
- 1只知道Vue嘛?来看看微软的Blazor
- 2leetcode 第188场周赛_leetcode周赛188
- 3python3 多进程讲解 multiprocessing_python3 multiprocessing
- 4C语言强化-1.数据结构概述
- 5数据中台的数据库技术和数据仓库技术
- 6数据结构:链表和经典链表OJ题合集(纯享版)
- 7深入了解适用于 Oracle 和 SQL Server 的 Amazon RDS 和 RDS Custom_aws oracle rds
- 8Spring Boot - 整合Actuator_endpoint.health.show-details: always
- 9NodeJS 入门
- 10小程序 · 订阅消息_requestsubscribemessage
大话数据结构--线性表(1)
赞
踩
表长加1。
/初始条件:顺序线性表L已存在,1≤i≤ListLength(L),/
/操作结果:在L中第i个位置之前插入新的数据元素e, L的长度加1/
Status ListInsert (SqList *L,int i, ElemType e)
{
int k;
if (L->length==MAXSIZE) /顺序线性表已经满/
return ERROR;
if(i<1 || i>L->length+1) /当i不在范围内时/
return ERROR;
if (i<=L->length) /若插入数据位置不在表尾/
{
for (k=L->length-l;k>=i-1;k–)/将要插入位置后数据元素向后移动一位/
L->data[k+1]-L->data[k];
}
L->data[i-1]=e; /将新元素插入/
L-> length++;
return OK;
}
书上讲的例子很有意思,哈哈哈哈!!!
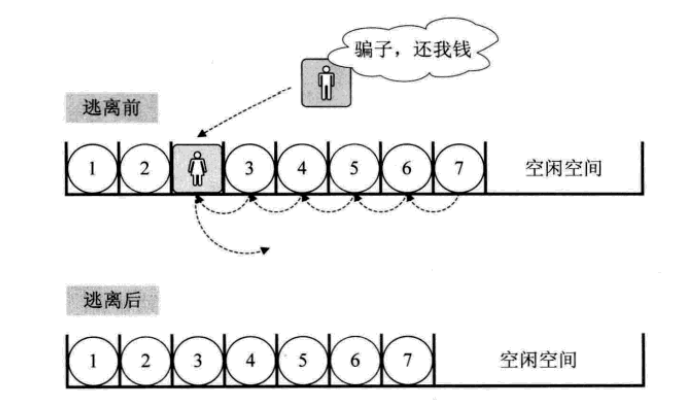
删除算法的思路:
如果删除位置不合理,抛出异常;
取出删除元素;
从删除元素 位置开始遍历到最后-一个元素 位置,分别将它们都向前移动一个位置;
表长减1
/初始条件:顺序线性表L已存在,1≤i≤ListLength(L),/
/操作结果:删除在L中第i个数据元素,并用e返回其值, L的长度减1/
Status ListDelete(SqList *L,int i, ElemType *e)
{
int k;
if (L->length==0) /顺序线性表已经满/
return ERROR;
if(i<1 || i>L->length+1) /当i不在范围内时/
return ERROR;
if (i<=L->length) /若数据位置不在表尾/
{
for (k = i;k < L->length;k++)/将要插入位置后数据元素向后移动一位/
L->data[k+1]-L->data[k];
}
L->data[i-1]=e; /将新元素插入/
L-> length++;
return OK;
}
下面讨论下时间复杂度
当要插入或删除的元素在最后一个位置,那么时间复杂度为O(1),因为不需要移动元素
最坏的情况当然是插入或删除第一个元素,此时所有的元素都要向后移,时间复杂度为O(n)
以上平均下来,为(n-1)/2
通过前面讨论过时间复杂度的推导,可以得出,平均时间复杂度还是0[n)。这说明什么?线性表的顺序存储结构,在存、读数据时,不管是哪个位置,时间复杂度都是0(1);而插入或删除时,时间复杂度都是0[n)。**这就说明,它比较适合元素个数不太变化,而更多是存取数据的应用。**当然,它的优缺点还不只这些…

=============================================================================
前面讲的线性表的顺序存储结构。它是有缺点的,最大的缺点就是插入和删除时需要移动大量元素,这显然就需要耗费时间。能不能想办法解决呢?
