
- 1宇宙最强帕鲁私服管理器诞生了!_帕鲁 worldoption rcon
- 2基于PyQt5的YOLOv5检测界面——YOLOv5检测目标后声音告警的美化_yolov5-master 没有声音
- 3【突破舒适圈】在SpringBoot中配置Redis_springboot配置redis
- 4Java中的跨站脚本攻击(XSS)处理技术_java 跨站点脚本攻击如何验证是否成功
- 5python Django在线可视化平台_使用python django框架建立可视化地图平台
- 6H5定位被拒绝处理方法_h5 浏览器拒绝访问地址之后,怎么再次请求地址
- 7【深度学习进阶之路】----解决新建Anconda虚拟环境总是安装在C盘的问题_conda软件包都装在c盘怎么办
- 8将dataframe中的某一行提取出来放到另一个dataframe中_将dataframe中某一行的值放进另一个dataframe
- 9如何开发一款电商app小程序_电商小程序开发方案
- 10COCO玛奇朵FL Studio21软件注册机
纯干技术分享:大模型LLama2-7B在高能效可重构视觉芯片部署
赞
踩
关于高能效可重构视觉芯片TX536
清微智能TX536是一款行业专用的智能高SOC,集成功能强大的可重构计算架构(CGRA)ISP、业界最新的H.265视频压缩编解码器,3D计算加速单元。基于高性能人工智能加速引擎RNE以及通用计算加速引擎RCE,TX536在低码率、高画质、智能处理和分析等方面引领行业。芯片集成POR、RTC、Audio Codec以及待机唤醒电路,极大的降低了客户的产品成本。AI计算有效能效比达6.3TOPS/W@INT8,典型功耗1W,支持AI降噪、AI超分等图像处理技术,峰值算力4.0Tops@INT8。
LLaMA2是目前为止,效果最好的开源 LLM 之一,是一系列预训练和微调的大型语言模型。因为原生LLaMA2对中文的支持很弱,国内的Llama中文社区在其基础上进行微调并开源了基础模型,本次分享的部署模型Llama2-Chinese-7b-Chat,就是来源于该中文社区:
https://github.com/FlagAlpha/Llama2-Chinese
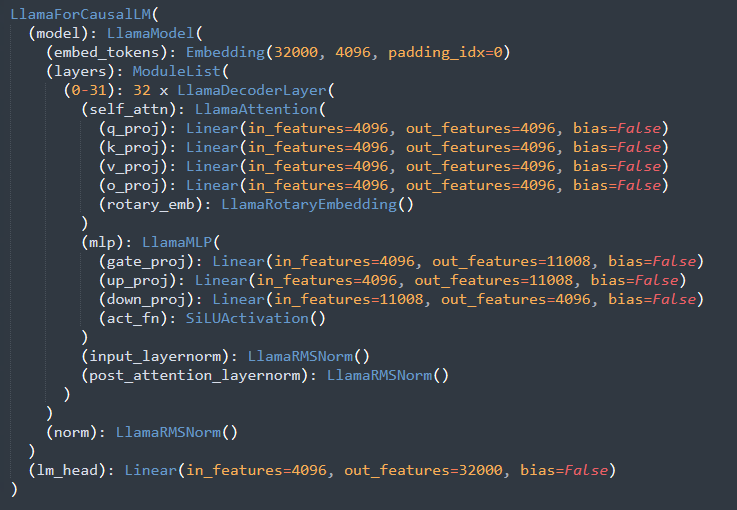
模型结构
LLaMA2-7B采用与LLaMA-7B相同的结构,如下图所示,相较于传统的Transformer,主要区别在于:
1)采用RMS Norm代替Layernorm,并在顺序上做了前移;
2)采用SwiGLU作为激活函数;
3)采用RoPE通过动态位置编码,来解决传统位置编码处理长序列时困难的问题。
量化方案
清微骑士Knight工具链,支持INT8量化(整网算子输入输出均采用W8A8量化方式,linear权重采用per-channel方式),可以很方便的把浮点模型(比如pytorch/tensorflow/onnx/paddlepaddle等)转换、部署到指定芯片上;Knight工具链还针对硬件架构做了深度优化,在精度和性能两个维度达到较好的平衡。因为LLaMA2-7B模型较大,这里采用分块的方式转换成若干ONNX模型,对这些模型分别进行PTQ量化、编译,并在板端串联起来进行部署、测试。
推理流程
LLaMA2-7B按照模型结构分拆了几个模块Tokenizer/Embedding/LlamaLayer/LmHead,、通过Knight工具链进行转换,调度到TX536芯片上运行。
模型及权重可以通过Hugging Face提供的资源下载到本地,然后按照下面方法导出ONNX模型。
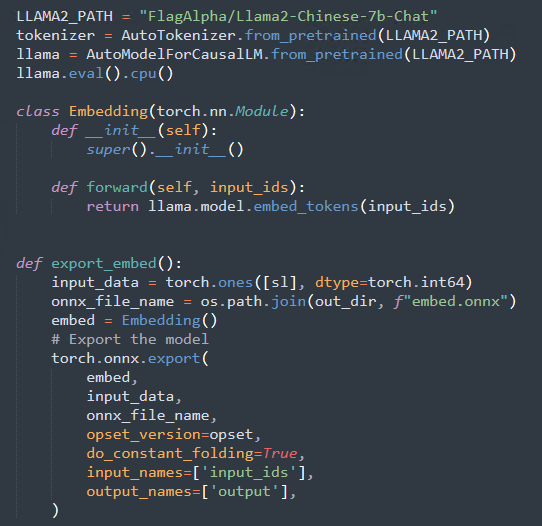
Embedding,词嵌入模块:
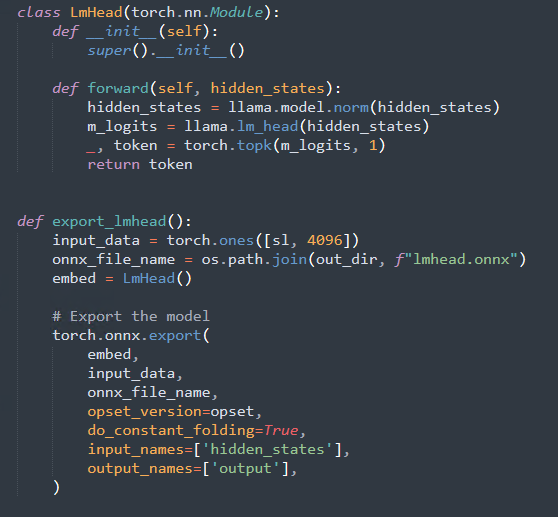
LmHead模块
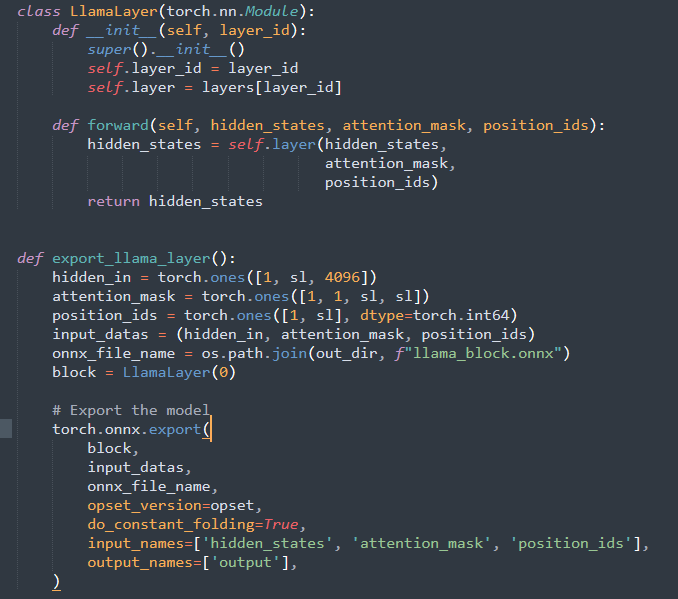
LlamaLayer:
整体推理流程:
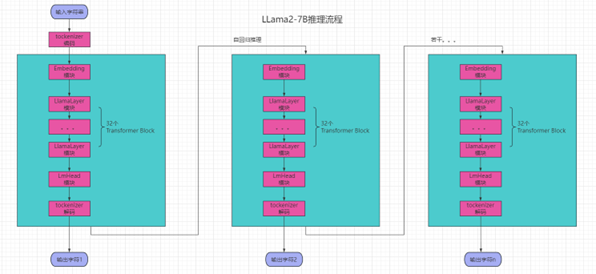
板端部署、性能测试
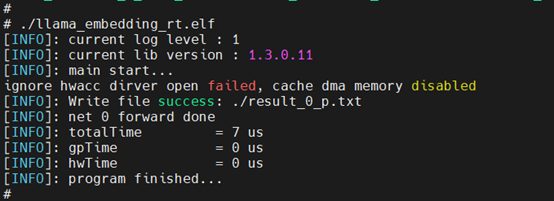
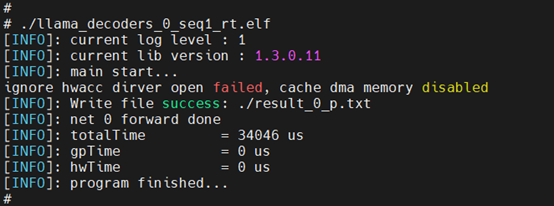
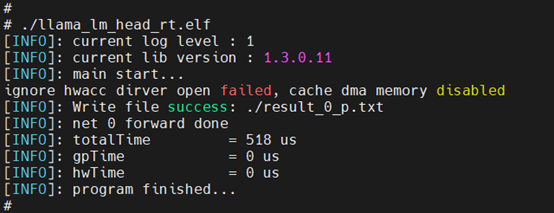
对Embedding/LlamaLayer/LmHead分别进行量化、编译后,生成可执行二进制文件,Sequence-length设置为1的条件下,完整执行过程如下:
Embedding板端运行:
LlamaLayer板端运行:
LmHead板端运行:
清微工具链目前已经完成了与百度paddlepaddle III级兼容性认证,支持30个多模型,涉及视觉,自然语言处理和推荐,无论是面向大模型还是在通用性方面,可重构软件工具都具有相当的优势。

