
- 1ArcGIS Engine10.0轻松入门级教程(4)——基本功能开发_arcengine movelinefeedbackclass
- 2java分布式事务——最终一致性,最大努力通知总结!_分布式事务中的最大努力通知思想
- 3python tokenizer是什么_Python tokenizer包_程序模块 - PyPI - Python中文网
- 4wordpress开源代码的一次白盒审计_开源代码安全审计
- 5大厂偏爱的Agent技术究竟是个啥_azure agent 是通过什么技术和后端通讯
- 6【gpt】免费部署个人gpt平台(无需tz)_gpt免费
- 7白天研究生系列:炼丹专题第三集《本地部署大语言模型保姆级教程——以ChatGLM-6B为例》_chatglm4-6b
- 8在Atlas 200 DK(Soc=Ascend 310)快速上手自定义模型训练、部署与推理_aclliteresource
- 9Python 零基础学习指南_momodel
- 10Python和人工智能的关系_人工智能程序是关联独立
如何从零开始用Keras开发一个机器翻译系统_keras做机器翻译
赞
踩
摘要: 作者拥有大量的实战经验,快来跟着作者开发属于你自己的神经网络翻译系统吧。
点此查看原文:http://click.aliyun.com/m/42632/
机器翻译是一项非常具有挑战性的任务,按照传统方法是使用高度复杂的语言知识开发的大型统计模型。而神经网络机器翻译是利用深度神经网络来解决机器翻译问题。
在本教程中,你将了解如何开发一个将德语短语翻译成英语的神经机器翻译系统,具体如下:
如何清理和准备数据,以及训练神经机器翻译系统。
如何开发一个机器翻译的编码解码器模型。
如何使用训练过的模型对新输入短语进行推理,并评估模型技巧。

教程概览:
这个教程分成了以下四个部分:
1.德文转译英文的数据集
2.准备文本数据
3.训练神经翻译模型
4.评估神经翻译模型
Python开发环境:
本教程假设你已经安装了Python 3 SciPy环境
你必须安装了带有TensorFlow 或者Theano 后台 的Keras (2.0或者更高版本)
如果你在开发环境方面需要帮助,请看如下的文章:
德文转译英文的数据集
在本教程中,我们将使用一个德文对应英文术语的数据集。
这个数据集是来自manythings.org网站的tatoeba项目的例子。该数据集是由德文的短语和英文的对应组成的,并且目的是使用Anki的教学卡片软件。
这个页面提供了一个由包含多语言匹配对的列表:
下载数据集到当前的工作目录并且解压缩;例如:

你将会得到一个叫 deu.txt的包含152820个英文到德文短语的匹配对,一对一行,并用一个标签把德文和英文相互分隔开。
例如,这个文件的前五行如下:

我们将用给定的一组德文单词作为输入来表达预测问题,翻译或预测与其对应的英文的单词序列。
我们将要开发的模型适合一些初级德语短语。
准备文本数据:
下一步是准备好文本数据。
查看原始数据,并注意在数据清理操作中我们可能需要处理你所遇到的的问题。
例如,以下是我在回顾原始数据时的观察所得:
1.有标点
2.文本包含大小写字母
3.有德文的特殊字符
4.有用不同德文翻译的重复英文短语
5.该文件是按句子长度排列的,贯穿全文有一些很长的句子
数据准备分为两个部分:
1.清理文本
2.拆分文本
1. 清理文本
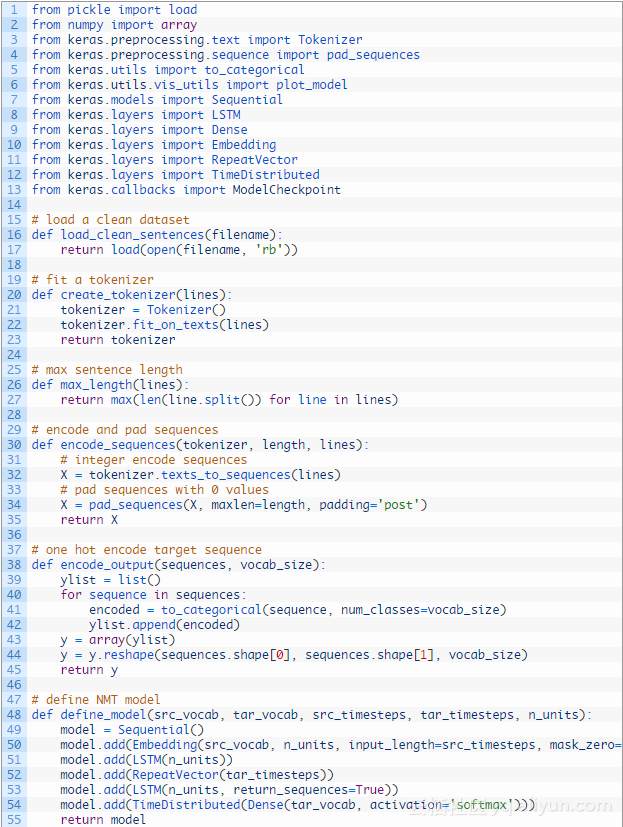
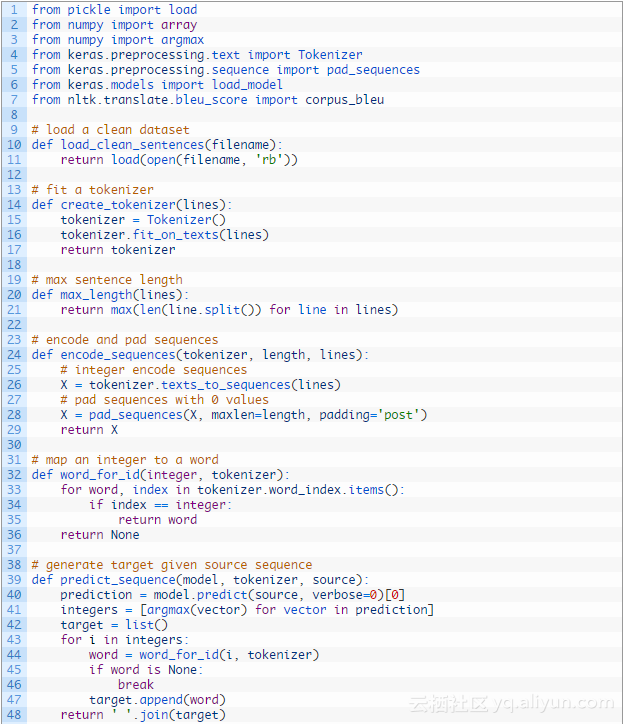
首先,我们必须以保存Unicode德文字符的方式加载数据。下面称为load_doc()的函数将要加载一个BLOB文本的文件。
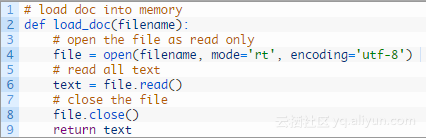
每行包含一对短语,先是英文,然后是德文,用制表符分隔。
我们必须把加载的文本按行拆分,然后用短语拆分。下面的函数to_pairs()将拆分加载的文本。

现在准备好清理文本中的句子了,我们将执行的具体清洗操作步骤如下:
删除所有不可打印字符。
删除所有标点符号。
将所有Unicode字符标准化为ASCII(例如拉丁字符)。
标准化为小写字母。
删除不是字母的所有剩余标识符。
下面的clean_pairs()函数执行如下操作:
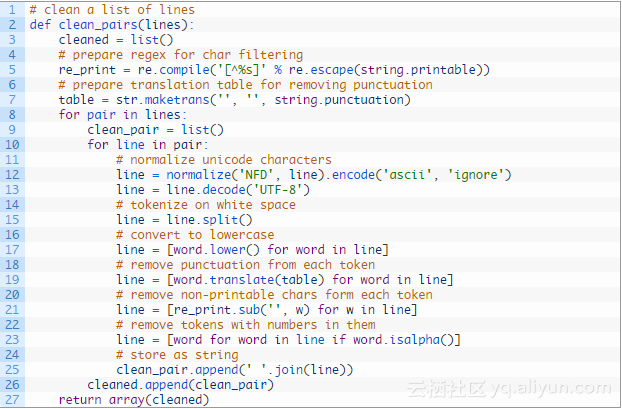
最后,可以将短语对的列表保存到可以使用的文件中
save_clean_data()函数用API来保存清理文本列表到文件中。
下面是完整例子:
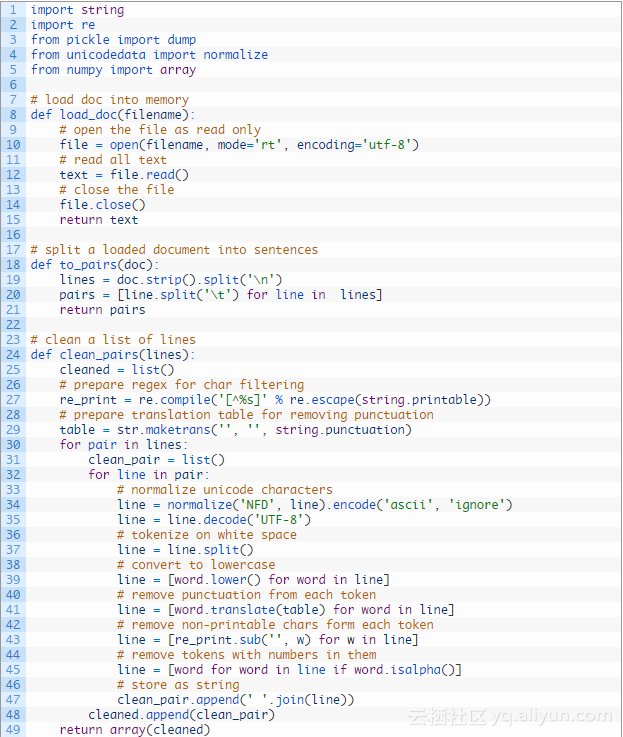
运行该示例,用清理过的english-german.pkl文本在当前目录中创建一个新文件。
打印一些清理文本的例子,以便在运行结束时对其进行评估,这样就能确认清理操作是否按预期执行的。

2. Split Text
清理过的数据包含了超过150000个短语匹配对,到文件的最后会有一些匹配对是和长的。
这是一些用来开发较小的翻译模型的例子。模型的复杂度随着实例的数量、短语长度和词汇量的增加而增加。
尽管我们有一个很好的建模翻译的数据集,但我们将稍微简化这个问题,以大幅度减少所需模型的大小,并且也相应地减少所需的训练时间来适应模型。
我们将通过减少数据集为文件中的前10000个示例来简化这个问题;此外,我们将把前9000个作为培训的例子,剩下的1000个例子来测试拟合模型。
下面是加载清理过的数据,并且将其分割,然后将分割部分保存到新文件的完整示例。
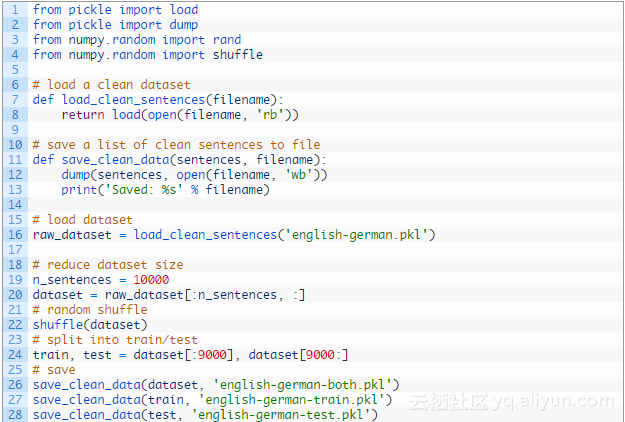
运行该示例创建三个新文件:english-german-both.pkl文件包含所有的训练和测试的例子,我们可以用这些例子来定义这些问题的参数,如最大的短语长度和词汇量,和用于训练和测试数据集的english-german-train.pkl文件和english-german-test.pkl文件。
我们目前准备好开始开发自己的翻译模型了。
训练神经翻译模型
在这部分,我们将开发一个翻译模型。
这涉及到加载和准备清理过的用于建模、定义以及训练模型的文本数据。
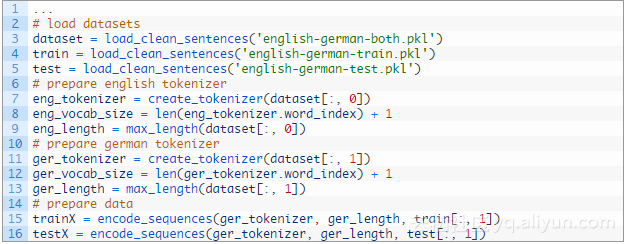
让我们通过加载数据集开始,这样就能准备数据了。下面被叫做load_clean_sentences()的函数,可以被用来加载训练、测试以及两种语言的数据集。

我们将使用“两者”或者训练和测试数据集的组合来定义此类问题的最大长度和词汇表。
另外,我们可以仅从训练数据集中定义这些属性,并缩短在测试集中过长或者不在词汇表中的示例。
我们可以使用Keras Tokenize类来映射单词到整数,如果建模需要的话。我们将为英文序列和德文序列使用分隔标记。这个create_tokenizer()函数将在一个短语列表上训练一个标记。

相似地,max_length()函数将找到在短语列表中最常的序列的长度。

我们可以调用带着组合数据集的函数来准备标记、词汇量大小和最大长度,同时给英文和德文的短语。
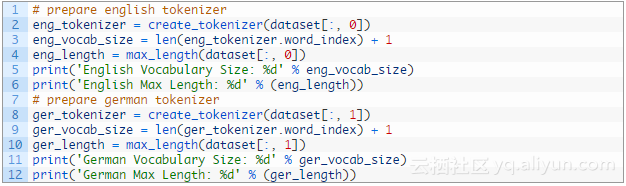
我们现在已经准备好训练数据集了。
每个输入和输出序列必须编码成整数,并填充到最大短语长度。这是因为我们将使用一个单词嵌入给输入序列和一个热编码输出序列。下面的函数encode_sequences()将执行这些操作并且返回结果。

输出序列需要是一个热编码的。这是因为该模型将预测词汇表中每个单词作为输出的概率。
下面的encode_output()函数将热编码英文输出序列。

我们可以利用这两个函数,准备好训练和测试数据集用于训练模型。

关于这个问题,我们将用编解码LSTM。在这个结构中,输入序列通过一个被称作前-后的模型进行编码,然后通过一个被称作后台模型的解码器一个单词一个单词的进行解码。
下面的define_model()函数定义了模型,并且用一些参数来配置模型,如如输入出的单词表的大小,输入输出短语的最大长度,用于配置模型的存储单元的数量。
该模型采用随机梯度下降的高效的Adam方法进行训练,最大限度地减少了分类损失函数,因为我们把预测问题框架化为多类分类。
对于这个问题,模型配置没有得到优化,这意味着你有足够的机会调整它,并提高翻译的技巧。
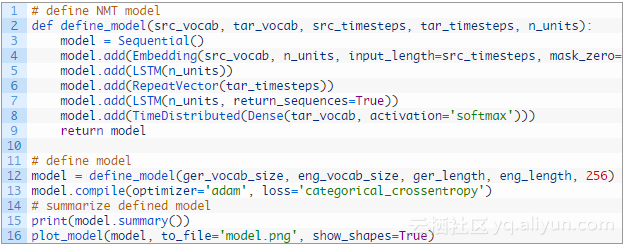
最后我们可以训练模型了。
我们训练了30个时期的模型和每64个实例为一批的多个批次。
我们使用检查点确保每次测试集上的模型技术的提高,将模型保存到文件中。

我们可以把所有这些结合在一起,并拟合神经翻译模型。
下面列出完整的示例。
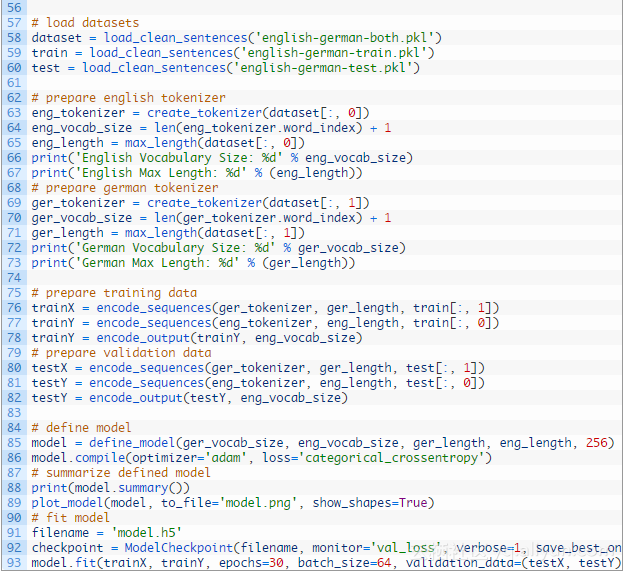
运行示例首先打印数据集的参数汇总,如词汇表大小和最大短语长度。

接下来,打印定义的模型的一览,允许我们确认模型配置:
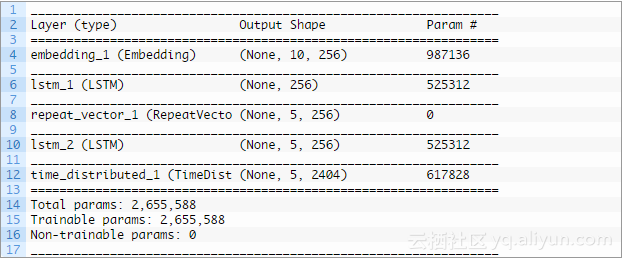
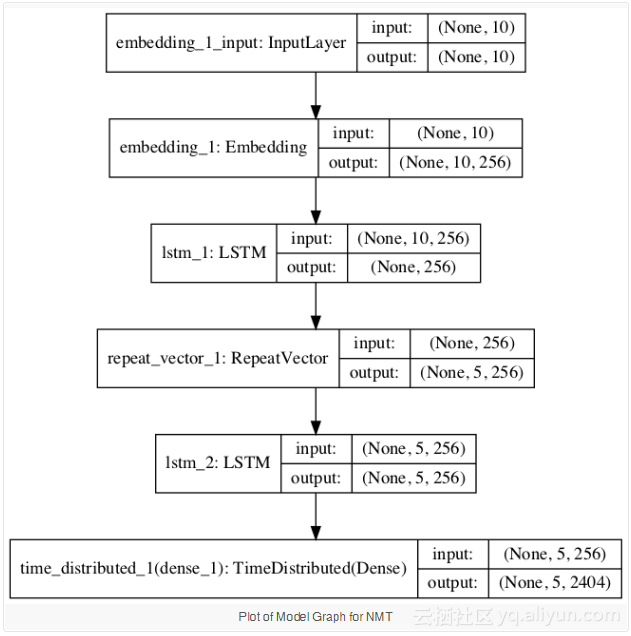
还创建了模型的一个部分,为模型配置提供了另一个视角:
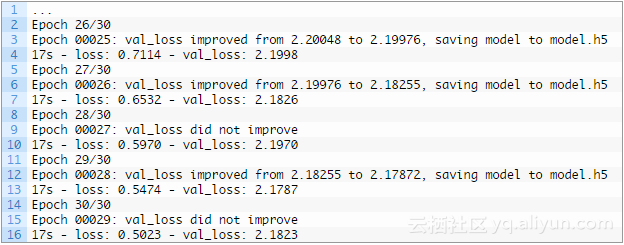
其次,对模型进行训练。以目前的CPU硬件每一个时期大约需要30秒;
在运行过程中,将模型保存到文件model.h5中,为了准备下一步的推论。
Evaluate Neural Translation Model
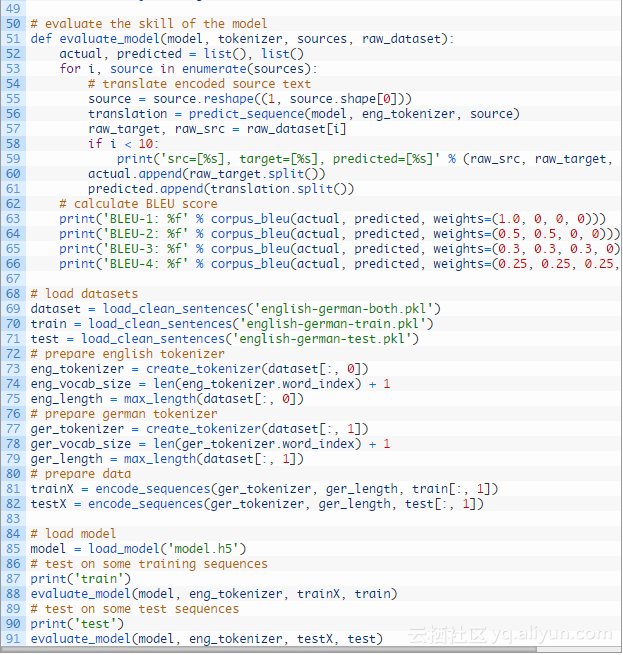
我们将在训练和测试的数据集上评估模型这个模型在训练数据集上将会表现的非常好,并且已经推广到在测试数据集上执行良好。理想情况下,我们将使用一个单独的验证数据集来帮助训练过程中的模型选择,而不是测试集。必须像以前那样加载和准备清理过的数据集。
其次,必须在训练过程中保存最佳模型。

