
- 1unity导入视频并实现播放及进度条滑动_unity2d放视频
- 2Jenkins用户密码重置
- 3sqlmap基本信息及参数使用方法
- 4Vue版Ant Design给a-form表单-赋值及获取表单数据-案例_ant design vue 怎么获取form的值
- 5Windows平台安装Pygame报错:is not a supported wheel on this platform._error: pygame-2.1.2-cp311-cp311-win_amd64.whl is n
- 6DL-1-week2-Basics of Neural Network Programming_week 2 quiz - neural network basics
- 7VUE3使用wavesurfer.js_vue3 wavesurfer.js
- 8spine介绍和在Unity里面的应用_unity spine
- 9WPF学习之绘图和动画_shader effects buildtask and templates
- 10Python Turtle 初学者指南_turtle.bgcolor
将学习速率可视化来优化神经网络--将学习速率视作超参数并使用可视化来观察其影响的技巧和诀窍
赞
踩

编者注:欢迎参考2017年9月17日至20日Siddha Ganju在旧金山召开的人工智能大会上的关于嵌入式深度学习的讲座。
更多人工智能内容请关注2018年4月10-13日人工智能北京大会。
学习速率是随着时间的推移神经网络里信息积累的速度。学习速率决定了神经网络达到(以及是否能达到)所需特定输出的最佳、最有利位置的速度。在原始随机梯度下降(SGD)中,学习速率与误差梯度的形状无关,因为它使用了一个与误差梯度无关的全局学习速率。
然而可以对原始SGD的更新规则进行许多修改,这些规则会将学习速率跟误差梯度的大小和方向关联起来。
为什么要将学习速率的可视化出来?
将随着时间变化的学习速率可视化与随着道路状况变化的汽车速度可视化是类似的。在高速公路等畅通宽阔的道路上,我们可以提高速度(学习速率),但是在狭窄的丘陵或山谷道路上,我们必须放慢速度。此外,我们不想在高速公路上行驶得太慢,否则我们将花费太长时间才能到达目的地(由于参数不当而导致更长的训练时间)。同样的,我们不想在丘陵和狭窄的道路上(就像优化损失函数表面的沟谷)开车太快,因为我们很容易失去对汽车的控制(陷入局部最小值,或因产生太多的反弹而几乎没有改进)或错过目的地(最优值)。
