
- 1ubuntu查看 固态硬盘位置_在Ubuntu(Linux)中启用固态硬盘(固态硬盘)TRIM | MOS86...
- 2刚拿到的《HarmonyOS应用开发者高级认证》,全网整理的题目,将近300题,100%通过_鸿蒙 关于video组件的回调事件,下列说法错误的是
- 3传感器概述_传感器 csdn
- 4Unity开发1 Unity简介
- 5Docker相关的概念
- 6MYSQL my.ini 详细配置_my.ini怎么配置
- 7亚马逊云VPC涉及到的知识点有哪些?
- 8chatgpt赋能python:Python遍历指南:掌握5种常用方法实现高效遍历_python遍历循环
- 9指定区间的链表反转问题|力扣leetcode92反转链表2(cpp、Java实现)_链表内指定区间翻转 递归
- 10PyCharm:简化工作与生活,提升生产力的理想工具_pycharm优势
大模型综述_chatglm3-6b是decoder only吗
赞
踩
大模型常识
知识星球 | 深度连接铁杆粉丝,运营高品质社群,知识变现的工具 (zsxq.com)
简介
一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large Language Model,LLM)是针对语言的大模型。
-
175B、60B、540B等:
-
这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
-
-
nB模型推理需要多少显存:
-
考虑模型参数都是fp16,2nG的显存能把模型加载。
-
-
nB模型训练需要多少显存:
-
基础显存:模型参数+梯度+优化器,总共16nG。
-
activation占用显存,和max len、batch size有关
-
优化器部分必须用fp32(似乎fp16会导致训练不稳定)对于常用的 AdamW 来说,需要储存两倍的模型参数(用来储存一阶和二阶momentum)
-
大模型优缺点
优点
-
可以利用大量的无标注数据来训练一个通用的模型,然后再用少量的有标注数据来微调模型,以适应特定的任务。这种预训练和微调的方法可以减少数据标注的成本和时间,提高模型的泛化能力;
-
可以利用生成式人工智能技术来产生新颖和有价值的内容,例如图像、文本、音乐等。这种生成能力可以帮助用户在创意、娱乐、教育等领域获得更好的体验和效果;
-
可以利用涌现能力(Emergent Capabilities)来完成一些之前无法完成或者很难完成的任务,例如数学应用题、常识推理、符号操作等。这种涌现能力可以反映模型的智能水平和推理能力。
缺点
-
需要消耗大量的计算资源和存储资源来训练和运行,这会增加经济和环境的负担。据估计,训练一个GPT-3模型需要消耗约30万美元,并产生约284吨二氧化碳排放;
-
需要面对数据质量和安全性的问题,例如数据偏见、数据泄露、数据滥用等。这些问题可能会导致模型产生不准确或不道德的输出,并影响用户或社会的利益;
-
需要考虑可解释性、可靠性、可持续性等方面的挑战,例如如何理解和控制模型的行为、如何保证模型的正确性和稳定性、如何平衡模型的效益和风险等。这些挑战需要多方面的研究和合作,以确保大模型能够健康地发展。
底层架构类别
-
encoder-only类型的更擅长做分类;
-
encoder-decoder类型的擅长输出强烈依赖输入的,比如翻译和文本总结,尤其擅长处理输入和输出序列之间存在复杂映射关系的任务
-
而其他类型的就用decoder-only,如各种Q&A。虽然encoder-only没有decoder-only类型的流行
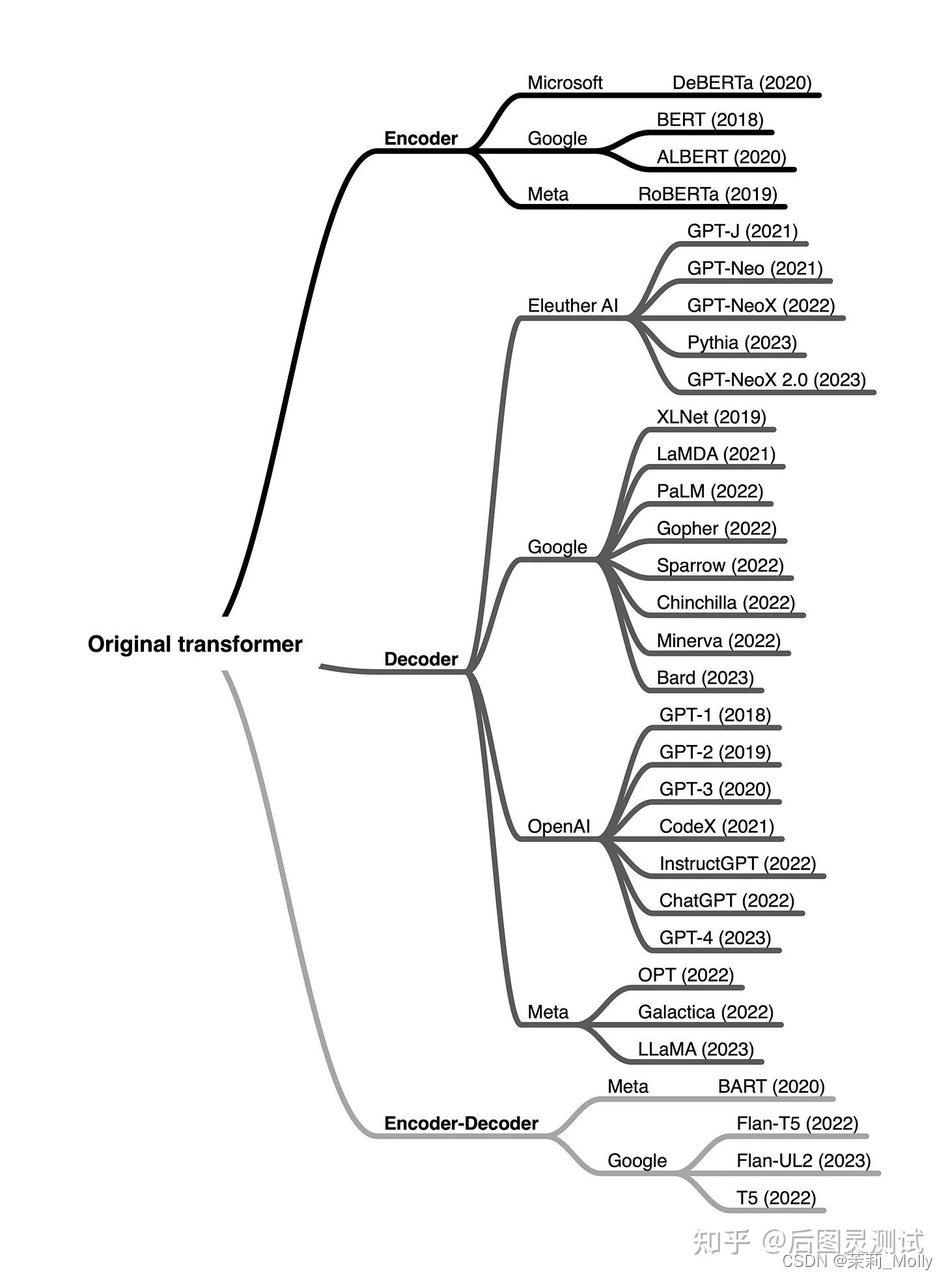
大模型种类
简介
现在为什么那么多人以清华大学的ChatGLM-6B为基座进行试验? - 知乎
目前,开源的大语言模型主要有三大类:
-
LLaMA衍生的大模型(Alpaca、Vicuna、BELLE、Phoenix、Chimera等)
-
Bloom衍生的大模型(Bloomz、BELLE、Phoenix等)。
其中,ChatGLM-6B主要以中英双语进行训练,LLaMA主要以英语为主要语言的拉丁语系进行训练,而Bloom使用了46种自然语言、13种编程语言进行训练。
开源领域 ChatGLM, LLAMA, RWKV 主要就是这3种模型, 中文好一点就是 ChatGLM , 潜力最好的就是LLAMA ,RNN架构决定RWKV有很好的 Length Extrapolation
Chatglm3