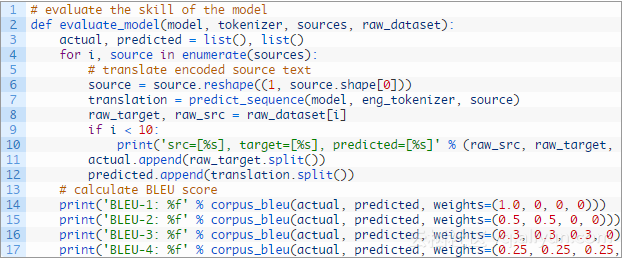
评估过程包括两个步骤:首先生成一个翻译过的输出序列,然后为许多输入示例重复这个过程,并在多个案例中总结该模型的技巧。
从推论开始,该模型可以一次性地预测整个输出序列。
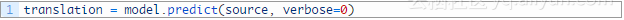
这将是一个我们能在标记(tokenizer)中枚举和查找的整数序列,以便映射回到对应的单词。
下面称为word_for_id()的函数,将执行此反向映射。

我们可以对转换中的每个整数执行此映射,并将返回一个单词字符串结果。
下面的函数predict_sequence()给一个单一编码过的源短语执行此操作。

接下来,可以对数据集中的每个源短语重复操作,并将预测结果与预期的目标短语进行比较。
可以将这些比较打印到屏幕上,以了解模型在实践中的执行情况。
我们也计算了BLEU得分以得到量化了的概念模型执行的质量。
下面的evaluate_model()函数实现这个功能,为在提供的数据集中的每个短语调用上述predict_sequence()函数。
将所有这些结合起来,并在训练和测试数据集上评估所加载的模型。
以下是完整的代码清单:
运行示例首先打印源文本、预期和预测翻译的示例,以及训练数据集的分数,然后是测试数据集。考虑到数据集的随机重排和神经网络的随机性,你的具体结果会有所不同。
首先查看测试数据集的结果,我们可以看到翻译是可读的,而且大部分是正确的
例如:“ich liebe dich”被正确地翻译成了“i love you”。我们也能看到这些翻译的结果不是太完美,“ich konnte nicht gehen”被翻译成了“i cant go”,而不是希望的“i couldnt walk”。
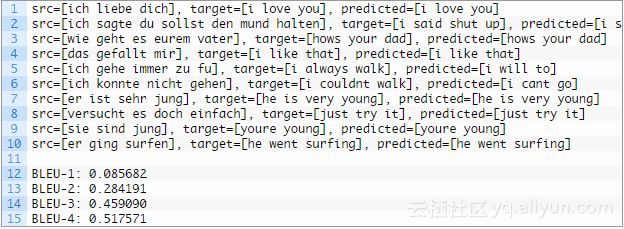
查看测试集上的结果,确实看到可接受的翻译结果,这不是一项容易的任务。
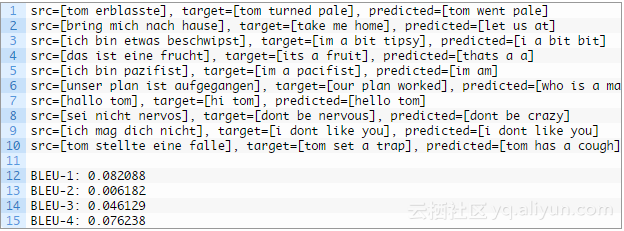
例如,我们可以看到“ich mag dich nicht”正确地翻译为“i dont like you”。也看到一些比较差的翻译,一个可以让该模型可能受到进一步调整的好例子,如“ich bin etwas beschwipst”翻译成了“i a bit bit”,而不是所期望的“im a bit tipsy”。
实现了bleu-4得分为0.076238,提供一个基本的技巧来对模型进行进一步的改进。
扫描二维码,获取更多资讯:


