
- 1maven打包, jdk新语法特性报错的解决方案
- 2【miniQMT实盘量化4】获取实时行情数据_miniqmt 发布订阅
- 32024年前端面试题加答案_2024 最新面前端试题
- 4Android Studio—— SQLite数据库存储(1)_android studiosqlite数据库文件
- 5基于Vue3的Axios异步请求_vue3 axios处理异步请求
- 6【Windows7远程桌面连接的实用技巧】_windows7serverwinstationsrdp-tcp
- 7ElasticSearch客户端操作
- 8UE5-UMG学习笔记_ue5 umg
- 9@Data注解与lombok_loobbok和@data区别
- 10网络安全产品之认识蜜罐_蜜罐 安全设备
RAG的10篇论文-2024Q1
赞
踩
大模型来了,论文都读不过来了。
在大型模型的研究与工程应用领域,变化之迅猛令人瞠目,用“日新月异”来形容似乎都显得有些保守。即便是针对其中的RAG技术,自2024年伊始至今,学界就已经涌现出了很多高质量的研究论文。在这里,老码农挑选了十篇具有代表性的作品,以期对大家的探索和实践提供有益的参考与启示。
1. RAG与微调:流水线、权衡和一个农业案例的研究
论文标题:RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
论文地址:https://arxiv.org/abs/2401.08406
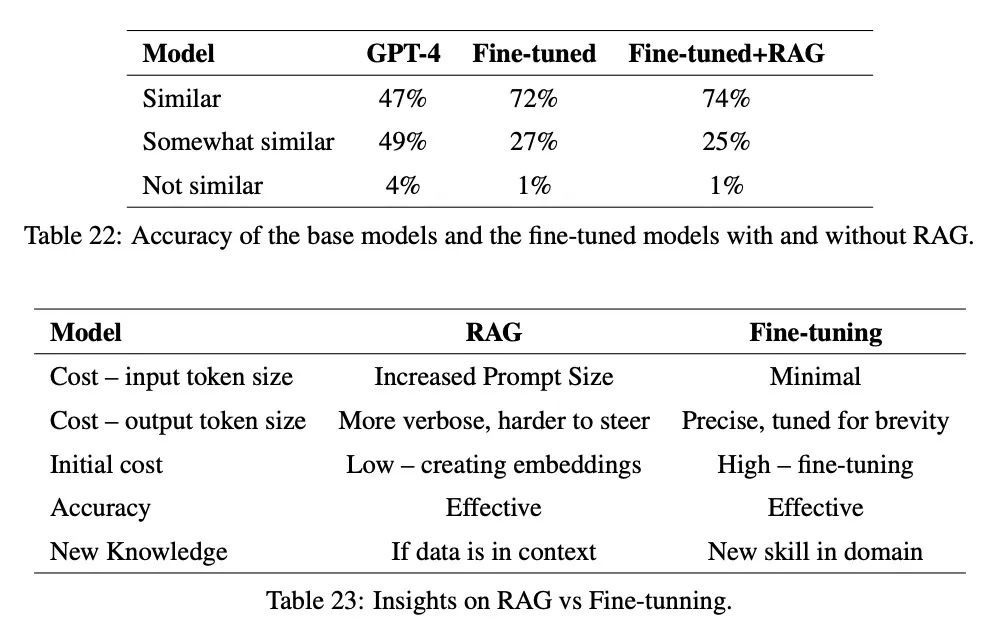
