
热门标签
热门文章
- 1代码版本管理和提交规范(二)代码提交_软件开发过程中代码提交规范
- 22022年博客之星排行榜 日榜 2023-01-04博客之星 后端排名榜单_个人博客排名
- 3力扣416 分割等和子集 Java版本
- 4C语言完整版笔记(初阶,进阶,深刨,初阶数据结构)_c语言代码速记
- 5保姆级教程:SpringBoot 对接支付宝完成扫码支付,完整流程梳理!_springboot对接支付宝支付
- 6OAuth2.0第三方微信登录_微信auth2.0
- 7【知识图谱】基于neo4j构建医疗领域知识图谱_个人知识体系 neo数据图
- 8PySpark特征工程(I)--数据预处理_pyspark数据预处理
- 9机器学习_深度学习毕设题目汇总——数据分析_数据挖掘_机器学习论文题目
- 10nginx配置密码访问_nginx 配置用户名密码访问
当前位置: article > 正文
手把手教您如何实现英文文本的情感分析-准确度高达82%-98%(新手必看项目)_英文情感分析
作者:Gausst松鼠会 | 2024-06-11 19:15:16
赞
踩
英文情感分析
比赛链接
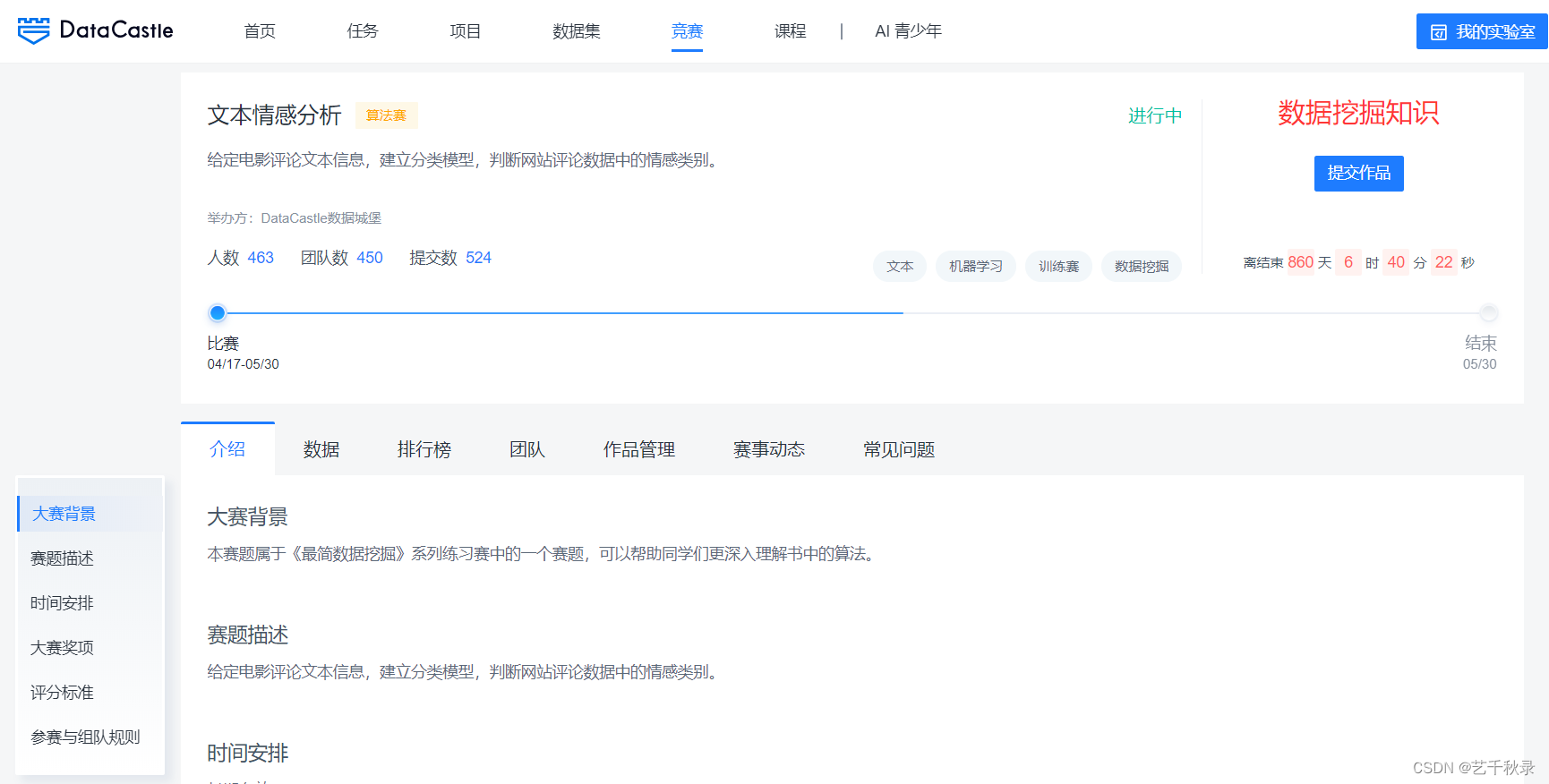
数据集介绍
数据集为英文文本数据,其中Label为其情感标签,正负类样本各有12500个。总计样本数量为两万五千条。
数据预处理
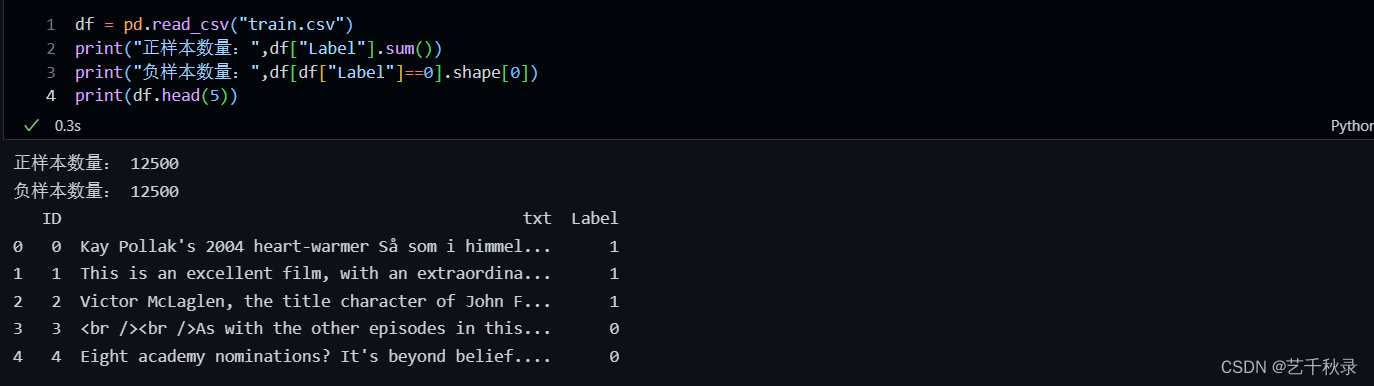
获取停用词表,用于过滤不想关的单词
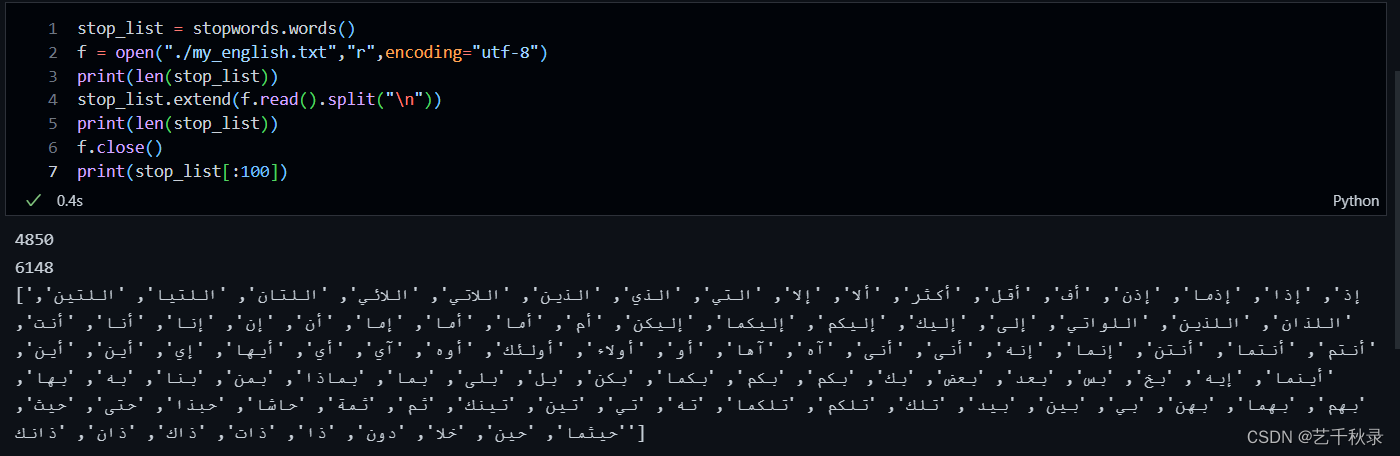
数据分词、词干提取、词性还原、过滤停用词等操作
lemmatizer = nltk.WordNetLemmatizer() strem = PorterStemmer() def is_contain_number(word): for i in range(10): if str(i) in word: return True return False def preprocess_sentence(sentence): # print("开始分词...") processed_tokens = nltk.word_tokenize(sentence) # 词干提取 processed_tokens = [strem.stem(w.lower()) for w in processed_tokens] # print("去除部分tokens...") processed_tokens2 = [w for w in processed_tokens if ((w not in stop_list) and (not is_contain_number(w)))] # print("词性还原...") processed_tokens = [lemmatizer.lemmatize(w) for w in processed_tokens2] return processed_tokens def tokenize(string): if not type(string) is str: return [] return preprocess_sentence(string)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
加载Glove2Word2vec模型
这里的Glove预训练模型官网下载较慢,私聊我可获取完整资料!
from gensim.scripts.glove2word2vec import glove2word2vec