请记住,“…一个高学习速率… [表示]系统含有太多的动能,参数向量胡乱的弹跳从而不能落入损失函数的较深但较窄的地方”(请参阅Karpathy的cs231n课程笔记)。
基于相同的数据来源,可以通过在数据集的一个子集上训练网络来获得一个良好的初始学习速率估计。理想的策略是从一个很大的学习速率开始,逐次减半直到损失不再变化。在接近训练结束时,学习速率的衰减应在100倍左右或更高。这种衰减使学习好的网络能够抵抗可能使学习失败的随机波动。在这里,我们将会先选择一个小的学习速率在一个小的数据集上测试,并选择适当的值。
学习速率衰减
非自适应学习速率可能不是最佳的。学习速率的衰减可以通过每几个周期减少某个常数因子,或通过指数衰减来实现,指数可以采用每几个周期的指数的数学形式。“衰减”通常被认为是一个消极的概念,在当前的学习速率衰减案例中也是负面的:它指的是学习速率下降的程度。然而这种衰减的结果实际上是我们非常想要的。例如我们降低一辆车的速度以适应道路和交通条件,这种减速可以被理解为汽车速度的“衰减”。同样我们也能从衰减学习速率以适应梯度中获益。
降低学习速率是必要的,因为高的学习速率在进行迭代训练时很可能会落入局部最小值。想象这个局部最小值是一张超速罚单、一个通行费、交通信号灯或是交通拥挤——某些基本上会增加到达目的地的时间的东西。完全避免所有的交通信号灯和通行费是不可能的,但是会有一个我们喜欢的最优驾驶路径。同样的在模型训练中,我们希望寻找最佳路径时避免在梯度上的反复跳跃,并希望模型训练是沿着最佳路径的。理想情况下,我们不希望加速太快因为我们会因此得到一张超速罚单(陷入局部最小值并抛锚)。同样的比喻也适用于学习速率。
动量是一种自适应学习速率方法的参数,它允许以较高速度在平缓方向上移动,而在陡峭方向上降低速度。这种动量定义被认为是“经典动量”,它会对速度进行校正然后在速度方向上大跳跃移动。动量有助于根据梯度的变化加速或减速基础学习速率,将引起净学习速率的变化而不影响其在损失函数表面上的位置。动量使学习到的网络更能抵抗输入中的噪声和随机性。