介绍:ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
-
更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。
-
更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
-
更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。
Github 代码:GitHub - THUDM/ChatGLM3: ChatGLM3 series: Open Bilingual Chat LLMs | 开源双语对话语言模型
模型架构对比:ChatGLM、ChatGLM2、ChatGLM3模型架构对比
模型地址:
huggingface:https://huggingface.co/THUDM/chatglm3-6b
modelscope:魔搭社区
项目代码:DeepSpeed框架对ChatGLM-6B的流水线并行实战
Baichuan2
介绍:Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。
Baichuan 2 在多个权威的中文、英文和多语言的通用、领域 benchmark 上取得同尺寸最佳的效果。
本次发布包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
Baichuan-7B
Baichuan-13B
介绍:Baichuan-13B是由百川智能继 Baichuan-7B 之后开发的包含 130 亿参数的开源可商用的大规模语言模型,在权威的中文和英文 benchmark 上均取得同尺寸最好的效果。Baichuan-13B 有如下几个特点:
更大尺寸、更多数据:Baichuan-13B 在 Baichuan-7B 的基础上进一步扩大参数量到 130 亿,并且在高质量的语料上训练了 1.4 万亿 tokens,超过 LLaMA-13B 40%,是当前开源 13B 尺寸下训练数据量最多的模型。支持中英双语,使用 ALiBi 位置编码,上下文窗口长度为 4096。
baichuan-inc/Baichuan-13B:GitHub - baichuan-inc/Baichuan-13B: A 13B large language model developed by Baichuan Intelligent Technology
Baichuan-13B 大模型:
官方微调过(指令对齐):https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
预训练大模型(未经过微调):https://huggingface.co/baichuan-inc/Baichuan-13B-Base
Llama2
介绍:全部开源,完全可商用的中文版 Llama2 模型及中英文 SFT 数据集,输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。https://github.com/LinkSoul-AI/Chinese-Llama-2-7b
论文名称:《Llama 2: Open Foundation and Fine-Tuned Chat Models》
论文地址:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Github 代码:GitHub - facebookresearch/llama: Inference code for LLaMA models
模型:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
Qwen1.5
最新版本介绍:https://qwenlm.github.io/blog/qwen1.5/
Qwen大语言模型是由阿里巴巴训练并开源的一系列大语言模型。最早是在2023年8月份开源70亿参数规模,随后几个月时间内陆续开源了4个不同规模版本的模型,最低参数18亿,最高参数720亿。2024年2月份阿里巴巴开源了他们家第二代的Qwen系列大语言模型(准确说是1.5代),从官方给出的测评结果看,Qwen1.5系列大模型相比较第一代有非常明显的进步,其中720亿参数规模版本的Qwen1.5-72B-Chat在各项评测结果中都非常接近GPT-4的模型,在MT-Bench的得分中甚至超过了此前最为神秘但最接近GPT-4水平的Mistral-Medium模型。
