
- 1路径规划 | 图解D* Lite算法(附ROS C++/Python/Matlab仿真)_python d* lite实现
- 2vue实现类似target="_blank"打开新窗口_element-plus 菜单新窗口打开 target="_blank
- 3ETL数据仓库的使用方式
- 4android应用程序开发_Android开发十年,我把NDK&UI&安全开发经验写成了实战文档...
- 5蓝桥杯练习系统习题(Python)--历届试题 成绩分析_蓝桥杯小学组python初赛晋级分数
- 6unity-鼠标点击并判断是否撞到物体(通过射线判断)_unity点击物体检测
- 7【已解决】xls“的文件格式和扩展名不匹配。文件可能已损坏或不安全。除非您信任其来源,否则请勿打开。是否仍要打开它?_新建xls格式工作表与扩展名不匹配
- 8多线程与多核运算(Threading&MultiProcess)_多核和多线程
- 9BufferedInputStream 和 BufferedOutputStream_mbufferedwrite缓冲区设置多大合适
- 10HTML新年贺卡源代码,春节贺卡源代码、新春贺卡_h5新年贺卡源代码
图像处理实战02-yolov5目标检测_yolov5是算法还是框架
赞
踩
yolov5
YOLOv5 是一种目标检测算法,它是 YOLO (You Only Look Once) 系列算法的最新版本。YOLOv5 采用了一种新的架构,它包括一个基于 CSPNet (Cross Stage Partial Network) 的主干网络以及一系列改进的技巧,如多尺度训练、数据增强、网络混合精度训练等,从而实现了更快的检测速度和更好的检测精度。
YOLOv5 支持多种类型的目标检测任务,如物体检测、人脸检测、车辆检测等,可以应用于各种实际场景,如智能安防、自动驾驶、机器人视觉等。同时,YOLOv5 还提供了预训练的模型和开源代码,方便开发者进行模型的训练和应用。
github地址:https://github.com/ultralytics/yolov5/blob/master/README.zh-CN.md
官网:https://ultralytics.com/
发展历程
YOLO(You Only Look Once)是一系列的目标检测模型,由Joseph Redmon等人开发。以下是YOLO系列的发展历程:
-
YOLOv1:于2015年首次提出,是YOLO系列的第一个版本。YOLOv1通过将目标检测任务转化为回归问题,将图像划分为网格并预测每个网格的边界框和类别概率。然而,YOLOv1存在定位不准确和对小目标敏感的问题。
-
YOLOv2(YOLO9000):于2016年提出,是YOLO系列的第二个版本。YOLOv2通过引入Darknet-19网络结构、使用anchor boxes和多尺度预测来改进检测性能。同时,YOLOv2还引入了目标类别的语义分割,可以检测更多类别的目标。
-
YOLOv3:于2018年提出,是YOLO系列的第三个版本。YOLOv3针对YOLOv2存在的问题进行了改进,引入了多尺度预测、使用FPN结构和使用更小的anchor boxes等技术,提高了检测精度和对小目标的检测能力。
-
YOLOv4:于2020年提出,是YOLO系列的第四个版本。YOLOv4在YOLOv3的基础上引入了一系列改进,包括CSPDarknet53作为主干网络、使用SAM和PANet模块来提取特征、使用YOLOv3和YOLOv4的预训练权重进行初始化等,提高了检测性能和速度。
-
YOLOv5:于2020年提出,是YOLO系列的第五个版本。YOLOv5采用了轻量化的网络结构,提高了检测的速度,并引入了一些新功能,如YOLOv5-seg分割模型、Paddle Paddle导出功能、YOLOv5 AutoCache自动缓存功能和Comet日志记录和可视化集成功能。
总体而言,YOLO系列模型通过不断的改进和优化,提高了目标检测的性能和速度,并在计算机视觉领域取得了重要的突破。
yolov8
YOLOv8是YOLO系列模型的一个变种,它在YOLOv5的基础上进行了改进和优化。YOLOv8模型包含了检测(Detect)、分割(Segment)和姿态估计(Pose)、跟踪(Track)以及分类(Classify)等功能。下面是对这些功能的简要说明:
-
检测(Detect):YOLOv8模型能够对图像或视频中的目标进行实时的物体检测。它通过预测目标的边界框和类别信息来完成检测任务。
-
