
- 1ChatGLM3的部署(windows版)_glm3 half quantize(4)
- 2【工具使用】Keil5软件使用-基础使用篇_keil uvision5使用教程
- 3Vue——项目部署到非根目录下的解决方案_vue2发布h5不配置到跟目录
- 4USB 2.0 与USB EHCI 硬件接口_usb port change
- 5抹机王怎么一键新机_ir新机工具箱手机版下载-ir新机抹机王盒子v5.6.6 免登陆版-007游戏网...
- 6MySQL锁分析读已提交级别下的锁分析_mysql 读已提交 读锁分表锁吗
- 7TFLOPS意思_tflops和p flops
- 8已解决java.lang.IllegalStateException异常的正确解决方法,亲测有效!!!_java.lang.illegalstateexception: endpostable alrea
- 9为什么要进行MicroPython到OpenHarmony的移植工作_micropython移植到openharmony
- 10皮肤电数据简介及预处理指南_皮肤电信号处理
Hive详解(1)_hive datetime数据类型
赞
踩
1 数据表操作
创建表
语法:
CREATE [EXTERNAL] TABLE [IF NOT NULL] table_name(
col_name data_type [COMMENNT ‘字段注释’],
…)]
PARTITION BY (col_name data_type [COMMENNT ‘字段注释’],…)]
CLUSTERED BY (col_name,col_name,…)]
[SORTED BY (col_name [ASC|DESC],…)] INTO num_buckers BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
EXTERNAL,创建外部表
PARTITIONED BY, 分区表
CLUSTERED BY,分桶表
STORED AS,存储格式
LOCATION,存储位置
常用的数据类型
简单数据类型:一个字段值代表一个数据含义
整型: int , bigint
浮点型: double
字符串类型: string char
string:变长数据类型,也就是我们存储多少数据,就占用多少空间(最大2G),该类型是沿用的java数据类型
char:固定长度数据类型,也就是我们存储多少数据,都只占用指定的空间,如果数据过大则会造成数据丢失
日期类型: tiemstamp date
布尔值: boolean
注意: 在hive当中没有datetime类型,如果要使用datetime类型需要使用timestamp类型转换
和mysql数据类型的不同:
- 增加了很多java中的数据类型以及复杂数据类型
- 在hive中没有datetime类型
- 在hive中一般不会因为数据类型占用空间问题而改变数据类型的选择
复杂数据类型:一个字段值包含多个数据元素,代表多个数据含义
array 数组类型:array:[0,1,2,3,4]
存储的是 多个同类型的单独的数据元素
array<int>
可以使用[元素索引]de形式调用该字段中的元素 例如address[2]
map 双列集合类型:map:{“height”:186,“weight”:65}
存储的是多个数据类型相同的键值对元素
map<string,int>
可以通过[键] 获取值 例如:member['sister']注意: 仅可以通过键获取值
map中键是唯一的{"height": 186, "height": 65}不行{"height": 186, "wight": 186}可以
struct 结构体类型:struct:{“name”:‘小明’,‘age’:18}
和map类型基本相同 但是其每个键值对的数据类型均可以不相同
在开发中struct中的键使我们手动复制的map中的键是数据
hive的SerDe机制:
- 就是hive获取数据时的序列化和反序列化机制,也可以说是hive映射数据和写入数据的规则
- 定义字段间的分隔符就属于serDe机制
- hive默认的serde机制是delimited, lazysimpleSerDe包含以下功能

hive中的元数据存储在mysql数据库中,hive映射的表中的数据记录存储在hdfs中
hive 映射表的过程:
- 客户端直接访问metastore或者通过hiveserver2访问metastore,获取需要的表的元数据信息
- 库名,表名,字段名称,字段类型,分隔符,映射数据所在的位置…(统称为元数据)
- 在内存中构建一个表对象(理解为在内存中搭建了一张虚拟的表,但是这张表是一个空表)
- 从hdfs中读取数据,根据元数据中提供的存储格式,压缩格式分隔符等奖每一个字段拆分开读取到内存中
- 将读取到的数据信息,按照字段顺序填充到虚拟表中
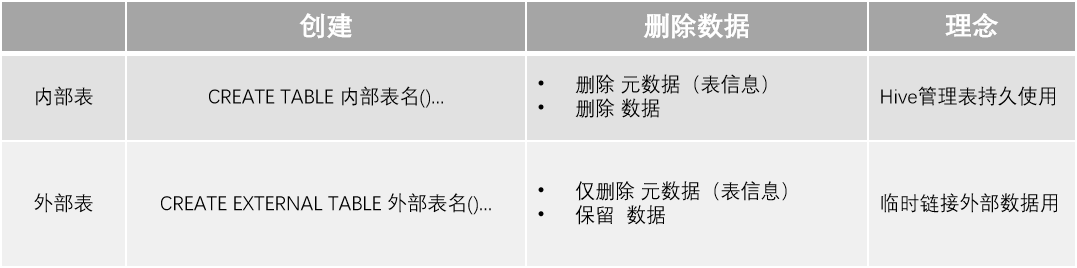
2 内部表与外部表
内部表
格式:CREATE TABLE table_name ......