在线测试:https://huggingface.co/spaces/Qwen/Qwen1.5-72B-Chat
模型:
MOSS
介绍:MOSS是一个支持中英双语和多种插件的开源对话语言模型,moss-moon系列模型具有160亿参数,在FP16精度下可在单张A100/A800或两张3090显卡运行,在INT4/8精度下可在单张3090显卡运行。MOSS基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
局限性:由于模型参数量较小和自回归生成范式,MOSS仍然可能生成包含事实性错误的误导性回复或包含偏见/歧视的有害内容,请谨慎鉴别和使用MOSS生成的内容,请勿将MOSS生成的有害内容传播至互联网。若产生不良后果,由传播者自负。
Github 代码:https://github.com/OpenLMLab/MOSS
模型:https://huggingface.co/fnlp/moss-moon-003-sft-int4
BLOOMz
介绍:大型语言模型(LLMs)已被证明能够根据一些演示或自然语言指令执行新的任务。虽然这些能力已经导致了广泛的采用,但大多数LLM是由资源丰富的组织开发的,而且经常不对公众开放。作为使这一强大技术民主化的一步,我们提出了BLOOM,一个176B参数的开放性语言模型,它的设计和建立要感谢数百名研究人员的合作。BLOOM是一个仅有解码器的Transformer语言模型,它是在ROOTS语料库上训练出来的,该数据集包括46种自然语言和13种编程语言(共59种)的数百个来源。我们发现,BLOOM在各种基准上取得了有竞争力的性能,在经历了多任务提示的微调后,其结果更加强大。
模型地址:https://huggingface.co/bigscience/bloomz
BELLE
介绍:相比如何做好大语言模型的预训练,BELLE更关注如何在开源预训练大语言模型的基础上,帮助每一个人都能够得到一个属于自己的、效果尽可能好的具有指令表现能力的语言模型,降低大语言模型、特别是中文大语言模型的研究和应用门槛。为此,BELLE项目会持续开放指令训练数据、相关模型、训练代码、应用场景等,也会持续评估不同训练数据、训练算法等对模型表现的影响。BELLE针对中文做了优化,模型调优仅使用由ChatGPT生产的数据(不包含任何其他数据)。
github:GitHub - LianjiaTech/BELLE: BELLE: Be Everyone's Large Language model Engine(开源中文对话大模型)
ChatRWKV
介绍:目前 RWKV 有大量模型,对应各种场景,各种语言,请选择合适的模型:
Raven 模型:适合直接聊天,适合 +i 指令。有很多种语言的版本,看清楚用哪个。适合聊天、完成任务、写代码。可以作为任务去写文稿、大纲、故事、诗歌等等,但文笔不如 testNovel 系列模型。
Novel-ChnEng 模型:中英文小说模型,可以用 +gen 生成世界设定(如果会写 prompt,可以控制下文剧情和人物),可以写科幻奇幻。不适合聊天,不适合 +i 指令。
Novel-Chn 模型:纯中文网文模型,只能用 +gen 续写网文(不能生成世界设定等等),但是写网文写得更好(也更小白文,适合写男频女频)。不适合聊天,不适合 +i 指令。
Novel-ChnEng-ChnPro 模型:将 Novel-ChnEng 在高质量作品微调(名著,科幻,奇幻,古典,翻译,等等)。
模型文件:https://huggingface.co/BlinkDL
大模型微调方式
简介
微调方式分类
-
fine-tune,也叫全参微调,bert微调模型一直用的这种方法,全部参数权重参与更新以适配领域数据,效果好。
-
prompt-tune, 包括p-tuning、lora、prompt-tuning、adaLoRA等delta tuning方法,部分模型参数参与微调,训练快,显存占用少,效果可能跟FT(fine-tune)比会稍有效果损失,但一般效果能打平。
几种参数高效微调方法,主要有如下几类:
-
增加额外参数,如:Prefix Tuning、Prompt Tuning、Adapter Tuning及其变体。
-
选取一部分参数更新,如:BitFit。
-
引入重参数化,如:LoRA、AdaLoRA、QLoRA。
-
混合高效微调,如:MAM Adapter、UniPELT。
prefix-tuning