将学习速率视为超参数的其他更新规则包括:
Duchi等人在2011年提出的AdaGrad,其增加了根据每个维度的历史平方和来缩放梯度的各个元素。
Tieleman和Hinton在2012年提出的RMSProp自适应学习速率,其保留了每个权重的平方梯度的移动平均值以正规化当前梯度。RMSProp增强了抵抗波动和随机噪声的能力。
Kingma和Ba在2014年提出的Adam,其引入了零初始化的一个偏差修正值补偿。
以及rprop,它只使用梯度符号来分别适应每个权重的步长。这不适用于小批量。
除了这些规则,还有很多遵循牛顿更新规则但计算量非常大的二阶方法。然而二阶方法不会把学习速率视为超参数,由于其计算量大所以很少被用于大型深度学习系统。
图1显示了在差不多的超参数设置下不同优化技术的比较:
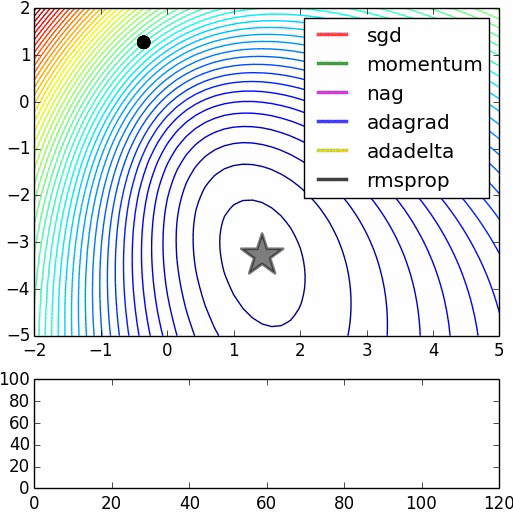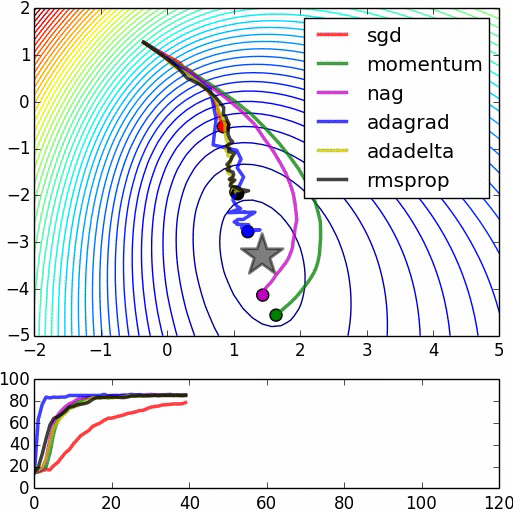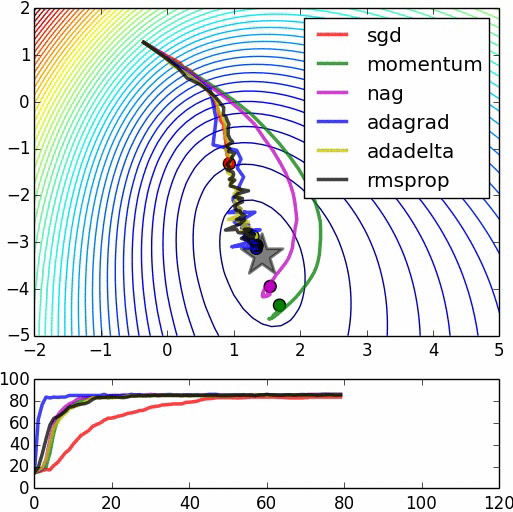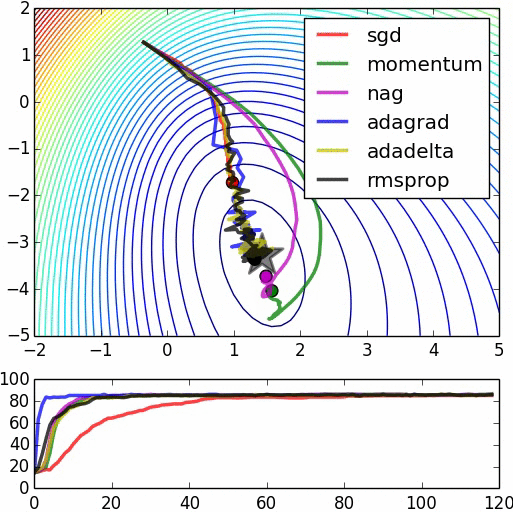
图1 优化技术的比较。资料来源:Alec Radford,经许可使用
在这个图像中,动量更新越过了目标,但是到达全局最小值的速度更快。“NAG”是Nesterov加速梯度(Nesterov Accelerated Gradient),其首先沿速度的方向移动然后基于新位置对速度矢量进行校正。
从本质上讲,我们的目标不是衰减而是利用衰减到达正确的位置。为了到达全局最优或者期望的目的地,必须有选择性地增大或者减小学习速率。不要害怕这些,因为我们经常要做很多遍。
可视化
想要了解模型学习的进展,可视化是很必要的。例如,损失周期图对于了解损失是如何随着周期变化是非常有用的。当所有数据点在当前训练中至少被看到过一次时就完成一个周期。与迭代相比,跟踪周期更好。这是因为迭代次数取决于可以任意设定的批量大小。
生成这个图的一个好方法是通过叠加不同参数集合的每个周期曲线的损失。这个过程有助于我们识别最适合训练的一组参数。这些图的y轴是损失,x轴是周期数。总体来说,图2所示的几个损失曲线看起来比较相似,但是它们的优化模式存在一些微小的差异,具体表现在其收敛所需的周期数量和结果误差上。