为什么当插入和删除时,就要移动大量元素,仔细分析后,发现原因就在于相邻两元素的存储位置也具有邻居关系,他们在内存中也是挨着的,中级没有空袭,当然就无法快速介入,而删除后,当中就会留出空隙,自然需要弥补。
干脆所有元素都不要考虑相邻位置了,哪里有空位就到哪里,而只是让每个元素知道它下一个元素的位置,这样就可以在第一个元素时,就知道第二个元素的位置(内存地址),在第二个元素时,再找到第三个的位置(内存地址)
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置
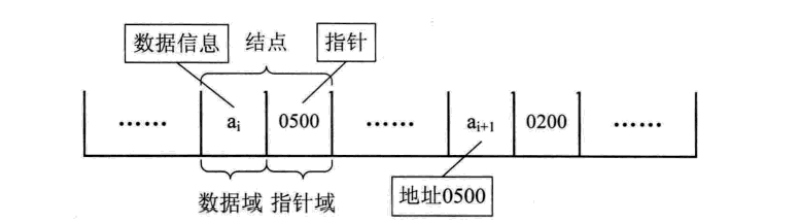
以前在顺序结构中,每个数据元素只需要存数据元素信息就可以了。现在链式结构中,除了要存数据元素信息外,还要存储它的后继元素的存储地址。
1.数据域和指针域
因此,为了表示每个数据元素ai 与其直接后继数据元素ai+1 之间的逻辑关系,对数据元素ai来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称做指针或链。这两部分信息组成数据元素ai的存储映像,称为结点(Node)。
书上说的太好了,看书真的比看视频更有收获!!!
同学们,快去看书吧!
n个结点(a的存储映像)链结成一个链表,即为线性表(a1, a2, an)的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。单链表正是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起
2.头指针
对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中第一个结点的存储位置叫做头指针,那么整个链表的存取就必须是从头指针开始进行了。之后的每一个结点,其实就是上一个的后继指针指向的位置。想象一下,最后一个结点,它的指针指向哪里?最后一个,当然就意味着直接后继不存在了,所以我们规定,线性链表的最后一个结点指针为“空”(通常用NULL或“^”符号表示)。
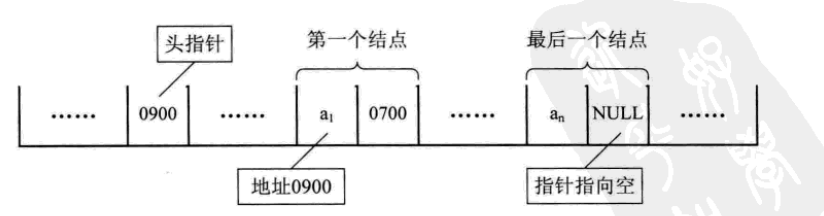
有时,我们为了更加方便地对链表进行操作,**会在单链表的第一个结点前附设一个结点,称为头结点。**头结点的数据域可以不存储任何信息,谁叫它是第一个呢,有这个特权。也可以存储如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针
异同点如下:

/线性表的单链表存储结构/
typedef struct Node
{
ElemType data;
struct Node *next;
} Node;
typedef struct Node *LinkList; /定义 LinkList/
从这个结构定义中,我们也就知道,结点由存放数据元素的数据域和存放后继结点地址的指针域组成。
假设p是指向线性表第i个元素的指针,则该结点ai的数据域我们可以用p->data来表示,p->data的值是一个数据元素,结点ai的指针域可以用p->next来表示,p->next 的值是一个指针。p->next指向谁呢?当然是指向第i+1个元素,即指向ai+1 的指针也就是说,如果p->data=ai,那么p->next->data=ai+1
上面这段话需要反复咀嚼!!!甚至自己可以拿笔画一下,多画几次就记住了~
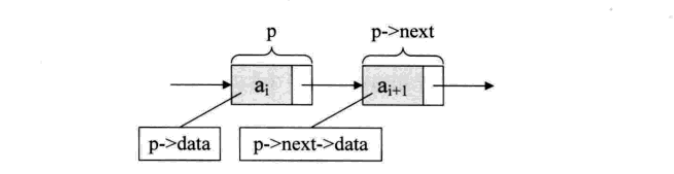
p指针一个结点,相当于干了两件事
分别是指向了结点的数据域与和指针域
指向数据域是p->data
指向指针域是指针域里本来有个指针,p呢,它又指向这个指针,这个指针呢有指向下一个结点的data所以就有了上面这个图
以此类推
太详细了有木有啊~!!!