分割(Segment):YOLOv8模型还支持目标分割的功能,即将图像中的每个像素进行分类,将不同的目标区域进行分割。这个功能可以用于识别图像中的不同物体,并进行更精确的定位和分析。
-
姿态估计(Pose):YOLOv8模型还可以对检测到的目标进行姿态估计,即推断目标在三维空间中的姿态信息。这对于一些需要了解目标的方向和位置的应用非常有用,比如人体姿态分析、机器人导航等。
-
跟踪(Track):YOLOv8模型还具有目标跟踪的功能,即在视频中连续追踪相同目标的位置和轨迹。这对于视频监控、自动驾驶等应用非常重要。
-
分类(Classify):除了目标检测和分割功能之外,YOLOv8模型还可以对检测到的目标进行分类,即给出目标的类别信息。这对于了解目标的属性和进行更细粒度的分析非常重要。
总而言之,YOLOv8模型综合了多种功能,包括检测、分割、姿态估计、跟踪和分类等,使其具备了更广泛的应用领域和更强大的功能。

github地址:https://github.com/ultralytics/ultralytics
v5入门示例
安装
克隆 repo,并要求在 Python>=3.7.0 环境中安装 requirements.txt ,且要求 PyTorch>=1.7 。
micromamba create prefix=d:/python380 python=3.8 #创建3.8的虚拟环境
micromamba activate d:/python380
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install
- 1
- 2
- 3
- 4
- 5
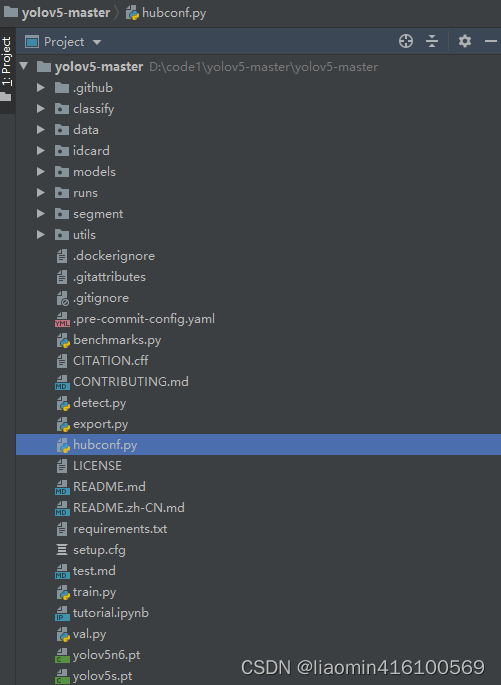
源代码目录结构
yolov5/ ├── data/ # 数据集配置目录 │ ├── coco.yaml # COCO数据集配置文件,里面有数据集的下载地址和加载的python脚本 │ ├──ImageNet.yaml # ImageNet数据集 │ ├── custom.yaml # 自定义数据集配置文件 │ └── ... # 其他数据集配置文件 ├── models/ # 模型定义目录 │ ├── common.py # 通用函数和类定义 │ ├── experimental.py # 实验性模型定义 │ ├── export.py # 导出模型为ONNX的脚本 │ ├── models.py # YOLOv5模型定义 │ ├── yolo.py # YOLO类定义 │ └── ... # 其他模型定义文件 ├── utils/ # 实用工具目录 │ ├── autoanchor.py # 自动锚框生成工具 │ ├── datasets.py # 数据集处理工具 │ ├── general.py # 通用实用函数 │ ├── google_utils.py # Google云平台工具 │ ├── loss.py # 损失函数定义 │ ├── metrics.py # 评估指标定义 │ ├── torch_utils.py # PyTorch工具 │ ├── wandb_logging.py # WandB日志记录工具 │ └── ... # 其他实用工具文件 ├── runs/ # 训练和预测的结果输出目录 │ ├── detect # 使用detect.py训练后输出目录,输出的目录是[ex自增数字] │ ├── train # 使用detect.py训练后输出目录,输出的目录是[ex自增数字],包含了训练好的模型和测试集效果 ├── weights/ # 预训练模型权重目录 ├── .gitignore # Git忽略文件配置 ├── Dockerfile # Docker容器构建文件 ├── LICENSE # 许可证文件 ├── README.md # 项目说明文档 ├── requirements.txt # 项目依赖包列表 ├── train.py # 训练脚本 ├── detect.py # 预测脚本 ├── export.py # 导出YOLOv5 PyTorch model to 其他格式 ├── hubconf.py # hubconf.py文件是用于定义模型和数据集的Python模块 └── ... # 其他源代码文件

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
这里通过yolov5可以下载到很多常用的训练数据集,而且很轻松的找到下载地址,如ImageNet,
coco128等,不用自己辛苦的找了
模型下载
