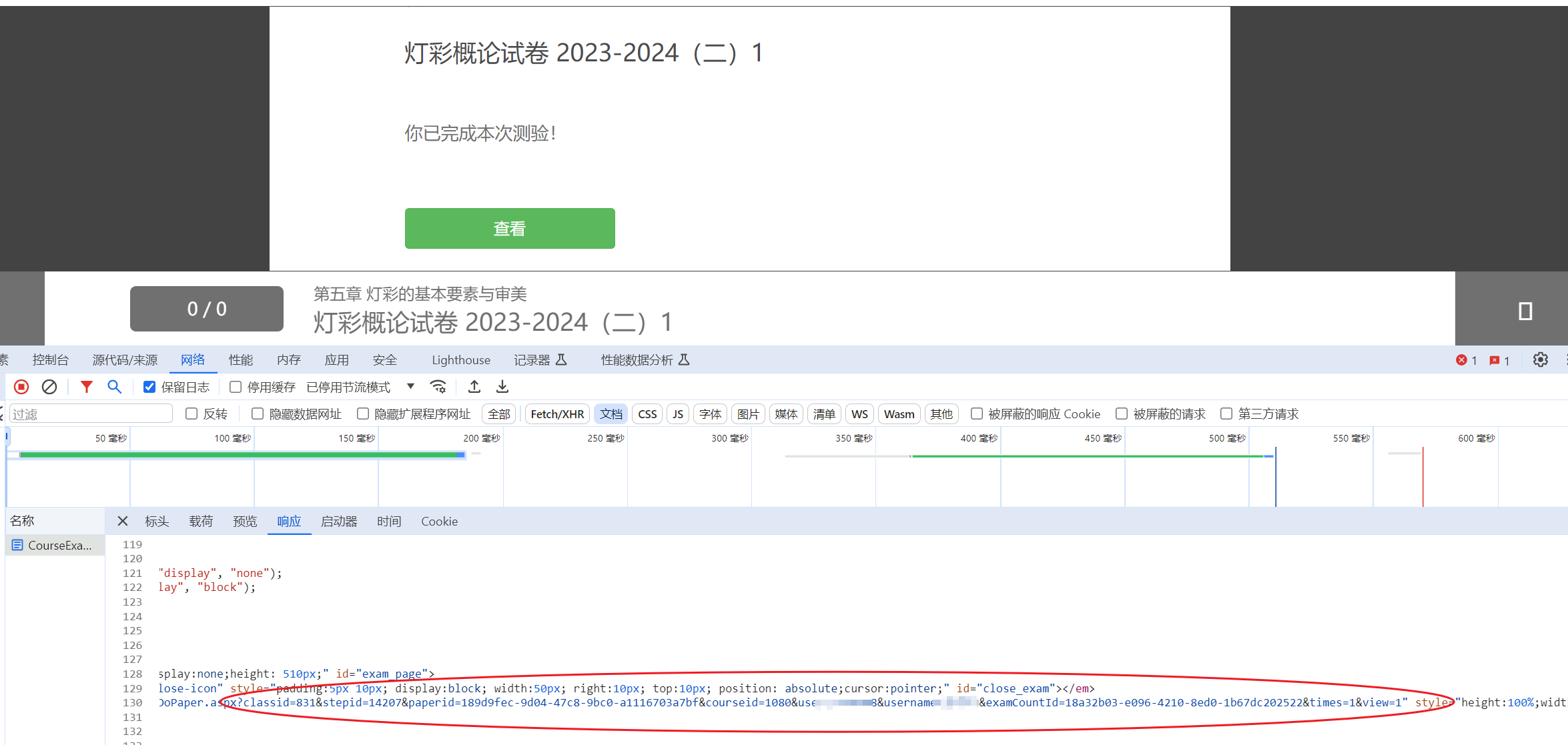
提取答案以及所需参数
查看答案后将响应的文本使用正则表达式提取答案以及参数(后续需要构造表单数据)
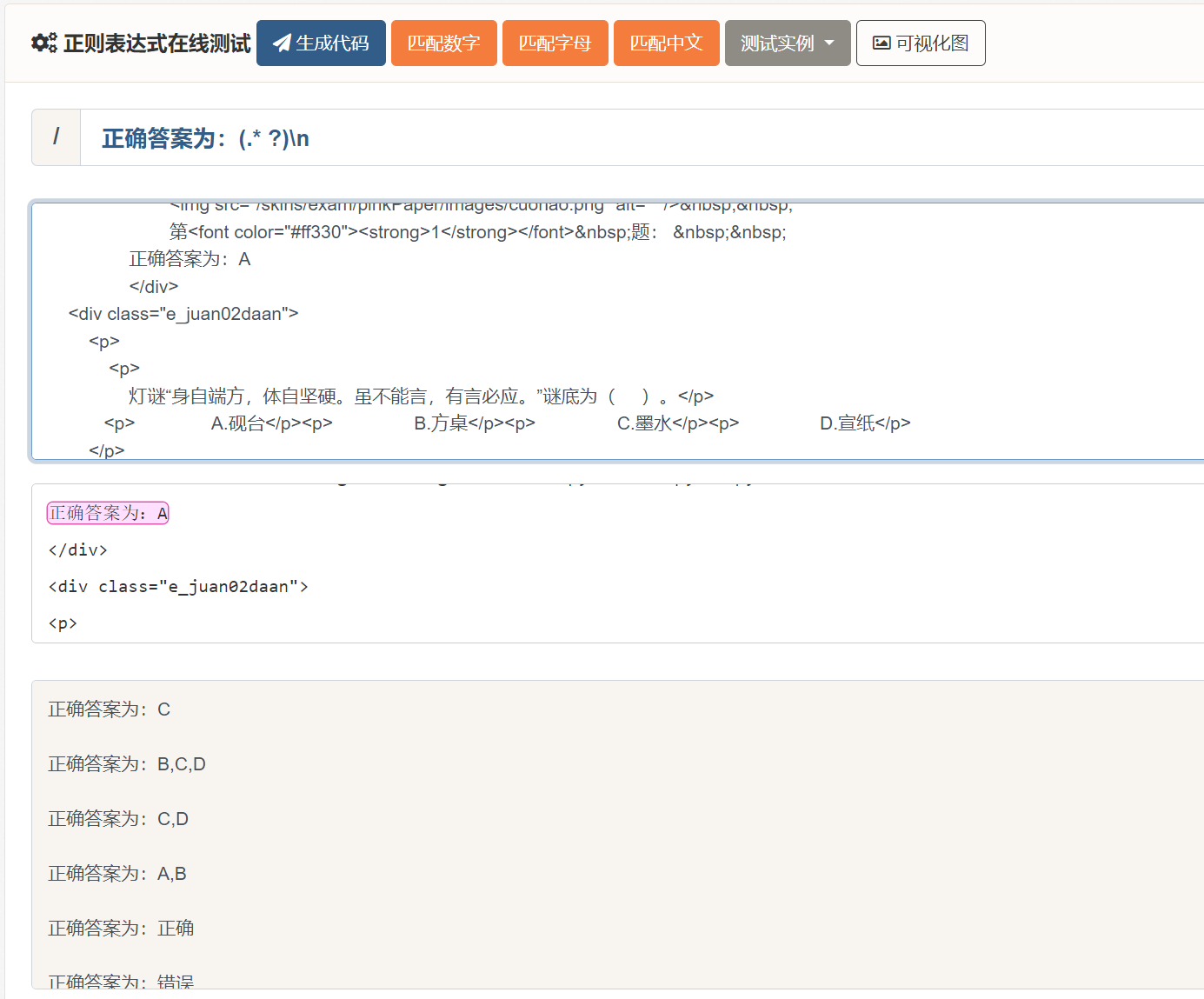
代码如下
#获取正确答案
answer = re.findall(rf'正确答案为:(.* ?)\n', response.text)
#获取每个问题的id值
answerid = re.findall(rf'id="result(.*?)"', response.text)
#获取每个选项的id以及选项的id值
answervalue = re.findall(rf'(A|B|C|D|E|F|).<input name="questionInfoID_(.*?)" value="(.*?)"', response.text)
#获取提交考试答案的url
endexamurl = re.findall(rf'<form name="form1" action="checkpaper.aspx(.*?)"', response.text)
#部分测验有简答题后续需要根据是否有简答题进行判断
jiandati = re.findall(r"简答题", response.text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数据如下
#数据太多部分省略,详细数据请看到最后自行获取
answer=['A\r', 'A\r', 'A\r', 'A\r', 'C\r', 'C\r', 'A\r', 'D\r', 'C\r', 'D\r', 'E\r', 'A\r', 'A\r', 'A,C,D\r', 'A,B\r', 'A,C\r', 'B,D\r', 'C,D\r', 'B,D\r', 'A,B,C,D,E\r', 'A,B,C,D\r', 'C,E\r', '正确\r', '正确\r', '正确\r']