=========================================================================
在线性表的顺序存储结构中,我们要计算任意-一个元素的存储位置是很容易的。但在单链表中,由于第i个元素到底在哪?没办法-开始就知道,必须得从头开始找。因此,对于单链表实现获取第i个元素的数据的操作GetElem,在算法上,相对要麻烦一些。
获得链表第i个数据的算法思路:
1.声明一个结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一结点,j 累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,返回结点p的数据。.
/*初始条件:顺序线性表L已存在,1≤i≤ListLength (L) */
/操作结果:用e返回L中第i个数据元素的值/
Status GetElem ( LinkList L,int i, ElemType*e)
{
int j;
LinkList P; /声明一结点 p/
P= L->next; /让p指向链表L的第一个结点/
j=1; /j为计数器/
while (p && j<i) /p不为空或者计数器j还没有等于i时,循环继续/
{
p= p->next; /让p指向下一个结点/
++j;
}
if (!pHI j>i )
return ERROR; /第i个元素不存在/
*e = p->data; /取第i个元素的数据/
return OK;
}
说白了,就是从头开始找,直到第i个元素为止。由于这个算法的时间复杂度取
决于i的位置,当i=1时,则不需遍历,第一个就取出数据了,而当i=n时则遍历n-1次才可以。因此最坏情况的时间复杂度是O(n)。
由于单链表的结构中没有定义表长,所以不能事先知道要循环多少次,因此也就不方便使用for来控制循环。其主要核心思想就是‘工作指针后移”, 这其实也是很多算法的常用技术。
============================================================================
先来看单链表的插入。假设存储元素e的结点为s,要实现结点p、p->next 和s .
之间逻辑关系的变化,只需将结点s插入到结点p和p->next之间即可。可如何插入呢?
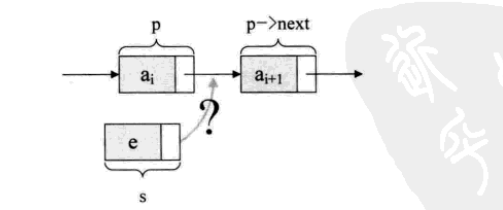
根本用不着惊动其他结点,只需要让s->next和p->next的指针做一点改 变即可。
s->next=p->next; p->next=s;
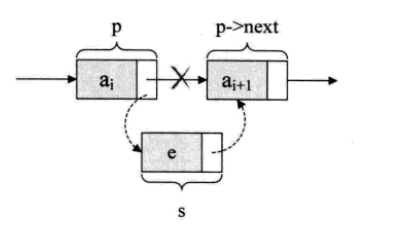
就是说让p的后继节节点改成s的后继节点,再把s变成p的后继节点
这段话需要多去体会,看不懂的可以再往前复习一下!很久好理解的
如果先p->next = s;再s->next= p->next行不行呢?
不行哦,因为第一句会使得p->next给覆盖成s的地址了。那么s->next = p->next,其实就等于s->next = s
这一点要是不懂的话一定要自己画个图,然后再写上过程
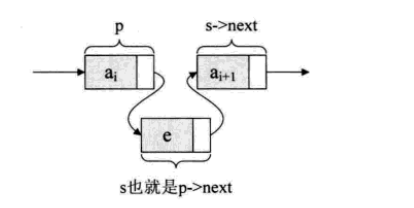
对于单链表的表头和表尾的特殊情况,操作是相同的
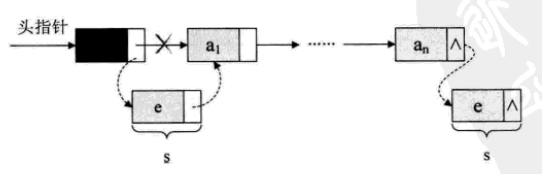
单链表第i个数据插入结点的算法思路:
1.声明一结点p指向链表第一个结点,初始化j从1开始;
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一-结点,j累加1;
3.若到链表末尾p为空,则说明第i个元素不存在;
4.否则查找成功,在系统中生成-一个空结点s;
5.将数据元素e赋值给s->data;
6.单链表的插入标准语句s->next=p->next p->next=s;
7.返回成功。
代码实现:
#include <stdio.h>/*初始条件:顺序线性表L已存在,1≤i≤ListLength (L),/操作结果: 在L中第1个位置之前插入新的数据元素 e,L的长度加 1/Status ListInsert(LinkList *L, int i, ElemType e){ int j; LinkList p, s; p = *L; j = 1; while (p && j < i) //寻找第i个结点,通过让p指针一直向后指,直到找到目标元素为止 { p = p->next; ++j; } if(!p || j > i) return ERROR; s = (LinkList)malloc(sizeof(Node));//生成新的结点 s->data = e; s->next = p->next; p->next = s; return OK; }
实际代码是执行不通的,主要是学习这个思想
核心思想就是工作指针后移
删除结点只需要将删除结点的前驱指针绕过,指向它的后继结点即可
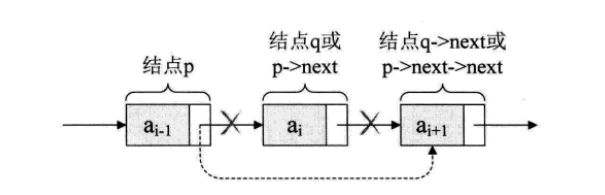
我们所要做的,实际上就是一步,p->next=p->next>next, 用q来取代p->next,即是