未被external关键字修饰的即是内部表, 即普通表。 内部表又称管理表
删除内部表:直接删除元数据(metadata)及存储数据
-- 创建内部表
create database if not exists hive_day02;
create table if not exists hive_day02.stu_neibu(
id int,
name string
)
row format delimited fields terminated by '\t'; --表中数据默认分隔符为tab键
- 1
- 2
- 3
- 4
- 5
- 6
- 7
表数据准备,查看本地虚拟机上的a.txt文件
[root@node1 ~]# cat a.txt
1 张三
2 李四
3 王五
4 小明
5 小红
[root@node1 ~]# pwd
/root
您在 /var/spool/mail/root 中有新邮件
[root@node1 ~]#
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
-- 将本地/root/目录下a.txt文件数据加载到表中
load data local inpath '/root/a.txt' into table hive_day02.stu_neibu;
-- 查询表数据
select * from stu_neibu;
- 1
- 2
- 3
- 4
数据库中查看数据
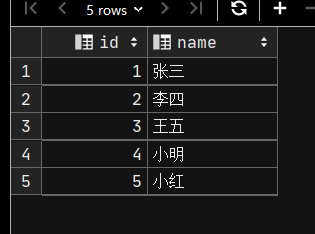
HDFS中查看
-- 清空内部表
truncate table hive_day02.stu_man;
-- 删除内部表,数据一概被删除
drop table hive_day02.stu_neibu;
-- 查询内部表数据
select * from hive_day02.stu_neibu;
- 1
- 2
- 3
- 4
- 5
- 6
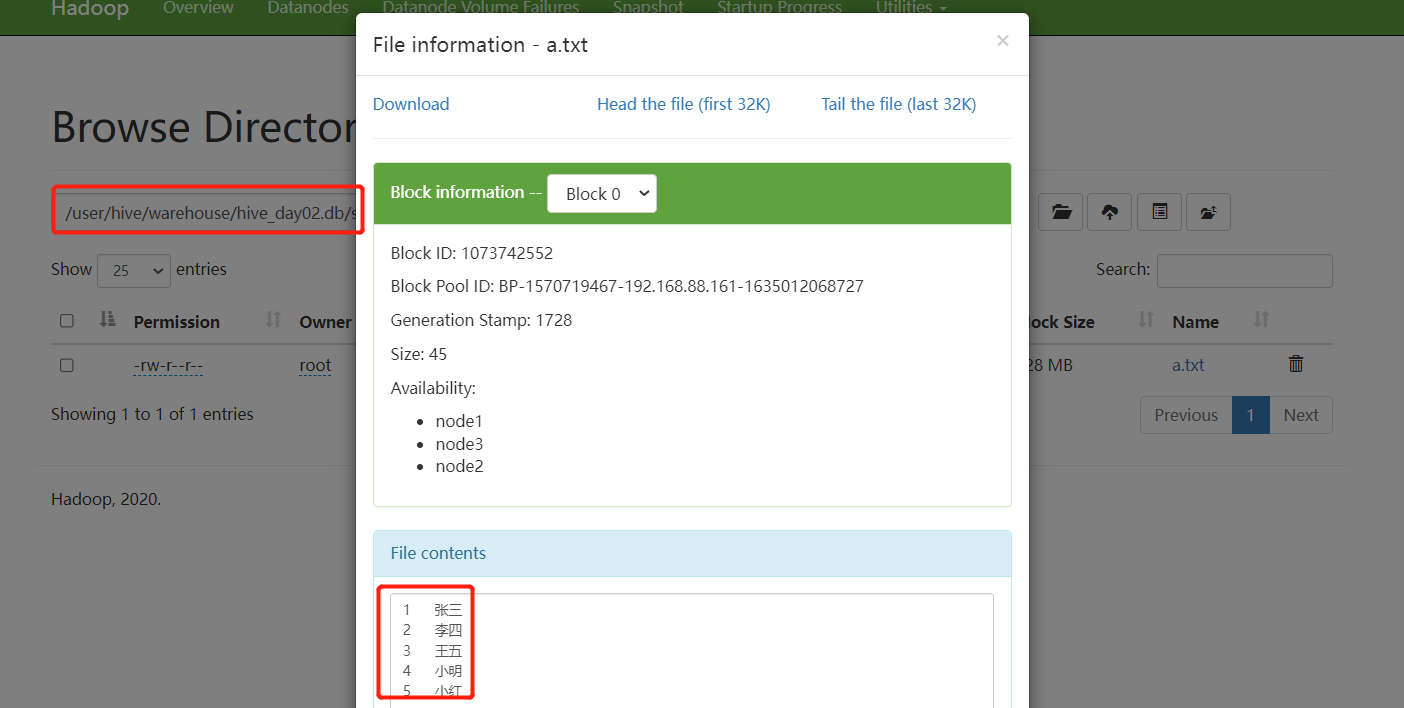
提示:org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:14 Table not found 'stu_neibu'
该表不存在,已被删除
HDFS中查看该表数据也被删除了
外部表
格式:CREATE EXTERNAL TABLE table_name ......LOCATION......
被external关键字修饰的即是外部表, 即关联表。
什么场景下使用内部表,什么场景下使用外部表:
如果数据获取难度大,且数据的重要性高,我们一般使用外部表,放置意外删除导致数据丢失
同一个数据被多个用户或者表所绑定,此时我们也会使用外部表
除上述两种情况外,一般使用内部表
删除外部表:仅仅是删除元数据(表的信息),不会删除数据本身
-- 创建外部表
create external table if not exists hive_day02.stu_ext(
id int,
name string
)
row format delimited fields terminated by '\t'; --表中数据默认分隔符为tab键
- 1
- 2
- 3
- 4
- 5
- 6
做同样的数据准备
-- 将本地/root/目录下a.txt文件数据加载到表中
load data local inpath '/root/a.txt' into table hive_day02.stu_ext;
-- 清空内部表
truncate table hive_day02.stu_ext;
- 1
- 2
- 3
- 4
提示org.apache.hadoop.hive.ql.parse.SemanticException:Cannot truncate non-managed table hive_day02.stu_ext2.