介绍:与full fine-tuning更新所有参数的方式不同,该方法是在输入token之前构造一段任务相关的virtual tokens作为Prefix,然后训练的时候只更新Prefix部分的参数,而Transformer中的其他部分参数固定。该方法其实和构造Prompt类似,只是Prompt是人为构造的“显式”的提示,并且无法更新参数,而Prefix则是可以学习的“隐式”的提示。 同时,为了防止直接更新Prefix的参数导致训练不稳定的情况,他们在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数。

全调优(顶部)会更新所有Transformers参数(红色Transformer框),并需要为每个任务存储一个完整的模型副本。前缀调优(底部)冻结Transformer参数,只优化前缀(红色的前缀块)。
因此,只需要为每个任务存储前缀,使前缀调优模块化并节省空间。
思路
-
step 1Prefix构建。在输入token之前构造一段任务相关的virtual tokens作为Prefix;
-
step 2训练时只更新Prefix部分的参数,而Transformer中的其他部分参数固定;
-
step 3在Prefix层前面加了MLP结构(相当于将Prefix分解为更小维度的Input与MLP的组合后输出的结果),训练完成后,只保留Prefix的参数;(用于 防止直接更新Prefix的参数导致训练不稳定的情况)
prompt-tuning
介绍:Prompt-tuning 给每个任务定义了自己的 Prompt,拼接到数据上作为输入,同时 freeze 预训练模型进行训练
该方法可以看作是Prefix Tuning的简化版本,只在输入层加入prompt tokens,并不需要加入MLP进行调整来解决难训练的问题。随着预训练模型参数量的增加,Prompt Tuning的方法会逼近fine-tuning的结果。
思路
-
将 prompt 扩展到连续空间,仅在 输入层 添加 prompt连续向量,通过反向传播更新参数来学习prompts,而不是人工设计prompts;
-
冻结模型原始权重,只训练prompts参数,训练完成后,只用同一个模型可以做多任务推理;
-
使用 LSTM 建模 prompt 向量间 关联性
P-tuning
介绍:该方法的提出主要是为了解决这样一个问题:大模型的Prompt构造方式严重影响下游任务的效果。P-Tuning将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对prompt embedding进行一层处理。
思路
-
可学习的 Embedding层 设计。将 Prompt 转换为 可学习 Embedding层;
-
prompt encoder设计。用 prompt encoder(由一个双向的LSTM+两层MLP组成) 的方式来对Prompt Embedding进行一层处理,建模伪token的相互依赖,并且可以提供一个更好的初始化。
P-Tuning v2
介绍:让Prompt Tuning能够在不同参数规模的预训练模型、针对不同下游任务的结果上都达到匹敌Fine-tuning的结果。相比Prompt Tuning和P-tuning的方法,P-Tuning v2方法在多层加入了Prompts tokens作为输入,带来两个方面的好处:
-
带来更多可学习的参数(从P-tuning和Prompt Tuning的0.1%增加到0.1%-3%),同时也足够参数高效。
-
加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
思路
-
Deep Prompt Encoding:采用 Prefix-tuning 的做法,在输入前面的每层加入可微调的 Prompts tokens作为输入;
-
移除了重参数化的编码器(prefix-tuning中可选的MLP、p-tuning中的LSTM):prefix-tuning 和 p-tuning,通过利用重参数化功能来提高训练速度和鲁棒性,但是 该方法对于较小的模型,同时还会影响模型的表现;
-
针对不同任务采用不同的提示长度。提示长度在提示优化方法的超参数搜索中起着核心作用。在实验中,发现不同的理解任务通常用不同的提示长度来实现其最佳性能,这与Prefix-Tuning中的发现一致,不同的文本生成任务可能有不同的最佳提示长度;
-
引入多任务学习,先在多任务的prompt上进行预训练,然后再适配下游任务;
-
连续提示的随机惯性给优化带来了困难,这可以通过更多的训练数据或与任务相关的无监督预训练来缓解;
-
连续提示是跨任务和数据集的特定任务知识的完美载体;
-