q = p->next;p->next=q->next
解读这两句代码,也就是说让p的后继的后继结点改成p的后继结点。
单链表第i个数据删除结点的算法思路
1.声明一结点p指向链表第一一个结点, 初始化j从1开始
2.当j<i时,就遍历链表,让p的指针向后移动,不断指向下一个结点, j累加1
3.若到链表末尾p为空,则说明第i个元素不存在
4.否则查找成功,将欲删除的结点p->next赋值给q
5.单链表的删除标准语句p->next=q->next
6.将q结点中的数据赋值给e,作为返回
7.释放q结点
8.返回成功
代码实现
初始条件:顺序线性表L已存在,1≤i≤ListLength (L)
操作结果: 删除L中的第i个数据元素,并用e返回其值,L中的长度减1
Status ListDelete (LinkList *L, int i, ElemType *e){ int j; LinkList p,q; P = *L; j = 1; while (p->next && j< i) /遍历寻找第 i个元素/ { P = P->next; ++j; } if (!(p->next) || j > i) return ERROR; /第i个元素不存在/ q = p->next; p->next = q->next; /将q的后继赋值给p的后继/ *e= q->data; /将q结点中的数据给e/ free (q) ; /让系统回收此结点,释放内存/ return OK;}
代码看不懂的,可以再回去画一遍图
分析一下刚才我们讲解的单链表插入和删除算法,我们发现,它们其实都是由两部分组成:第一部分就是遍历查找第i个元素;第二部分就是插入和删除元素。
从整个算法来说,我们很容易推导出:它们的时间复杂度都是O(n)。 如果在我们不知道第i个元素的指针位置,单链表数据结构在插入和删除操作上,与线性表的顺序存储结构是没有太大优势的。但如果,我们希望从第i个位置,插入10个元素,对于顺序存储结构意味着,每一次插入都需要移动n-i个元素,每次都是O(n)。 而单链表,我们只需要在第一次时,找到第i个位置的指针,此时为0(n),接下来只是简单地通过赋值移动指针而已,时间复杂度都是0(1)。显然,对于插入或删除数据越频繁的操作,单链表的效率优势就越是明显。
===========================================================================
顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。而单链表和顺序存储结构就不一样,它不像顺序存储结构这么集中,它可以很散,是一种动态结构。对于每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
所以创建单链表的过程就是一个动态生成链表的过程。即从空表的初始状态起,依次建立各个元素结点,并逐个插入链表
单链表整表创建的算法思路:
1.声明一结点p和计数器变量i;
2.初始化一空链表L
3.让L的头结点的指针指向null,即建立一个带头结点的单链表
4.循环:
生成一新结点赋值给p
随机生成一数字赋值给p的数据域p-》data;
将p插入到头结点与前一新结点之间
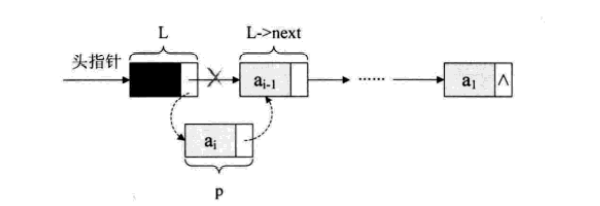
随机产生n个元素的值,建立带表头结点的单链线性表L(头插法)
void CreateListHead(LinkList *L,int n){ LinkList p; int i; srand (time(0)) ; /初始化随机数种子/ *L = (LinkList) malloc (sizeof (Node)); (*L) -> next = NULL; /先建立一个带头结点的单链表/ for(i=0; i<n; i++ ) { P = (LinkList) malloc(sizeof (Node) ); /生成新结点/ p->data = rand()%100+1; /随机生成100以内的数字/ p->next = (*L)->next; (*L)->next = p; /插入到表头/ }}
在算法代码里,最长用的是插队的办法,就是始终让新结点在第一的位置。这种算法简称为头插法
为什么新来的到第一的位置,每次把新结点都插在终端结点的后面,这种算法称之为尾插法
代码如下:
void CreateListTail(LinkList *L,int n){ LinkList p,r; int i; srand(time(0)); *L = (LinkList) malloc (sizeof(Node)); //L为整个线性表 r = *L; //*r 为指向尾部的结点; for (i = 0; i < n; i++) { p = (Node *)malloc(sizeof(Node)); //生成新结点 p->data = rand() % 100 +1; r->next = p; r = p; //将当前结点的新结点定义为终端节点 } r->next = NULL; }
注意L与r的关系,L是指整个单链表,而r是指向尾结点的变量, r会随着循环不断地变化结点,而L则是随着循环增长为一个多结点的链表。
注意啊,r是一个变量!!!