本篇论文深入探讨了开发者如何借助RAG以及微调(FT)将私有数据及特定行业数据融合至大型语言模型(LLM)之中。文中详细阐述了如何将这些技术应用于Llama2-13B、GPT-3.5和GPT-4等主流LLM,重点在于信息的精确提取、问题及答案的生成、模型的微调过程以及效果评估。研究结果显现,通过微调,模型能够有效利用跨域信息,显著提升回答的相关性。此外,本文还强调了LLM在众多工业领域应用的广泛潜力和明显优势。
2. 针对非常见知识的微调与RAG对比
论文标题:Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge
论文地址:https://arxiv.org/pdf/2403.01432.pdf
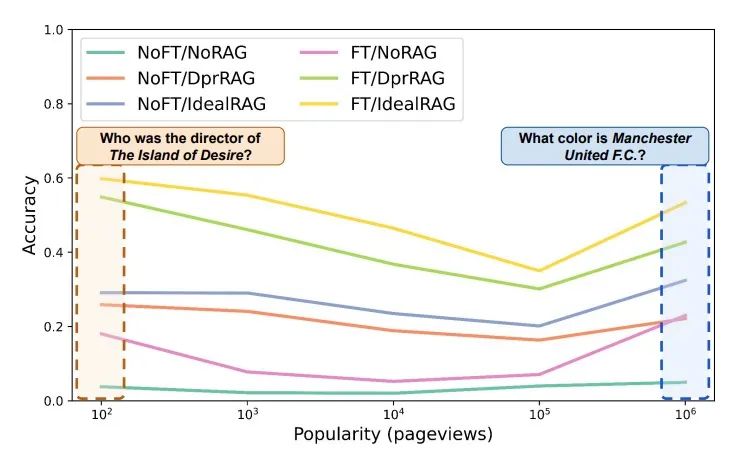
在执行问答任务时,本文深入分析了关系抽取与图构建(RAG)以及微调(FT)这两种方法对于增强大型语言模型(LLM)处理低频实体问题的能力。研究结果表明,尽管微调方法在不同受欢迎程度的实体识别中取得了显著的性能提升,但RAG在性能上更胜一筹,优于其他对比方法。此外,随着检索技术和数据增强技术的不断进步,RAG和FT方法在定制化LLM以应对低频实体方面的能力得到了显著增强。
3. 通过从数万亿token中检索来改进语言模型
论文标题:Improving language models by retrieving from trillions of tokens
论文地址:https://arxiv.org/abs/2112.04426
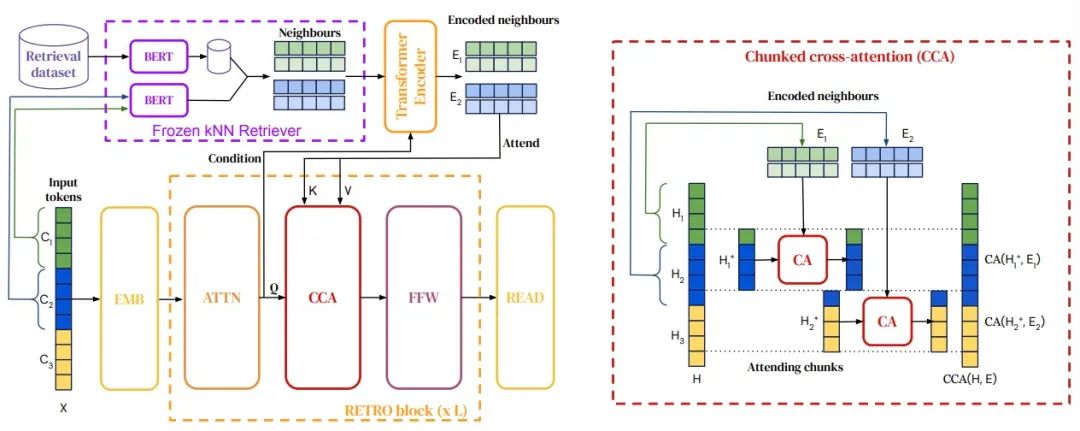