抛弃了prompt learing中常用的verbalizer,回归到传统的CLS和token label分类范式。标签词映射器(Label Word Verbalizer)一直是提示优化的核心组成部分,它将one-hot类标签变成有意义的词,以利用预训练语言模型头。尽管它在few-shot设置中具有潜在的必要性,但在全数据监督设置中,Verbalizer并不是必须的。它阻碍了提示调优在我们需要无实际意义的标签和句子嵌入的场景中的应用。因此,P-Tuning v2回归传统的CLS标签分类范式,采用随机初始化的分类头(Classification Head)应用于tokens之上,以增强通用性,可以适配到序列标注任务。
Adapter
介绍:该方法设计了Adapter结构(首先是一个down-project层将高维度特征映射到低维特征,然后过一个非线形层之后,再用一个up-project结构将低维特征映射回原来的高维特征;同时也设计了skip-connection结构,确保了在最差的情况下能够退化为identity),并将其嵌入Transformer的结构里面,在训练时,固定住原来预训练模型的参数不变,只对新增的Adapter结构进行微调。同时为了保证训练的高效性(也就是尽可能少的引入更多参数)。

在预训练模型每一层(或某些层)中添加 Adapter 模块(如上图左侧结构所示),微调时冻结预训练模型主体,由 Adapter 模块学习特定下游任务的知识。每个 Adapter 模块由两个前馈子层组成,第一个前馈子层将 Transformer 块的输出作为输入,将原始输入维度 d 投影到 m,通过控制 m 的大小来限制 Adapter 模块的参数量
问题:通过在Transformer层中嵌入Adapter结构,在推理时会额外增加推理时长。
几个变体:
-
AdapterFusion
思路:一种融合多任务信息的Adapter的变体,在 Adapter 的基础上进行优化,通过将学习过程分为两阶段来提升下游任务表现。
-
AdapterDrop
思路:在不影响任务性能的情况下,对Adapter动态高效的移除,尽可能的减少模型的参数量,提高模型在反向传播(训练)和正向传播(推理)时的效率。
-
AdapterDrop
思路:通过从较低的 Transformer 层删除可变数量的Adaper来提升推理速度;
当对多个任务执行推理时,动态地减少了运行时的计算开销,并在很大程度上保持了任务性能。
-
MAM Adapter
思路:一种在 Adapter、Prefix Tuning 和 LoRA 之间建立联系的统一方法。最终的模型 MAM Adapter 是用于 FFN 的并行 Adapter 和 软提示的组合。
lora
介绍:模型是过参数化的,它们有更小的内在维度,模型主要依赖于这个低的内在维度(low intrinsic dimension)去做任务适配。假设模型在任务适配过程中权重的改变量是低秩(low rank)的,由此提出低秩自适应(LoRA)方法,LoRA 允许我们通过优化适应过程中密集层变化的秩分解矩阵来间接训练神经网络中的一些密集层,同时保持预先训练的权重不变。
LoRA 的实现思想很简单,如下图所示,就是冻结一个预训练模型的矩阵参数,并选择用 A 和 B 矩阵来替代,在下游任务时只更新 A 和 B。

思路:
-
在原模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量;
-
训练时,原模型固定,只训练降维矩阵A和升维矩阵B;
-
推理时,可将BA加到原参数上,不引入额外的推理延迟;
-
初始化,A采用高斯分布初始化,B初始化为全0,保证训练开始时旁路为0矩阵;
-
可插拔式的切换任务,当前任务W0+B1A1,将lora部分减掉,换成B2A2,即可实现任务切换;
应用教程:LLM PEFT——使用LoRA做fine-tuning
Qlora
介绍:QLoRA本身讲的是模型本身用4bit加载,训练时把数值反量化到bf16后进行训练,利用LoRA([2])可以锁定原模型参数不参与训练,只训练少量LoRA参数的特性使得训练所需的显存大大减少。
思路:
-
使用一种新颖的高精度技术将预训练模型量化为 4 bit;
-
然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
AdaLoRA
介绍:因为在一个模型中,不同模块拥有着不同的贡献,那么在使用LoRA时如果我们能够根据它们重要性的不同为不同的模块分配不同的秩,那么将会带来很多好处。首先,我们为重要性更低的模块分配更小的秩,那么将有效的减少模型的计算量。其次,如果我们能够为更重要的特征分配更大的秩,那么将能够更有效的捕捉特征的细节信息。这也就是AdaLoRA的提出动机。