glove_input_file = 'glove.6B.100d.txt'
word2vec_output_file = 'glove.6B.100d.word2vec.txt'
(count, dimensions) = glove2word2vec(glove_input_file, word2vec_output_file)
print(count, '\n', dimensions)
- 1
- 2
- 3
- 4
- 5
根据预训练模型的词典对数据进行过滤,并保证数据长度一致,过长的数据将其截断,过短的数据则以“PAD”为填充符。
max_seq_len = 0
for i,sentence in enumerate(tqdm(sentence_list)):
sent_list = sentence.split()
sent_list = [x for x in sent_list if x in word2idx.keys()]
max_seq_len = max(max_seq_len,len(sent_list))
sentence_list[i] = " ".join(sent_list)
print(max_seq_len)
max_seq_len = min(max_seq_len,200)
print(max_seq_len)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如下所示:


将单词转化为字典序号
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
def make_data(sentences, labels):
inputs = []
for sen in tqdm(sentences):
inputs.append([word2idx[n] for n in sen.split()])
targets = labels.tolist()
return np.array(inputs), np.array(targets)
input_batch, target_batch = make_data(sentence_list, labels)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
构建模型
class Bi_Lstm(nn.Module): def __init__(self): super(Bi_Lstm,self).__init__() self.embeddings = torch.tensor(glove_model.vectors) self.add_embedding('<PAD>') self.embeding = nn.Embedding(self.embeddings.shape[0],self.embeddings.shape[1], padding_idx=word2idx['<PAD>']) self.embeding.weight.data.copy_(self.embeddings) self.embeding.weight.requires_grad = False self.lstm = nn.LSTM(input_size = self.embeddings.shape[1], hidden_size = 100,num_layers = 2, bidirectional = True, batch_first=True, dropout=0.3)#加了双向,输出的节点数翻2倍 self.l1 = nn.BatchNorm1d(self.embeddings.shape[1]*2) self.l2 = nn.ReLU() self.dense = nn.Sequential( nn.Linear(self.embeddings.shape[1]*2,128), nn.BatchNorm1d(128), nn.Dropout(0.2), nn.Linear(128,64), nn.BatchNorm1d(64), nn.Linear(64,n_class), nn.BatchNorm1d(n_class) ) def add_embedding(self, word): vector = torch.empty(1, self.embeddings.shape[1])#生成空的 torch.nn.init.uniform_(vector)#随机生成 self.embeddings = torch.cat([self.embeddings, vector], 0)#在embedding_matrix中加入新的vector def forward(self, x): x = self.embeding(x) out,_ = self.lstm(x) #选择最后一个时间点的output out = self.l1(out[:,-1,:]) out = self.l2(out) out = self.dense(out) return out
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
开始训练
from sklearn.metrics import classification_report, confusion_matrix import warnings warnings.filterwarnings("ignore") training_step = 50#迭代次数 batch_size = 512#每个批次的大小 kf = KFold(n_splits=5)#5折交叉验证 def res2array(xx): data = [] [data.extend(x.tolist()) for x in xx] return np.array(data) for fold, (train_idx, test_idx) in enumerate(kf.split(train, targets)): max_acc = 0.0 print('-'*15, '>', f'Fold {fold+1}', '<', '-'*15) x_train, x_val = train[train_idx], train[test_idx] y_train, y_val = targets[train_idx], targets[test_idx] M_train = len(x_train)-1 x_train = torch.from_numpy(x_train).to(torch.long).to(device) x_val = torch.from_numpy(x_val).to(torch.long).to(device) y_train = torch.from_numpy(y_train).to(torch.long).to(device) y_val = torch.from_numpy(y_val).to(torch.long).to(device) model = Bi_Lstm() model.to(device) optimizer = torch.optim.Adam(model.parameters(),lr=0.001) loss_func = nn.CrossEntropyLoss()#多分类的任务 