answerid=['02d4b327-3002-4282-aa5b-f015c51a6b60', '124d536e-4610-4751-a431-522f181aa277', '3ba4bc47-338d-4abc-a7eb-96dd176b3972', '3ffa1902-f87b-43e4-b771-500abc7416d0', '5333d142-0a63-4215-a8ac-3338265d175e', '75da608f-0334-4e19-82b0-37d3190e64bd', '92a92b8d-1eb4-4bd8-bc6d-06c73047c8b2', '94d306f5-8069-4941-825b-08aa6efc7069', 'bb8b4c25-991c-418d-92fd-1ce63e8f6fe5', 'c79e8d2e-cf1c-40c2-946a-5b67312eae29', 'd90d63e9-c342-465f-94b7-7d8a44587f77', 'fab4d8d1-29a0-4829-a50c-113e8230c44d', '5daf09cb-d6e7-473a-9bba-e328dd6a870f', '79696994-d556-4117-bb91-e0ebffea498c', '7ed25abe-cef2-45d8-994e-b2d1c9ef5fe8']
answervalue=[('A', '02d4b327-3002-4282-aa5b-f015c51a6b60', '14b77147-540e-4159-9c0c-1f053b34efe0'), ('B', '02d4b327-3002-4282-aa5b-f015c51a6b60', '3de2671c-b31c-4ae5-85a4-f9141123b3ae'), ('C', '02d4b327-3002-4282-aa5b-f015c51a6b60', 'b99ac033-e1b0-41af-bbee-59bb2e9fa239'), ('E', '92a92b8d-1eb4-4bd8-bc6d-06c73047c8b2', 'ffd7d84f-2d03-4492-ab08-31435812156f'), ('A', '94d306f5-8069-4941-825b-08aa6efc7069', '1af4af8a-86b2-4bf0-afc6-f72dcce220c1'), ('', '7ed25abe-cef2-45d8-994e-b2d1c9ef5fe8', '690dde09-699a-4640-a206-01e83c1c7b15'), ('', '7ed25abe-cef2-45d8-994e-b2d1c9ef5fe8', '5af72370-7d47-4b8e-800c-7d822c5cd7c0')]
