
热门标签
热门文章
- 1小程序展开收起
- 2如何在前端实现WebSocket发送和接收TCP消息(多线程模式)
- 3Elasticsearch的使用RestHighLevelClient_elasticsearch-rest-high-level-client 使用教程
- 4STM32完美移植RT-Thread实时操作系统_rtconfig.h
- 5注解处理器、ServiceLoader 开发SpringCloud启动参数拓展类_implements launcherservice
- 6带你深入浅出Vue
- 7Windows 服务资料不错_cserctrl.writetolog vc
- 8校验 ChatGPT 4.0 真实性的三个经典问题:快速区分 GPT3.5 与 GPT4,并提供免费测试网站_gpt4.0测试csdn
- 9C语言:通过自定义函数实现查找功能_c语言查找函数怎么写
- 10对于超出一行的文本进行(展开/收起)操作的vue组件,实测好用_vue 判断内容是否超过一行
当前位置: article > 正文
1.0数据采集与预处理概述
作者:Gausst松鼠会 | 2024-02-16 00:53:02
赞
踩
数据采集与预处理
大数据的来源:
1.搜索引擎数据
2.电商交易数据
3.社交网络数据
4.物联网传感器数据
5.网站日志数据
数据采集的概念:
数据采集的ETL 工具负责将分布的、异构数据源中的不同种类,和结构的数据如文本数据、关系数据以及图片、视频等非结构化数据等抽取到临时中间层后进行
清洗、转换、分类、集成
,最后加载
到对应的数据存储系统如
数据仓库
中,成为
联机分析处理
、数据挖掘的基础。
数据采集来源:
根据MapReduce 产生数据的应用系统分类,大数据的采集主要有四种来源:管理信息系统、web信息系统、物理信息系统、科学实验系统。
(1)管理信息系统
管理信息系统是指企业、机关内部的信息系统,如事务处理系统、办公自动化系统,主要用于经营和管理,为特定用户的工作和业务提供支持。数据的产生既有终端用户的始输人,也有系统的二次加工处理。系统的组织结构上是专用的,数据通常是结构化的。
(2) Web信息系统
web信息系统包括互联网上的各种信息系统,如社交网站、社会媒体、系统引擎等,主要用于构造虚拟的信息空间,为广大用户提供信息服务和社交服务。系统的组织结构是开放式的,大部分数据是半结构化或无结构的。数据的产生者主要是在线用户。
(3)物理信息系统
物理信息系统是指关于各种物理对象和物理过程的信息系统,如实时监控、实时检测,主要用于生产调度、过程控制、现场指挥、环境保护等。系统的组织结构上是封闭的,数据由各种嵌入式传感设备产生,可以是关于物理、化学、生物等性质和状态的基本测量值,也可以是关于行为和状态的音频、视频等多媒体数据。
(4)科学实验系统
科学实验系统实际上也属于物理信息系统,但其实验环境是 预先设定的,主要用于研究和学术,数据是有选择的、可控的, 有时可能是人工模拟生成的仿真数据。数据往往表现为具有不同形式的数据。
数据采集方法:
①系统日志采集方法
很多互联网企业都有自己的海量数据采集工具,多用于系统日志采集,如Hadoop的Chukwa、Cloudera 的
Flume
、 Facebook 的Scribe 等这些工具均采用分布式架构,能满足每秒数百MB 的日志数据采集和传输需求。
②网络数据采集方法
对非结构化数据的采集网络数据采集是指通过网络爬虫或网站公开API等方式从网站上获取数据信息,该方法可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。它支持图片、音频、视频等文件或附件的采集,附件与正文可以自动关联。 除了网络中包含的内容之外,对于网络流量的采集可以使用DPI或DFI等带宽管理技术进行处理。(
urllib and beautifulsoup)
③其他数据采集方法
对于企业生产经营数据或学科研究数据等保密性要求较高的数据,可以通过与企业、研究机构合作或授权的方式,使用特定系统接口等相关方式采集数据。
Scrapy的常用命令
startproject 创建一个新工程 scrapy startproject<name>[dir]
genspider 创建一个爬虫 scrapy genspider[options]<name><domain>
settings 获得爬虫配置信息 scrapy settings[options]
crawl 运行一个爬虫 scrapy crawl<spider>
list 列出工程中所有的爬虫 scrapy list
shell 启动URL调试命令行 scrapy shell [url]
flume系统日志环境的搭建
Flume是Cloudera提供的一个
高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统
,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方 (可定制)的能力。
主要功能:
实时读取服务器本地磁盘的数据,将数据写入到HDFS上。
服务器本地磁盘的数据来源:Python爬虫数据和Java后台日志数据。
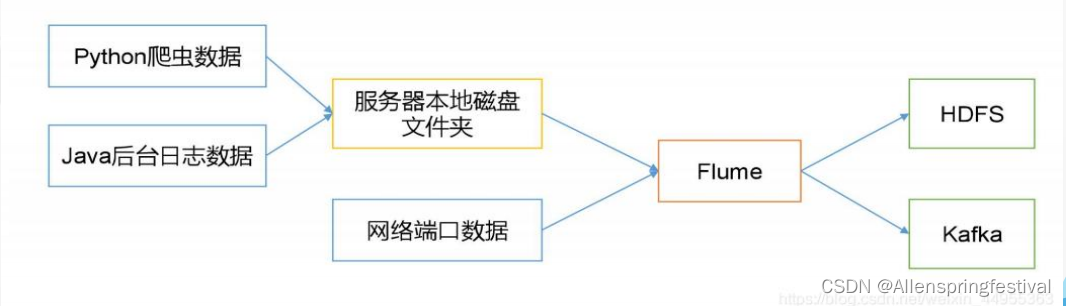
Flume的一些核心概念:

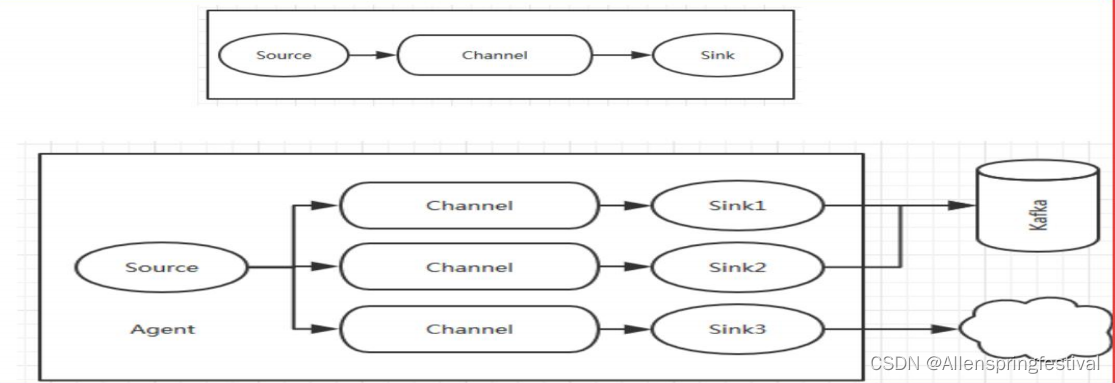
最简单的图一定要会画。
Ø
Client:Client生产数据,运行在一个独立的线程。
Ø
Event:
一个数据单元,消息头和消息体组成。
(Events可以是日志记录、 avro 对象等。)
Ø
Flow: Event从源点到达目的点的迁移的抽象。
Ø
Agent:
一个Flume进程包含Source,Channel,Sink(
Agent使用JVM 运行Flume。
每台机器运行一个agent,但是可以在一个 agent中包含多个sources和sinks。
)
Ø
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Ø
Channel:
转Event的一个临时存储
,保存由Source组件传递过来的 Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
Ø
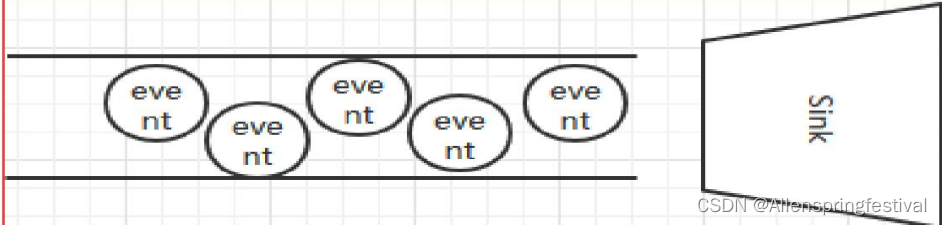
Sink: 从Channel中读取并移除Event,
将Event传递到FlowPipeline中的下一个Agent