下载地址:https://github.com/ultralytics/yolov5/releases
v6.1
这里的版本是v6.1是yolov5的子版本号
Pretrained Checkpoints
Pretrained Checkpoints 是预训练权重文件的一种称呼。在深度学习中,预训练权重是指在大规模数据集上通过无监督学习或有监督学习得到的模型参数。这些参数通常可以被用来初始化一个新的模型,从而加速模型训练并提高模型的性能。
Pretrained Checkpoints 是指已经训练好的预训练权重文件,可以用来初始化一个新的模型,并继续训练这个模型以适应新的任务或数据集。这种方法被称为迁移学习,可以大大提高模型的训练效率和泛化能力。在计算机视觉领域,常见的预训练网络包括 VGG、ResNet、Inception、MobileNet 等。
模型概述
以下模型列的解释
| 列名 | 解释 |
|---|---|
| Model | 模型的名称 |
| size(pixels) | 输入图像的大小(以像素为单位) |
| mAPval0.5:0.95 | 在验证集上的平均精确度(mean Average Precision),考虑所有IOU阈值从0.5到0.95的情况,准确率是% |
| mAPval0.5 | 在验证集上的平均精确度,只考虑IOU阈值为0.5的情况 |
| Speed CPU b1(ms) | 在CPU上使用batch size为1时的推理速度(以毫秒为单位) |
| Speed V100 b1(ms) | 在NVIDIA V100 GPU上使用batch size为1时的推理速度(以毫秒为单位) |
| Speed V100 b32(ms) | 在NVIDIA V100 GPU上使用batch size为32时的推理速度(以毫秒为单位) |
| params (M) | 模型的参数量(以百万为单位) |
| FLOPs @640 (B) | 在输入图像大小为640时,模型的浮点运算次数(以十亿为单位) |
| Model | size(pixels) | mAPval0.5:0.95 | mAPval0.5 | Speed CPU b1(ms) | Speed V100 b1(ms) | Speed V100 b32(ms) | params (M) | FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
v7.0
新的YOLOv5 v7.0实例分割模型是世界上最快、最准确的,超过了所有当前的SOTA基准。我们使它们非常简单易用,可以轻松进行训练、验证和部署。
这个版本中的主要目标是引入与我们现有的目标检测模型类似的超级简单的YOLOv5分割工作流程。
重要更新
- 分割模型 ⭐ 新增:第一次提供了SOTA YOLOv5-seg COCO预训练的分割模型(由@glenn-jocher、@AyushExel和@Laughing-q开发的#9052)
- Paddle Paddle导出:使用python export.py --include paddle 可以将任何YOLOv5模型(cls、seg、det)导出为Paddle格式(由@glenn-jocher开发的#9459)
- YOLOv5 AutoCache:使用python train.py --cache ram 现在会扫描可用内存并与预测的数据集RAM使用量进行比较。这降低了缓存风险,并应该有助于提高数据集缓存功能的使用率,从而显著加快训练速度。(由@glenn-jocher开发的#10027)
- Comet日志记录和可视化集成:永久免费,Comet可以保存YOLOv5模型,恢复训练,并进行交互式可视化和调试预测。(由@DN6开发的#9232)
| Model | size (pixels) | mAPbox 50-95 | mAPmask 50-95 | Train time 300 epochs A100 (hours) | Speed ONNX CPU (ms) | Speed TRT A100 (ms) | params (M) | FLOPs @640(B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-seg | 640 | 27.6 | 23.4 | 80:17 | 62.7 | 1.2 | 2.0 | 7.1 |
| YOLOv5s-seg | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