思路:AdaLoRA 对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵,将关键的增量矩阵分配高秩以捕捉更精细和任务特定的信息,而将较不重要的矩阵的秩降低,以防止过拟合并节省计算预算。
Freeze
仅微调后几层的全连接层。
RLHF
ChatGPT需要有大致三个阶段的训练过程:
-
Pretraining: 在大规模“无监督”的语料上训练,训练任务是预测下一个词。
-
Supervised Fine-Tuning(SFT):在人类标注上进行微调,所谓人类标注就是人类写Prompt,人类写答案。然后语言模型学习模仿人类是如何作答的。这部分通常要求数据集多样性很好,也因为标注成本很高,通常量级很小。
-
Reinforcement Learning with human feedback(RLHF):对于同一个Prompt把模型的多个输出给人类排序,获取人类偏好标注。用人类的偏好标注,训练一个reward model。训练得到的reward model会作为PPO算法中的reawrd function,来继续优化SFT得到的模型。
RLHF这一步训练,实则包含两步训练:
-
训练Reward Model(RM);
-
用Reward Model和SFT Model构造Reward Function,基于PPO算法来训练LLM。
大模型训练加速方法
分布式并行技术
-
数据并行(如:PyTorch DDP)
-
模型/张量并行(如:Megatron-LM(1D)、Colossal-AI(2D、2.5D、3D))
-
流水线并行(如:GPipe、PipeDream、PipeDream-2BW、PipeDream Flush(1F1B))
-
多维混合并行(如:3D并行(数据并行、模型并行、流水线并行))
-
自动并行(如:Alpa(自动算子内/算子间并行))
-
优化器相关的并行(如:ZeRO(零冗余优化器,在执行的逻辑上是数据并行,但可以达到模型并行的显存优化效果)、PyTorch FSDP)
数据并行DP
将整个数据集切分为多份,每张GPU分配到不同的数据进行训练,每个进程都有一个完整的模型副本。
介绍:假设有N张卡,每张卡都保存一个模型,每一次迭代(iteration/step)都将batch数据分割成N个等大小的micro-batch,每张卡根据拿到的micro-batch数据独立计算梯度,然后调用AllReduce计算梯度均值,每张卡再独立进行参数更新。
流水线并行PP
模型层间划分,将不同的层划分到不同的GPU上
介绍:模型在多个 GPU 上垂直(层级)拆分,因此只有模型的一个或多个层放置在单个 GPU 上。每个 GPU 并行处理管道的不同阶段,并处理一小部分批处理。
张量并行TP
层内划分,切分一个独立的层划分到不同的GPU上
介绍:每个张量都被分成多个块,因此不是让整个张量驻留在单个 GPU 上,而是张量的每个分片都驻留在其指定的 GPU 上。在处理过程中,每个分片在不同的 GPU 上分别并行处理,最终结果在步骤结束时同步。这也被称作横向并行。
3D并行
DP+TP+PP,这就是3D并行。
ZeRO
针对模型状态的存储优化(去除冗余),ZeRO使用的方法是分片,即每张卡只存 1/N的模型状态量,这样系统内只维护一份模型状态。
ZeRO 具有三个主要的优化阶段(ZeRO-1,ZeRO-2,ZeRO-3),它们对应于优化器状态(optimizer states)、梯度(gradients)和参数(parameters)的分片。累积启用时:
-
优化器状态分区 (Pos) – 内存减少 4 倍,通信量与数据并行性相同
-
添加梯度分区 (Pos+g) – 内存减少 8 倍,通信量与数据并行性相同
-
添加参数分区 (Pos+g+p) – 内存减少与数据并行度 Nd 成线性关系。例如,拆分为 64 个 GPU ( Nd =64) 内存将减少到 1/64 。GPU 通信量略有增加 50%
AMP混合精度
分布式训练框架
如何选择一款分布式训练框架
-
训练成本:不同的训练工具,训练同样的大模型,成本是不一样的。对于大模型,训练一次动辄上百万/千万美元的费用。合适的成本始终是正确的选择。
-
训练类型:是否支持数据并行、张量并行、流水线并行、多维混合并行、自动并行等
-
效率:将普通模型训练代码变为分布式训练所需编写代码的行数,我们希望越少越好。
-
灵活性:你选择的框架是否可以跨不同平台使用?
常见的分布式训练框架
-
第一类:深度学习框架自带的分布式训练功能。如:TensorFlow、PyTorch、MindSpore、Oneflow、PaddlePaddle等。
-
第二类:基于现有的深度学习框架(如:PyTorch、Flax)进行扩展和优化,从而进行分布式训练。如:Megatron-LM(张量并行)、DeepSpeed(Zero-DP)、Colossal-AI(高维模型并行,如2D、2.5D、3D)、Alpa(自动并行)等
Accelerate
PyTorch Accelerate 提供了一组简单易用的 API,帮助开发者实现模型的分布式训练、混合精度训练、自动调参、数据加载优化和模型优化等功能。它还集成了 PyTorch Lightning 和 TorchElastic,使用户能够轻松地实现高性能和高可扩展性的模型训练和推断。
PyTorch Accelerate 的主要优势包括:
-
分布式训练:可以在多个 GPU 或多台机器上并行训练模型,从而缩短训练时间和提高模型性能;
-
混合精度训练:可以使用半精度浮点数加速模型训练,从而减少 GPU 内存使用和提高训练速度;
-
自动调参:可以使用 PyTorch Lightning Trainer 来自动调整超参数,从而提高模型性能;
-
数据加载优化:可以使用 DataLoader 和 DataLoaderTransforms 来优化数据加载速度,从而减少训练时间;
-
模型优化:可以使用 Apex 或 TorchScript 等工具来优化模型性能。
gitbub:https://github.com/huggingface/accelerate
Megatron-LM
gitbub:https://github.com/huggingface/accelerate
DeepSpeed
其他框架相比,DeepSpeed支持更大规模的模型和提供更多的优化策略和工具。其中,主要优势在于支持更大规模的模型、提供了更多的优化策略和工具(例如 ZeRO 和 Offload 等)
-
用 3D 并行化实现万亿参数模型训练。DeepSpeed 实现了三种并行方法的灵活组合:ZeRO 支持的数据并行,流水线并行和张量切片模型并行。3D 并行性适应了不同工作负载的需求,以支持具有万亿参数的超大型模型,同时实现了近乎完美的显存扩展性和吞吐量扩展效率。此外,其提高的通信效率使用户可以在网络带宽有限的常规群集上以 2-7 倍的速度训练有数十亿参数的模型。
-
ZeRO(Zero Redundancy Optimizer)是一种用于大规模训练优化的技术,主要是用来减少内存占用。ZeRO 将模型参数分成了三个部分:Optimizer States、Gradient 和 Model Parameter。在使用 ZeRO 进行分布式训练时,可以选择 ZeRO-Offload 和 ZeRO-Stage3 等不同的优化技术。
-
混合精度训练是指在训练过程中同时使用FP16(半精度浮点数)和FP32(单精度浮点数)两种精度的技术。使用FP16可以大大减少内存占用,从而可以训练更大规模的模型。在使用混合精度训练时,需要使用一些技术来解决可能出现的梯度消失和模型不稳定的问题,例如动态精度缩放和混合精度优化器等。
-
结合使用huggingface和deepspeed
github:https://github.com/huggingface/accelerate
大模型推理加速方法
llm框架适用概览

Text-Generation-Inference
Text Generation Inference源码解读(一):架构设计与业务逻辑
Faster Transformer
英伟达推出的FasterTransformer不修改模型架构而是在计算加速层面优化 Transformer 的 encoder 和 decoder 模块。具体包括如下:
-
尽可能多地融合除了 GEMM 以外的操作
-
支持 FP16、INT8、FP8
-
移除 encoder 输入中无用的 padding 来减少计算开销
TurboTransformers
微信TurboTransformers—变长输入任务的Inference优化
腾讯推出的 TurboTransformers 由 computation runtime 及 serving framework 组成。加速推理框架适用于 CPU 和 GPU,最重要的是,它可以无需预处理便可处理变长的输入序列。具体包括如下:
-
与 FasterTransformer 类似,它融合了除 GEMM 之外的操作以减少计算量