model.train()#模型中有BN和Droupout一定要添加这个说明 #开始迭代 for step in range(training_step): ytrain_pre_epoch = [] ytrain_true_epoch = [] yval_pre_epoch = [] yval_true_epoch = [] train_acc_per_epoch = 0.0 val_acc_per_epoch = 0.0 train_loss_per_epoch = 0.0 val_loss_per_epoch = 0.0 all_step = 0 with tqdm(np.arange(0,M_train,batch_size), desc='Training...') as tbar: for index in tbar: L = index R = min(M_train,index+batch_size) if (R-L) <= 1: continue #-----------------训练内容------------------ model.train() optimizer.zero_grad() # 清空上一步的残余更新参数值 train_pre = model(x_train[L:R]) # 喂给 model训练数据 x, 输出预测值 train_loss = loss_func(train_pre, y_train[L:R]) #-----------------反向传播更新--------------- train_loss.backward() # 以训练集的误差进行反向传播, 计算参数更新值 optimizer.step() # 将参数更新值施加到 net 的 parameters 上 #----------- -----计算准确率---------------- ytrain_pre = np.argmax(np.array(train_pre.data.cpu()),axis=1) train_true = np.array(y_train[L:R].data.cpu()) ytrain_pre_epoch.append(ytrain_pre) ytrain_true_epoch.append(train_true) train_acc = np.sum(np.argmax(np.array(train_pre.data.cpu()),axis=1) == np.array(y_train[L:R].data.cpu()))/(R-L) #---------------打印在进度条上-------------- tbar.set_postfix( train_loss=float(train_loss.data.cpu()), train_acc=train_acc ) tbar.update() # 默认参数n=1,每update一次,进度+n train_acc_per_epoch += train_acc train_loss_per_epoch += train_loss.data.cpu() all_step += 1 # --------------------每个epoch结束就要验证一次模型的准确度----------------------------- with torch.no_grad(): M_val = len(x_val) - 1 all_step = 0 with tqdm(np.arange(0,M_val,batch_size), desc='Validation...') as tbar: for index in