| YOLOv5m-seg | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
| YOLOv5l-seg | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
| YOLOv5x-seg | 640 | 50.7 | 41.4 | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
我这里选择一个V6.1模型yolov5n6.pt
将模型丢到yolov5项目根目录即可
预测
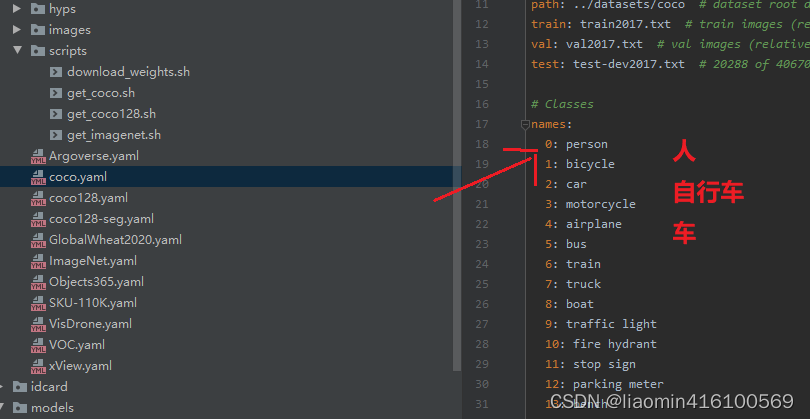
因为预训练模型,已经有检测某些类别能力,我们可以看下data/coco.yml中names可以看到总共有80个类别
在yolov5中可以使用./detect.py脚本来进行目标物品检测。
以下是对"./detect.py"脚本中常见参数的详细解释:
-
--source:指定输入源,可以是图像路径、视频文件路径或摄像头索引(默认为当前目录data/images,里面就两张图片)。 -
--weights:指定模型权重文件的路径。可以是本地路径或PaddleHub模型中心的模型名称,默认是当前目录的yolov5s.pt。 -
--data:指定要使用的数据集的配置文件。数据集的配置文件包含了数据集的路径、类别标签、训练集、验证集和测试集的划分等信息,默认data/coco128.yaml,选填。 -
--img-size:指定输入图像的尺寸,格式为",“,例如"640,480”。默认为640x640。 -
--conf-thres:目标置信度阈值,范围为0到1。超过该阈值的目标将被保留,默认为0.25。 -
--iou-thres:NMS(非极大值抑制)的IoU(交并比)阈值,范围为0到1。重叠度大于该阈值的目标将被合并,默认为0.45。 -
--max-det:每个图像中最多检测的目标数,默认为100。 -
--device:指定使用的设备,可以是"cpu"或"cuda"。默认为"cpu"。 -
--view-img:在检测过程中显示图像窗口。 -
--save-txt:保存检测结果的txt文件。 -
--save-conf:保存检测结果的置信度。 -
--save-crop:保存检测结果的裁剪图像。 -
--half:使用半精度浮点数进行推理。
这些参数可以根据您的需求进行调整,以获得最佳的检测结果。您可以在运行脚本时使用--help参数查看更多参数选项和说明。
执行命令预测
python ./detect.py --source ./data/images --weight ./yolov5n6.pt
- 1
执行结果
(D:\condaenv\yolov5) D:\code1\yolov5-master\yolov5-master>python ./detect.py --source ./data/images --weight ./yolov5n6.pt
detect: weights=['./yolov5n6.pt'], source=./data/images, data=data\coco128.yaml, imgsz=[640, 640], conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=Fal
se, augment=False, visualize=False, update=False, project=runs\detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 2023-5-30 Python-3.8.16 torch-2.0.1+cpu CPU
Fusing layers...
YOLOv5n6 summary: 280 layers, 3239884 parameters, 0 gradients
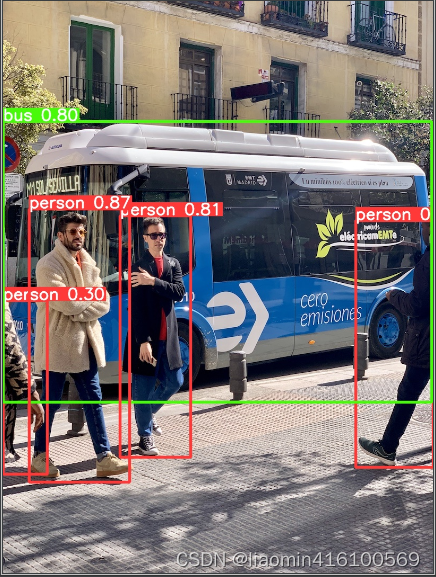
image 1/2 D:\code1\yolov5-master\yolov5-master\data\images\bus.jpg: 640x512 4 persons, 1 bus, 211.9ms
image 2/2 D:\code1\yolov5-master\yolov5-master\data\images\zidane.jpg: 384x640 3 persons, 1 tie, 152.9ms