值得注意的是r->next = p;的含义,其实就算将刚才的表尾终端结点r的指针指向新结点p
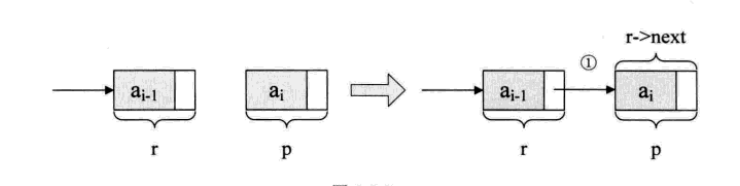
那么r = p是什么意思???
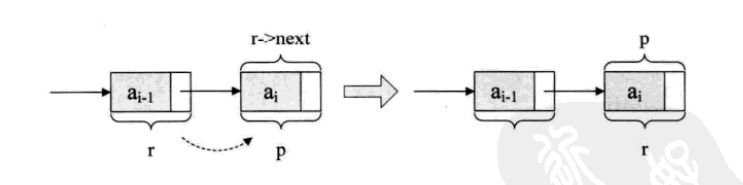
它的意思,就是本来r是在ai-1元素的结点,可现在它已经不是最后的结点了,现在最后的结点是ai,所以应该要让将p结点这个最后的结点赋值给r。此时r又是最终的尾节点了
当我们不打算使用这个单链表时,我们需要把它销毁,其实也就是在内存中将它释放掉,以便于留出空间给其他程序或软件使用。
单链表整表删除的算法思路如下:
1.声明一结点p和q;
2.将第一个结点赋值给p;
3.循环
将下一结点赋值给q;
释放p;
将q赋值给p。
初始条件:顺序线性表L已存在,操作结果:将L重置为空表
Status ClearList ( LinkList *L){ LinkList p,q; p= (*L)->next; /p指向第一个结点(将第一个结点赋值给p)/ while § /没到表尾/ { q=p->next; //将下一节点赋值给q free§; //释放p p=q; //将q赋值给p } (*L)->next=NULL; /头结点指针域为空/ return OK;}
这个蛮好理解的!
