
- 1NLTK-自然语言工具包_ntlk
- 2MSP430——Timer(输出比较编码器测速)(五)_msp430f5529编码器测速
- 3Linux下安装VNC_没有.vnc目录
- 4华为OD面试手撕算法-合法的括号对_华为od手撕算法做不出来
- 5uni-app封装自定义导航栏组件【简单】_uinapp 小程序 头部导航栏组件封装
- 6【AI绘画】Stable Diffusion学习——自用大模型分享_麦橘写实模型下载
- 7pytorch 使用netron可视化_pt模型可视化
- 8【开源】基于Vue+SpringBoot的图书管理系统_开源图书管理系统
- 91000道最新高频Java面试题,覆盖25个技术栈(多线程、JVM、高并发、spring、微服务、kafka,redis、分布式)从底层原理到架构_java 高级或架构 面试题
- 10RuntimeError: expected scalar type Float but found Half
YOLOv10: Real-Time End-to-End Object Detection
赞
踩
论文地址:: http://arxiv.org/abs/2405.14458
代码地址: https://github.com/THU-MIG/yolov10
废话不多说,先上图:

从图中可以看出效果确实有了明显的提升。
在过去的几年里,由于在计算成本和检测性能之间取得了有效的平衡,YOLO系列算法已经成为实时目标检测领域的主导范式。研究人员已经对YOLO的架构设计、优化目标、数据增强策略等进行了探索,并取得了显著进展。然而,对非最大抑制(NMS)的后处理依赖阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。此外,YOLO中各部件的设计缺乏全面彻底的检查,导致计算冗余明显,限制了模型的能力。它提供了次优的效率,以及相当大的性能改进潜力。在这项工作中,作者的目标是从后处理和模型架构两个方面进一步推进YOLO的性能效率边界。为此,作者提出了一种一致的双任务方法,用于无NMS训练的YOLO,它同时带来了具有竞争力的性能和较低的推理延迟。此外,还介绍了整体效率-精度驱动的模型设计策略。
一、引言
现如今,YOLO在训练过程中通常采用一对多的标签分配策略,即一个真值对象对应多个正样本。尽管这种方法产生了优越的性能,但需要NMS在推理过程中选择最佳的预测输出。这降低了推理速度,使性能对NMS的超参数敏感,从而阻碍了YOLO实现端到端最优部署。解决这个问题的一个方法是采用最近引入的端到端DETR架构。此外,模型架构设计仍然是YOLO面临的一个基本挑战,它对精度和速度有重要影响。为了实现更高效的模型架构,研究人员探索了不同的设计策略。为增强主干特征提取能力,提出了多种特征提取模块,包括DarkNet、CSPNet、EfficientRep和ELAN等。对于Neck部分,研究了PAN、BiC、GD、RepGFPN等方法来增强多尺度特征融合。此外,还研究了模型缩放策略和重参数化技术。虽然这些努力取得了显著的进展,但仍然缺乏从效率和精度的角度对YOLO中各种组件的全面检查。因此,YOLO内部仍然存在相当大的计算冗余,导致参数利用率低,效率次优。此外,由此产生的受约束的模型能力也导致了较差的性能,为精度的提高留下了充足的空间。在这项工作中,作者的目标是解决这些问题,并进一步推进YOLO的精度-速度边界。作者的目标是整个检测算法的后处理和模型架构。为此,首先提出了一种具有双标签分配和一致匹配度量的无NMS-YOLO的一致双分配策略,解决了后处理中的冗余预测问题。它使模型在训练过程中得到丰富一致的监督,而在推理过程中不需要NMS,从而获得高效率的性能。其次,通过对YOLO中各部件的全面检测,提出了整体效率-精度驱动的模型体系结构设计策略;为了提高效率,提出了轻量化分类头、空间通道解耦下采样和秩引导块设计,以减少显式计算冗余,实现更高效的架构。为了提高准确性,探索了大核卷积,并提出了有效的部分自注意力模块来增强模型能力。
二、标签分配
这项工作中,作者提出了一种具有双标签分配和一致匹配度量的无NMS的YOLO训练策略,实现了高效率和竞争性的性能。
双标签分配:与一对多分配不同,一对一匹配只对每个真值分配一个预测框,避免了NMS的后处理。然而,它导致弱监督,导致次优精度。幸运的是,这个缺陷可以通过一对多赋值来弥补。为了实现这一目标,YOLO10引入了双标签分配,以结合两种策略的优点。具体来说,如下图(a)所示,YOLO10加入了另一个一对一的头部。它保留了与原始一对多分支相同的结构和优化目标,但利用一对一匹配来获得标签分配。在训练过程中,两个头部与模型共同优化,使骨干和Neck享受到一对多分配所提供的丰富监督。在推理过程中,抛弃了一对多的监预测头,利用一对一的预测头进行预测。这使YOLO能够进行端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,采用了top1的选择,达到了与匈牙利匹配相同的效果,并且减少了额外的训练时间。