Speed: 1.0ms pre-process, 182.4ms inference, 3.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
找到runs\detect\exp8 打开目录查看分类图片

训练模型
参考自官网:https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/#before-you-start
准备数据集
创建数据集yaml
COCO128是一个小型教程数据集的例子,由COCO train2017中的前128张图像组成。这128张图像同时用于训练和验证,以验证我们的训练流程能够过拟合。data/coco128.yaml是数据集配置文件,定义了以下内容:
1)数据集根目录路径以及训练/验证/测试图像目录的相对路径(或包含图像路径的*.txt文件);
2)类别名称字典。
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..] path: ../datasets/coco128 # dataset root dir train: images/train2017 # train images (relative to 'path') 128 images val: images/train2017 # val images (relative to 'path') 128 images test: # test images (optional) # Classes (80 COCO classes) names: 0: person 1: bicycle 2: car ... 77: teddy bear 78: hair drier 79: toothbrush # Download script/URL (optional) download: https://ultralytics.com/assets/coco128.zip
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
https://ultralytics.com/assets/coco128.zip下载后,目录结构如下
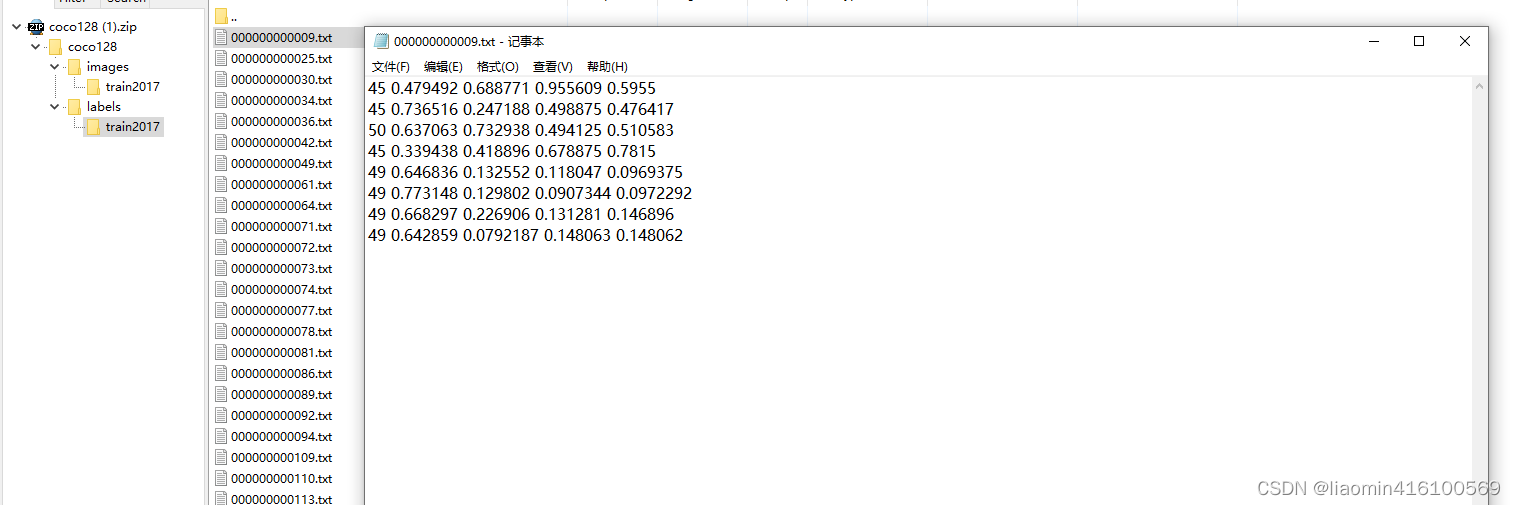
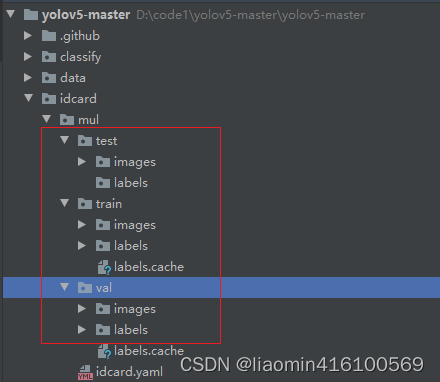
我这里用来训练判断一个身份证的正反面,我在项目根目录新建一个idcard目录,下面在建一个mul目录,这个目录只是用来训练不同的身份证信息用来区分的,我们的所有数据集都在mul目录
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./idcard/mul # dataset root dir
train: images # train images
val: images # val images
test: images # test images
# Classes
names:
0: idcard_z #表示身份证正面
1: idcard_f #表示身份证反面
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注意这里yolov5回自动找path下的train目录在加上你的images作为图片的目录
比如真正的训练目录是:./idcard/mul/train/images,images的同级目录下会有个labels目录是标注
验证集的目录是:./idcard/mul/val/images
测试集的目录是:./idcard/test/val/images
一般来说,常见的做法是将数据集划分为训练集、验证集和测试集,比如将数据划分为70%的训练集、15%的验证集和15%的测试集。这种比例通常适用于较小的数据集。对于较大的数据集,可以考虑增加验证集和测试集的比例。
创建labels
在使用注释工具(labelme,lableimg)为图像标注后,将标签导出为YOLO格式,每个图像对应一个*.txt文件(如果图像中没有对象,则不需要*.txt文件)。*.txt文件的规范如下:
- 每个对象占据一行
- 每行的格式为:类别 x中心点 y中心点 宽度 高度。
框的坐标必须使用归一化的xywh格式(范围在0-1之间)。如果您的框的坐标是以像素为单位的,则需要将x中心点和宽度除以图像宽度,并将y中心点和高度除以图像高度。 - 类别编号从零开始(索引为0),和数据集yaml的names索引对应。