无法清空此外部表,外部表不被hive管理,hive外部表只是维护了此表的映射关系,无法清空外部的数据。所以需要清空表等表编辑表的操作还是建内部表吧
-- 删除外部表,删除表的同时不删除数据,在hdfs中依旧可以查询到数据
drop table hive_day02.stu_ext;
-- 查询表数据
select * from stu_ext;
- 1
- 2
- 3
- 4
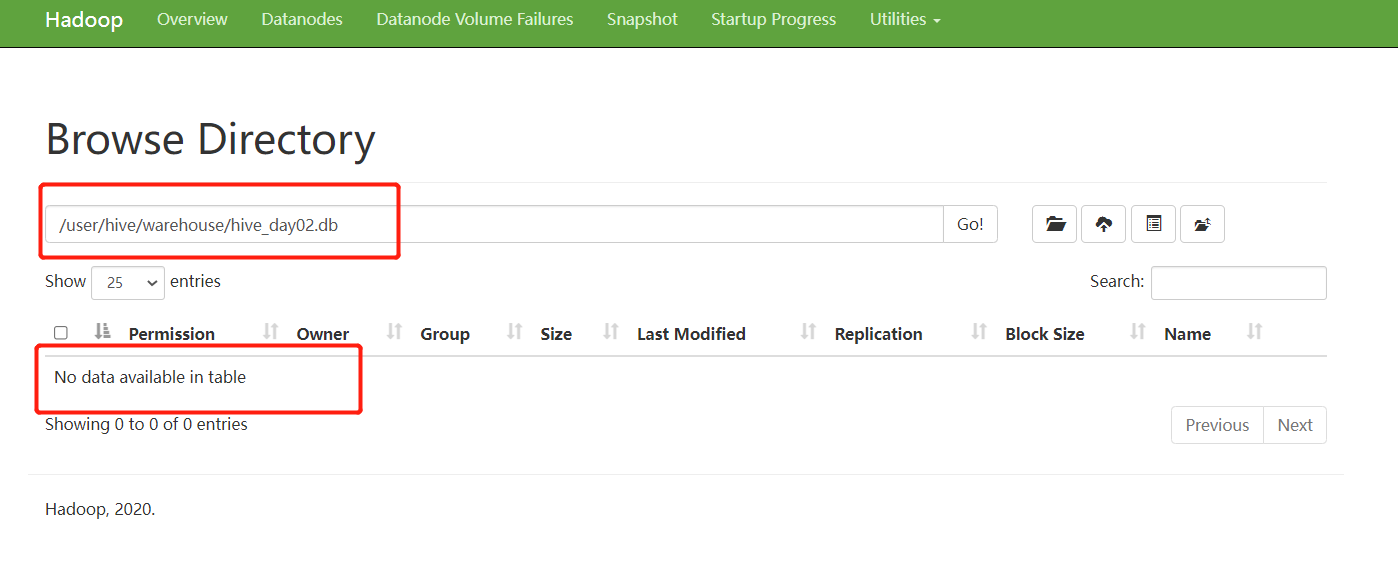
提示;org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:14 Table not found 'stu_ext'
在数据库中表信息已删除,在HDFS中仍能查到数据
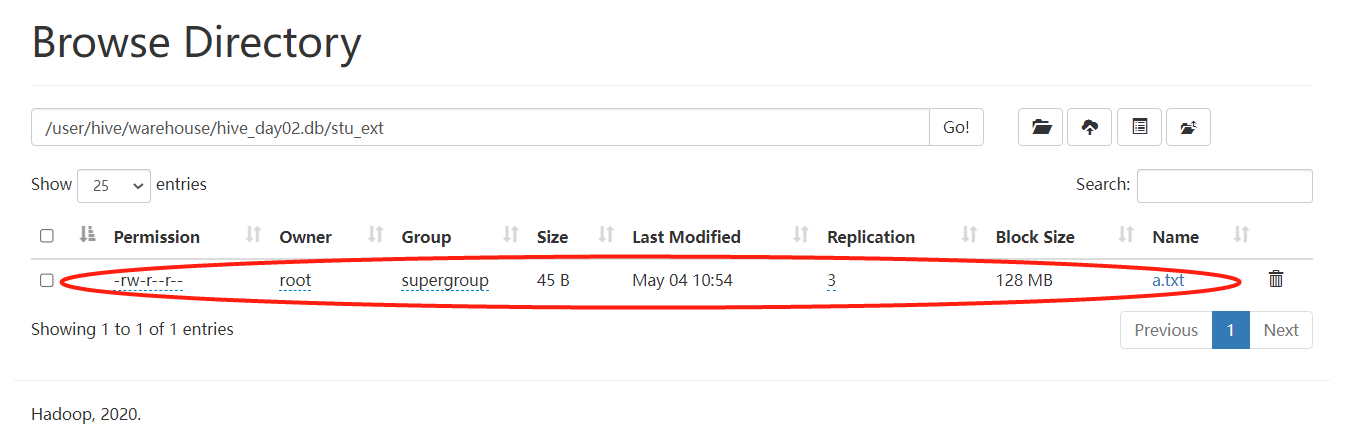
也可在先存在数据,后创建外部表 通过location '数据路径'绑定已有数据,也可以修改表的路径。
数据准备:在HDFS/text目录下存在a.txt数据
-- 创建外部表,绑定已有的数据
create external table if not exists hive_day02.stu_ext2(
id int,
name string
)
row format delimited fields terminated by '\t'
location '/test/students';
-- 修改表的路径
alter table hive_day02.stu_ext set location '/test/students';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
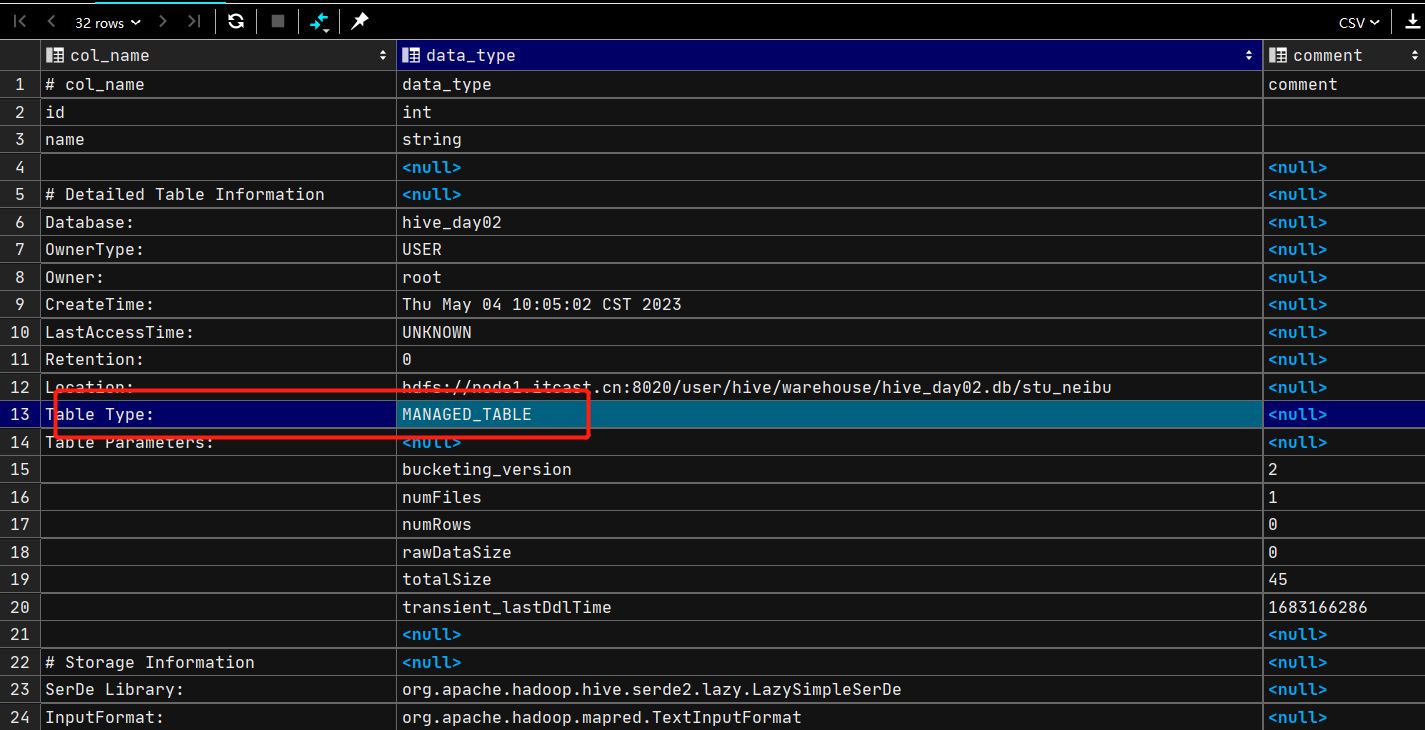
desc formatted table_name;可以查看表信息
内部表的Table Type为MANAGED_TABLE
外部表的Table Type为EXTERNAL_TABLE
内部表与外部表的区别
注:
hive中的元数据存储在mysql数据库中,hive映射的表中的数据记录存储在hdfs中
外部表删除时数据库中查不到数据但是记录依旧存储在hdfs中
内部表外部表转换
内部表转外部表
alter table stu set tblproperties('EXTERNAL'='TRUE');
- 1
外部表转内部表
alter table stu set tblproperties('EXTERNAL'='FALSE');
- 1
通过set tblproperties来修改属性,要注意:(‘EXTERNAL’=‘FALSE’) 或 (‘EXTERNAL’=‘TRUE’)为固定写法,区分大小写!!!
3 数据的上传与导出
上传
方法一: 直接使用web页面上传
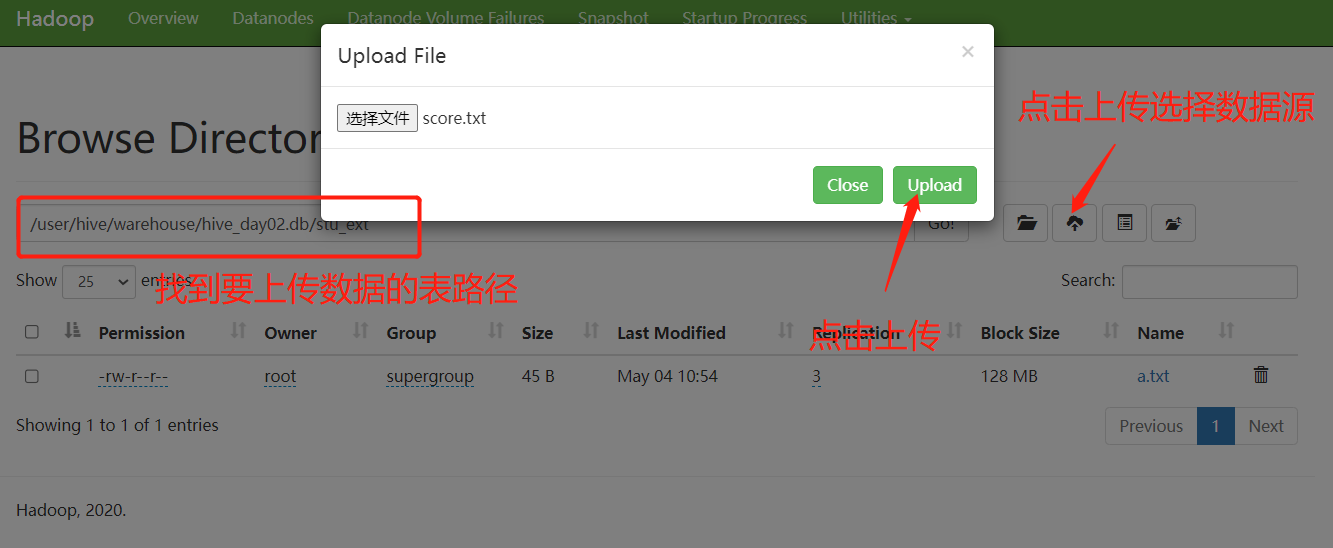
若无法上传需在windows中配置主机映射,在C:\Windows\System32\drivers\etc\hosts文件中配置主机映射
方法二: 使用hadoop的shell指令进行数据上传
hadoop fs -put 本地文件路径 hdfs文件路径
hdfs dfs -put 本地文件路径 hdfs文件路径
注意: 本地文件路径,可以使用相对路径,也可以使用绝对路径, 而hdfs只能使用绝对路径
方式三: 使用功能load data命令加载数据
语法:LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename;
LOCAL:数据是否在本地:使用local,数据不在HDFS,需使用file://协议指定路径;
不使用local,数据在HDFS,可以使用HDFS://协议指定路径;
