
- 1存储型XSS与反射型XSS有什么区别?_存储型xss漏洞和反射型xss漏洞区别
- 2java配置多个grpc client_GrpcClient
- 3CVPR2019论文列表(中英对照)_label propagation for deep semi-supervised learnin
- 4【jellyfin】解决使用自定义域名和免费ssl证书安卓端无法访问服务器的问题_jellyfin绑定域名
- 5自定义注解对bean中属性的注入和ConvertUtils动态转化String_javabean传输redis字段转string类型的注解
- 6vue3 - Element Plus 切换主题色及el-button hover颜色不生效的解决方法_element plus 配置主题色button和input不生效
- 7pip升级安装_linuxs升级py
- 8Pycharm服务器配置与内网穿透工具结合实现远程开发的解决方法
- 9threeJS 实现加载模型 + 页面按钮交互 + 显示css2Renderer标注_css2drenderer
- 10vxe-table的常见用法_vxe-table api
记一次SOFA内存泄漏排查过程_sofaboot健康检查信息泄露
赞
踩
记一次内存泄漏排查过程
起因
某天中午大家还在安静的午休,睡得正香的时候突然被一阵手机滴…滴滴直响短信惊醒。一看是应用的服务器告警并且对应服务的所有机器都在告警“健康检查失败,自动拉下线”。这还得了,无意识的打开CAT,大盘红得直奔5000点的感觉。直接使用终极大招,赶紧联系运维小哥重启所有服务,留一台保留现场调查原因。服务恢复正常。
分析
通过分析发现一个现象:健康检查在多次检查失败后把机器拉下线,过一会又健康检查成功又拉上线,过一会健康检查又失败了又拉下线。就这样一直反复。通过保留的机器调用健康检查发现的现象也是这样,多次请求后成功一次,然后又失败。请求健康检查页报:ERR_CONNECTION_RESET。
检查应用的日志里也没有任何的报错信息,没有OOM错误。通过查看问题机器的JVM堆内存,线程数以及线程状态都是正常的。GC次数,耗时也是正常的。但是内存使用率达到了5-6G,而JVM的启动参数设置的是-Xmx3g -Xms3g -Xmn1g。也就是说另外的2-6G并不是JVM占用的。通过top工具参看5-6G的内存确实是服务的进程占用。那肯定就是堆外内存了。
但在应用的代码了没有地方使用了堆外内存,那么就可以推断问题应该是出现在服务化框架SOFA(蚂蚁的一个微服务开源框架)上。因为他使用的是netty做为底层的协议通信。于是就拉上我们的架构师和框架组的同事一起分析。
调查的心路历程1:
架构师通过jstack的进程日志发现所有的SOAF REST线程都是RUNNABLE(SOAF默认是200个线程)。怀疑是线程池满了,无法提供服务。刚好我通过CAT看到这两天的一个api的请求量特别大高峰是达到200QPS,平均在100QPS。问了业务方说是这两天调用发全量了。结合这两方面我们认为可能是线程池不够的问题。于是服务器扩容4台。并且配置了rest的线程池为400,重启一台机器后REST线程变成400了。继续观察。
在这个过程中又有一个新的怀疑那就是:如果是请求的线程满了,保留现场的机器在拉下线后在原来请求处理完后,没有线上新请求的情况下应该可以恢复正常,为什么一直不能恢复正常呢,任然还是调用多次失败,成功一次。按道理在没有新请求打入的情况下线程应该可以释放掉恢复正常,也没有任何线程是block的。
不幸的事还是发生了,运行一段时间后发现虽然增加了4台机器,结果连新增的机器也在运行一段时间后出现同样的问题。并且REST线程变成400的机器也一样没有得到解决。所以可以得出结论不是线程池满了引起的。后面的详细分析下也可以得出这个结论。
- 上面我分析的机器下线后一直也没有恢复
- 线程池满了与堆外内存增长没有关系
当时也是期望能早点解决问题。所以有任何希望都要尝试下。
调查的心路历程2:
通过观察线上的现象来看物理内存达到63%-65%的时候系统就挂住。所以可以肯定是堆外内存泄漏导致。与此同时在网上看到有人在github提sofa-rpc的Netty 4.1 堆外内存泄漏问题#592。SOFA的commiter说5.6.0已经修复这个问题。于是我们尝试升级sofa-rpc 5.4.7升级到5.6.0试试。升级5.6.0必须升级一个bolt的版本。中间还要解决zk的版本问题,后来用了公司使用5.6.0自己打包的版本不用升级zk。结果升级后不但没有解决内存泄漏的问题,更悲催的是还引起了一个因升级bolt无法调用下游低版本的服务导致业务失败搞了个线上事件。
调查的心路历程3:
在这期间架构师也在看sofa-rpc的源码说sofa-rpc 5.4.7没有上面#592提的没有关闭bytebuf(使用的是netty的堆外内存)的问题。因为没有在SofaRestRequestHandler里发现用了bytebuf。而框架组的同事同时也在提他们知道的CAT与netty 4的版本有堆外内存泄漏的问题。刚好我们使用的是netty4。通过查看cat的日志发现一些错误日志
[08-22 10:44:09.572] [ERROR] [TcpSocketSender] Netty write buffer is full!
于是矛头又转向了CAT。架构师通过查看CAT源码确实也存在内存泄漏的问题。刚好我通过工具把堆外内存的数据导出来了。因为数据比较大有1g左右,一般的工具打不开,于是用linux的cat工具看到有部分数据乱码,但刚好能看到CAT打点的字眼。
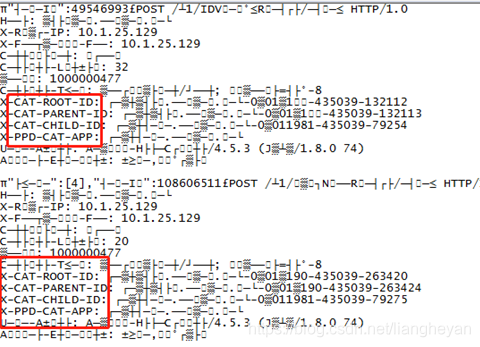
于是非常确定是CAT导致的内存泄漏。感觉终于找到问题了。让框架组把CAT上报功能关闭,暂时不上报看是否可以解决这个问题。而与此同时框架组的同事也在尽量修改这个bug。大家现在都等着解决CAT的bug。但是我通过观察一直到第二天,关闭CAT上报,堆外内存还是在上升。还是需要运维继续重启服务来规避。于是怀疑与CAT无关。因为上次看到的堆外内存的数据有乱码,于是下载了一个可以打开大文件的工具打开了导出的文件看到内容如下:
堆外内存里的内容: POST /v1/xxxxxxx/query HTTP/1.0
Host: authxxx.xxxx.com
X-Real-IP: 10.1.xxx.208
X-Forwarded-For: 10.1.xxx.208
Connection: close
Content-Length: 19
appid: xxxxxxxx
Content-Type: application/json; charset=utf-8
X-CAT-ROOT-ID: loanxxx.xxxxx.com-0a01a1e6-435033-363198
X-CAT-PARENT-ID: loanxxx.xxxxx.com-0a01a1e6-435033-363202
X-CAT-CHILD-ID: loanxxx.xxxxx.com-0a0116d0-435033-117116
X-PPD-CAT-APP: loanxxx.xxxx.com
User-Agent: Apache-HttpClient/4.5.3 (Java/1.8.0_74)
Accept-Encoding: gzip,deflate
{“userId”:xxxxxxx}
从中我发现这些数据与请求的header数据很像,而里面出现的X-CAT-ROOT-ID这些应该是上游服务在header里设置的CAT打点调用链跟踪的数据,而不是CAT上报的数据。于是我又开始怀疑是SOFA泄漏。而且以前在请求量少的时候偶尔发现有下面的错误。
LEAK: ByteBuf.release() was not called before it’s garbage-collected. See http://netty.io/wiki/reference-counted-objects.html for more information.
通过在github上提issue.而SOFA的commiter说这个不影响业务。内存会被回收的,让我加一个启动参数-Dio.netty.leakDetectionLevel=advanced 可以打印详细错误但是影响性能。既然没有问题,所以我也就没有管了。这次我让运维同学在一台机器上加上了这个启动参数,结果打印了详细错误。错误信息如下:
[xxxx-08-25 00:01:02.258] [SOFA-SEV-REST-IO-8098-5-T4] [ERROR] io.netty.util.ResourceLeakDetector:273 x:() - LEAK: ByteBuf.release() was not called before it's garbage-collected. See http://netty.io/wiki/reference-counted-objects.html for more information.