一致性匹配度量。在分配过程中,一对一和一对多方法都利用一个度量方法来定量地评估预测值和真值之间的一致性水平。
为了实现两个分支的预测感知匹配,采用统一的匹配度量,即:

式中
p
p
p为分类分数,
b
b
b和
b
b
b分别为预测和真实值的边界框。S表示预测框是否在实例内的空间先验。α和β是平衡语义预测任务和位置回归任务影响的两个重要超参数。将一对多和一对一的度量分别表示为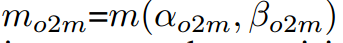
和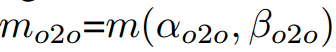
这些指标影响两个预测头的标签分配和监督信息。
在双标签分配中,一对多分支比一对一分支提供更丰富的监督信息。直观地说,如果能够将一对一预测头的监督与一对多头像的监督协调起来,就可以朝着一对多的预测头优化的方向去优化一对一预测头。因此,一对一预测头可以在推理过程中提供更好的样本质量,从而获得更好的性能。为此,首先分析了两个头部之间的监管差距。由于训练过程中的随机性,在开始时用相同的值初始化两个预测头并产生相同的预测,即一对一预测头和一对多预测头为每个预测实例对生成相同的p和IoU。两个分支的回归目标不冲突,因为匹配的预测共享相同的目标,而不匹配的预测被忽略。因此,监管缺口在于分类目标的不同。给定一个实例,用
u
∗
u^∗
u∗表示其最大的IoU,并将最大的一对多和一对一匹配分数分别表示为
m
o
2
m
∗
m^∗_{o2m}
mo2m∗和
m
o
2
o
∗
m^∗_{o2o}
mo2o∗。假设一对多分支产生正样本
Ω
Ω
Ω,并且一对一分支选择了度量为
m
o
2
o
,
i
=
m
o
2
o
∗
m_{o2o,i}=m^∗_{o2o}
mo2o,i=mo2o∗的第i个预测,那么对于
j
∈
Ω
j∈Ω
j∈Ω和
t
o
2
m
,
j
=
u
∗
⋅
m
o
2
m
,
j
m
o
2
m
∗
≤
u
∗
t_{o2m},j=u^∗·\frac {m_{o2m,j}} {m^∗_{o2m}}≤u^∗
to2m,j=u∗⋅mo2m∗mo2m,j≤u∗,对于任务对齐损失,可以得到分类目标
t
o
2
o
,
i
=
u
∗
⋅
m
o
2
o
,
i
m
o
2
o
∗
=
u
∗
t_{o2o},i=u^∗·\frac {m_{o2o,i}} {m^∗_{o2o}} =u^∗
to2o,i=u∗⋅mo2o∗mo2o,i=u∗。因此,两个分支之间的监督差距可以由不同分类目标的1-Wasserstein距离推导出来,即:

我们可以观察到,差距随着
t
o
2
m
t_{o2m}
to2m的增加而减小,即i在Ω中的排名更高。在
t
o
2
m
,
i
=
u
∗
t_{o2m,i}=u^*
to2m,i=u∗时达到最小值,即在Ω中i为最佳正样本,如下图所示。为此,作者提出了一致的匹配度量,即
α
o
2
o
=
r
⋅
α
o
2
m
α_{o2o}=r·α_{o2m}
αo2o=r⋅αo2m,
β
o
2
o
=
r
⋅
β
o
2
m
β_{o2o}=r·β_{o2m}
βo2o=r⋅βo2m,这意味着
m
o
2
o
=
m
o
2
m
r
m_{o2o}=m^r_{o2m}
mo2o=mo2mr。因此,一对多的最佳正样本也是一对一的最佳正样本。因此,两个头部可以持续优化。为简单起见,默认取r=1,即
α
o
2
o
=
α
o
2
m
α_{o2o}=α_{o2m}
αo2o=αo2m,
β
o
2
o
=
β
o
2
m
β_{o2o}=β_{o2m}
βo2o=βo2m。为了验证改进后的监督一致性,在训练后的一对多结果的前1 / 5 / 10内计算一对一匹配对的数量。如下图 (b)所示,在一致的匹配度量下,对准得到了改善。

三、整体效率-精度驱动的模型设计
除了后处理之外,yolo的模型架构也对效率和精度的权衡提出了很大的挑战。尽管之前的作品探索了各种设计策略,但对YOLO各部件的全面检查仍显不足。因此,模型体系结构表现出不可忽略的计算冗余和约束能力,这阻碍了其实现高效率和高性能的潜力。在这里,从效率和准确性的角度全面执行YOLO的模型设计。
效率驱动的模型设计。YOLO的组件包括stem、下采样层、具有基本构建块的stage和检测头。该系统的计算成本很少,因此对其他三个部分进行了效率驱动的模型设计。
(1)预测头轻量化。在YOLO中,分类和回归头通常共享相同的架构。然而,在计算开销方面表现出明显的差异。例如,在YOLOv8-S中,分类头(5.95G/1.51M)的FLOPs和参数数分别是回归头(2.34G/0.64M)的2.5倍和2.4倍。然而,在分析分类误差和回归误差的影响后,发现回归头对YOLO的性能具有更重要的意义。因此,可以减少分类头的开销,而不必担心对性能造成很大的影响。因此,简单地对分类头采用轻量级架构,它由两个深度可分离的卷积组成,核大小为3×3,然后是一个1×1卷积。
(2)空间通道解耦下采样。YOLO通常利用步长为2的规则3×3标准卷积,同时实现空间下采样(从H × W到H/2 × W/2)和通道变换(从C到2C)。这引入了不可忽略的计算成本O(
9
/
2
H
W
C
2
9/2HWC^2
9/2HWC2)和参数数O(
18
C
2
18C^2
18C2)。相反,作者建议将空间缩减和通道增加操作解耦,从而实现更有效的下采样。具体来说,首先利用点向卷积来调整通道维度,然后利用深度卷积来执行空间下采样。这将计算成本降低到
O
(
2
H
W
C
2
+
9
/
2
H
W
C
)
O(2HWC^2 + 9/2HWC)
O(2HWC2+9/2HWC),参数计数降低到
0
(
2
C
2
+
18
C
)
0 (2C^2 + 18C)
0(2C2+18C)。同时,它最大限度地提高了下采样期间的信息保留,从而在降低延迟的情况下获得具有竞争力的性能。
(3)基础块设计。YOLO通常在所有阶段使用相同的基本构建块,例如,YOLOv8中的瓶颈块。为了彻底检验YOLO的这种同质设计,作者利用内在秩来分析每个阶段的冗余度。具体来说,计算每个阶段最后一个基本块的最后一个卷积的数值秩,计算大于阈值的奇异值的个数。下图 (a)为YOLOv8的结果,表明深阶段和大模型容易表现出更多的冗余。这一观察结果表明,简单地在所有阶段采用相同的区块设计并不能达到最佳的产能效率平衡。为了解决这个问题,作者提出了一个等级引导的块设计方案,旨在减少使用紧凑的架构设计显示冗余的阶段的复杂性。首先提出了一种紧凑的倒残差块(CIB)结构,该结构采用低成本的深度卷积进行空间混合,采用高成本的点卷积进行通道混合。如下图(b)所示。它可以作为高效的基本构建块,例如嵌入ELAN结构中(下图(b))。在此基础上,提出了一种排序引导的区块分配策略,以在保持竞争能力的同时达到最佳效率。具体来说,给定一个模型,根据其内在的升序排序其所有阶段。进一步检查用CIB替换先前基本块的性能变化,如果与给定模型相比没有性能下降,则继续更换下一阶段,否则停止该过程。因此,可以实现跨阶段和模型尺度的自适应紧凑块设计,在不影响性能的情况下实现更高的效率。

精度驱动的模型设计。作者也进一步探索了精度驱动设计的大核卷积和自注意力,旨在以最小的成本提高性能。
(1)大核卷积。采用大核深度卷积是扩大接受野和增强模型能力的有效方法。然而,在所有阶段简单地利用它们可能会导致用于检测小物体的浅层特征受到污染,同时在高分辨率阶段也会带来显著的I/O开销和延迟。因此,建议在深度阶段利用CIB中的大核深度卷积。具体来说,将CIB中第二个3×3深度卷积的核大小增加到7×7。此外,采用结构重参数化技术引入另一个3×3深度卷积分支来缓解优化问题,而不需要推理开销。此外,随着模型大小的增加,其感受野自然会扩大,使用大核卷积的好处会减少。因此,只对小模型尺度采用大核卷积。
(2)局部自注意力(PSA)。自注意力由于其卓越的全局建模能力而被广泛应用于各种视觉任务中。然而,它表现出很高的计算复杂度和内存占用。为了解决这个问题,鉴于普遍存在的注意力头冗余,提出了一种高效的局部自注意力(PSA)模块设计,如下图所示。具体来说,在1×1卷积后将跨通道的特征均匀地划分为两部分。只将其中一部分输入到由多头自注意模块(MHSA)和前馈网络(FFN)组成的NPSA模块中。然后通过1×1卷积将两个部分连接并融合。此外,将查询和键的维度分配为MHSA中值的一半,并将LayerNorm替换为BatchNorm以进行快速推理。此外,PSA仅放置在分辨率最低的阶段4之后,避免了自注意力的二次计算复杂性带来的过多开销。这样可以将全局表示学习能力融入到YOLO中,计算成本较低,很好地增强了模型的能力,从而提高了性能。

四、实验展示:



