
热门标签
热门文章
- 1机器学习技术-层次聚类算法(组平均)-综合层次聚类方法(BIRCH、CURE)_birch cure
- 2C++ libVNC开源库_rfbinitclient
- 3Kali渗透测试:通过Web应用程序实现远程控制_chrome远程控制kali
- 4自然语言处理中的文本迁移学习与零散数据学习
- 5【MATLAB源码-第22期】基于matlab的手动实现的(未调用内置函数)CRC循环码编码译码仿真。
- 6transformer的实现+详细注释,不来看看吗_transformer实现
- 7demonstration记忆_单词记忆法
- 8LIDA:让LLM自动可视化数据-《LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Info》_lida库
- 9信用评分卡建模:决策树模型_使用树模型做评分卡
- 10在VMware ESXi虚拟机上设置静态MAC地址_虚拟机mac地址怎设置
当前位置: article > 正文
Transformer代码讲解(最最最最......详细)
作者:IT小白 | 2024-03-31 01:57:42
赞
踩
transformer代码
Transformer代码讲解(最最最最…详细)
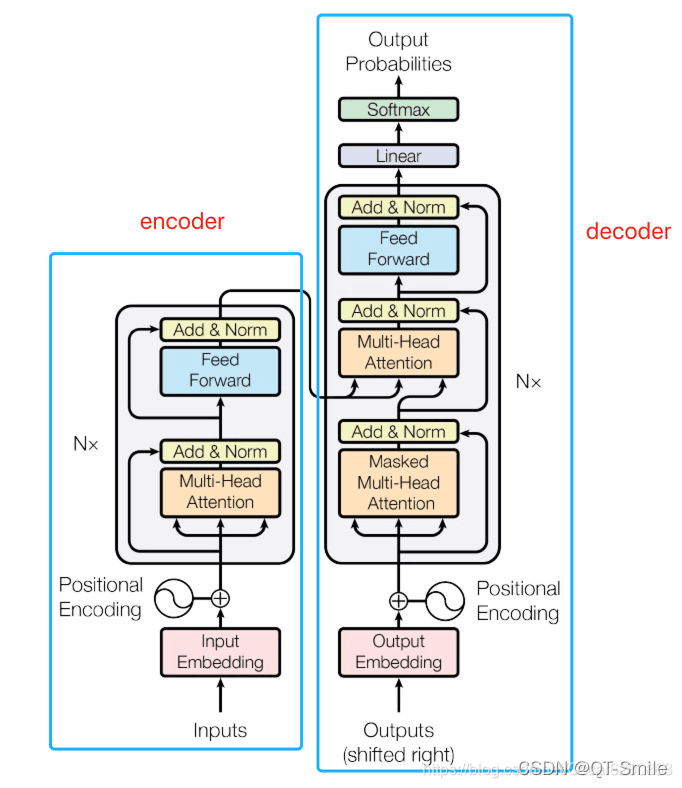
整个代码主要分为两部分去讲解:
一、完整代码
二、部分代码剖析
1、主函数if __name__ == '__main__':
2、 从整体网路结构来看,分为三个部分:编码层,解码层,输出层
3、Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
4、PositionalEncoding 代码实现
5、get_attn_pad_mask
6、EncoderLayer :包含两个部分,多头注意力机制和前馈神经网络
7、MultiHeadAttention
8、ScaledDotProductAttentio
9、PoswiseFeedForwardNet
10、Decoder
11、DecoderLayer(nn.Module):
12、get_attn_subsequent_mask(seq)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
正文:
一、完整代码
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import math
def make_batch(sentences):
input_batch = [[src_vocab[n] for n in sentences[0].split()]]
output_batch = [[tgt_vocab[n] for n in sentences[1].split()]]
target_batch = [[tgt_vocab[n] for n in sentences[2].split()]]
return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)
## 10
def get_attn_subsequent_mask(seq):
"""
seq: [batch_size, tgt_len]
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
# attn_shape: [batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask # [batch_size, tgt_len, tgt_len]
## 7. ScaledDotProductAttention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
## 输入进来的维度分别是 [batch_size x n_heads x len_q x d_k] K: [batch_size x n_heads x len_k x d_k] V: [batch_size x n_heads x len_k x d_v]
##首先经过matmul函数得到的scores形状是 : [batch_size x n_heads x len_q x len_k]
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
## 然后关键词地方来了,下面这个就是用到了我们之前重点讲的attn_mask,把被mask的地方置为无限小,softmax之后基本就是0,对q的单词不起作用
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is one.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
## 6. MultiHeadAttention
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
## 输入进来的QKV是相等的,我们会使用映射linear做一个映射得到参数矩阵Wq, Wk,Wv
self.W_Q = nn.Linear(d_model, d_k * n_heads) # 这儿是不是应该是d_q啊????
