- 1uniapp 总结篇 (小程序)_uniapp开发小程序
- 2chatgpt赋能python:用Python画龙:SEO技巧大放送_用python画一条龙
- 3!!!亲测成功:langchain+ChatGLM 大模型部署_chatglm3 如何langchain结合
- 4tf.data.Dataset.map()函数的理解
- 5基于yolov5的目标检测-停车位检测、低矮障碍物、地面标识检测等_yolo算法准确识别车辆,车位划线
- 6微信小程序接入直播_微信小程序如何对接直播
- 7基于本地知识库的大模型搭建教程_python 个人知识库搭建
- 8Gradle下载以及安装教程_gradle-5.5.1-bin.zip
- 9C++异步变化:libunifex实现!
- 10面试知识点梳理及相关面试题(三) -- springcloud_springcloudalibaba面试题
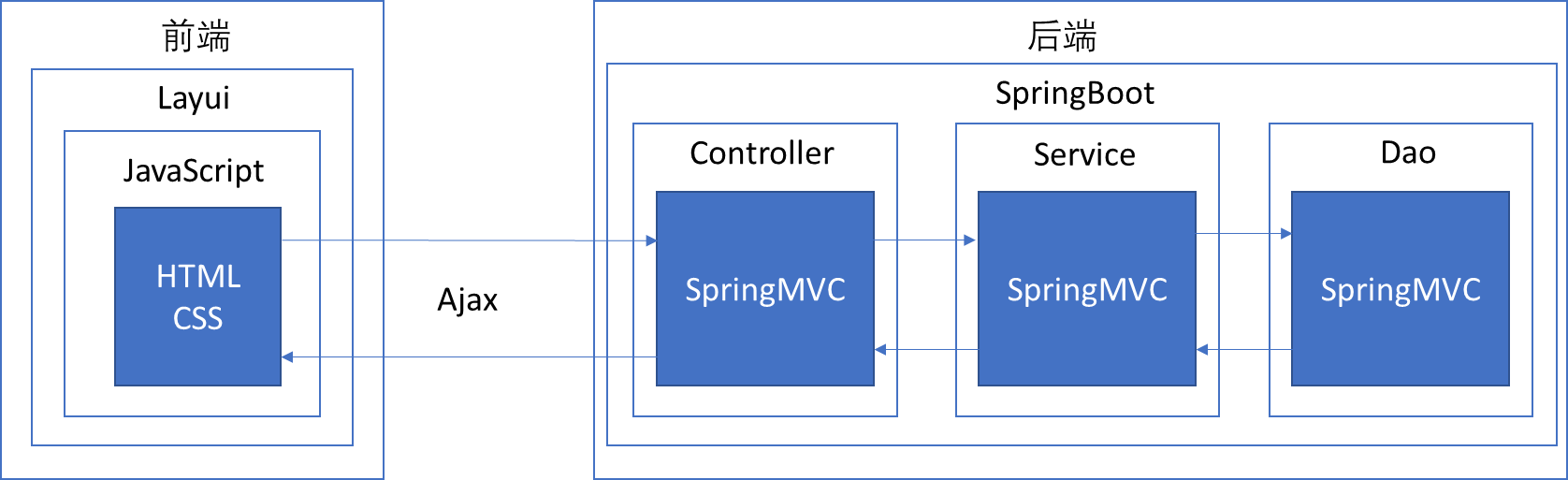
毕业设计:舆情监测系统(SpringBoot+NLP)_springboot nlp
赞
踩
【问题】项目的主要模块?