其中q的作用,就是一个记录作用,p被释放了,但是谁得到了记录,以便于等当前结点释放后,把下一节点拿回来补充
===================================================================================
顺序存储结构用一段连续的存储单元依次存储线性表的数据元素
单链表采用链式存储结构,用一组任意的存储单元存放线性表的元素
●查找
●顺序存储结构0(1)
●单链表0(n)
●插入和删除
●顺序存储结构需要平均移动表长半的元素,时间为0(n)
●单链表在线出某位置的指针后,插入和删除时间仅为0(1)
●顺序存储结构需要预分配存储空间,分大了,浪费,分小了易发生上溢
●单链表不需要分配存储空间,只要有就可以分配,元素个数也不受限制
**若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。**若需要频繁插入和删除时,宜采用单链表结构。比如说游戏开发中,对于用户注册的个人信息,除了注册时插入数据外,绝大多数情况都是读取,所以应该考虑用顺序存储结构。而游戏中的玩家的武器或者装备列表,随着玩家的游戏过程中,可能会随时增加或删除,此时再用顺序存储就不太合适了,单链表结构就可以大展拳脚。当然,这只是简单的类比,现实中的软件开发,要考虑的问题会复杂得多。
当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,这样可以不需要考虑存储空间的大小问题。而如果事先知道线性表的大致长度,比如一年12个月,一周就是星期一至星期日共七天,这种用顺序存储结构效率会高很多。
各有优缺点~
========================================================================
这里不做过多的言语
========================================================================
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表(circular linkedlist)。
循环链表解决了一个很麻烦的问题。如何从当中一个结点出发,访问到链表的全部结点。
为了使空链表与非空链表处理一致,我们通常设-一个头结点,当然,这并不是说,循环链表一定要头结点,这需要注意。
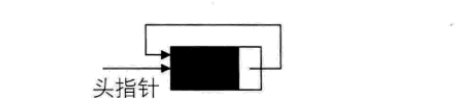
非空的循环链表:

其实循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p->next是否为空,现在则是p -> next不等于头结点,则循环未结束。
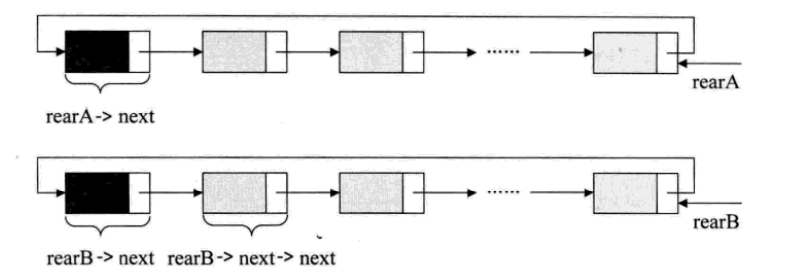
在单链表中,有了头结点时,可以用0(1)的时间访问第一个结点,但对于要访问到最后一个结点,却需要0(n)时间,因为我们需要将单链表全部扫描一遍。有没有可能用0(1)的时间由链表指针访问到最后一个结点呢? 当然可以。不过需要改造一下这个循环链表, 不用头指针,而是用指向终端结点的尾指针来表示循环链表

终端结点用尾指针rear(后)指示,则查找终端结点是o(1)
举个程序的例子,要将两个循环链表合并成一个表时,有了尾指针就非常简单了。比如下面的这两个循环链表,它们的尾指针分别是rearA和rearB
要想把它们合并,只需要如下的操作即可,
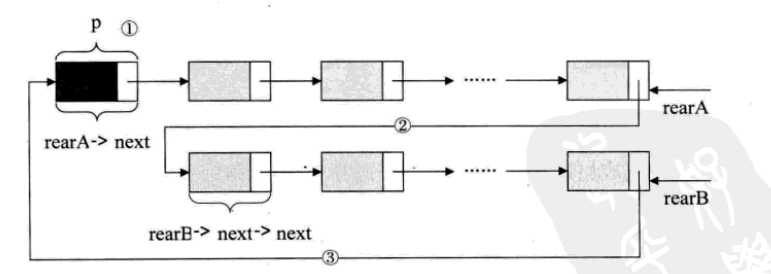
p=rearA->next; 保存A表的头结点,即①
rearA->next=rearB->next->next; 将本是指向B表的第一个结点(不是头结点) 賦值給reaA->next,即②
rearB->next=p; 将原A表的头结点赋值给rearB->next,即③
free § ; 释放p
========================================================================
书中的故事很精彩,有时间一定看一遍
为了克服单向性这一缺点, 老科学家们,设计出了双向链表。双向链表(double linked list) 是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
img.cn/img_convert/4231efeb66bdfeb7c9308a56f6af32fa.png)
要想把它们合并,只需要如下的操作即可,
p=rearA->next; 保存A表的头结点,即①
rearA->next=rearB->next->next; 将本是指向B表的第一个结点(不是头结点) 賦值給reaA->next,即②
rearB->next=p; 将原A表的头结点赋值给rearB->next,即③
free § ; 释放p
========================================================================
书中的故事很精彩,有时间一定看一遍
为了克服单向性这一缺点, 老科学家们,设计出了双向链表。双向链表(double linked list) 是在单链表的每个结点中,再设置一个指向其前驱结点的指针域。所以在双向链表中的结点都有两个指针域,一个指向直接后继,另一个指向直接前驱。
[外链图片转存中…(img-WLbipr54-1714322441996)]
[外链图片转存中…(img-F2MMd2BB-1714322441997)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