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
self.linear = nn.Linear(n_heads * d_v, d_model)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, Q, K, V, attn_mask):
## 这个多头分为这几个步骤,首先映射分头,然后计算atten_scores,然后计算atten_value;
##输入进来的数据形状: Q: [batch_size x len_q x d_model], K: [batch_size x len_k x d_model], V: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
##下面这个就是先映射,后分头;一定要注意的是q和k分头之后维度是一致额,所以一看这里都是dk
q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
##然后我们计算 ScaledDotProductAttention 这个函数,去7.看一下
## 得到的结果有两个:context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q x len_k]
context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
output = self.linear(context)
return self.layer_norm(output + residual), attn # output: [batch_size x len_q x d_model]
## 8. PoswiseFeedForwardNet
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q, d_model]
output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))
output = self.conv2(output).transpose(1, 2)
return self.layer_norm(output + residual)
## 4. get_attn_pad_mask
## 比如说,我现在的句子长度是5,在后面注意力机制的部分,我们在计算出来QK转置除以根号之后,softmax之前,我们得到的形状
## len_input * len_input 代表每个单词对其余包含自己的单词的影响力
## 所以这里我需要有一个同等大小形状的矩阵,告诉我哪个位置是PAD部分,之后在计算计算softmax之前会把这里置为无穷大;
## 一定需要注意的是这里得到的矩阵形状是batch_size x len_q x len_k,我们是对k中的pad符号进行标识,并没有对k中的做标识,因为没必要
## seq_q 和 seq_k 不一定一致(我自己的理解是原文是德文,翻译成英文,而原文的德语的单词个数和英语的单词个数不一样多,所以这儿可能不一致),在交互注意力,q来自解码端,k来自编码端,所以告诉模型编码这边pad符号信息就可以,解码端的pad信息在交互注意力层是没有用到的;
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k, one is masking
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
## 3. PositionalEncoding 代码实现
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
## 位置编码的实现其实很简单,直接对照着公式去敲代码就可以,下面这个代码只是其中一种实现方式;
## 从理解来讲,需要注意的就是偶数和奇数在公式上有一个共同部分,我们使用log函数把次方拿下来,方便计算;
## pos代表的是单词在句子中的索引,这点需要注意;比如max_len是128个,那么索引就是从0,1,2,...,127
##假设我的demodel是512,2i那个符号中i从0取到了255,那么2i对应取值就是0,2,4...510
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)## 这里需要注意的是pe[:, 0::2]这个用法,就是从0开始到最后面,步长为2,其实代表的就是偶数位置
pe[:, 1::2] = torch.cos(position * div_term)##这里需要注意的是pe[:, 1::2]这个用法,就是从1开始到最后面,步长为2,其实代表的就是奇数位置
## 上面代码获取之后得到的pe:[max_len*d_model]
## 下面这个代码之后,我们得到的pe形状是:[max_len*1*d_model]
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe) ## 定一个缓冲区,其实简单理解为这个参数不更新就可以
