
- 1Android 之一 Android Studio 安装、配置等新手入门 + 百度地图定位 + 移动摇杆 的实现_ndk was located by using ndk.dir property. this me
- 2UI 自动化测试框架:PO 模式+数据驱动 【详解版】_po框架
- 3UTAustin最新提出!无相机姿态40秒重建3DGS方法_无需相机参数三维重建
- 4【小程序开发必备】微信小程序常用API全介绍,附示例代码和使用场景_微信小程序代码大全
- 5Mac OS X 10.10 Yosemite 关闭Dashboard和Spotlight_spotlightv100能删除吗
- 6Pycharm报错torch.cuda.OutOfMemoryError: CUDA out of memory.
- 7Drools基础篇-01-规则引擎简单介绍_drools规则引擎
- 8华为云注册登录之图像标签识别_华为云aksk登录
- 9DDoS攻击原理是什么?DDoS攻击原理及防护措施介绍_ddos 不挂科
- 10自动化测试(UI)----PO设计模式_自动化测试模式
今日arXiv最热联邦学习论文:通信成本降低94%,中科院计算所发布个性化联邦学习方法
赞
踩
引言:你的隐私,联邦来守护!
想象一下,未来你的手机就像一位贴心的私人助理,能够洞察你的喜好、日程,甚至预测你的情绪。听起来很棒,但你可能会担心隐私泄露的问题。别担心,最近一种名为“联邦学习”的创新技术或许能解决这个问题。它让各个手机上的AI模型只需相互学习彼此的经验,而无需直接交换原始数据,就像我们协作学习时只分享心得和方法,而不抄袭他人作业。这样既能让AI变聪明,又能保护用户隐私。
然而,联邦学习也面临挑战:模型之间交换的参数数量庞大,通信成本很高。但中科院计算所最近提出的“FUELS”方法或许能解决这些问题。它通过寻找数据间的相似性,帮助模型更好地理解彼此,还能节约94%的通信成本。
个性化联邦学习技术让AI更懂你,同时很好地保护了隐私,还让AI变得更加聪明高效。这项技术的出现,让我们对未来AI的发展有了更多期待。相信在不久的将来,我们就能享受到更加智能、安全、高效的AI助手带来的便利!
论文标题:
Personalized Federated Learning for Spatio-Temporal Forecasting: A Dual Semantic Alignment-Based Contrastive Approach
论文链接:
https://arxiv.org/pdf/2404.03702.pdf
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
方法详解:双重语义对齐的对比学习方法