本研究提出了一种创新的RAG Transformer,它通过条件性地处理从庞大语料库中检索出的文本段落,以此增强自回归语言模型的性能。虽然该Transformer相较于现有模型如GPT-3使用的参数大幅减少,但经过微调后,在问题回答等任务上表现出色。这是通过结合一个固定的Bert检索器、可微分编码器以及分块交叉注意力机制实现的,从而在预测阶段能够利用比之前多出一个数量级的数据。这一方法为借助显式记忆来规模性提升LLM能力开辟了新的路径。
4. 将语言模型适应于特定领域的RAG
论文标题:RAFT: Adapting Language Model to Domain Specific RAG
论文地址:https://arxiv.org/abs/2403.10131
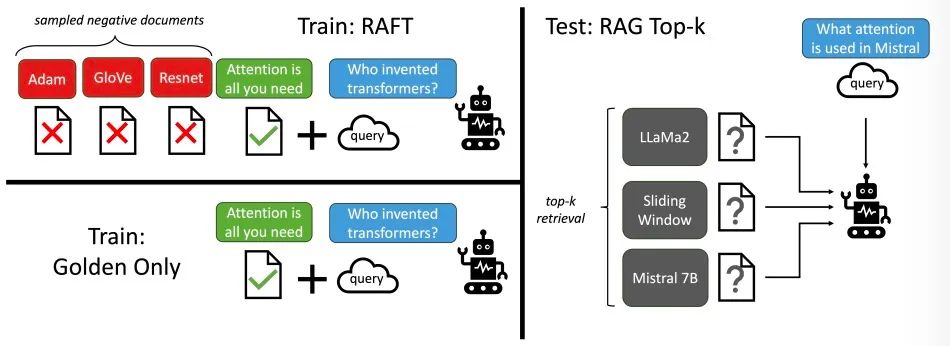
RAFT(Retrieval Augmented FineTuning)是一种创新的训练方法,旨在提升预训练大型语言模型(LLM)在特定领域内回答问题的能力。RAFT专注于对模型进行微调,使其学会在问答过程中忽略那些无关的检索文档,从而灵活地吸收新知识。通过有针对性地整合检索文档中的相关资讯,RAFT显著增强了模型在包括PubMed、HotpotQA和Gorilla等多个数据集上的推理表现和整体性能。
5. 可修正的RAG
论文标题:Corrective Retrieval Augmented Generation
论文地址:https://arxiv.org/abs/2401.15884
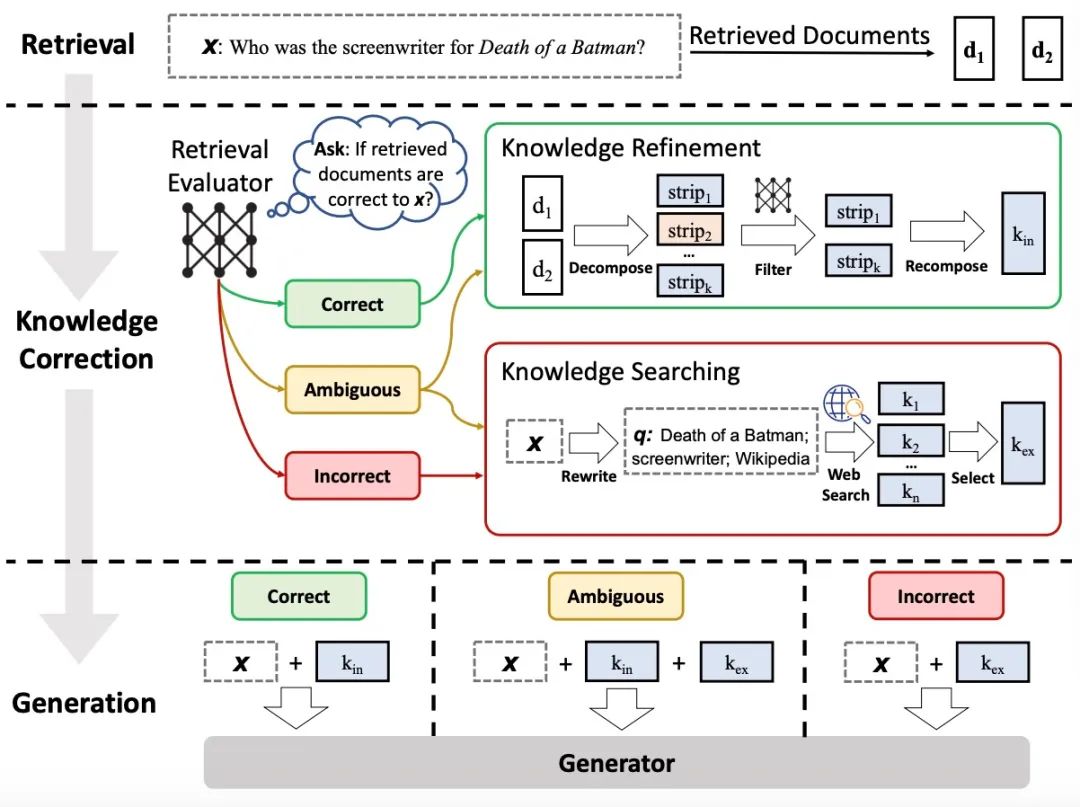
在RAG流程中,本研究引入了一项新颖策略,旨在显著提升大型语言模型的鲁棒性和精确度。针对依赖检索文档相关性可能引发的缺陷,采用了一种检索评估器来对给定查询返回的文档质量和相关性进行量化,进而实施了一种基于置信度的自适应检索机制。为了突破静态数据库的限制,该方法整合了大规模网络搜索资源,为模型提供了一个更加丰富的文档集。