
热门标签
热门文章
- 1HarmonyOS(十七)——状态管理之@Provide装饰器和@Consume装饰器(与后代组件双向同步)_harmonyos@consume
- 2音视频开发之旅(71)- 人脸修复画质增强之GFPGAN_roop中涉及到的gfpgan算法模型文件
- 3js日期判断先后_js年月比先后
- 4使用websocket实现群聊(多个群)_java websocket实现群聊,不同群
- 5RK3588平台开发系列讲解(硬件篇-最小系统设计)
- 6Android Studio调试方法
- 7raster2pgsql命令参数详解_raster2psql参数
- 8Docker进阶Compose——swarm集群_compose跟swarm
- 9大模型训练太难了!
- 10EMC存储VNX1或者CX更换SPS常见问题_emc vnx5100更换电池
当前位置: article > 正文
自然语言处理(二十九):Transformer与BERT常见问题解析_transformer sostoken
作者:IT小白 | 2024-03-31 01:35:57
赞
踩
transformer sostoken
自然语言处理笔记总目录
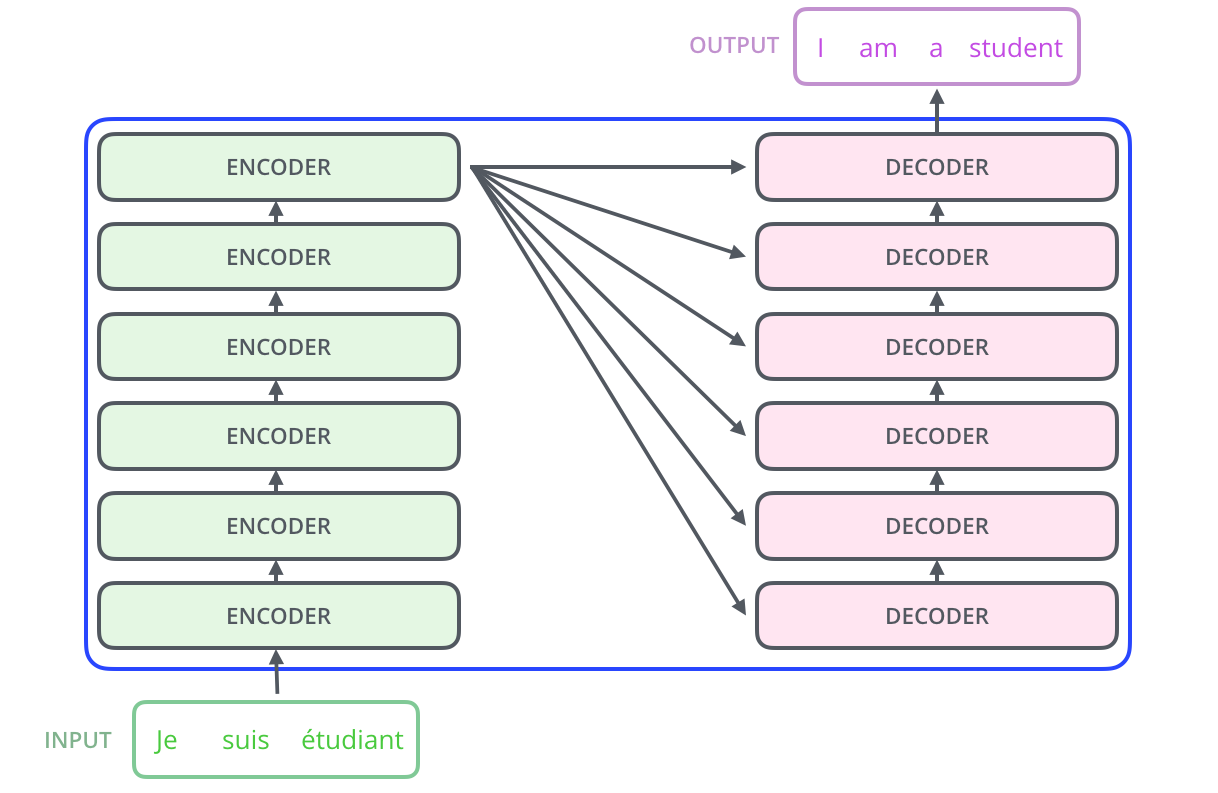
Transformer结构图:

一、Transformer结构中的Decoder端具体输入是什么? 在训练阶段和预测阶段一致吗?