在众多的损失函数中,选择使用哪一种是很重要的。对于一些分类任务,交叉熵误差往往比其他度量更适合(如均方误差),这是因为交叉熵误差背后所代表的数学假设。如果我们将神经网络视为概率模型,则交叉熵会变成一个直观的损失函数,其利用Sigmoid或softmax非线性函数使输入数据被正确分类的可能性最大化。另一方面,均方误差更多地关注于标签不正确的数据。因此平均分类误差是一个粗略的标准。
交叉熵的优点是包括一个log项,使其粒度更细,同时考虑到了预测值与目标值的接近度。交叉熵也有更好的偏导数以产生较大的误差,这会使梯度更大以确保更快的学习速度。通常损失函数应根据输出单元跟概率模型假设相匹配的假设来选择。例如,softmax和交叉熵最适合多类分类。绘制交叉熵函数可能更容易解释,因为log项仅仅是因为学习过程主要表现为指数形式的一个指数过程。
试验不同的学习速率
学习速率是控制更新步骤大小的超参数。随着学习速率的提高,振荡次数会随之增加。如图2所示,随着学习速率的增加会引起更多混乱或随机噪声。图2里的所有的图都是针对MNIST数据集训练的单层神经网络。
我们可以从图中推断出,高的学习速率更有可能使整个模型爆炸,导致数值不稳定(如向上或向下溢出),这也是在运行这些实验时经验性的发现。事实上,NAN在第一个训练周期之后就出现了。
| 学习速率 | 交叉熵 | 分类误差 |
| 1 | 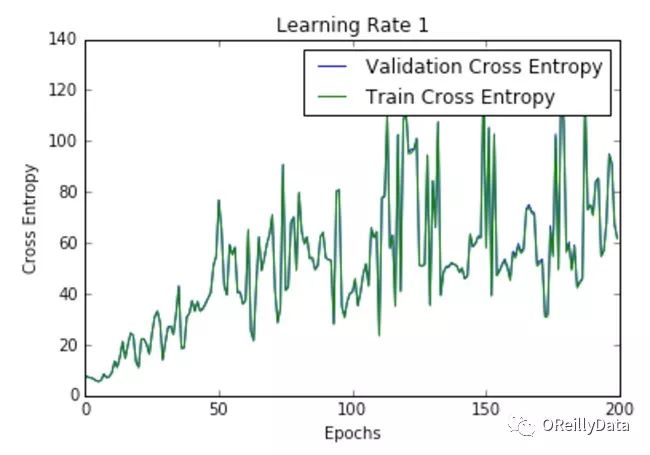 | 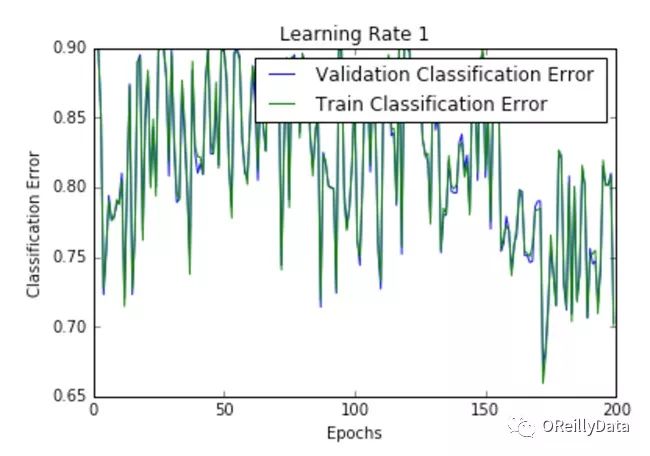 |
| .5 | 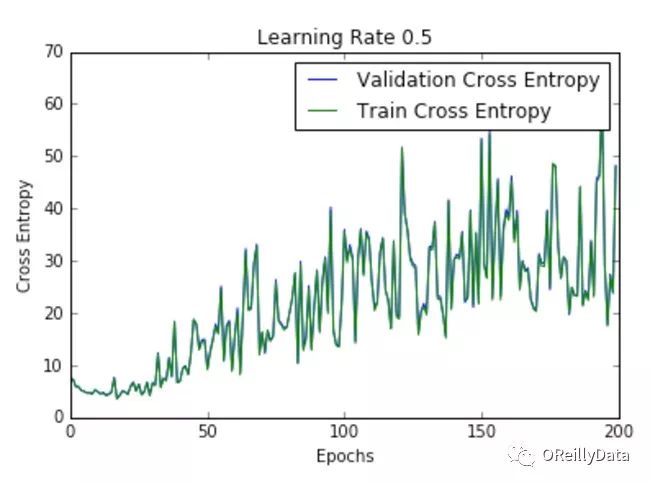 | 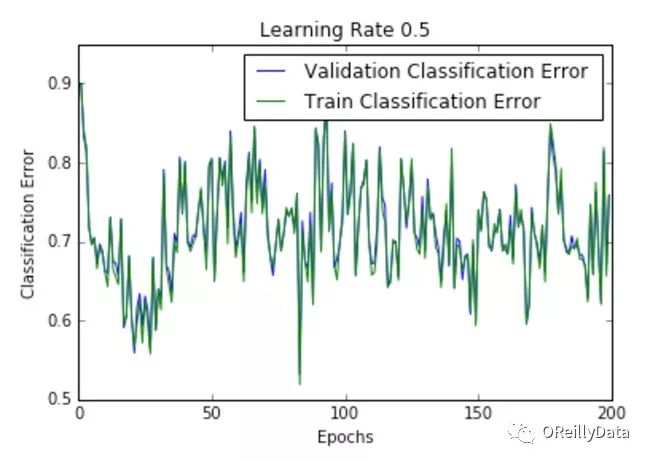 |
| .2 | 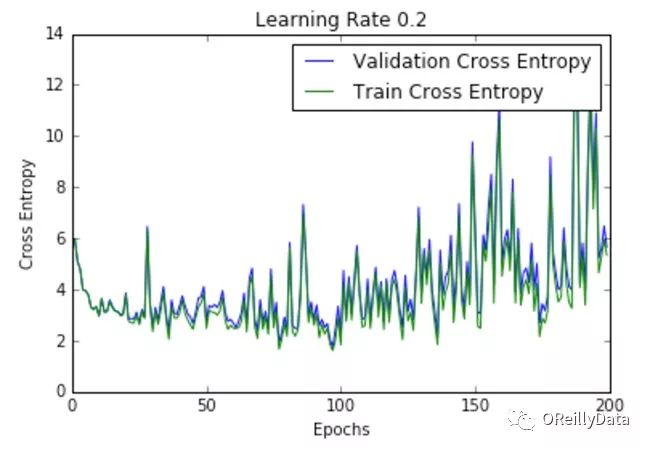 | 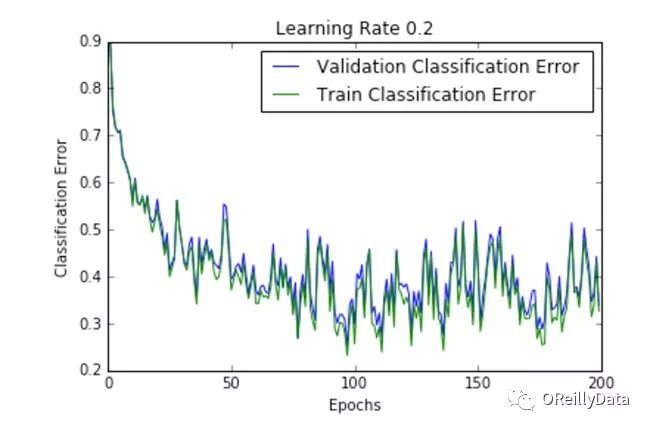 |
| .1 | 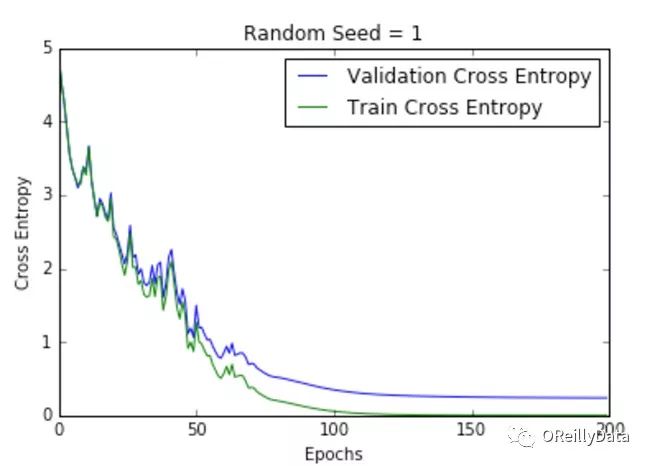 | 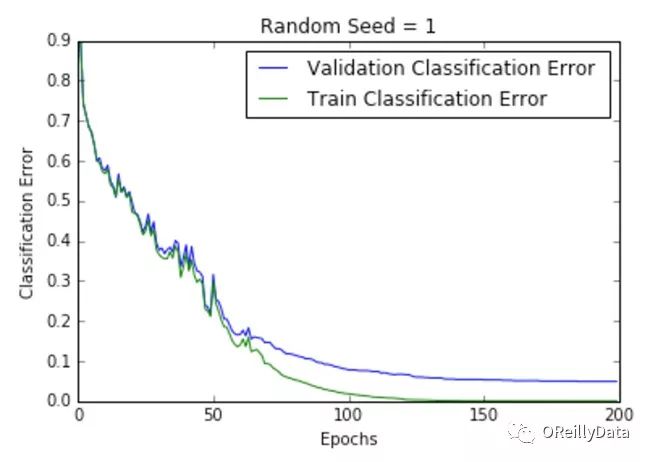 |