此外,其独创的分解再重组算法确保了模型在滤除不相关信息的同时,能够聚焦于抓取关键信息,从而显著提升了内容生成的品质。作为一套通用型的即插即用解决方案,该方法极大地增强了基于RAG的模型在多种生成任务中的处理能力,并通过四个不同数据集上的显著成绩提升得到了验证。
6. 通过迭代自反馈从RAG中学习回答和理解
论文标题:RA-ISF: Learning to Answer and Understand from Retrieval Augmentation via Iterative Self-Feedback
论文地址:https://arxiv.org/abs/2403.06840
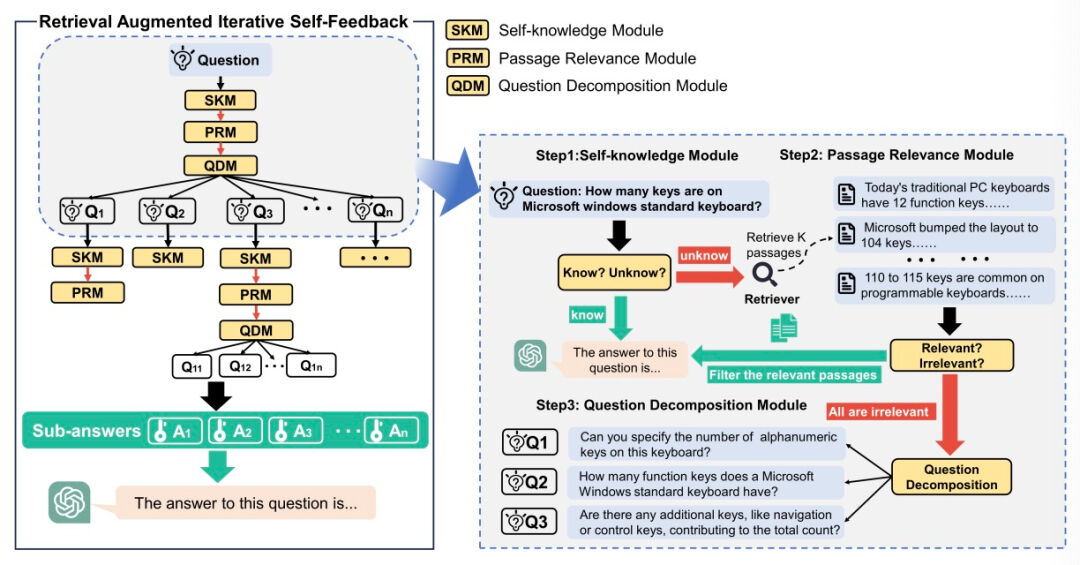
RA-ISF采用了一种迭代自反馈的RAG方法,通过将任务分解并在三个专门的子模块中依次处理,从而显著增强了大型语言模型(LLM)的问题解决效率。实验结果证明,相较于现有的基准模型——包括GPT3.5和Llama2在内——RA-ISF展现出了卓越的性能优势,它在事实性推理方面取得了显著提升,并有效减少了模型产生幻觉的情况。
7. 长时距生成中RAG引发的上下文感知推理
论文标题:RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation
论文地址:https://arxiv.org/abs/2403.05313
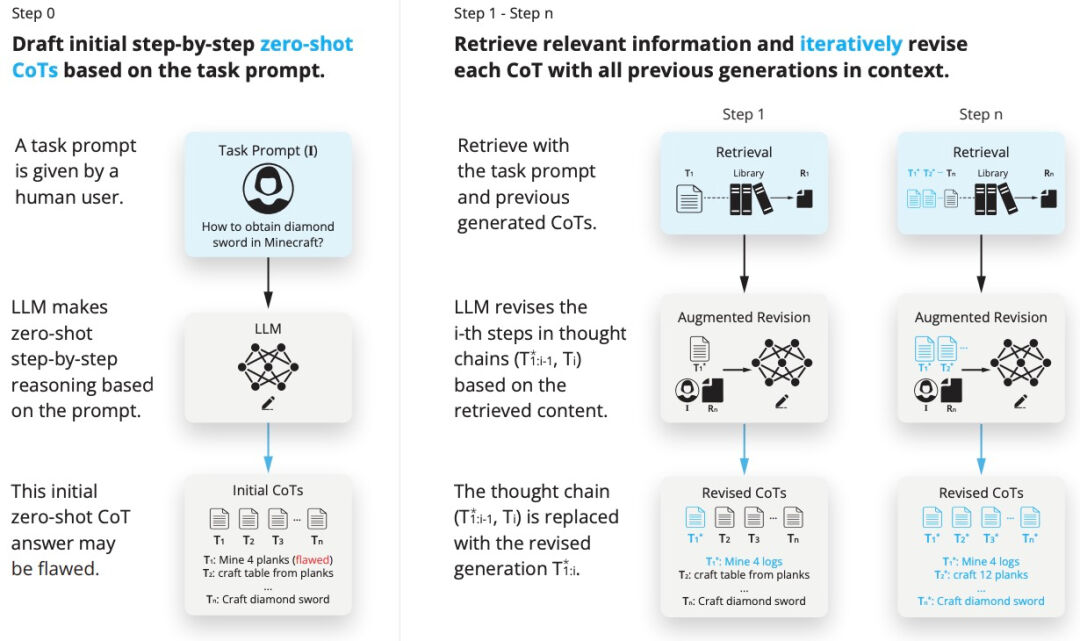