这里建议使用labelimg标注
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
切换到当前环境输入labelimg ,输入labelimage命令打开

选择open dir选择你的需要标记的图片目录(idcard/mul/train/images目录),Change Save Dir选择你的idcard/mul/train/labels目录,选择YOLO格式
打开了图片后,需要一张一张图片的标记,常用的操作步骤是:
- 按w唤起一个矩形框,选择你要选择的目标,选择后,弹出label,注意要先标注一个data.yaml中索引为0的,然后是1的,后面在弹出是可以选择的。

- 标准完成后ctrl+s保存。
- 按键盘d键切换到下一张图片,继续按w矩形框标注,知道所有图片完成。
在你的labels目录下会有个classes.txt,看下他的顺序是否和data.yaml一致,如果不一致,不要调整classes.txt,调整data.yaml保持一致就行。
训练
我这里准备了差不多350个标注好的图片,训练后识别率98%。
使用train.py执行
# --weight是指定初始的权重,可以用它来fine tuning调整训练你自己的模型。
python train.py --batch-size 4 --epochs 10 --data .\idcard\mul\idcard.yaml --weight .\yolov5n6.pt
- 1
- 2
执行完成后,runs\trains\expn\weights\best.pt就是训练好的模型,可以使用之前的detect.py指定这个模型来预测下
python ./detect.py --source .\idcard\mul\test\images --weight .\runs\train\exp3\weights\best.pt
- 1
查看runs\detect\expn\下的预测图片



模型应用
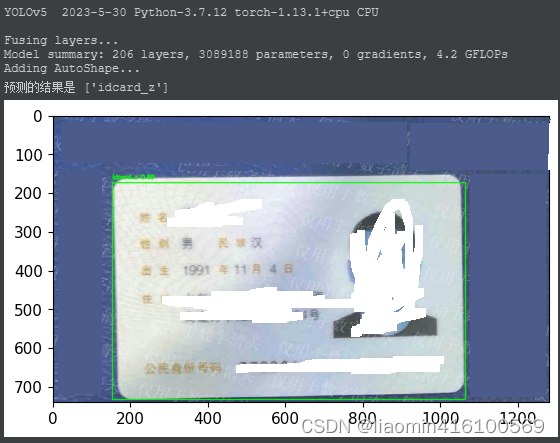
我们需要在我们的应用使用生成好的best.pt模型可以使用torch.hub
#使用我们本地之前用于训练的yolov5-master,我有把best.pt拷贝到当前目录 model = torch.hub.load('D:\\code1\\yolov5-master\\yolov5-master', 'custom', path='./best.pt', source='local') # local repo #print(model) # 读取图像 img = cv2.imread('../images/zm.jpg') # 进行预测 results = model(img) resultLabel=[] # 解析预测结果 for result in results.xyxy[0]: x1, y1, x2, y2, conf, cls = result.tolist() if conf > 0.5: # 绘制边框和标签 cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 255, 0), 2) cv2.putText(img, f"{model.names[int(cls)]} {conf:.2f}", (int(x1), int(y1 - 10)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2) resultLabel.append(model.names[int(cls)]) # 显示图像 print("预测的结果是",resultLabel) plt.imshow(img) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
这是官方提供在线的版本调用,但是程序会自动去下载ultralytics/yolov5包和yolov5s模型,速度很慢
import torch
# Model
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
# Images
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
# Inference
results = model(img)
# Results
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