- 1
- 2
- 3
- 4
提交考试答案
根据以下表单数据以及上述提取的答案进行构建
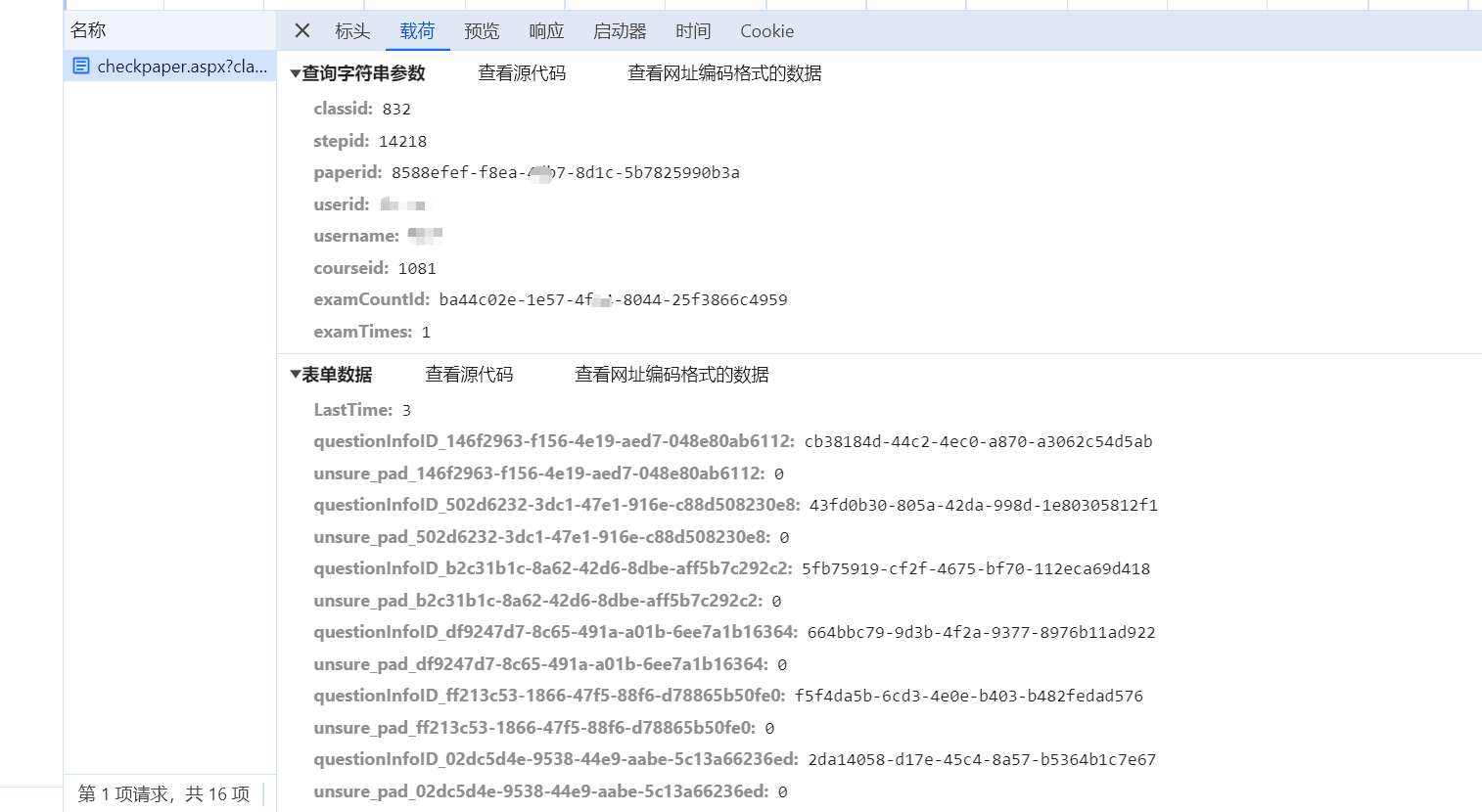
构建表单
newdata = {} newdata["LastTime"] = 3 for i in matched_data: # print(i) if ',' in i[0][0]: # 处理多选题 selected_answers = i[0][0].split(',') # 将多选答案分割成列表 shuzhu = [] for k in selected_answers: for j in i[1]: if k == j[0]: shuzhu.append(j[1]) newdata["questionInfoID_" + i[0][1]] = shuzhu newdata["unsure_pad_" + i[0][1]] = 0 else: if i[0][0] == 'A': newdata["questionInfoID_" + i[0][1]] = i[1][0][1] newdata["unsure_pad_" + i[0][1]] = 0 if i[0][0] == 'B': newdata["questionInfoID_" + i[0][1]] = i[1][1][1] newdata["unsure_pad_" + i[0][1]] = 0 if i[0][0] == 'C': newdata["questionInfoID_" + i[0][1]] = i[1][2][1] newdata["unsure_pad_" + i[0][1]] = 0 if i[0][0] == 'D': newdata["questionInfoID_" + i[0][1]] = i[1][3][1] newdata["unsure_pad_" + i[0][1]] = 0 if i[0][0] == 'E': newdata["questionInfoID_" + i[0][1]] = i[1][4][1] newdata["unsure_pad_" + i[0][1]] = 0 if '正确' == i[0][0]: newdata["questionInfoID_" + i[0][1]] = i[1][0][1] newdata["unsure_pad_" + i[0][1]] = 0 if '错误' == i[0][0]: newdata["questionInfoID_" + i[0][1]] = i[1][1][1] newdata["unsure_pad_" + i[0][1]] = 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
代码如下
#将表单数据newdata以及上述endexamurl传入 def endexam(endexamurl, newdata): headers = { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cache-Control': 'max-age=0', 'Connection': 'keep-alive', 'Content-Type': 'application/x-www-form-urlencoded', 'Origin': 'http://wrggkk.whvcse.edu.cn', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36', } data = newdata response = requests.post( endexamurl, headers=headers, data=data, verify=False, ) print(response.url + "刷测验成功")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
结果:成功
结语
到目前为止该学习网站就已经完结了,难度不大,非常适合新手学习。
文中获取的数据需要进行答案与结果的匹配再进行判断才可以成功,这里留给大家们自行思考。
我本来打算直接将正确答案与选项一起获取,未果,于是选择了分开提取,再合并。
有想试试的小伙伴我这里给出查看答案的页面数据,如果有更好的方法可以在讨论区讨论。
如果有其它学习网站可以在讨论区打出,一起探讨。
https://wwm.lanzn.com/iyLjJ1rp57ef
密码:f2p7