这一方法通过在信息检索过程中以迭代的方式精炼思维链,显著增强了LLM在处理长期依赖任务中的推理与内容生成能力。将RAG技术融入GPT-3.5、GPT-4以及CodeLLaMA-7b等先进模型后,其在多个领域任务上的表现得到了显著提升。具体而言,在代码编写、数学逻辑推理、创意写作以及具体化任务规划等方面,模型的平均评分分别提高了13.63%、16.96%、19.2%和42.78%,展现了其卓越的性能优化效果。
8. 用于大语言模型中幻觉抑制的自适应RAG
论文标题:Retrieve Only When It Needs: Adaptive Retrieval Augmentation for Hallucination Mitigation in Large Language Models
论文地址:https://arxiv.org/abs/2402.10612
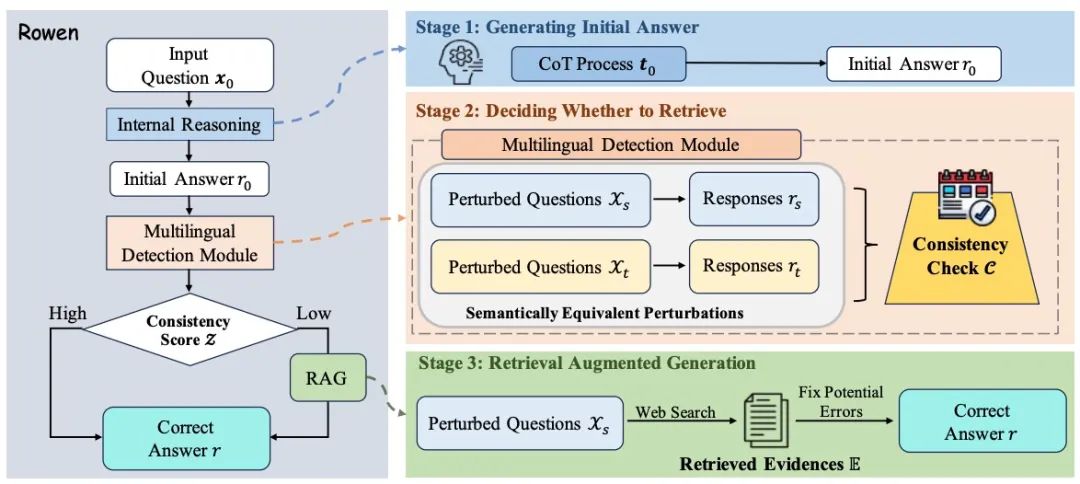
对于LLM而言,幻觉现象是一个严峻的挑战,这主要归咎于其内部知识的局限性。尽管融合外部信息可以在一定程度上缓解这一问题,但这也可能引入与上下文无关的杂乱细节,从而引发所谓的外部幻觉。在识别跨语境不一致性时,通过有选择性地利用检索结果来增强LLM,能够揭示出潜在的幻觉内容。这一语义感知机制恰当地权衡了内在逻辑推理与外部事实证据,有效降低了幻觉发生的几率。经验性分析证实,相较于现行的其他方法,此策略在侦测和消减LLM输出中的幻觉成分方面表现出显著的优势。
9. 树型组织检索的递归抽象处理
论文标题:RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
论文地址:https://arxiv.org/abs/2401.18059
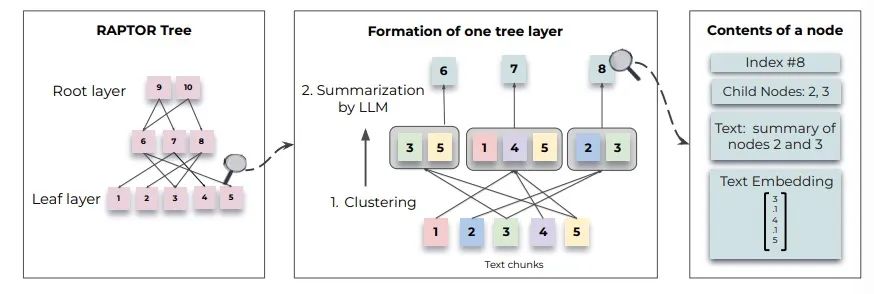
