
- 1vue2(H5录音)_vue2录音插件
- 2android studio的语言设置在哪,android studio 0.3.2中的语言级别设置是什么?(What does the language level setting in andro...
- 3【AI入门】利用Paddle实现简单的数字识别_paddle 检测识别脚本
- 4怎么查询公网IP_公网ip查询
- 5人工智能(AI)-机器学习-深度学习-大语言模型LLM(chatgtp)
- 6SpringBoot———实现增删改查操作_简单的数据库的增删改查springboot
- 7在线SQL格式化工具
- 8鸿蒙OS ArkUI 封装接口网络请求 -- 小白篇_鸿蒙axios封装
- 9vue小项目todolist,20分钟复习Vue基础知识点_vue简单复习项目
- 10Neovim Lua 配置从0到1_neovim lua配置
论文阅读——Rein
赞
踩
Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
一、引言
是一个对Domain Generalized Semantic Segmentation (DGSS)任务的视觉大模型的微调方法,即Rein。
Rein 专为 DGSS 任务量身定制,采用更少的可训练参数来利用更强大的 VFM 来实现卓越的泛化。 Rein 的核心由一组随机初始化的tokens组成,每个token都直接链接到不同的实例。这些tokens通过 VFM 特征的点积运算,生成类似注意力的相似性图。该图使 Rein 能够针对图像中的每个实例执行精确的细化,从而显着增强 DGSS 背景下的 VFM。此外,为了减少可训练参数的数量,我们在不同层的 MLP 之间采用共享权重,并通过将两个低秩矩阵相乘来设计可学习的令牌。
主要贡献:
我们首先在领域广义语义分割(DGSS)的背景下评估各种视觉基础模型(VFM)。我们在 DGSS 框架中进行的广泛实验凸显了 VFM 令人印象深刻的泛化能力。研究结果证实,VFM 可以作为更强大的支柱,从而在该领域建立了重要的基准。
我们提出了一种强大的微调方法,即“Rein”,以参数有效地利用VFM。 Rein 的核心由一组可学习的令牌组成,每个token都直接链接到不同的实例。通过深思熟虑的设计,这种链接使 Rein 能够在每个骨干层内的实例级别细化特征图。因此,Rein 增强了 VFM 在 DGSS 任务中的能力,用更少的可训练参数实现这一目标,同时保留预先训练的知识。
跨各种DGSS 设置的综合实验表明,Rein 采用更少的可训练参数来有效利用更强的VFM 来实现卓越的通用性。该性能大幅超越现有的 DGSS 方法。值得注意的是,Rein 旨在与现有的普通视觉 Transformer 平滑集成,提高其泛化能力并使训练更加高效。
二、相关工作:
DGSS:领域广义语义分割。领域广义语义分割(DGSS)专注于增强模型的通用性。该领域通常涉及在一组源域数据上训练模型,以增强其在不同的和不可见的目标域数据集上的性能。已经提出了各种方法来解决DGSS中的这个问题,代表性的方法包括将学习到的特征分成域不变和域特定的组件,或者采用元特征学习训练更强大的模型。 DGSS 中的标准场景是从一个城市场景数据集推广到另一个城市场景数据集,例如,从合成 GTAV 数据集推广到现实世界的城市景观。
参数高效的微调:
在 NLP 领域,参数高效微调(PEFT)通过冻结基础模型的大部分参数并微调少数参数,取得了显着的成功。已经引入了各种策略,例如 BitFit,它仅调整模型的偏差项,或仅调整这些项的子集;Prompt-tuning,它学习软提示来调节冻结的语言模型以执行特定的下游任务;Adapter-tuning,在每个 Transformer 层中包含额外的轻量级模块;值得注意的是,LoRA,它将可训练的秩分解矩阵注入到 Transformer 架构的每一层中,产生了显着的影响。 PEFT 方法也在计算机视觉领域获得关注,例如 Visual Prompt Tuning,它将提示预先添加到 Transformer 层的输入序列中以进行微调,以及 AdaptFormer,它将 Transformer 编码器中的 MLP 块替换为包含两个子分支的 AdaptMLP。然而,这些方法主要针对分类任务进行调整,其中每张图像仅包含一个要识别的目标。我们的努力是针对分割任务量身定制的,为图像中的每个实例在对象级别细化特征图,从而实现卓越的性能。
三、方法
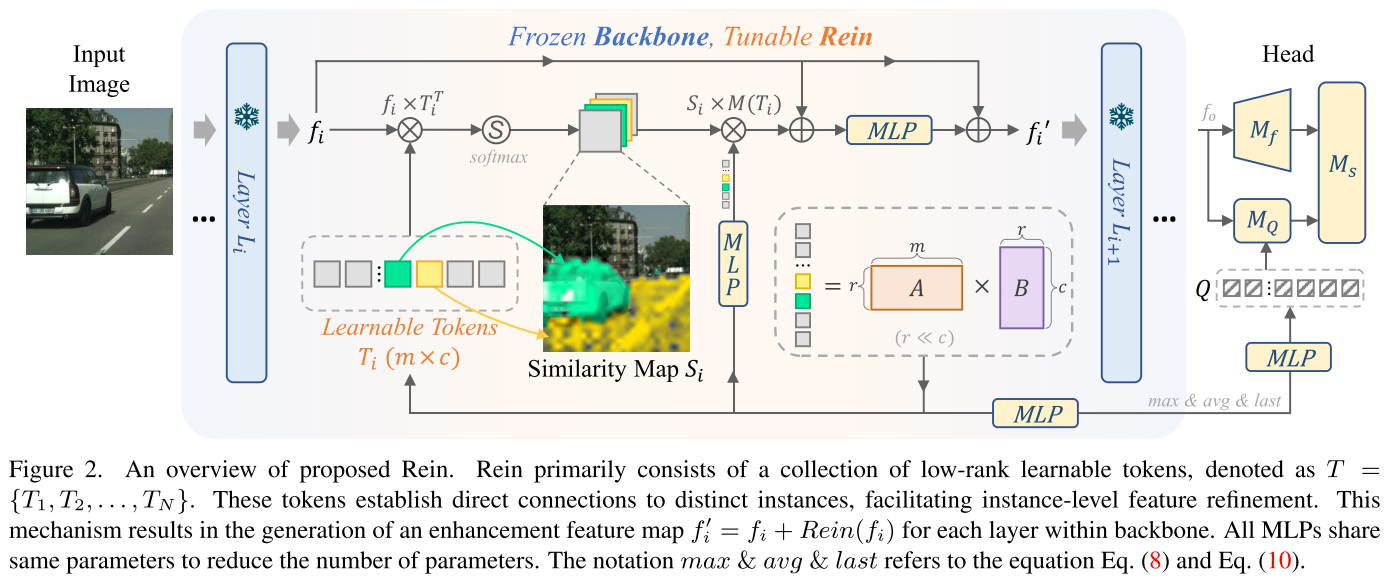
在主干内的各层之间嵌入一种名为“Rein”的机制。 Rein 主动细化特征图并将其从每一层转发到后续一层。这种方法使我们能够更有效地利用 VFM 的强大功能,就像使用缰绳控制马一样。
Core of Rein

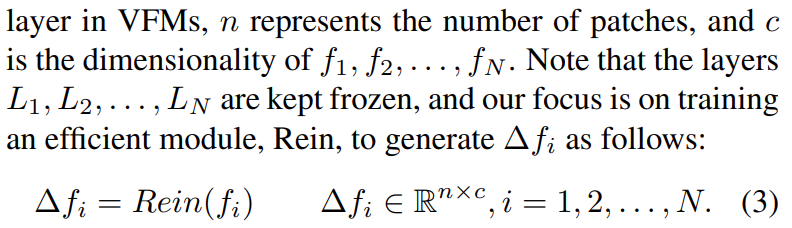
Rein有一组可学习的tokens,![]() Ti是随机初始化的,m表示Ti的序列长度。
Ti是随机初始化的,m表示Ti的序列长度。
计算每个token Ti 和VLM特征fi的相似度:

对齐:
![]()
![]()
![]()
Details of Rein
![]()
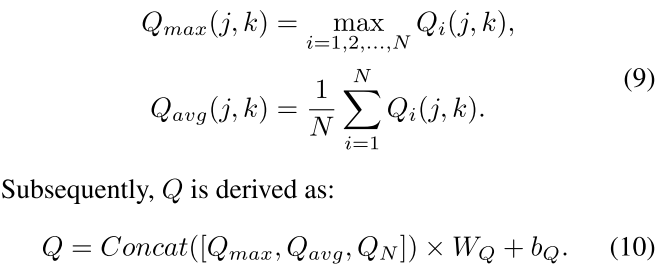
Layer-shared MLP weights.
Low-rank token sequence.