本文提出的 FUELS 框架主要包括三个关键技术:编码器与解码器、客户端内对比任务和客户端间对比任务。下面将逐一对其进行详细介绍。

1. 编码器与解码器
在 FUELS 中预测模型 被拆分为两个部分:编码器 和解码器 。
编码器的作用是将输入数据 映射到一个 维的隐藏空间。具体而言,编码器采用两个门控循环单元(GRU)模型来分别提取输入数据的短期特征和周期性特征,记为 和 , 和 分别表示输入数据 的短期子序列和周期性子序列。编码器的输出表示为 ,论文中将短期特征 GRU 和周期特征 GRU 编码的结果级联生成编码器的表示:
解码器以编码器输出 作为输入,生成最终的预测结果 ,论文中采用简单的全连接层作为解码器结构。
2. 客户端内对比任务
客户端内对比任务的目的是通过对齐不同时间表示的语义相似性,将时间异质性引入到隐空间表示中。为此,本文设计了一个困难负样本过滤模块,用于自适应对齐真实的负样本对。
作者首先采用时空偏移方式生成客户端 的增广数据集 。具体而言,对于客户端中的数据 生成对应的增广样本 ,其表示记为 ,其中第 行表示 第 个时间戳的时间表示。
然后作者通过一个可学习的过滤矩阵 得到过滤之后的相似矩阵 , 被用于区分困难负样本和真实负样本:
上面的过程可以筛选出时间戳不同但语义相似的表征。对比任务的目标是排斥语义不同的表征,从而有效地为表征注入时间异质性。
3. 客户端间对比任务
客户端间对比任务旨在通过共享不同客户端的语义原型,在保留空间异质性的同时实现知识共享。为此作者将客户端所有数据表示的均值定义为客户端级语义原型 :
然后设计了一种基于 Jensen-Shannon 散度(JSD)的聚合机制,用于对齐不同客户端的原型,并为每个客户端生成定制化的全局正负原型。具体而言,服务器根据 JSD 值将所有其他客户端划分为第 个客户端的正样本集 和负样本集 。最后通过平均聚合得到全局正负原型 和 :
综上,FUELS 的本地训练目标可表示为最小化三个损失函数组成的联合损失函数:
通过联合优化三个损失函数,可以使本地模型在注入时空异质性的同时,实现较好的预测性能。
除此之外,本文还对 FUELS 的泛化性、收敛性与复杂度进行理论分析,以此证明 FUELS 的有效性。
实验:FUELS vs. 主流联邦学习方法
1. 个性化联邦实验设置
本文在三个真实的数据集上评估了 FUELS 的性能,包括短信服务(SMS)、语音呼叫(Call)和互联网服务(Net)。此外,还在 METR-LA 交通流量预测基准数据集上进行了实验。
实验中将 FUELS 与6种主流联邦学习方法进行了比较,包括FedAvg、FedProx、FedRep、PerFedAvg、pFedMe 和 FedDA。为了全面评估模型性能,本文采用了均方误差(MSE)和平均绝对误差(MAE)两个评价指标。
