
- 1中国下一代AI开源框架:国际、创新、实用和长期主义_各个开源框架名称
- 2PHP WebSocket:技术解析与实用指南_php socket
- 3自动化测试之selenium的chromedriver安装、配置的全部问题详解(保姆级教程)
- 4Python3获取办公室IP并更新至腾讯云安全组
- 5【安全】大模型安全综述
- 6【Docker】Docker的优势、与虚拟机技术的区别、三个重要概念和架构及工作原理详细讲解_容器和虚拟机区别,容器的架构
- 7Linux删除超大文件的前N行或后N行_linux 删除文件前n行
- 8Error querying database. Cause: java.lang.IllegalStateException 参数类型写错Long写成long
- 9数据库id自增重排序问题_数据库自增列重新排序
- 102024年幻兽帕鲁服务器搭建架设教程(保姆级)_幻兽帕鲁服务器配置
LLM之RAG理论(九)| 如何在LLM应用程序中提高RAG结果:从基础到高级
赞
踩
如果你正在用LLM(大型语言模型)构建产品或者功能,你可能会使用一种名为RAG(检索增强生成)的技术。RAG允许用户将LLM的训练数据中不可用的外部数据集成到LLM的文本生成过程中,这可以大大减少幻觉的产生,并提高文本响应的相关性。
RAG的想法其实很简单:查询并检索最相关的文本块,并将其插入LLM的原始提示中,这样LLM就可以访问这些引用文本片段,并可以使用它们生成响应。但是,要获得一个高质量的RAG管道(在生产环境中产生用户想要的确切结果)可能相当困难。
在这篇文章中,让我们探讨一下从最基本到更高级的技术,以提高LLM应用程序的RAG结果。
一、基本RAG
首先让我们介绍一下基本的RAG,它主要包括三个阶段:索引、检索和生成。
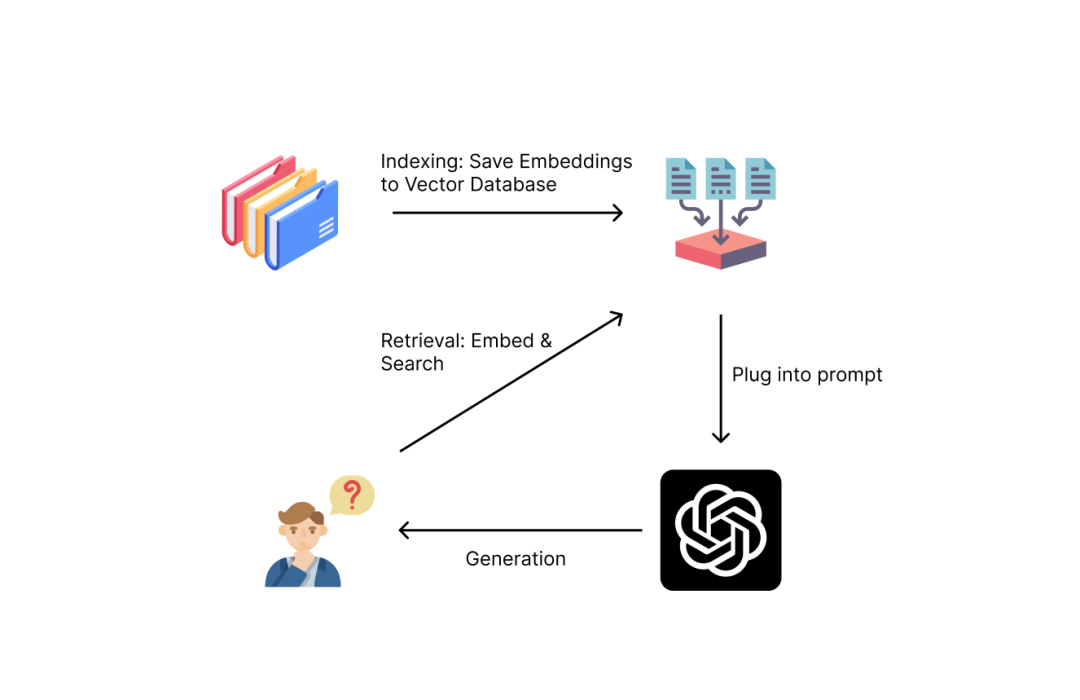
索引过程是为检索过程准备数据。你应该收集你想让你的LLM知道的一切,例如,产品文档、产品政策、公司网站等,这取决于你想让聊天机器人做什么。然后你会把它分解成更小的文本块(这样你就可以很容易地把这些块放进LLM的上下文大小)。然后,你将通过嵌入模型将块转换为矢量表示(这样以后你就可以很容易地找到类似的块)。最后,你可以将所有这些文本嵌入对保存在索引或矢量数据库中,以供检索使用。
检索过程发生在用户查询LLM时。在用户提出问题后,你可以保留该查询,而不是直接将其发送到LLM。相反,你将使用索引中文本块中的一些附加信息来丰富查询。你将使用相同的嵌入模型对用户的原始查询进行编码,然后执行相似性搜索,在数据库中找到最相似(大多数时候也是最相关)的文本块。
然后,为了生成,需要将文本块插入到包括用户原始查询的提示中,LLM将使用检索到的文本块中提供的信息生成答案。
以下是RAG的基本提示:
Answer the following question based on the given information only. If the given information is not enough to answer the question, simply reply "I don't know".Question: "<user's original query>"Given information: "<the text chunk you retrieved from the database>"RAG是业界公认的流程,LlamaIndex[1]和LangChain[2]两个流行的库支持上述这些步骤用于RAG流程。RAG需要矢量数据库来创建索引和检索,如Pinecone[3]和Chroma[4]。
这个过程简单有效,但在现实世界中,经常会面临以下问题:
- RAG无法检索用于生成的最相关的信息块。当检索到类似但不相关的块时,LLM将对用户的原始查询给出不正确的答案;
- RAG检索到的块没有正确的上下文。有时,检索到的块会错过周围的上下文,使它们无法生成有用的答案,甚至无法向LLM提供矛盾的信息;
- 用户的不同查询需要不同的检索或生成策略;