- Decoder端的架构:Transformer论文中的Decoder模块是由N=6个相同的Decoder Block堆叠而成,其中每一个Block是由3个子模块构成,分别是多头self-attention模块,Encoder-Decoder attention模块,前馈全连接层模块
- 6个Block的输入不完全相同:
- 最下面的一层Block接收的输入是经历了MASK之后的Decoder端的输入 + Encoder端的输出
- 其他5层Block接收的输入模式一致,都是前一层Block的输出 + Encoder端的输出
- Decoder在训练阶段的输入解析:
- 从第二层Block到第六层Block的输入模式一致,无需特殊处理,都是固定操作的循环处理
- 聚焦在第一层的Block上:训练阶段每一个time step的输入是上一个time step的输入加上真实标签序列向后移一位。具体来说,假设现在的真实标签序列等于"How are you?",当time step=1时,输入张量为一个特殊的token,比如"SOS";当time step=2时,输入张量为"SOS How";当time step=3时,输入张量为"SOS How are",以此类推…
- 注意:在真实的代码实现中,训练阶段不会这样动态输入,而是一次性的把目标序列全部输入给第一层的Block,然后通过多头self-attention中的MASK机制对序列进行同样的遮掩即可
- Decoder在预测阶段的输入解析:
- 同理于训练阶段,预测时从第二层Block到第六层Block的输入模式一致,无需特殊处理,都是固定操作的循环处理
- 聚焦在第一层的Block上:因为每一步的输入都会有Encoder的输出张量,因此这里不做特殊讨论,只专注于纯粹从Decoder端接收的输入。预测阶段每一个time step的输入是从time step=0,input_tensor="SOS"开始,一直到上一个time step的预测输出的累计拼接张量。具体来说:
- 当time step=1时,输入的input_tensor=“SOS”,预测出来的输出值是output_tensor=“What”;
- 当time step=2时,输入的input_tensor=“SOS What”,预测出来的输出值是output_tensor=“is”;
- 当time step=3时,输入的input_tensor=“SOS What is”,预测出来的输出值是output_tensor=“the”;
- 当time step=4时,输入的input_tensor=“SOS What is the”,预测出来的输出值是output_tensor=“matter”;
- 当time step=5时,输入的input_tensor=“SOS What is the matter”,预测出来的输出值是output_tensor="?";
- 当time step=6时,输入的input_tensor=“SOS What is the matter ?”,预测出来的输出值是output_tensor=“EOS”,代表句子的结束符,说明解码结束,预测结束
二、Transformer中一直强调的self-attention是什么? 为什么能发挥如此大的作用? 计算的时候如果不使用三元组(Q, K, V), 而仅仅使用(Q, V)或者(K, V)或者(V)行不行?
self-attention的机制和原理
- self-attention是一种通过自身和自身进行关联的attention机制,从而得到更好的representation来表达自身
- self-attention是attention机制的一种特殊情况:
- 在self-attention中,Q=K=V,序列中的每个单词(token)都和该序列中的其他所有单词(token)进行attention规则的计算
- attention机制计算的特点在于,可以直接跨越一句话中不同距离的token,可以远距离的学习到序列的知识依赖和语序结构

- 从上图中可以看到,self-attention可以远距离的捕捉到语义层面的特征(its的指代对象是Law)
- 应用传统的RNN,LSTM,在获取长距离语义特征和结构特征的时候,需要按照序列顺序依次计算,距离越远的联系信息的损耗越大,有效提取和捕获的可能性越小
- 但是应用self-attention时,计算过程中会直接将句子中任意两个token的联系通过一个计算步骤直接联系起来
- 关于self-attention为什么要使用(Q, K, V)三元组而不是其他形式:
- 首先一条就是从分析的角度看,查询Query是一条独立的序列信息,通过关键词Key的提示作用,得到最终语义的真实值Value表达,数学意义更充分,完备
- 这里不使用(K, V)或者(V)没有什么必须的理由,也没有相关的论文来严格阐述比较试验的结果差异,所以可以作为开放性问题未来去探索,只要明确在经典self-attention实现中用的是三元组就好
三、Transformer为什么需要进行Multi-head Attention? Multi-head Attention的计算过程是什么?