【答案】
数据采集模块:这个模块负责从各种渠道(例如社交媒体、新闻网站、论坛等)收集原始数据。该模块需要支持对多种数据源进行爬取,并对不同类型的数据进行整合和转换。同时,还需要考虑数据存储和过滤的问题。
数据预处理模块:在原始数据采集之后,数据往往需要进行清洗、过滤、去重、标准化等预处理操作。该模块需要支持将原始数据转化为可供后续模块处理的格式,并且在处理过程中需要保证数据的质量和准确性。
分词与特征提取模块:该模块负责对预处理后的数据进行分词,并提取相应的特征。这些特征可以包括文本中的关键词、情感词汇、句法分析、主题模型等。这些特征将被用作后续的分析和建模。
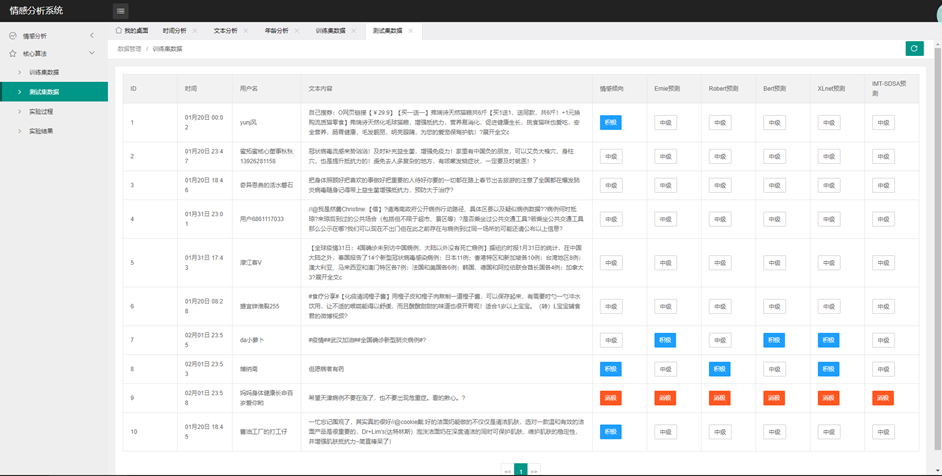