-
smart batching,对于一个 batch 内不同长度的序列,它也最小化了 zero-padding 开销
-
对 LayerNorm 和 Softmax 进行批处理,使它们更适合并行计算
-
引入了模型感知分配器,以确保在可变长度请求服务期间内存占用较小
PagedAttention
[nlp] vllm: page attention 加速优化
PagedAttention是vLLM的核心技术
与传统的注意力算法不同,PagedAttention 允许在不连续的内存空间中存储连续的key和value。
PagedAttention 如何存储 连续的key和value?
具体来说,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量token的key和value。在注意力计算过程中,PagedAttention 内核有效地识别并获取这些块。
vLLM
有人使用vLLM加速过自己的大语言模型吗?效果怎么样? - 知乎
vLLM 用于大模型并行推理加速,其中核心改进是PagedAttention算法,在 vLLM 中,我们发现 LLM 服务的性能受到内存的瓶颈。在自回归解码过程中,LLM 的所有输入标记都会生成其key和value张量,并且这些张量保存在 GPU 内存中以生成下一个token。这些缓存的key和value张量通常称为 KV 缓存。KV缓存是:
占用大: LLaMA-13B 中的单个序列最多占用 1.7GB。
动态变化:其大小取决于序列长度,序列长度变化很大且不可预测。因此,有效管理 KV 缓存提出了重大挑战。我们发现现有系统由于碎片和过度预留而浪费了60% - 80%的内存。
swift框架:https://github.com/modelscope/swift/blob/main/docs/source/LLM/VLLM%E6%8E%A8%E7%90%86%E5%8A%A0%E9%80%9F%E4%B8%8E%E9%83%A8%E7%BD%B2.md
langchain框架:https://python.langchain.com/docs/integrations/llms/vllm
LightLLM
LightLLM引入了一种更细粒度的kv cache管理算法 TokenAttention,并设计了一个与TokenAttention高效配合的Efficient Router调度实现。在TokenAttention 和 Efficient Router的相互作用下,LightLLM在大部分场景下都能获得比vLLM 和 Text Generation Inference 得到更高的吞吐,部分场景下可以得到4倍左右的性能提升。
一套基于纯Python语言的大模型推理部署框架LightLLM,方便研究员进行轻量级的本地部署和定制修改,用于快速扩展对不同模型的支持,吸纳层出不穷的优秀开源特性,探索最优服务架构。LightLLM的核心feature如下:
-
三进程架构。主要用于异步化处理 tokenize 和 detokenize操作, 可以避免这些耗时的cpu处理阻碍模型推理时gpu的调度执行,降低gpu的使用率,进而降低了整体服务性能。
-
Token Attention。一种以Token为粒度进行kv cache 显存管理的特性,并实现了高性能的管理方法。
-
Efficient Router。配合 Token Attention 用于精确的管理调度请求的合并推理。
配合基于OpenAI Triton 开发的与服务调度高度配合的高效算子,LightLLM实现了优秀的吞吐性能。
目前支持模型:
BLOOM:https://huggingface.co/bigscience/bloom
LLaMA:GitHub - facebookresearch/llama: Inference code for LLaMA models
LLaMA V2:https://huggingface.co/meta-llama
github:GitHub - ModelTC/lightllm: LightLLM is a Python-based LLM (Large Language Model) inference and servi
代码解读:lightllm代码解读——之模型推理
OpenLLM
github:https://github.com/bentoml/OpenLLM
TensorRT-LLM
github:https://github.com/NVIDIA/TensorRT-LLM