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
## 5. EncoderLayer :包含两个部分,多头注意力机制和前馈神经网络
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
## 下面这个就是做自注意力层,输入是enc_inputs,形状是[batch_size x seq_len_q x d_model] 需要注意的是最初始的QKV矩阵是等同于这个输入的,去看一下enc_self_attn函数 6.
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
return enc_outputs, attn
## 2. Encoder 部分包含三个部分:词向量embedding,位置编码部分,注意力层及后续的前馈神经网络
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) ## 这个其实就是去定义生成一个矩阵,大小是 src_vocab_size * d_model
self.pos_emb = PositionalEncoding(d_model) ## 位置编码情况,这里是固定的正余弦函数,也可以使用类似词向量的nn.Embedding获得一个可以更新学习的位置编码
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)]) ## 使用ModuleList对多个encoder进行堆叠,因为后续的encoder并没有使用词向量和位置编码,所以抽离出来;
def forward(self, enc_inputs):
## 这里我们的 enc_inputs 形状是: [batch_size x source_len] # 提问:这儿的source_len == max_len???max_len:输入一段话所包含的词的最多有多少个。
## 下面这个代码通过src_emb,进行索引定位,enc_outputs输出形状是[batch_size, src_len, d_model] # 提问:这儿是因为这儿只有一句话,所以才是src_len,当有多句话时,这儿应该是max_len?
enc_outputs = self.src_emb(enc_inputs)
## 这里就是位置编码,把两者相加放入到了这个函数里面,从这里可以去看一下位置编码函数的实现;3.
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)
##get_attn_pad_mask是为了得到句子中pad的位置信息,给到模型后面,在计算自注意力和交互注意力的时候去掉pad符号的影响,去看一下这个函数 4. 这句话表示什么意思?
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # get_attn_pad_mask告诉后面的层那些位置是被pad填充的
enc_self_attns = []
for layer in self.layers:
## 去看EncoderLayer 层函数 5.
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
## 10.
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn
## 9. Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, tgt_len, d_model]
## get_attn_pad_mask 自注意力层的时候的pad 部分
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
## get_attn_subsequent_mask 这个做的是自注意层的mask部分,就是当前单词之后看不到,使用一个上三角为1的矩阵
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
## 两个矩阵相加,大于0的为1,不大于0的为0,为1的在之后就会被fill到无限小
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
## 这个做的是交互注意力机制中的mask矩阵,enc的输入是k,我去看这个k里面哪些是pad符号,给到后面的模型;注意哦,我q肯定也是有pad符号,但是这里我不在意的,之前说了好多次了哈
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
## 1. 从整体网路结构来看,分为三个部分:编码层,解码层,输出层
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() ## 编码层
self.decoder = Decoder() ## 解码层
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False) ## 输出层 d_model 是我们解码层每个token输出的维度大小,之后会做一个 tgt_vocab_size 大小的softmax # d_model:在这里每一个词表的维度都被设计成了512,而现在这是在预测
# 一个德语单词被翻译成英语,它会对应为那个单词,所以这里输入就是一个单词在词表中的维度,这里的维度是512,在词表中一个单词的维度是512。如果一句话有n个单词,那么在翻译的整个过程中就会调用n次这个全连接函数。然后假设英语单词有100000个,那么这儿的tgt_vocab_size就是1000000个
# 到达这儿,就好像是一个分类任务,看这个单词属于这100000个类中的哪一个类,最后全连接分类的结果然后再进行一个softmax就会得到这100000个单词每个单词的概率。那个那个单词的概率最大,那么我们就把这个德语单词翻译成那个单词。也就是我们这儿的projection就是那个德语单词被翻译成英语单词的词。
def forward(self, enc_inputs, dec_inputs):
# 位置参数是函数里面有一个固定的生成的,不需要人给。
## 这里有两个数据进行输入,一个是enc_inputs 形状为[batch_size, src_len](这儿的enc_inputs是一个矩阵,行代表这句话有几句话,列向量表示的一句话中最多允许有多少个德语单词。),主要是作为编码段的输入,一个dec_inputs,形状为[batch_size, tgt_len],主要是作为解码端的输入(这儿是训练,所以这儿就是标签)
## enc_inputs作为输入 形状为[batch_size, src_len],输出由自己的函数内部指定,想要什么指定输出什么,可以是全部tokens的输出,可以是特定每一层的输出;也可以是中间某些参数的输出;
## enc_outputs就是主要的输出,enc_self_attns这里没记错的是QK转置相乘之后softmax之后的矩阵值,代表的是每个单词和其他单词相关性;
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
## dec_outputs 是decoder主要输出,用于后续的linear映射(既然用于全连接的映射,那么这儿的dec_outputs就是512个维度的); dec_self_attns类比于enc_self_attns 是查看每个单词对decoder中输入的其余单词的相关性
# (也就是当decoder已经翻译到机器学习中的学时,此时学和机、器直接的相关性,由于在真实翻译中,我们是不可能知道学后面是习的,所以这个只有翻译的这个单词和前面这个单词之间的相关性。);dec_enc_attns是decoder中每个单词对encoder中每个单词的相关性
# (这个就相当于开了天眼,它知道这个最终翻译的最终结果,比如,现在才翻译到学,它就已经知道最后一个是习,并且早就计算了几个字之间的相关性。);
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs) # 提问:这儿的参数中,为什么解码器需要编码器的输入,它不是只需要编码器的输出吗?
## dec_outputs做映射到词表大小
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
if __name__ == '__main__':
## 句子的输入部分,
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
# Transformer Parameters
# Padding Should be Zero
## 构建词表
# 编码端的词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4}
src_vocab_size = len(src_vocab) # src_vocab_size:实际情况下,它的长度应该是所有德语单词的个数
# 解码端的词表
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6}
tgt_vocab_size = len(tgt_vocab) # 实际情况下,它应该是所有英语单词个数
src_len = 5 # length of source 编码端的输入长度
tgt_len = 5 # length of target 解码端的输入长度
## 模型参数
d_model = 512 # Embedding Size 每一个字符转化成Embedding的大小
d_ff = 2048 # FeedForward dimension 前馈神经网络映射到多少维度
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer encoder和decoder的个数,这个设置的是6个encoder和decoder堆叠在一起(encoder和decoder的个数必须保持一样吗)
n_heads = 8 # number of heads in Multi-Head Attention 多头注意力机制时,把头分为几个,这里说的是分为8个
model = Transformer()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
enc_inputs, dec_inputs, target_batch = make_batch(sentences)
for epoch in range(20):
optimizer.zero_grad()
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, target_batch.contiguous().view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
二、部分代码剖析
1、主函数if name == ‘main’:
if __name__ == '__main__':
## 句子的输入部分,
sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E']
# Transformer Parameters
# Padding Should be Zero
## 构建词表
# 编码端的词表
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4}
src_vocab_size = len(src_vocab) # src_vocab_size:实际情况下,它的长度应该是所有德语单词的个数
# 解码端的词表
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6}
tgt_vocab_size = len(tgt_vocab) # 实际情况下,它应该是所有英语单词个数
src_len = 5 # length of source 编码端的输入长度
tgt_len = 5 # length of target 解码端的输入长度
## 模型参数
d_model = 512 # Embedding Size 每一个字符转化成Embedding的大小
d_ff = 2048 # FeedForward dimension 前馈神经网络映射到多少维度
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer encoder和decoder的个数,这个设置的是6个encoder和decoder堆叠在一起(encoder和decoder的个数必须保持一样吗)
n_heads = 8 # number of heads in Multi-Head Attention 多头注意力机制时,把头分为几个,这里说的是分为8个
model = Transformer()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
enc_inputs, dec_inputs, target_batch = make_batch(sentences)
for epoch in range(20):
optimizer.zero_grad()
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, target_batch.contiguous().view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
1.1
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/342670
推荐阅读
相关标签