Recent access records:
#6:
io.netty.buffer.AdvancedLeakAwareByteBuf.writeBytes(AdvancedLeakAwareByteBuf.java:634)
io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(NioSocketChannel.java:345)
io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:148)
io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:647)
io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:582)
io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:499)
io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:461)
io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:884)
java.lang.Thread.run(Thread.java:745)
Created at:
io.netty.buffer.PooledByteBufAllocator.newDirectBuffer(PooledByteBufAllocator.java:331)
io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:185)
io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:176)
io.netty.buffer.AbstractByteBufAllocator.ioBuffer(AbstractByteBufAllocator.java:137)
io.netty.channel.DefaultMaxMessagesRecvByteBufAllocator$MaxMessageHandle.allocate(DefaultMaxMessagesRecvByteBufAllocator.java:114)
io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:147)
io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:647)
io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:582)
io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:499)
io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:461)
io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:884)
java.lang.Thread.run(Thread.java:745)
: 6 leak records were discarded because they were duplicates
: 6 leak records were discarded because the leak record count is targeted to 4. Use system property io.netty.leakDetection.targetRecords to increase the limit.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
于是周五晚上我在本地调整jvm -Xmx256m -Xms256m -Xmn126m。用JMeter压测,跑了1个小时后发重现了线上问题的现象,也打印出了上面的日志,所以现在可以非常肯定是sofa的堆外内存泄漏了。于是在github上提了一个issue:https://github.com/sofastack/sofa-rpc/issues/750。第二天就看到有commiter回复说这个问题在sofa-rpc 5.5.7已经解决了。心情比较激动。于是马上升级到sofa-rpc 5.5.7再次压测。压测起来后就出去了,晚上回来后发现还在继续跑,没有发现有请求错误,也没有发现有错误日志。感觉应该是解决了。于是周一到公司升级了sofa-rpc 5.5.7准备发。等到周二我们发了一台观察了3个小时发现内存没有升而是维持在27%。所以下午就把剩下的都发了。第二天观察内存都是很平稳的维持在27%。到此堆外内存的问题终于解决了。
下面是升级前后的内存对比
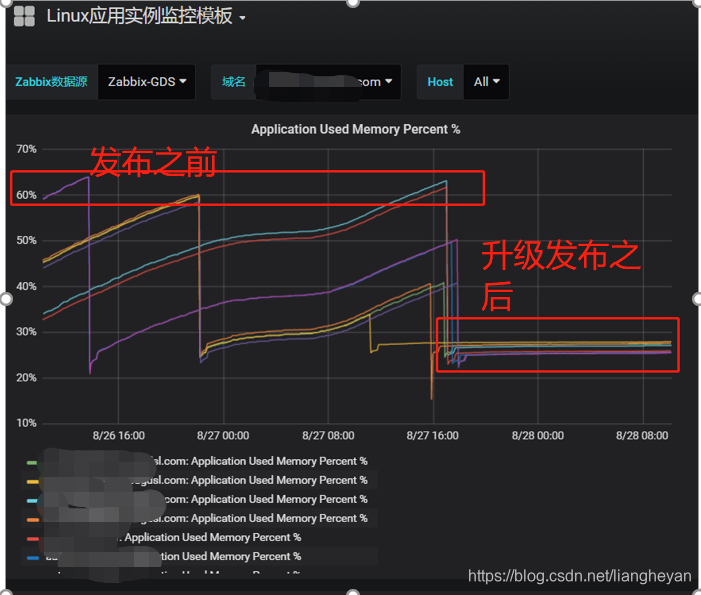
结果
sofa-rpc 5.4.7版本 Rest协议存在堆外内存泄漏的情况,升级到5.5.7解决问题。
敲黑板:导出堆外内存工具和步骤
- 通过ps -ef|grep java 找到应用的PID
- pmap -x pid 打印出内存的使用情况,可以通过linux的 cat /proc/PID/maps打印出内存的情况只是没有pmap 直观。
pmap 结果如下:
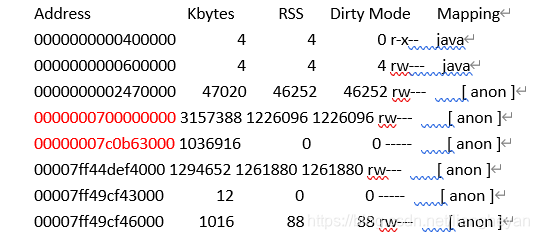
Address:是内存的开始地址
Kbytes :是内存的申请大小
RSS :是内存实际使用的大小
Mapping的[ anon ] 表示的是应用向内存申请的内存
通过计算地址0000000700000000的大小刚好是JVM启动参数设置的3G大小的堆内存。
而00007ff44def4000开始的地址占用内存比较大,可以推断应该就是堆外内存。
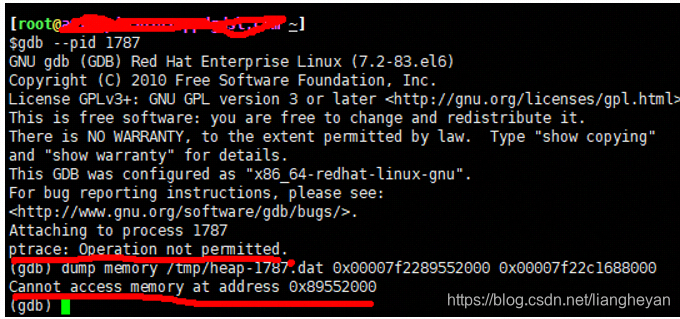
3. 有了内存的地址就可以用linux的gdb调试工具导出内存了(这个工具C++开发人员用得比较多)
gdb --pid PID (进入gbd模式)
(gdb) dump memory /tmp/heap-61.dat 0x0000000700000000 0x00000007c0b63000
dump memory:导出内存命令
/tmp/heap-61.dat:导出的文件
0x表示16进制
0000000700000000:是导出内存的起始地址
00000007c0b63000:导出内存的结束地址
说明:如果执行 gdb –pid PID提示
ptract:Operation not permitted
dump memory命令时报Cannot access memory ataddress时,可以用
ps -ef | grep gdb
看看是否有其他进程在,如果有的话kill掉就可以执行了。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