OVERWRITE:覆盖已存在数据,使用OVERWRITE进行覆盖,不使用OVERWRITE则不覆盖
-- load data加载 ------------------------------------↓本地加载↓-------------------------------- -- comment 是注释内容,该信息与表的属性和使用方式无关 CREATE TABLE hive_day02.test_load( dt string comment '时间(时分秒)', user_id string comment '用户ID', word string comment '搜索词', url string comment '用户访问网址' ) comment '搜索引擎日志表' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- 加载本地数据 load data local inpath '/root/hive_data/search_log.txt' into table hive_day02.test_load; -- 查询数据 select * from hive_day02.test_load; -- 再次加载本地数据 load data local inpath '/root/hive_data/search_log.txt' into table hive_day02.test_load; -- 再次查询数据 select * from hive_day02.test_load; -- 大多数情况下,我们不希望导入的数据重复,我们可以使用overwrite进行覆盖导入 -- 覆盖后会将原有的数据删除,而保留本次导入的数据内容 load data local inpath '/root/hive_data/search_log.txt' overwrite into table hive_day02.test_load; -- 再次查询数据 select * from hive_day02.test_load; -- 清空test_load表 truncate table hive_day02.test_load; ------------------------------------↓hdfs加载↓-------------------------------- -- 不加local本地加载,会自动在HDFS加载 No files matching path hdfs://node1.itcast.cn:8020/root/hive_data/search_log.txt -- 修改为hdfs中的路径后继续上传 load data inpath '/tmp/hive_data/search_log.txt' into table hive_day02.test_load; -- 查询数据 select * from hive_day02.test_load; -- 再次加载hdfs中的数据 -- 报错 : No files matching path hdfs://node1.itcast.cn:8020/tmp/hive_data/search_log.txt -- 当我们加载的数据时hdfs中的数据时,会将源文件移动到指定的表目录中,原始数据消失, 而本地加载则相当于复制,源文件不丢失 -- load data inpath '/tmp/hive_data/search_log.txt' into table hive_day02.test_load;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
总结:
- load data 如果加上local就是加载本地数据,如果不加local就是加载hdfs中的数据