| .01 | 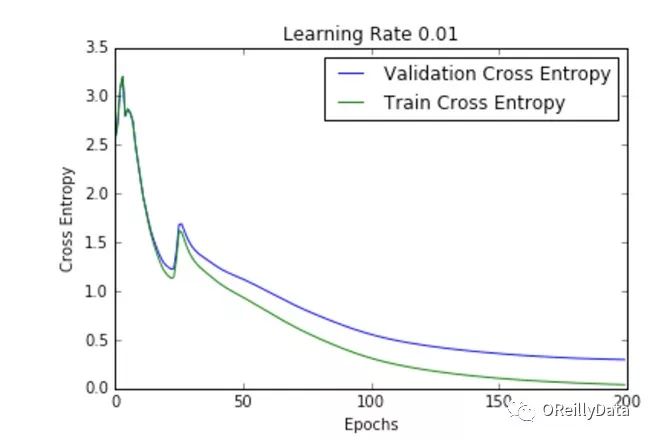 | 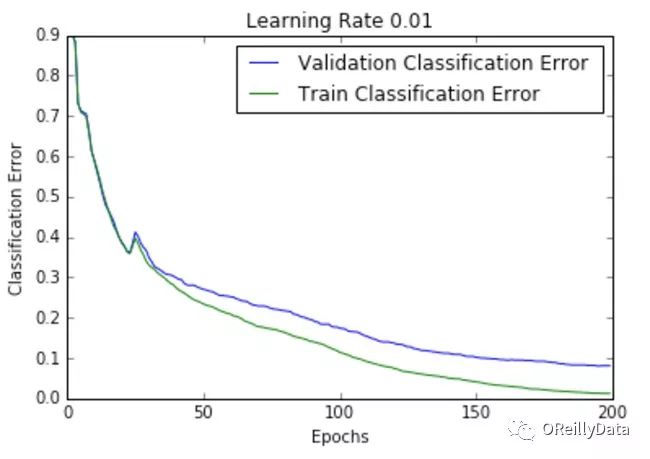 |
图2 在不同学习速率下损失随周期的变化。资料来源:Siddha Ganju
图2显示了不同学习速率下随周期变化的损失曲线。它比较了两种不同的损失函数:交叉熵和分类误差。这些图表明,在较低的学习速率下,模型改进是线性的(如学习速率0.01)。当学习速率高时,可以看到几乎指数级的跳跃(如学习速率1和0.5)。较高的学习速率能够更快地衰减损失,但缺点是大的跳跃可能会使他们陷入局部最低点,然后陷入较差的损失值。
这种现象通常表现为图中的振荡,表明所学习的参数主要是跳来跳去,并且不能使梯度向全局最小值移动。如果验证曲线跟训练曲线相近,则网络已被正确训练。然而,验证曲线和训练曲线之间的巨大差距表明网络在训练集上过度拟合(学习速率0.01)。这可以通过使用dropout或其他正则化技术来减少过拟合的几率。
为每个连接使用单独的自适应学习速率
神经网络通常不止只有一层。每层具有不同的扇入或输入单元的数量,其决定了由于同时更新单元输入权重所引起的超过目标的结果,这些权重用于校正相同错误(如全局学习速率)。另外梯度的大小因不同层而异,特别是如果初始权重小时(通常是初始化的情况)。因此适当的学习速率在不同权重时有很大的不同。
这个问题的一个解决方案是设置全局学习速率,并将其乘以一个合适的局部增益,该增益是由每个权重凭经验确定的。为了提高网络性能,增益应在合理的预定范围内。在使用单独的自适应学习速率时,或将整个批量用于学习,或使用比较大的小批量,以确保梯度信号的变化不是主要是由于小批量的抽样误差或随机波动引起的。这些每个权重的自适应学习速率也可以与动量相结合。(有关更多信息,请参见Coursera的神经网络课程的第6b节。)
迁移学习的学习速率
迁移学习是调整一个已有预先训练好的模型以供另一个应用使用。这种模型的复用是必要的,因为在某些应用领域中获取用于训练的大数据集是相对困难的。微调是迁移学习的一种,其中网络的一部分(比如最后一层)被修改以提供其他应用所需的特定数量的输出。还有许多我们没有在本文中讨论的其他类型的迁移学习。如图3所示,当网络已经在一种类型的数据上(钢琴数据)被训练好时,微调可以调整该网络去学习稍微不同的其他类型的数据(手风琴数据)