tbar: L_val = index R_val = min(M_val,L_val + batch_size) if (R_val-L_val) <= 1: continue #-----------------验证------------------ model.eval() val_pre = model(x_val[L_val:R_val])#验证集也得分批次,不然数据量太大内存爆炸 val_loss = loss_func(val_pre, y_val[L_val:R_val]) yval_pre = np.argmax(np.array(val_pre.data.cpu()),axis=1) val_true = np.array(y_val[L_val:R_val].data.cpu()) yval_pre_epoch.append(yval_pre) yval_true_epoch.append(val_true) val_acc = np.sum(np.argmax(np.array(val_pre.data.cpu()),axis=1) == np.array(y_val[L_val:R_val].data.cpu()))/(R_val-L_val) #---------------打印在进度条上-------------- tbar.set_postfix( val_loss=float(val_loss.data.cpu()), val_acc=val_acc ) tbar.update() # 默认参数n=1,每update一次,进度+n val_acc_per_epoch += val_acc val_loss_per_epoch += val_loss.data.cpu() all_step += 1 res = classification_report(res2array(ytrain_pre_epoch),res2array(ytrain_true_epoch),digits=3,output_dict=True) # print(res) train_stat = res["weighted avg"] train_stat["accuracy"] = res["accuracy"] res = classification_report(res2array(yval_pre_epoch),res2array(yval_true_epoch),digits=3,output_dict=True) # print(res) val_stat = res["weighted avg"] val_stat["accuracy"] = res["accuracy"] print("Epoch %d/%d: trainning acc: %.3f validation acc: %.3f"%(step,training_step,train_stat["accuracy"],val_stat["accuracy"])) model_path = "model_fold_"+str(fold)+".pt" if res["accuracy"] > max_acc: max_acc = res["accuracy"] torch.save(model,model_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
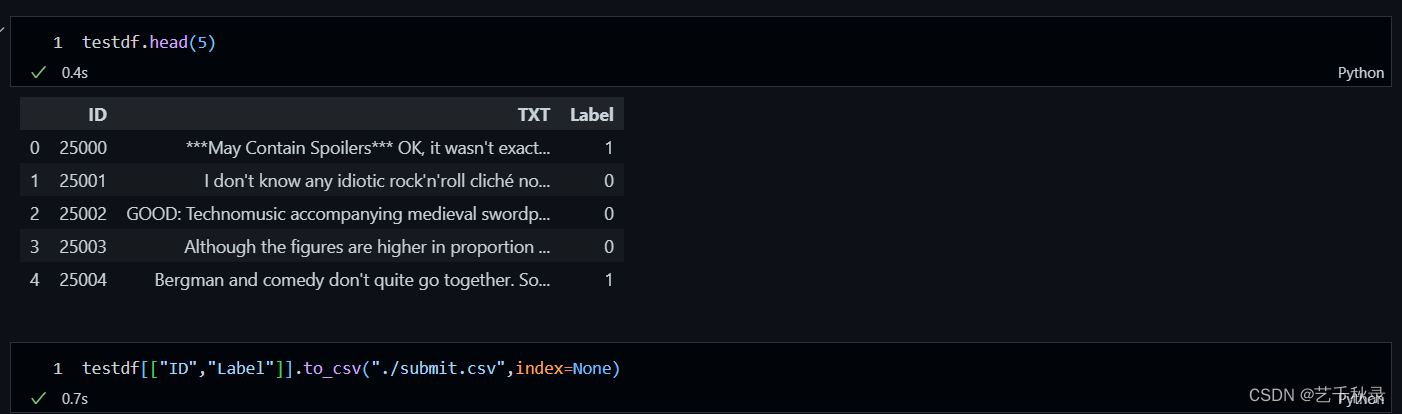
提交测试结果

声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