提出了一种创新的检索增强语言建模方法,通过构建一棵分层摘要树,直接从庞大的文档资料中逐层精炼信息。这种方法区别于传统的摘录式提取,它采纳一个递归的过程,在多个层次上对文本内容进行嵌入、分群和概括。这种层次化的处理方法使得我们可以对文档内的资讯进行深度剖析和整合,极大地增强了处理复杂查询的能力,尤其是那些需要多步骤推理的任务。广泛的基准测试表明,这一方法有望彻底革新模型如何存取和利用大型知识库,为问答系统等领域树立了新的典范。
10. 个性化对话系统的统一多源RAG
论文标题:UniMS-RAG: A Unified Multi-source Retrieval-Augmented Generation for Personalized Dialogue Systems
论文地址:https://arxiv.org/abs/2401.13256
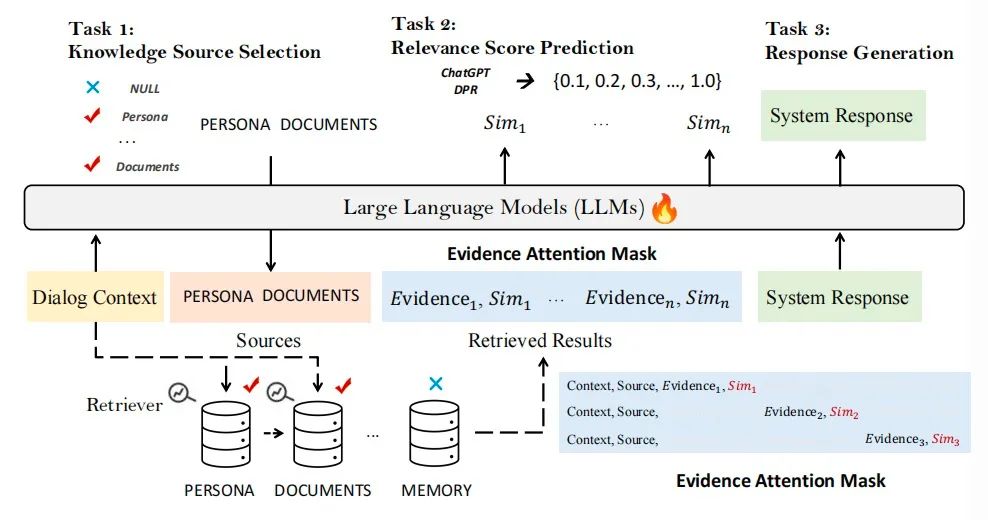
这篇论文设计了一款新型框架,专门针对对话系统中实现个性化的挑战,通过整合多个知识源来进行解决。该框架将任务拆分成三个关键子任务:知识源的选择、知识的检索以及回答的构建,并且在训练阶段将这三个步骤融合为一个连贯的序列到序列的学习范式。这种设计赋予模型利用特定的令牌,动态地检索和评价相关信息,从而促进与众多知识源的有效互动。此外,我们还引入了一种精细自我调整机制,它根据一致性和相关性的评分,对生成的回答进行迭代优化,以提升其质量。
一句话小结
如果希望对RAG的现状有一个相对完整的认识,论文《Retrieval-Augmented Generation for Large Language Models: A Survey》(https://arxiv.org/abs/2312.10997)或许是一个不错的选择,如果需要一个通俗一些的解读,可以参考老码农的《大模型系列——解读RAG》。
【关联阅读】