情感分析模块:情感分析模块使用机器学习算法和自然语言处理技术,对数据进行情感分析。该模块可以分为两个子模块:模型训练和测试、情感分类预测。
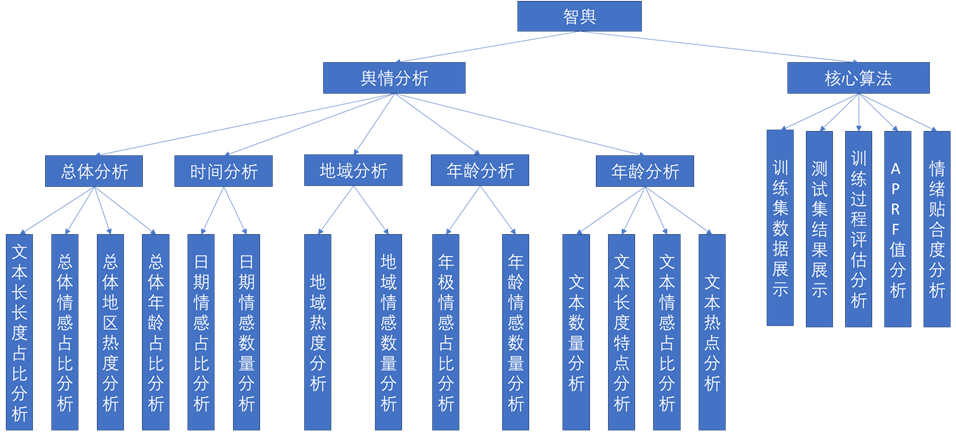
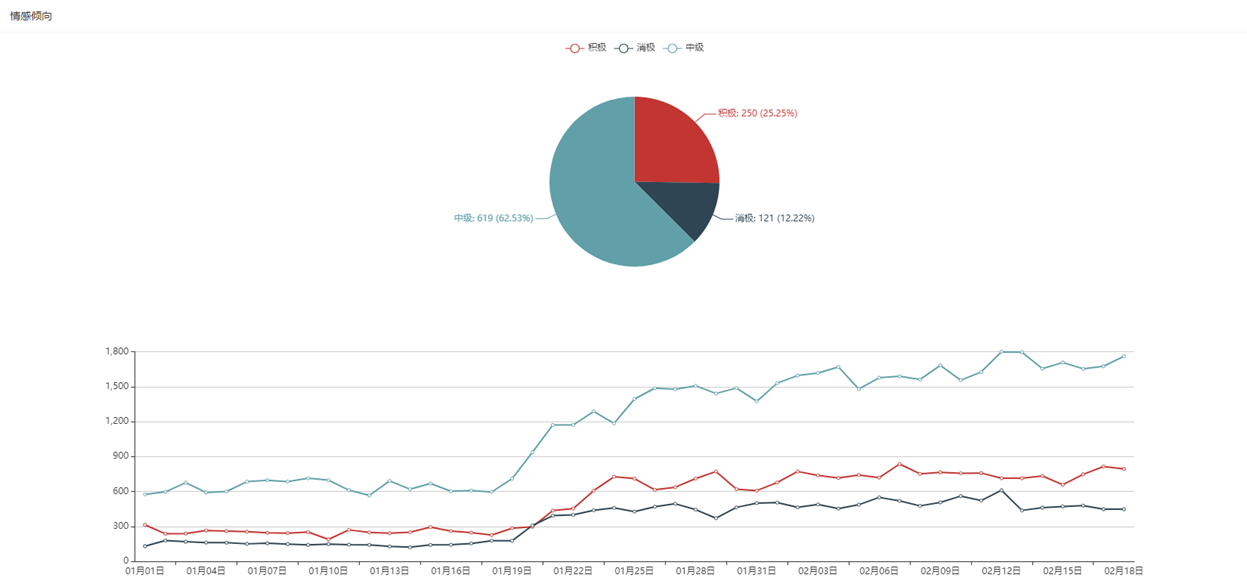
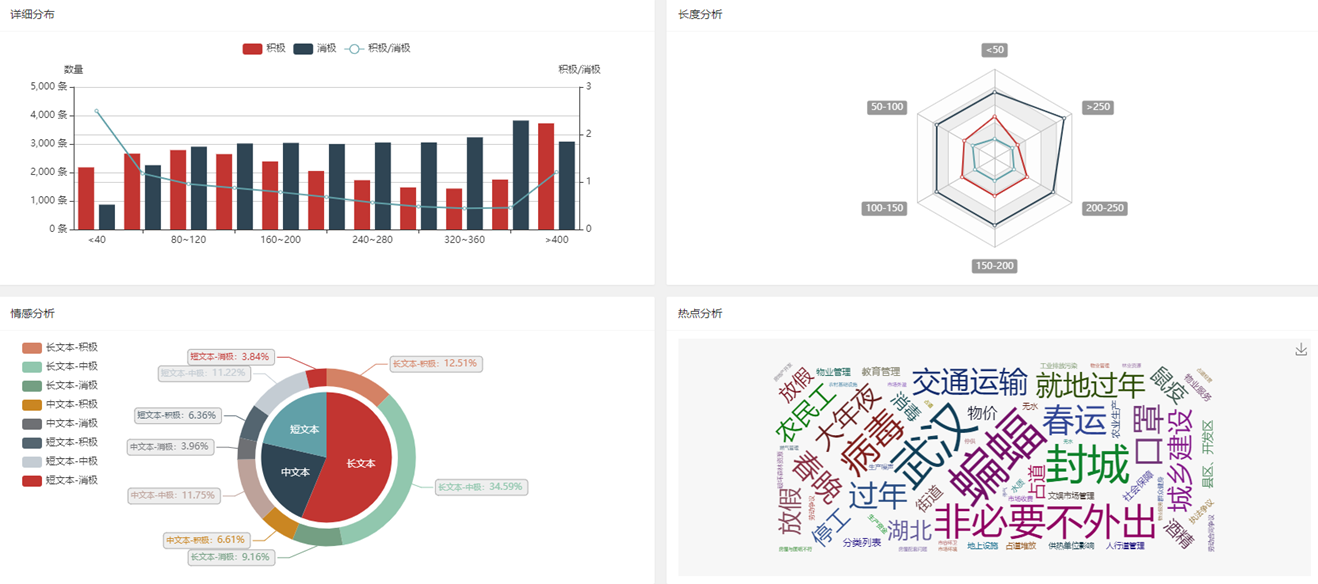
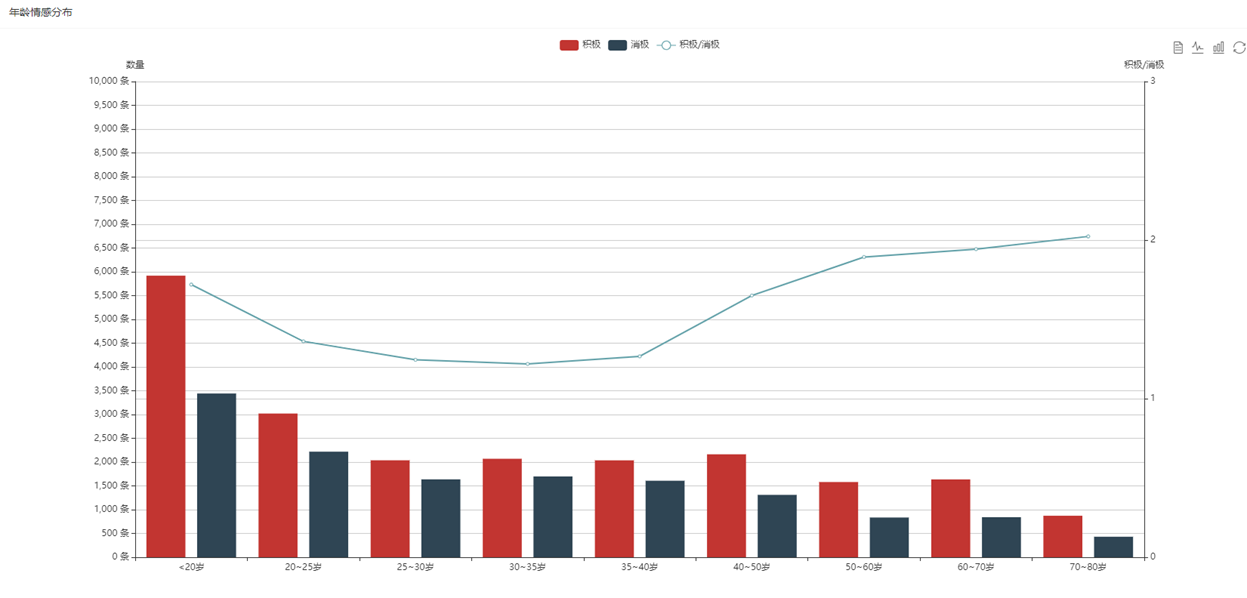
可视化展示模块:可视化展示模块将情感分析结果以图表、表格等形式展现出来,为用户提供更直观的分析结果。此外,该模块还需要支持数据查询、筛选、导出等功能。
用户管理和安全模块:在情感分析系统中,需要实现用户管理和安全模块,包括用户注册登录、权限管理、HTTPS 加密等功能。
商品模块:针对会员设置不同的API套餐。
1,项目简介
2019新冠肺炎疫情的爆发对人们日常生活、社会经济发展和国家安定的各个方面都产生了严重的影响,并且迅速引起国内大量网民的关注,众多网民在网络上利用社交软件发表个人想法和理解。为了科学有效地帮助各级政府及时掌握网络舆论信息和网民情感倾向情况,本文提出一种新型中文文本情绪分类模式设计方法和一种中文舆情监测系统的设计和实现方法,通过这种模型和系统能够有效的发现舆情演变规律和潜在风险,提高政府的舆论应对能力,进而推动政府治理能力的现代化,助力于社会和经济的发展。
本文所做的贡献包括:
(1)提出一种交互式多任务学习模型,将情感词典扩展和情感分类两个任务组合在一起,以新冠肺炎背景的微博文本为语料库,验证了该模型的优越性能,为网络舆情监控提供基础。
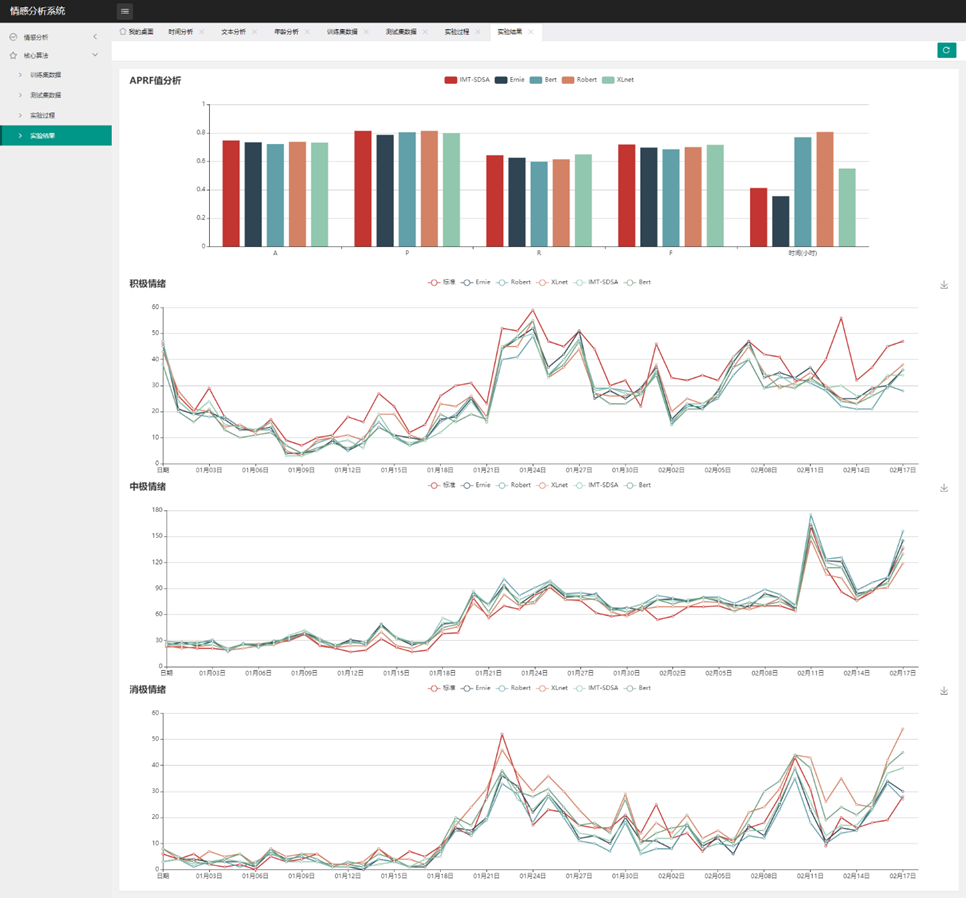
(2)引入多任务学习网络的信息交互机制,最大化任务之间的交互作用,并通过实验证明该信息交互机制在进行中文文本情感分类时可以显著提高模型性能。
(3)设计开发一款网络舆情监控系统,利用微博文本数据和提出的交互式多任务学习模型,对互联网中文本数据信息进行情感预测、监控和分析。
(4)验证了IMT-SDSA模型在中文文本情感分类时相较于其他情感分类模型如Bert, Roberta,XLnet,ERINE的优越性。