
【论文精读系列】Real-ESRGAN_real-esrgan超分重构如何做到的
赞
踩
论文标题:Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data
论文地址:https://arxiv.org/abs/2107.10833v2
作者代码:https://github.com/xinntao/Real-ESRGAN
原文概述
在单张图片超分辨率(Single Image Super-resolution)的问题中,许多方法都采用传统的 Bicubic 方法实现降采样,但是这与现实世界的降采样情况不同,太过单一。
盲超分辨率(Blind Super-resolution)旨在恢复未知且复杂的退化的低分辨率图像。根据其使用的降采样方式不同,可以分为显式建模(explicit modeling)和隐式建模(implicit modeling)。
-
显式建模:经典的退化模型由模糊、降采样、噪声和 JPEG 压缩组成。但是现实世界的降采样模型过于复杂,仅通过这几个方式的简单组合无法达到理想的效果。
-
隐式建模:依赖于学习数据分布和采用 GAN 来学习退化模型,但是这种方法受限于数据集,无法很好的泛化到数据集之外分布的图像。
在现实世界中,图像分辨率的退化通常是由多种不同的退化复杂组合而成的。
例如,当我们使用手机拍照时,照片可能会发生多种退化,比如相机模糊、传感器噪声、锐化伪影和 JPEG 压缩。然后,我们进行一些编辑,并上传到一个社交媒体程序,这将引入进一步的压缩并增加未知的噪声。当图像在互联网上被多次分享时,上述过程会变得更加复杂。
因此,作者将经典的一阶退化模型(“first-order” degradation model)拓展现实世界的高阶退化建模(“high-order” degradation modeling),即利用多个重复的退化过程建模,每一个退化过程都是一个经典的退化模型。但是为了平衡简单性和有效性,作者在代码中实际采用的是二阶退化模型(“second-order” degradation model)。

但是因为采用了高阶退化模型,使得退化空间相比于 ESRGAN 来说大得多,训练也就更加具有挑战性。因此作者在 ESTGAN 的基础上做了两个改动:1)使用 U-Net 判别器替换 ESRGAN 中使用的 VGG 判别器;2)引入 spectral normalization 来使得训练更加稳定,并减少 artifacts。
综上所述,在这篇文章中作者做出了如下研究,1)提出使用高阶退化模型,并利用 sinc 滤波器来建模常见的振铃(ringing)和超调效应(overshoot artifacts)。2)采用了一些基本的修改(例如,带 spectral normalization 的 U-Net 判别器)来增加判别器的能力和训练稳定性。3)使用纯合成数据训练的 Real-ESRGAN 能够恢复大部分真实世界的图像,比以往的作品具有更好的视觉性能,在现实世界中更具有实用性。
经典退化模型(Classical Degradation Model)
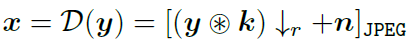
其中, y y y 表示原始图像, k k k 表示模糊函数, ↓ r \downarrow_r ↓r 表示下采样因子, n n n 表示噪声, [ ] J P E G []_{JPEG} []JPEG表示将得到的结果使用 JPEG 方式压缩处理。
因此,整个式子的含义就是将一张高分辨率图像 y y y 通过模糊处理之后进行下采样,然后添加噪声,最后通过 JPEG 压缩处理得到低分辨率图像 x x x。
高阶退化模型(High-order Degradation Model)
高阶退化模型是在一阶退化模型的基础上,重复多次得到,但是每一次退化过程中使用的参数都不尽相同。比如 Blur 这个操作可以选用多种核函数间的一个,每一个取得的概率不同。作者在代码中实际采用的是二阶退化模型。
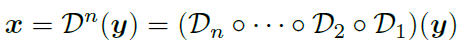
网络结构
Generator:采用 ESRGAN 中的 Generator,即使用 Residual-in-residul Dense Block(RRDB)。
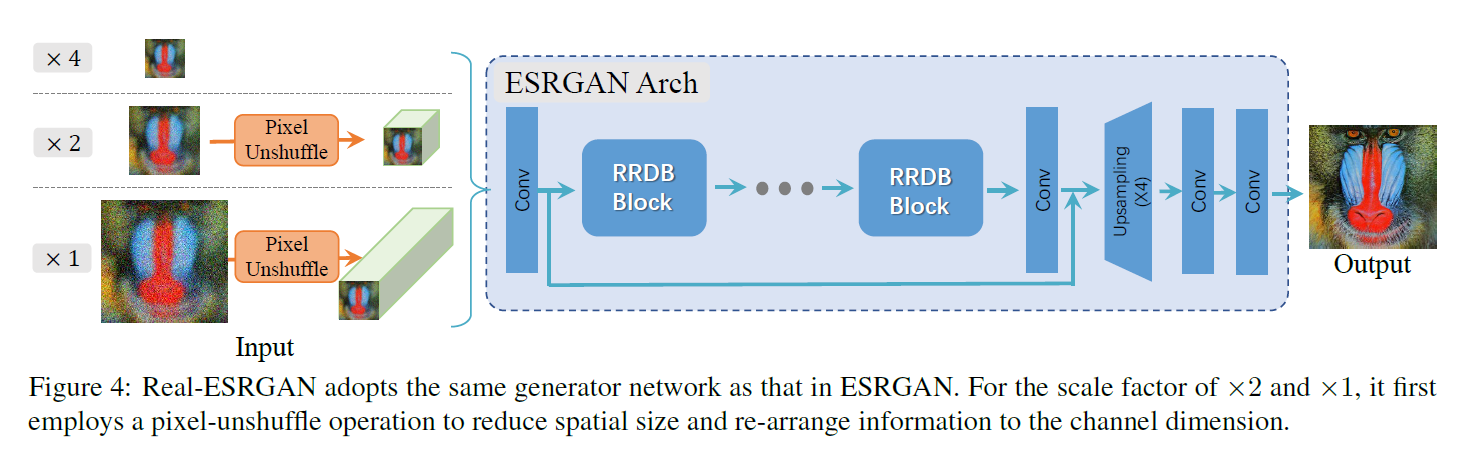
Discriminator:使用有 spectral normalization(SN) 的 U-Net。使用 SN 是为了稳定训练过程,并且使用 SN 有助于缓和 oversharp 和 artifacts。
训练方法
1)预训练一个以 PSNR 为目标的模型,并采用 L1 loss,得到 Real-ESRNet
2)用 Real-ESRNet 初始化 Real-ESRGAN 中的 Generator,然后训练 Real-ESRGAN,采用 L1 loss、perceptual loss 和 GAN loss 三种组合的 loss。
实验效果