- load data 加载本地数据时,等同与复制,源文件不丢失, 如果加载hdfs中的数据时,相当于移动,源文件丢失
- 使用insert into 将会持续追加数据,使用insert overwrite into 则会覆盖数据,不会追加
- local是指hiveserver2服务部署在的node1服务器上.
- 在开发中是hdfs导入数据用的多:
- local是从单机获取数据,数据体量不会太大
- local的数据读取需要权限设定,而hdfs中一般公共数据都有权限
- 重要数据,使用load data 会移动其位置,后续不好查找,我们一般使用外部表指定location直接绑定不移动
导出
hive表数据导出- insert overwrite方式
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hdfs,例如mysql等等
语法:insert overwrite [local] directory 目标路径 [row format delimited fields terminated by 分隔符] select ... from ...;
将查询的结果导出到本地 - 使用默认列分隔符
insert overwrite local directory '/home/hadoop/export1' select * from test_load ;
- 1
将查询的结果导出到本地 - 指定列分隔符
insert overwrite local directory '/home/hadoop/export2' row format delimited fields terminated by '\t' select * from test_load;
- 1
将查询的结果导出到HDFS上(不带local关键字)
insert overwrite directory '/tmp/export' row format delimited fields terminated by '\t' select * from test_load;
- 1
hive表数据导出 - hive shell
语法:hive -f/-e 执行语句 > file批处理: 执行一次就结束
bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt
- 1
语法:hive -f/-e 脚本 > file可以将数据写入到hive.sql文件中再调用
bin/hive -f export.sql > /home/hadoop/export4/export4.txt
- 1
4 分区表与分桶表
分区表
单分区表
什么是分区表?
可以选择字段作为表分区
分区其实就是HDFS上的不同文件夹
分区表可以极大的提高特定场景下Hive的操作性能
语法:create table tablename(...) partitioned by (分区列 列类型, ...) row format delimited fields terminated by '';
分区表的分区列,在partitioned by中定义,不在普通列中定义
-- 创建一个单分区表
create table hive_day02.score_part(
s_name string,
c_name string,
score double
)
partitioned by (dt string)
row format delimited fields terminated by '\t';
-- 加载数据 dt字段不是真实存在的
load data local inpath '/root/hive_data/score.txt' into table score_part partition (dt='2022-05-03');