(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
Agent:
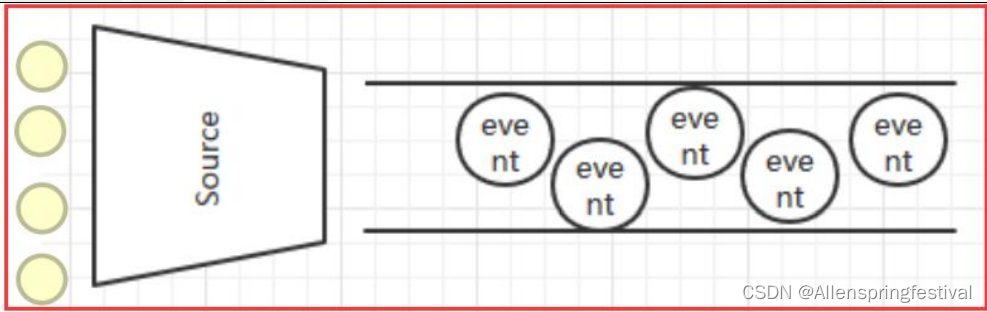

Flume的运行核心是以agent为最小的独立运行单位。
一个
agent
就是一 个JVM
。它是一个完整的数据收集工具,含有三个核心组件,分别是
source
、
channel
、 sink。通过这些组件,
Event
可以从一个地方流向另一个地方,如上图图所示。
Source
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如 AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
Channel
Channel是连接Source和Sink的组件
,可以将它看做
一个数据的缓冲区(数据队列)
,它可以
将事件暂存到内存中也可以持久化到本地磁盘上
, 直到Sink处理完该事件。介绍两个较为常用的Channel, MemoryChannel和FileChannel。
Sink
Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
两个重要的概念:
Flume拦截器和Flume数据流
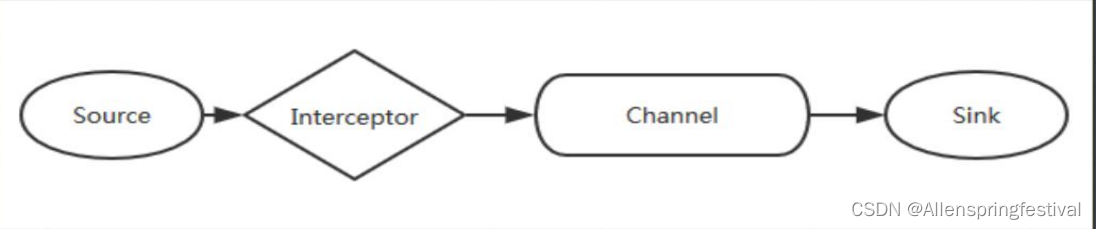
1.Flume拦截器
当我们需要对数据进行过滤时,除了我们在Source、 Channel和Sink进行代码修改之外, Flume为我们提供了拦截器,
拦截器也是chain形式的
。 拦截器的位置
在Source和Channel之间
,当我们为Source指定拦截器后, 我们在拦截器中会得到event,根据需求我们可以对event进行保留还是抛弃, 抛弃的数据不会进入Channel中。
2.Flume数据流
1)Flume 的核心是
把数据从数据源收集过来,再送到目的地
。为了保证输送一定成功,在送到目的地之前
,会
先缓存数据,待数据真正到达目的地后,删除自己缓存的数据
。
2) Flume 传输的数据的基本单位是
Event
,如果是文本文件,通常是一行记录,这也是
事务的基本单位。
Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。
Event 代 表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去
。
3. Flume的可靠性
Sink
必须
在
Event
被存入
Channel
后
,或者,
已经被传达到下一站 agent里
,又或者,
已经被存入外部数据目的地之后
,才能把
Event
从 Channel 中
remove
掉。这样
数据流里的
event
无论是在一个
agent
里还 是多个 agent
之间流转,都能保证可靠,因为以上的事务保证了
event
会 被成功存储起来
。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Gausst松鼠会/article/detail/89049
推荐阅读
相关标签