采用Multi-head Attention的原因
- 1、原论文中提到进行Multi-head Attention的原因是将模型分为多个头,可以形成多个子空间,让模型去关注不同方面的信息,最后再将各个方面的信息综合起来得到更好的效果
- 2、多个头进行attention计算最后再综合起来,类似于CNN中采用多个卷积核的作用,不同的卷积核提取不同的特征,关注不同的部分,最后再进行融合
- 3、直观上讲,多头注意力有助于神经网络捕捉到更丰富的特征信息
Multi-head Attention的计算方式
- 1、Multi-head Attention和单一head的Attention唯一的区别就在于,其对特征张量的最后一个维度进行了分割,一般是对词嵌入的embedding_dim=512进行切割成head=8,这样每一个head的嵌入维度就是512/8=64,后续的Attention计算公式完全一致,只不过是在64这个维度上进行一系列的矩阵运算而已
- 2、在head=8个头上分别进行注意力规则的运算后,简单采用拼接concat的方式对结果张量进行融合就得到了Multi-head Attention的计算结果
四、Transformer相比于RNN/LSTM有什么优势? 为什么?
Transformer的并行计算
- 对于Transformer比传统序列模型RNN/LSTM具备优势的第一大原因就是强大的并行计算能力
- 对于RNN来说,任意时刻t的输入是时刻t的输入x(t)和上一时刻的隐藏层输出h(t-1),经过运算后得到当前时刻隐藏层的输出h(t),这个h(t)也即将作为下一时刻t+1的输入的一部分。这个计算过程是RNN的本质特征,RNN的历史信息是需要通过这个时间步一步一步向后传递的。而这就意味着RNN序列后面的信息只能等到前面的计算结束后,将历史信息通过hidden state传递给后面才能开始计算,形成链式的序列依赖关系,无法实现并行
- 对于Transformer结构来说,在self-attention层,无论序列的长度是多少,都可以一次性计算所有单词之间的注意力关系,这个attention的计算是同步的,可以实现并行
Transformer的特征抽取能力
- 对于Transformer比传统序列模型RNN/LSTM具备优势的第二大原因就是强大的特征抽取能力
- Transformer因为采用了Multi-head Attention结构和计算机制,拥有比RNN/LSTM更强大的特征抽取能力,这里并不仅仅由理论分析得来,而是大量的试验数据和对比结果,清楚的展示了Transformer的特征抽取能力远远胜于RNN/LSTM
- 注意:不是越先进的模型就越无敌,在很多具体的应用中RNN/LSTM依然大有用武之地,要具体问题具体分析
五、为什么说Transformer可以代替seq2seq?
seq2seq的两大缺陷
- 1、seq2seq架构的第一大缺陷是将Encoder端的所有信息压缩成一个固定长度的语义向量中,用这个固定的向量来代表编码器端的全部信息,这样既会造成信息的损耗,也无法让Decoder端在解码的时候去用注意力聚焦哪些是更重要的信息.
- 2、seq2seq架构的第二大缺陷是无法并行,本质上和RNN/LSTM无法并行的原因一样
Transformer的改进
- Transformer架构同时解决了seq2seq的两大缺陷,既可以并行计算,又应用Multi-head Attention机制来解决Encoder固定编码的问题,让Decoder在解码的每一步可以通过注意力去关注编码器输出中最重要的那些部分
六、self-attention公式中的归一化有什么作用? 为什么要添加scaled?
七、Transformer架构的并行化是如何进行的? 具体体现在哪里?
八、BERT模型的优点和缺点?
九、BERT的MLM任务中为什么采用了80%, 10%, 10%的策略?
十、长文本预测任务如果想用BERT来实现, 要如何构造训练样本?
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/342610
推荐阅读
相关标签