-- 查询数据
select * from hive_day02.score_part;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

-- 增加分区
alter table hive_day02.score_part add partition (dt='2022-05-04');
- 1
- 2
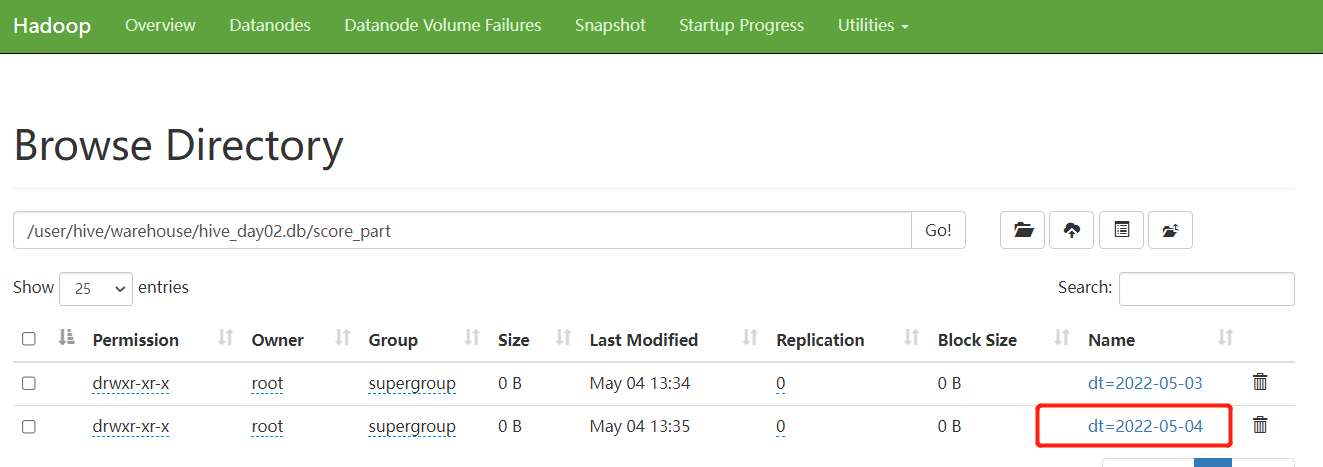
-- 删除分区,删除分区后HDFS网页上对应的分区将会被删除
alter table hive_day02.score_part drop partition (dt='2022-05-04');
-- 修改分区名字
alter table hive_day02.score_part partition (dt='2022-05-03') rename to partition (dt='2032-04-03');
- 1
- 2
- 3
- 4

多级分区表
创建多级分区表语法:
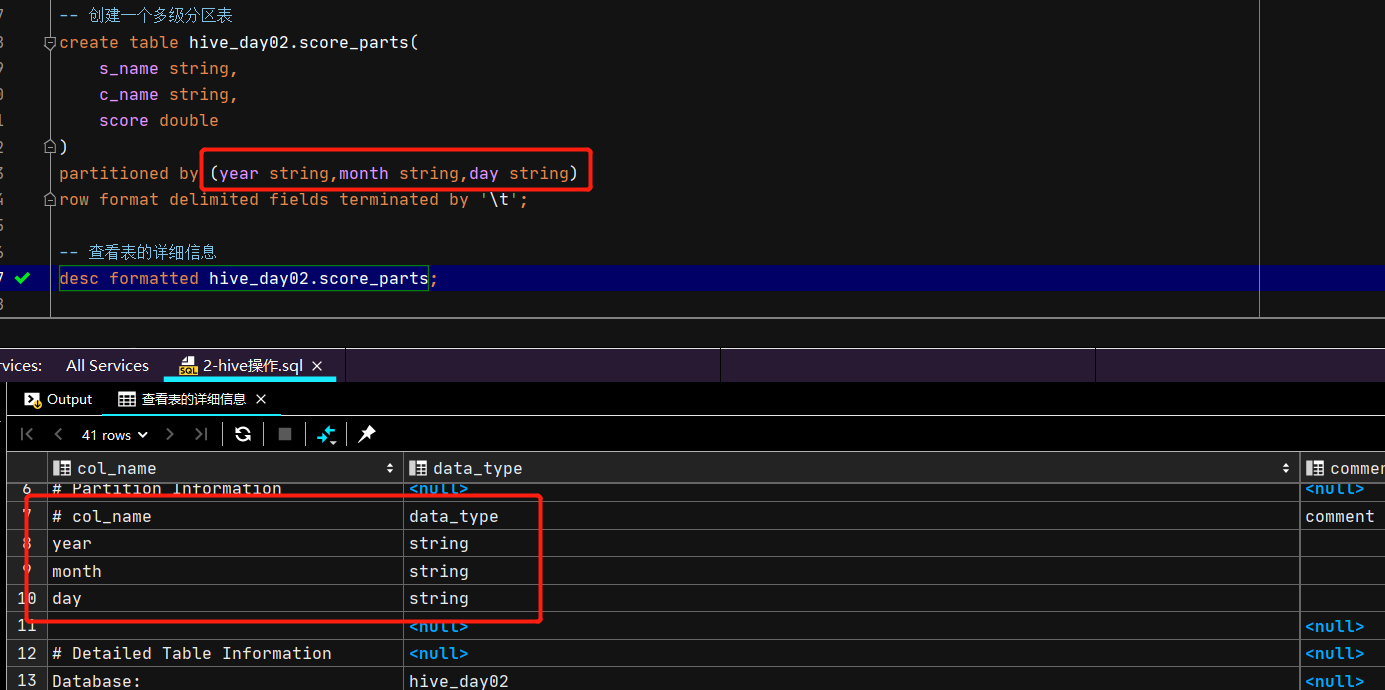
create table hive_day02.score_parts( s_name string, c_name string, score double ); partitioned by (year string,month string,day string) row format delimited fields terminated by '\t';
通过表信息查询可以看到多级分区的分区字段
-- 创建一个多级分区表 create table hive_day02.score_parts( s_name string, c_name string, score double ) partitioned by (year string,month string,day string) row format delimited fields terminated by '\t'; -- 查看表的详细信息 desc formatted hive_day02.score_parts; -- 加载本地数据 load data local inpath '/root/hive_data/score.txt' into table hive_day02.score_parts partition (year='2022',month='12',day ='31'); load data local inpath '/root/hive_data/score.txt' into table hive_day02.score_parts partition (year='2032',month='06',day ='31'); -- 查看分区字段 show partitions hive_day02.score_parts;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
查看表详细信息
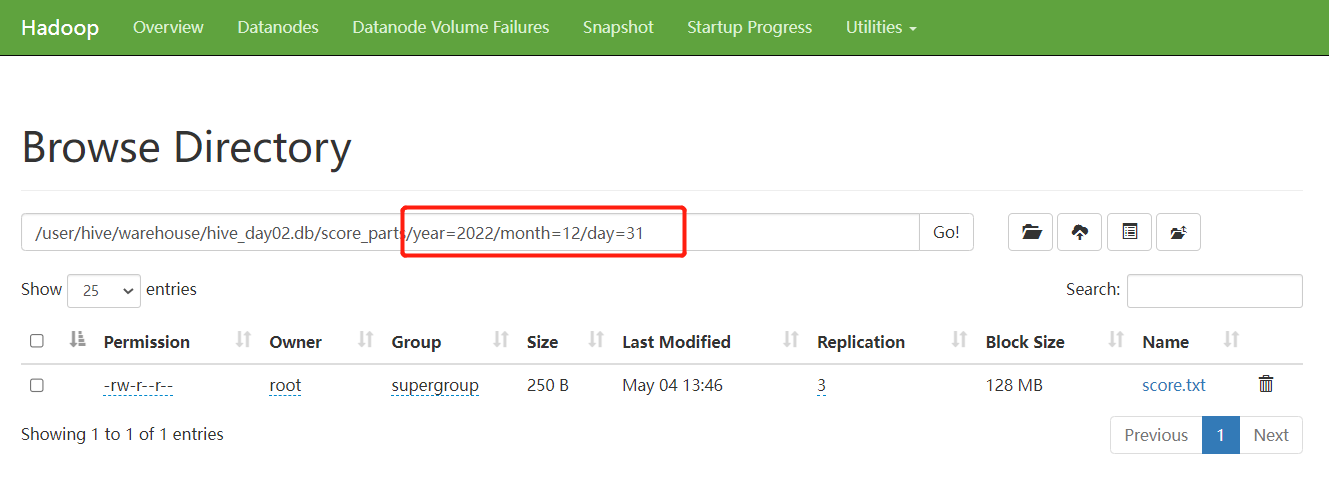
插入多级分区表数据后体现的结果是多级目录文件,如下图所见:
总结:
多级分区相当于在表目录下创建了多级目录文件,并且在最底层目录中添加数据文件,也就是必须在每一级添加数据,否则创建不了
注意:在开发中使用多级分区时,分区字段间一定要有依赖关系,如年月日,省市区;
一般多级分区表不会超过3级,若分级过多将会产生大量小文件,造成大量内存资源占用(开启容器有最小容量限制),hdfs不善于处理小文件。
分桶表(也称分簇表)
什么是分桶表?
可以选择字段作为分桶字段
分桶表本质上是数据分开在不同的文件中
分区和分桶可以同时使用
分桶规则:哈希取模法:
取模:取余,如10/3余1,此时取模或取余后值为1
哈希:哈希是一种散列函数,通过哈希算法,一个数据可以得到一个唯一的值
根据分桶字段的值计算哈希值,然后根据分桶数量将哈希值进行取模计算,根据计算结果不同将数据放入不同桶文件内,就是哈希取模法分桶法
语法:clustered by(c_id) into 3 buckets clustered by指定分桶字段 into num buckets指定分桶数量
-- 创建分桶表
create table hive_day02.course_buck(
c_id int comment '学科id',
c_name string comment '学科名称',
t_name string comment '教师名称'
)
clustered by (c_id) into 3 buckets --创建分桶表时,字段必须为实体字段
row format delimited fields terminated by '\t';
-- 向分桶表中插入数据
-- 方法一:直接使用load data
load data local inpath '/root/hive_data/score.txt' into table hive_day02.course_buck;
-- 查看表中数据
select * from course_buck;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
注意: 方法一加载数据不建议使用,因为在老版本的hive中,这种方式加载会出现错误
插入分桶表中的数据,会根据分桶字段的值分为多个桶,并且查询数据时,按桶的顺序排列数据
方法二:
- 创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
- 然后通过insert select 从临时表向桶表插入数据
-- 创建一个普通临时表 create table hive_day02.course1( c_id int comment '学科id', c_name string comment '学科名称', t_name string comment '教师名称' ) row format delimited fields terminated by '\t'; -- 导入数据 load data local inpath '/root/hive_data/course.txt' into table hive_day02.course1; -- 查看表数据 select * from course1; -- 创建分桶表 create table hive_day02.course_buck2( c_id int comment '学科id', c_name string comment '学科名称', t_name string comment '教师名称' ) clustered by (c_id) into 3 buckets --创建分桶表时,字段必须为实体字段 row format delimited fields terminated by '\t'; -- 方法二:从非分桶表中读取数据插入到分桶表中 insert overwrite table hive_day02.course_buck2 select * from hive_day02.course1 cluster by (c_id);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
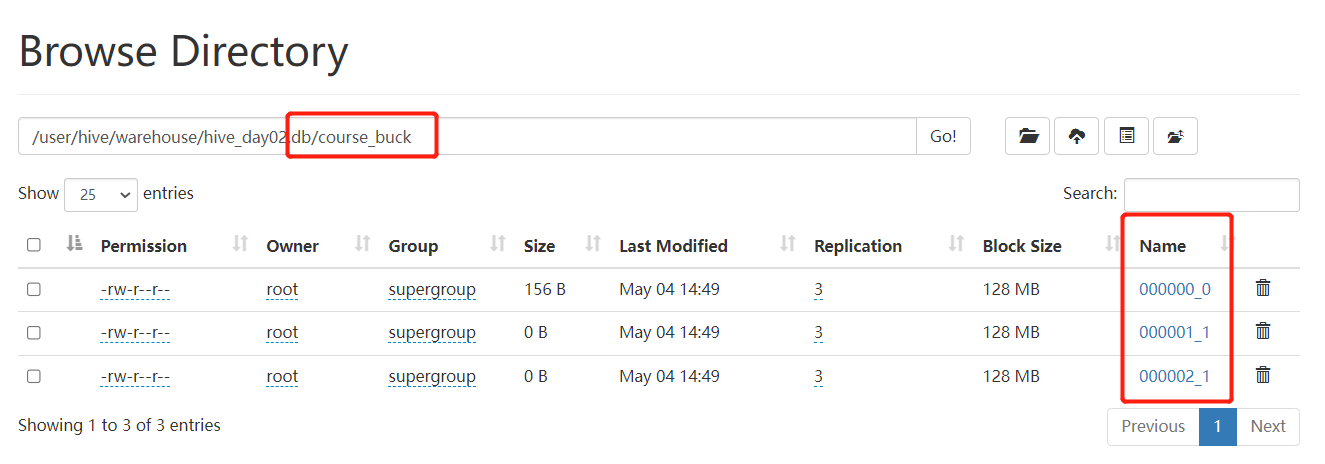
分桶数为3,创建呈现出来的是三个文件,如下图所示:
为什么要使用分区表:
因为在数据查询和计算过程中,如果使用非分区表,我们会将表中所有的数据都读取出来,进行计算或使用,如果表过于庞大,对于内存的要求较高
如果我们根据分区字段进行分区过滤,则我们处理数据时,只读取其中满足条件的分区中的数据
减小了表扫描的范围,增加了查询和计算效率
举例: 按照dt 进行分区, 则select * from where dt > ‘2020-12-12’ 此时不满足条件的分区数据不会被读取出来
注意: 如果不筛选数据,或者不使用分区字段进行筛选,则使用起来和普通表效率相当.