图3 对以前获得的钢琴知识进行微调用于学习手风琴。源自Anirudh Koul的《将深度学习放入移动电话中》,经许可使用
由于神经网络已被预先训练好,微调训练所需的时间要少得多,因为网络已经获得了需要的大部分信息,并且只需要在微调阶段改进这些知识。
在微调时,我们降低了整体学习速率同时提高了部分网络(最后一层或新层)的学习速率。例如,在开源Caffe框架中,base_lr应该在求解器prototxt中减少,而新引入的层的lr_mult应该增加。这有助于实现整体模型的缓慢变化,同时利用新数据快速改变新层。经验法则是保持需要更新的层的学习速率是其他静态层(全局学习速率)的至少10倍或更高。
结论
在这篇文章中,我们只是简要介绍了深度学习算法的多元参数宇宙中的一点东西。学习速率衰减是一个参数,其对于避免陷入局部极小值是至关重要的。在进行深度学习实验时,请记住尽可能地使用可视化。他们是了解深度学习黑匣子中到底发生了什么事情的最重要的方式之一。
想象一下深度学习里充满了各种小按钮和开关,就像飞行员的仪表板。我们需要学习如何调整这些按键以获得最佳的输出结果。我们可以随时为我们正在开发的应用找到一个预先训练好的模型,有选择性地添加或删除某些部分,并最终针对我们需要的应用进行微调。而且如果我们能精确地将学习速率画出来,我们就能较快地到达目的地。
This article originally appeared in English: "Contouring learning rate to optimize neural nets".

Siddha Ganju
Siddha毕业于卡内基梅隆大学,获得计算数据科学硕士学位。她的工作包括视觉问题回答以及利用生成对抗网络理解CERN的PB级数据。她已经在诸如CVPR等顶级会议上发表过文章。她是Strata数据大会和人工智能大会的常客(作为讲师),并为NASA的数据实验室提供咨询。不工作时她会去徒步旅行!可以访问Siddha的网站http://sidgan.me/siddhaganju