- 用户的数据结构可能不适合使用嵌入进行相似性搜索。
在下一节中,我们将介绍一些克服这些问题并提高RAG性能的技术。
二、提高RAG性能的技术
经过近一年的LLM使用,我学到了许多提高RAG性能的技术,并总结了一些使用RAG的经验教训。在本节中,我将介绍许多在检索前、检索中和检索后提高RAG性能的技术。
2.1 预检索技术
预检索技术包括可以在索引步骤中或在搜索数据库中的块之前使用的技术。
第一种技术是提高索引数据的质量。在机器学习领域,有一句话叫“垃圾进,垃圾出”,我认为这也适用于RAG,但许多人只是忽略了这一步骤,并在这一非常关键的初始步骤之后专注于优化步骤。您不应该期望将每一个文档(无论是否相关)都放入您的矢量数据库,并抱着最好的希望。为了提高索引数据的质量,您应该:(1)删除与特定任务无关的文本/文档(2)将索引数据重新格式化为与最终用户可能使用的格式类似的格式(3)向文档中添加元数据,以实现高效和有针对性的检索。
这是我自己的一个例子。我需要检索的文本是数学问题,但关于不同概念的两个数学问题在语义上可能相似。例如,许多问题可能使用“汤姆第一天吃了8个苹果……”,但它们可能测试加法、乘法和除法,这是非常不同的。在这种情况下,最好使用概念和级别的元数据对它们进行标记,并在检索它们之前检查正确的概念。
另一个非常典型的情况是,块在拆分时可能会丢失信息。考虑一篇典型的文章,开头的句子通过名字介绍实体,而后面的句子只依靠代词来指代它们。不包含实际实体名称的分割块将失去语义,无法通过向量搜索进行检索。因此,在这种情况下,用实际名称替换代词可以提高分割块的语义意义。
第二种技术是分块优化。根据你的下游任务是什么,你需要确定块的最佳长度是多少,以及你希望每个块有多少重叠。如果你的块太小,它可能不包括LLM回答用户查询所需的所有信息;如果块太大,它可能包含太多不相关的信息,从而混淆LLM,或者可能太大而无法适应上下文大小。
根据我自己的经验,对于管道中的所有步骤,您不必拘泥于一种块优化方法。例如,如果您的管道同时涉及高级任务(如摘要)和低级任务(如基于函数定义的编码),则可以尝试使用较大的块大小进行摘要,然而使用较小的块大小作为编码参考。
还有另一种技术是在尝试在矢量数据库中匹配用户的查询之前重写该查询。此步骤的本质是将用户的查询转换为与矢量数据库中的查询格式和内容类似的格式和内容。Query2Doc技术生成伪文档,并用这些文档扩展查询[5]。类似地,HyDE(假设文档嵌入)生成与查询相关的假设文档[6]。
以下是一些如何生成假设文档的示例:
# if your reference documents are blog articles.prompt = f"Please generate a paragraph from a blog article on {user_query}"# if your reference documents are code documentations in markdown.prompt = f"Please generate a code documentation for {user_query} in markdown format."使用Query2Doc或HyDE技术时的一个陷阱是,假设文档可能与实际文档相矛盾或完全不一致,这可能导致不准确的检索。为了解决这个问题,您可以检索包含和不包含假设文档的文档,这样您就可以应用我稍后将介绍的后期检索技术来找到最佳参考文本。
当用户的查询很复杂,可能需要多个参考文本时,可以使用LLM将其分解为多个子查询,然后为每个查询找到相关的文本块。例如,如果用户问两个不同的问题“ChomaDB和Weaviate之间的区别是什么?”,可以分为“什么是ChromaDB?”和“什么是Weaviate?”。
下面是一个要求LLM分解查询的示例:
Please rephrase the following query into three or fewer subqueries, so that each sub-query contains only one topic. Show each sub-query in each new line.Query:"<original user query>"如果您的聊天机器人或代理可以处理多个下游任务和不同格式的用户查询,您可以考虑使用查询路由,在该路由中,您可以将查询动态路由到不同的RAG进程。例如,如果你的用户正在询问一个问题的特定答案,你可以将他们路由到查询特定的块;如果你的用户要求一个整体的摘要,你可以将他们路由到一个递归创建的许多检索到的文档的摘要;如果您的用户要求在两个文档之间进行比较,您可能需要使用上面提到的子查询技术。您可以使用LLM本身进行路由,也可以使用关键字匹配/嵌入相似性进行路由。
2.2 检索技术
准备好查询后,可以在RAG管道的第二步中进一步改进检索结果。
第一种技术经常被忽视,因为人们只是跟着别人做——一直坚持向量相似性搜索。但是,您可以也应该考虑使用其他搜索方法来取代向量相似性搜索,或者通过混合搜索来补充它。尽管矢量相似性搜索在大多数情况下可以找到相关文档,但对于某些情况或数据结构,最好使用全文搜索、结构化查询、基于图的搜索或混合搜索方法。
例如,如果您的文本数据包含许多语义非常相似的块,但仅在某些关键字上有所不同,或者如果您的文字数据包含太多通用文字,则最好使用精确的关键字匹配进行搜索。例如,在电子商务中搜索仅按功能组不同的特定药物名称或数以万计的类似产品名称,可能会受益于全文匹配和过滤器。
另一个经常被忽视的技术是针对特定任务测试和使用不同的嵌入。许多人甚至不会考虑这一点,因为框架/向量数据库有一个默认的嵌入选项,他们只是随波逐流。但不同的嵌入模型实际上可以捕获不同的语义信息,并可能适用于不同的任务。一个有用的嵌入模型是指导嵌入,它允许您提供关于嵌入的数据类型和任务的具体说明[7][8]。您也可以参考MTEB排行榜,它是文本嵌入模型的基准。一定要测试这些模型,因为在排行榜上排名靠前并不意味着它最适合你的特定任务[9]。
除此之外,您还可以在检索过程中进行一些调整,使检索更具相关性。Small2big、递归或上下文感知检索是一种最初检索较小的数据块,由于更具体和更详细,这些数据块更有可能与查询匹配,然后继续检索父文档或围绕这些较小数据块的较大文本块,以包括更多上下文的技术。它们确保您检索相关的块以及所有重要的上下文。一些框架提供了对这种检索的支持,如LangChain[2]中的ParentDocumentRetriever、句子窗口和LlamaIndex[1]中的节点引用。
如果您可以从小到大地检索文档,那么您也可以用另一种方式来检索,分层检索从更通用到更具体。例如,您可以创建两层数据,一层包含原始块,另一层包含块的摘要。您首先在摘要索引中搜索最相关的文档,然后在这些文档中再次搜索特定的块。这样,你可以在第一关快速过滤掉不相关的文档,然后在第二关找到实际的信息进行问答。
类似地,您可以将递归搜索与图形搜索结合使用。该方法将相似性搜索与图形数据结构相结合。您首先通过向量相似性搜索找到最相关的块,然后探索与这些块相关的节点,以探索更多潜在的有用信息。例如,如果您有一个包含Notion或Obsidian等互连文档的数据库,则可以通过链接轻松找到LLM的相关文档。LlamaIndex通过RecursiveRetriever模块支持类似的搜索。
还有更多的代理方式来执行检索,方法是首先使用查询文档的工具/功能创建检索器代理,并让它决定是搜索更多信息还是仅将相关的检索块返回给原始代理以回答用户的查询。但这些技术通常需要更长的响应时间,而且可能不稳定,因此可能不是很好的生产选择。希望通过更强大的模型和更快的推理,我们可以在这个方向上获得更好的结果。
2.3 后检索技术
在从数据库中检索到相关的块之后,仍然有更多的技术可以提高生成质量。根据任务的性质和文本块的格式,您可以使用以下一种或多种技术。
如果你的任务与一个特定的块更相关,一种常用的技术是重新排序或评分。正如我前面提到的,向量相似性搜索中的高分并不意味着它总是具有最高的相关性。你应该进行第二轮重新排序或评分,找出对生成答案真正有用的文本块。对于重新排序或评分,您可以要求LLM对文档的相关性进行排序,也可以使用一些其他方法,如关键字频率或元数据匹配,在将这些文档传递给LLM以生成最终答案之前,对选择进行细化。
另一方面,如果你的任务与多个块有关——比如摘要或比较。您可以在将信息传递给LLM之前进行一些信息压缩作为后处理,以减少噪声或上下文长度。例如,您可以首先从每个块中总结、转述或提取关键点,然后将聚合的、浓缩的信息传递给LLM进行生成。
2.4 平衡质量和延迟
我发现还有一些其他技巧可以帮助改进和平衡生成质量和延迟。在实际生产中,您的用户可能没有时间等待多步骤RAG过程完成,尤其是当存在LLM调用链时。如果您想提高RAG管道的延迟,以下选择可能会有所帮助。
第一种是在某些步骤中使用更小、更快的模型。对于RAG过程中的所有步骤,您不一定需要使用最强大的模型(通常是最慢的)。例如,对于一些简单的查询重写、假设文档的生成或文本块的汇总,您可能可以使用更快的模型(如7B或13B本地模型)。这些模型中的一些甚至能够为用户生成高质量的最终输出。
如果你感兴趣,你可以阅读更多关于如何运行本地模型的信息[11],并在这个GitHub Repo[12]中查看我对一些小型LLM的评级。
下一个技术是使一些中间步骤并行运行。你不必总是等到一步完成后再进入第二步。您可以进行一些中间步骤,如并行混合搜索或多个块并行的摘要。要做到这一点,您可能需要大量修改RAG框架或自己创建RAG管道,但这可以大大减少最终输出的时间。
第三种技术是如果可能的话,让LLM做出多项选择,而不是生成长文本。例如,在重新排序/评分时,您可以要求LLM仅列出文本块的分数/排名,而不是将其生成或包括详细解释。
另一个有用的提示是为常见问题或常见查询实现缓存。如果新查询与旧查询非常相似或几乎相同,则系统可以提供即时答案,而无需每次都经过整个RAG过程。如果新查询有点相似,但仍然相关,您甚至可以将上一个查询的答案包含到LLM中,作为生成新答案的参考。
三、结论
在本文中,我介绍了许多可以在LLM支持的应用程序中改进RAG管道的技术,包括:
-RAG的基本过程:索引、检索和生成
-预检索技术:
- 提高索引数据的质量
- 块优化
- 查询重写
-检索技术
- 使用其他搜索方法
- 使用不同的嵌入模型
- Small2big、递归或上下文感知检索
- 分层检索
-后期检索技术
- 重新排序或对检索到的块进行评分
- 信息压缩
-平衡质量和延迟
- 在某些步骤中使用更小、更快的模型
- 使中间步骤平行运行
- 让LLM做出选择而不是生成
- 实现缓存
您可以在RAG管道中使用其中一种或多种技术,使其更加准确和高效。我希望这些技术可以帮助你为你的应用程序构建一个更好的RAG管道。
参考文献:
[1] http://www.llamaindex.ai/
[2] http://www.langchain.com/
[3] http://www.pinecone.io/
[4] http://www.trychroma.com/
[5] https://browse.arxiv.org/abs/2303.07678
[6] https://browse.arxiv.org/abs/2212.10496
[7] https://browse.arxiv.org/abs/2212.09741
[8] https://github.com/xlang-ai/instructor-embedding
[9] https://huggingface.co/spaces/mteb/leaderboard
[10] https://doi.org/10.48550/arXiv.2312.10997
[11] https://medium.com/design-bootcamp/a-complete-guide-to-running-local-llm-models-3225e4913620
[12] https://github.com/Troyanovsky/Local-LLM-Comparison-Colab-UI
[13] https://bootcamp.uxdesign.cc/how-to-improve-rag-results-in-your-llm-apps-from-basics-to-advanced-822818014144