为什么要使用分桶表:
- 分桶表可以提高查询效率, 我们根据分桶表进行筛选时,只读取满足筛选条件的分桶文件,缩小了查询范围,提高了查询效率
- 举例: 根据性别,将班级同学分成两个桶, 如果我们查询男生的数据,则先计算哈希值,找到指定哈希值所在的分桶,不会查询另外一个分桶中的数据.
- 提升表连接的效率(提升笛卡尔积效率), 两张表连接时需要使用一张表的每一个字段和另一张表的每一个字段进行匹配
- 普通表: 两表链接需要匹配的次数 左表的记录数 * 右表的记录数
- 分桶表: 先计算连接字段的哈希取模结果,然后仅匹配 哈希取模结果相同的数据,匹配次数减少
分桶数量越多连接优势越明显,但是不会分太多的桶,因为分桶过多或产生大量的小问题件,或者产生空桶.
注意: 如果不筛选数据,或者不使用分桶字段进行筛选,则使用起来和普通表效率相当. 如果不连接数据,或者连接数据时没有使用分桶字段连接,则与普通表没有区别
分桶表和分区表的区别:
- 分区表是将一个表中的数据拆分为多个文件目录,写入不同的分区目录中,分桶表时将一个表中的数据拆分为多个文件,写入不同的分桶文件中
- 分区表使用的分区字段是元数据字段,数据记录中不存在该数据, 分桶表中使用的分桶字段是实体字段,数据记录中存在该字段
- 分区表可以多级分区,分桶表不能多级分桶
- 分区表主要是为了减小数据检索范围,提高查询效率, 分桶表主要是为了提高表的连接效率
分桶表和分区表的相同点:
- 都可以提高查询数据的效率,缩小检索范围
- 如果不根据分区字段或分桶字段进行筛选或连接,则与普通表没有区别
- 都是在模型创建(建表建库)时对于数据仓库的优化措施
5 hive查询语句
语法:SELECT [ALL | DISTINCT]select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BYcol_list] [HAVING where_condition] [ORDER BYcol_list] [CLUSTER BYcol_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT number]
CLUSTER BY:桶内排序
整体上和普通SQL差不多,部分有区别,如:CLUSTER BY、DISTRIBUTE BY、SORT BY等
-------------------------------------------HIVE基本查询--------------------------------------- -- 数据准备 订单表 CREATE TABLE hive_day02.orders( orderId bigint COMMENT '订单id', orderNo string COMMENT '订单编号', shopId bigint COMMENT '门店id', userId bigint COMMENT '用户id', orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货', goodsMoney double COMMENT '商品金额', deliverMoney double COMMENT '运费', totalMoney double COMMENT '订单金额(包括运费)', realTotalMoney double COMMENT '实际订单金额(折扣后金额)', payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他', isPay tinyint COMMENT '是否支付 0:未支付 1:已支付', userName string COMMENT '收件人姓名', userAddress string COMMENT '收件人地址', userPhone string COMMENT '收件人电话', createTime timestamp COMMENT '下单时间', payTime timestamp COMMENT '支付时间', totalPayFee int COMMENT '总支付金额' ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -- 加载数据 load data local inpath '/root/hive_data/itheima_orders.txt' into table hive_day02.orders; -- 查询数据 select * from orders; -- 1.基础查询 select orderId,goodsMoney+200 as price,'2020-12-12' as dt from hive_day02.orders; -- 2.条件查询 select * from hive_day02.orders where goodsmoney>500000; select * from hive_day02.orders where userphone like '189%'; select * from hive_day02.orders where realtotalmoney between 200 and 500; select * from hive_day02.orders where realtotalmoney!=200; select * from hive_day02.orders where realtotalmoney is not null; select * from hive_day02.orders where realtotalmoney in (100, 200); -- 3.聚合函数 select count(1) from hive_day02.orders; select sum(realtotalmoney) from hive_day02.orders; -- 4.分组查询 select paytype,sum(realtotalmoney) from hive_day02.orders group by payType; -- Expression not in GROUP BY key 'paytime' -- select paytype,paytime,sum(realtotalmoney) from hive_day02.orders group by paytype; -- 5.分组后聚合 select paytype,sum(realtotalmoney) total_money from hive_day02.orders group by paytype having total_money; -- 6.排序 select paytype,sum(realtotalmoney) total_money from hive_day02.orders group by paytype having total_money>5000 order by total_money; -- 7.分页 select paytype,sum(realtotalmoney) total_money from hive_day02.orders group by paytype having total_money>5000 order by total_money limit 0,20;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
6 hive启动连接
hive的启动:
1 启动metastore : nohup hive --service metastore &
2 启动hiveserver2 : nohup hive --service hiveserver2 &
hive的客户端:
一代客户端: hive
二代客户端: beeline
eg:通过beeline的方式连接->退出
[root@node1 ~]# beeline log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Beeline version 2.3.7 by Apache Hive beeline> !connect jdbc:hive2://node1:10001 Connecting to jdbc:hive2://node1:10001 Enter username for jdbc:hive2://node1:10001: root Enter password for jdbc:hive2://node1:10001: Connected to: Spark SQL (version 3.1.2) Driver: Hive JDBC (version 2.3.7) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://node1:10001> show databases; +------------+ | namespace | +------------+ | default | +------------+ 1 row selected (0.113 seconds) 0: jdbc:hive2://node1:10001> !quit Closing: 0: jdbc:hive2://node1:10001
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
二代客户端与一代客户端相比有什么优势?
1 一代客户端,既负责元数据的查询,还负责连接保持,峰值性能不强,而二代客户端所有的连接保持由hiveserver2保持,metastore只负责与hiveserver2保持连接
2 二代客户端对于用户身份进行了验证,数据更加安全
3 二代客户端支持jdbc协议连接,可以连接大量的第三方服务,使hive的兼容范围更广

