
- 1服务器上搭建网页版vscode|一站式搭建附各种问题解决|nginx反向代理实现域名登陆|域名注册解析|搭配ipad使用_csdn建立vscode网页版
- 2Vivado2020.2 联合 Modelsim2019.2进行仿真_和vivado2020适配的modelsim
- 3关于GRUB2引导grub4dos时"--config-file"参数失效的问题
- 4HarmonyOS开发Java与ArkTS如何抉择_arkts 不选java
- 5JavaWeb——注解_@webexport
- 6用Python画向日葵?
- 7用pyhton爬取网页中的视频代码_用python爬取网页视频的代码
- 8Docker的安装
- 9Springboot + redis操作多种实现(以及Jedis,Redisson,Lettuce的区别比较)_redisson和lettuce
- 10kubernetes Pod控制器详解
如何解决微服务的数据一致性分发问题?
赞
踩
介绍
系统架构微服务化以后,根据微服务独立数据源的思想,每个微服务一般具有各自独立的数据源,但是不同微服务之间难免需要通过数据分发来共享一些数据,这个就是微服务的数据分发问题。Netflix/Airbnb等一线互联网公司的实践[参考附录1/2/3]表明,数据一致性分发能力,是构建松散耦合、可扩展和高性能的微服务架构的基础。
本文解释分布式微服务中的数据一致性分发问题,应用场景,并给出常见的解决方法。本文主要面向互联网分布式系统架构师和研发经理。
为啥要分发数据?场景?

数据分发场景
我们还是要从具体业务场景出发,为啥要分发数据?有哪些场景?在实际企业中,数据分发的场景其实是非常多的。假设某电商企业有这样一个订单服务Order Service,它有一个独立的数据库。同时,周边还有不少系统需要订单的数据,上图给出了一些例子:
一个是缓存系统,为了提升订单数据的访问性能,我们可以把频繁访问的订单数据,通过Redis缓存起来;
第二个是Fulfillment Service,也就是订单履行系统,它也需要一份订单数据,借此实现订单履行的功能;
第三个是ElasticSearch搜索引擎系统,它也需要一份订单数据,可以支持前台用户、或者是后台运营快速查询订单信息;
第四个是传统数据仓库系统,它也需要一份订单数据,支持对订单数据的分析和挖掘。
当然,为了获得一份订单数据,这些系统可以定期去订单服务查询最新的数据,也就是拉模式,但是拉模式有两大问题:
一个是拉数据通常会有延迟,也就是说拉到的数据并不实时;
如果频繁拉的话,考虑到外围系统众多(而且可能还会增加),势必会对订单数据库的性能造成影响,严重时还可能会把订单数据库给拉挂。
所以,当企业规模到了一定阶段,还是需要考虑数据分发技术,将业务数据同步分发到对数据感兴趣的其它服务。除了上面提到的一些数据分发场景,其实还有很多其它场景,例如:
第一个是数据复制(replication)。为了实现高可用,一般要将数据复制多分存储,这个时候需要采用数据分发。
第二个是支持数据库的解耦拆分。在单体数据库解耦拆分的过程中,为了实现不停机拆分,在一段时间内,需要将遗留老数据同步复制到新的数据存储,这个时候也需要数据分发技术。
第三个是实现CQRS,还有去数据库Join。这两个场景我后面有单独文章解释,这边先说明一下,实现CQRS和数据库去Join的底层技术,其实也是数据分发。
第四个是实现分布式事务。这个场景我后面也有单独文章讲解,这边先说明一下,解决分布式事务问题的一些方案,底层也是依赖于数据分发技术的。
其它还有流式计算、大数据BI/AI,还有审计日志和历史数据归档等场景,一般都离不开数据分发技术。
总之,波波认为,数据分发,是构建现代大规模分布式系统、微服务架构和异步事件驱动架构的底层基础技术。
双写?
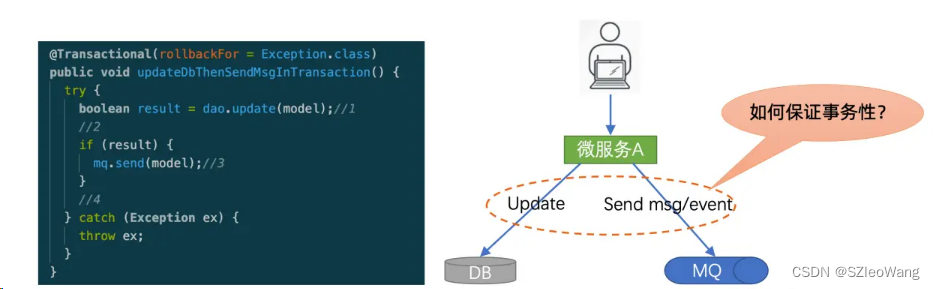
如何保证双写的事务性?
对于数据分发这个问题,乍一看,好像并不复杂,稍有开发经验的同学会说,我在应用层做一个双写不就可以了吗?比方说,请看上图右边,这里有一个微服务A,它需要把数据写入DB,同时还要把数据写到MQ,对于这个需求,我在A服务中弄一个双写,不就搞定了吗?其实这个问题并没有那么简单,关键是你如何才能保证双写的事务性?
请看上图左边的代码,这里有一个方法updateDbThenSendMsgInTransaction,这个方法上加了事务性标注,也就是说,如果抛异常的话,数据库操作会回滚。我们来看这个方法的执行步骤:
第一步先更新数据库,如果更新成功,那么result设为true,如果更新失败,那么result设为false;
第二步,如果result为true,也就是说DB更新成功,那么我们就继续做第三步,向mq发送消息
如果发消息也成功,那么我们的流程就走到第四步,整个双写事务就成功了。
如果发消息抛异常,也就是发消息失败,那么容器会执行该方法的事务性回滚,上面的数据库更新操作也会回滚。
初看这个双写流程没有问题,可以保证事务性。但是深入研究会发现它其实是有问题的。比方说在第三步,如果发消息抛异常了,并不保证说发消息失败了,可能只是由于网络异常抖动而造成的抛异常,实际消息可能是已经发到MQ中,但是抛异常会造成上面数据库更新操作的