在超参数设置方面,编码器使用具有128个单元的 GRU 模型,解码器采用全连接层。设定了合理的本地批大小、窗口大小、温度系数等参数。此外,客户端选择比例 设为0.2,训练轮数为200轮。
2. 主要实验结果
实验结果表明,FUELS 在所有数据集上都取得了优于基线方法的性能,且通信开销大幅降低。在三个数据集上的平均 MSE 比最佳基线 PerFedAvg 降低了9.8%,平均 MAE 降低6.7%。同时,FUELS 的通信参数量比基线方法平均减少了94%。
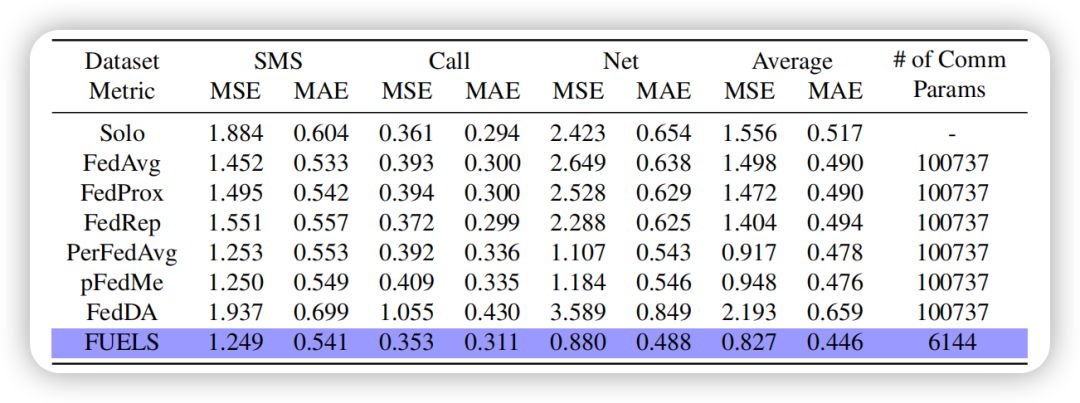
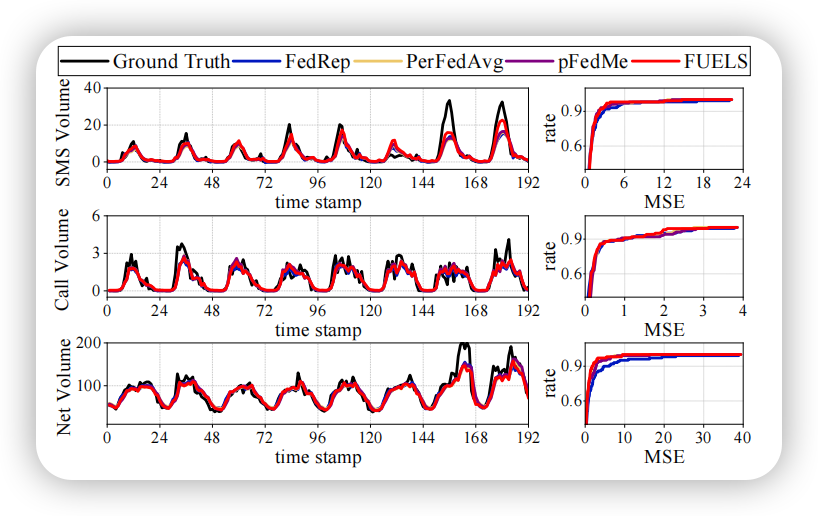
本文还可视化了各方法的预测值曲线和 MSE 的累积分布函数(CDF)曲线。结果显示 FUELS 在各数据集的波动序列上,都能给出更加准确的预测。此外,FUELS 的 MSE 分布更集中在较低的区域,如在 Net 数据集上,87%的客户端 MSE 低于1.5,而 FedRep 等方法的比例仅为72%~81%。
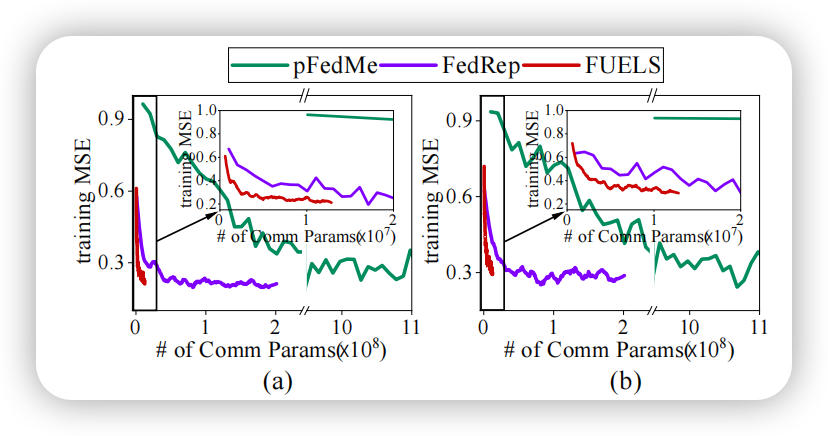
本文进一步分析了各方法在不同通信成本下的性能变化趋势。结果发现,在相同MSE水平下 FUELS 的通信开销显著低于其他个性化联邦学习方法,体现出其出色的通信效率。
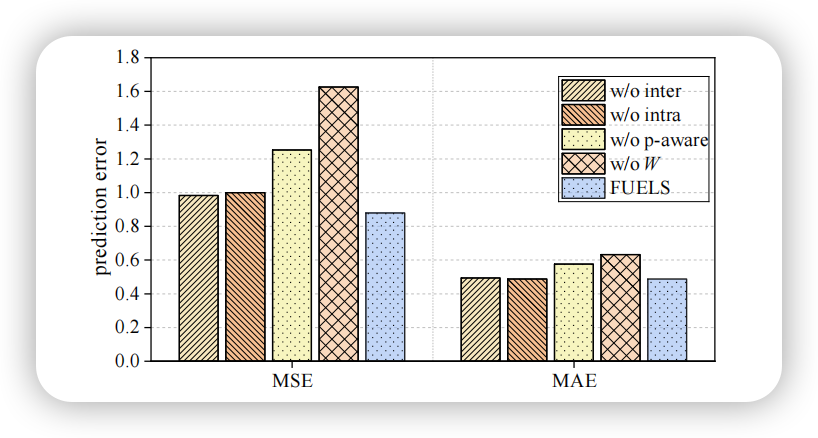
3. 不同组件对FUELS的影响
为了验证 FUELS 不同组件的有效性,本文设计了一系列消融实验。
首先,分别移除了客户端内和客户端间对比任务,发现性能都有所下降,表明两类对比任务可从不同角度改进本地训练。其次,用拼接方式生成原型,发现性能略有下降,且通信量大幅上升,说明周期性感知原型的优越性。然后去除了动态过滤模块,性能出现明显下滑,表明该机制可有效挑选出真正的负样本。
此外,本文还考察了一些关键参数的影响,包括相似度阈值 、温度系数 以及损失权重 。结果表明, 取 JSD 值的中位数, 取0.02, 取5时,FUELS 能取得较好的性能。
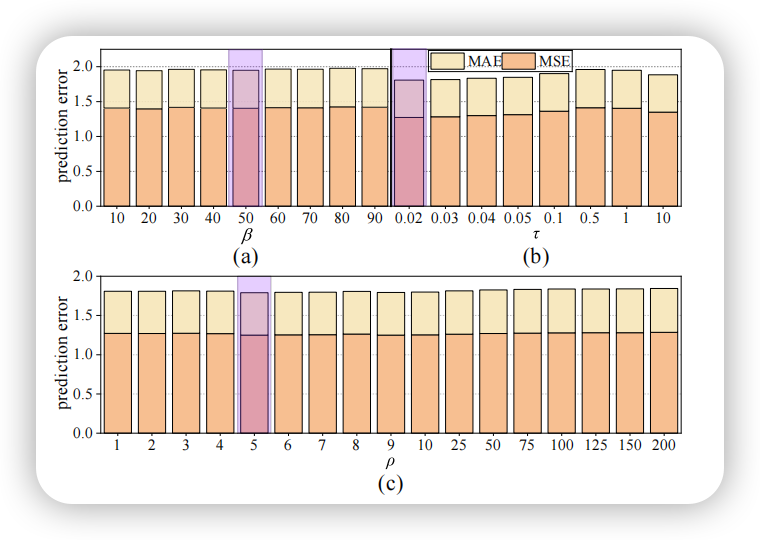
最后,实验对比了原型与原始数据的相关性,并可视化了过滤矩阵,进一步验证了语义对齐机制的有效性。同时,本文还将 FUELS 与差分隐私等机制结合,在隐私保护的同时保持了较好的性能表现。
总结
FUELS 通过语义相似性自适应对齐正负样本对,利用客户端内和客户端间的对比任务,将时空异质性引入表示空间,同时采用周期性感知原型作为通信载体,在大幅降低通信开销的同时实现了显著的性能提升。该方法在理论和实验上都得到了充分的验证,为个性化联邦学习在时空预测等领域的应用提供了新的思路。





