
- 1算法-动态规划入门(C++实现)_c++动态规划
- 2Guitar Pro8软件激活码许可证如何获取?最新2024年免费教学步骤_guitarpro8许可证
- 3CNN中的卷积的作用及原理通俗理解_添加卷积cnn的作用是什么?
- 4HybridCLR热更新介绍
- 5用I/O流建立一个text.txt并写入字符。_用io流以文本方式建立一个文件txt,写入字符
- 6Redis集群原理和总结_redis的无主集群
- 7网络原理——TCP/IP--数据链路层,DNS
- 8Java安全--CC1的补充和CC6_yso cc6
- 9计划有变,国内应用厂商都在适配HarmonyOS?_haromony os next 适配情况_鸣潮适配鸿蒙吗
- 10基于OpenHarmony 系统通过S7协议读取西门子PLC数据_go plc s7
MQ——Kafka主题与分区原理_kafka主题和分区的关系
赞
踩
摘要
主题和分区是Kafka 的两个核心概念,前面章节中讲述的生产者和消费者的设计理念所针对的都是主题和分区层面的操作。主题作为消息的归类,可以再细分为一个或多个分区,分区也可以看作对消息的二次归类。分区的划分不仅为Kafka提供了可伸缩性、水平扩展的功能,还通过多副本机制来为Kafka提供数据冗余以提高数据可靠性。
从Kafka的底层实现来说,主题和分区都是逻辑上的概念,分区可以有一至多个副本,每个副本对应一个日志文件,每个日志文件对应一至多个日志分段(LogSegment),每个日志分段还可以细分为索引文件、日志存储文件和快照文件等。不过对于使用Kafka进行消息收发的普通用户而言,了解到分区这一层面足以应对大部分的使用场景。
主题的管理
主题的管理包括创建主题、查看主题信息、修改主题和删除主题等操作。可以通过 Kafka提供的 kafka-topics.sh 脚本来执行这些操作,这个脚本位于SKAFKA_HOME/bin/目录下,其核心代码仅有一行,具体如下, i' ...
exec $ (dirname $0)/ kafka-run-class.sh kafka. admin. TopicCommand "$@"
可以看到其实质上是调用了kafka.admin.TopicCommand类来执行主题管理的操作。主题的管理并非只有使用kafka-topics.sh 脚本这一种方式,我们还可以通过KafkaAdminClient 的方式实现(这种方式实质上是通过发送CreateTopicsRequest,DeleteTopicsRequest 等请求来实现的),甚至我们还可以通过直接操纵日志文件和ZooKeeper 节点来实现。下面按照创建主题查看主题信息、修改主题、删除主题的顺序来介绍其中的操作细节。
创建主题
如果 broker端配置参数auto.create.topics.enable设置为true(默认值就是true)那么当生产者向一个尚未创建的主题发送消息时,会自动创建一个分区数为num.partition(默认值为1)、副本因子为default.replication.factor(默认值为1)的主题。除此之外,当一个消费者开始从未知主题中读取消息时,或者当任意一个客户端向未知主题发送元数据请求时,都会按照配置参数num.partitions和 default.replication.factor的值来创建一个相应的主题。很多时候,这种自动创建主题的行为都是非预期的。除非有特殊应用需求,否则不建议将auto.create.topics.enable参数设置为true,这个参数会增加主题的管理与维护的难度。
更加推荐也更加通用的方式是通过kafka-topics.sh脚本来创建主题。在1.3节演示消息的生产与消费时就通过这种方式创建了一个分区数为4、副本因子为3的主题topic-demo。下面通过创建另一个主题topic-create来回顾一下这种创建主题的方式,示例如下:


主题、分区、副本和Log(日志)的关系如图4-1所示,主题和分区都是提供给上层用户的抽象,而在副本层面或更加确切地说是Log层面才有实际物理上的存在。同一个分区中的多个副本必须分布在不同的broker 中,这样才能提供有效的数据冗余。对于示例中的分区数为4、副本因子为2、broker数为3的情况下,按照2、3、3的分区副本个数分配给各个 broker 是最优的选择。再比如在分区数为3、副本因子为3,并且. broker数同样为3的情况下,分配3、3、3的分区副本个数给各个broker是最优的选择,也就是每个broker中都拥有所有分区的一个副本。
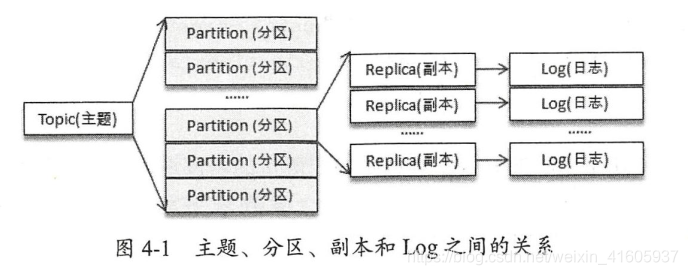
分区副本的分配
- 生产者的分区分配是指为每条消息指定其所要发往的分区,
- 消费者中的分区分配是指为消费者指定其可以消费消息的分区,
- 而这里的分区分配是指为集群制定创建主题时的分区副本分配方案,即在哪个broker 中创建哪些分区的副本。
查看主题
kafka-topics.sh脚本有5种指令类型: create、list、describe、alter和 delete。其中 list和describe 指令可以用来方便地查看主题信息,在前面的内容中我们已经接触过了describe指令的用法,本节会对其做更细致的讲述。
修改主题
当一个主题被创建之后,依然允许我们对其做一定的修改,比如修改分区个数、修改配置等,这个修改的功能就是由kafka-topics.sh 脚本中的alter指令提供的。

目前Kafka只支持增加分区数而不支持减少分区数。比如我们再将主题topic-confi g的分区数修改为1,就会报出InvalidPartitionException的异常。
为什么不支持减少分区?
按照Kafka现有的代码逻辑,此功能完全可以实现,不过也会使代码的复杂度急剧增大。实现此功能需要考虑的因素很多,比如删除的分区中的消息该如何处理?如果随着分区一起消失则消息的可靠性得不到保障;如果需要保留则又需要考虑如何保留。直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于Spark、Flink 这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入现有的分区,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、事务性问题,以及分区和副本的状态机切换问题都是不得不面对的。反观这个功能的收益点却是很低的,如果真的需要实现此类功能,则完全可以重新创建一个分区数较小的主题,然后将现有主题中的消息按照既定的逻辑复制过去即可。
配置管理
kafka-configs.sh脚本是专门用来对配置进行操作的,这里的操作是指在运行状态下修改原有的配置,如此可以达到动态变更的目的。kafka-configs.sh 脚本包含变更配置alter和查看配置describe这两种指令类型。同使用kafka-topics.sh脚本变更配置的原则一样,增、删、改的行为都可以看作变更操作,不过kafka-configs.sh脚本不仅可以支持操作主题相关的配置,还可以支持操作broker、用户和客户端这3个类型的配置。
主题端参数
与主题相关的所有配置参数在 bro ker面都有对应参数,比如主题端参数cleanuppolicy对应 bro ke层面的log.cleanup.policy。如果没有修改过主题的任何配置参数,那么就会使用bro ker端的对应参数作为其默认值。可以在创建主题时覆盖相应参数的默认值,也可以在创建完主题之后变更相应参数的默认值。比如在创建主题的时候没有指定cleanup.policy 参数的值,那么就使用log.cleanup.policy 参数所配置的值作为cleanup.policy的值。

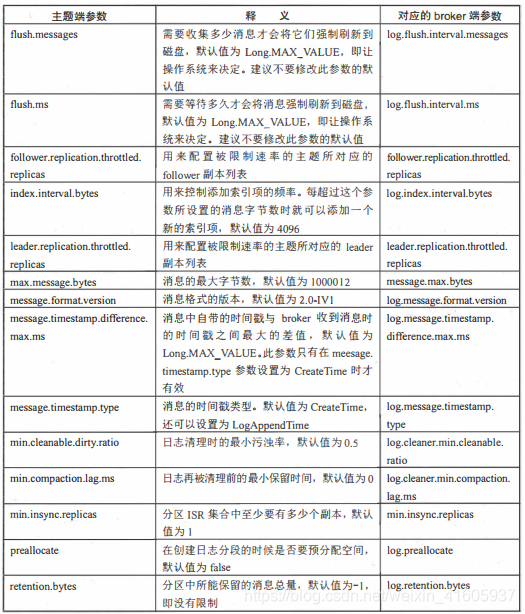
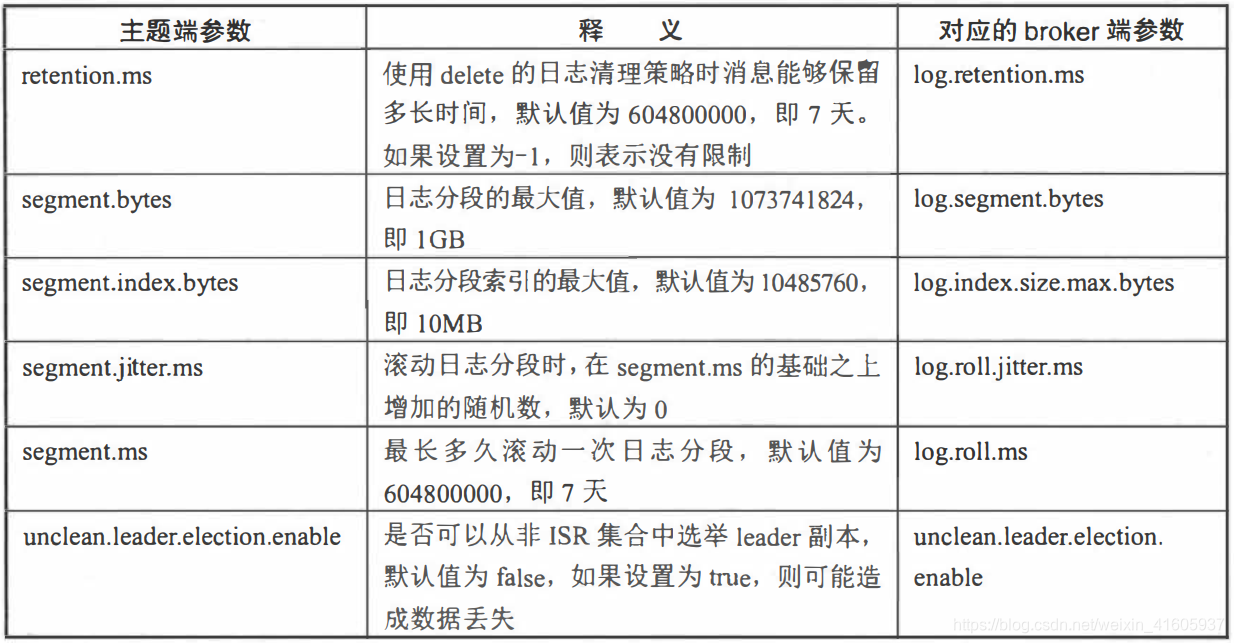
删除主题
如果确定不再使用一个主题,那么最好的方式是将其删除,这样可以释放一些资源,比如磁盘、文件句柄等。kafka-topics.sh 脚本中的delete指令就可以用来删除主题,比如删除一个主题topic-delete:

分区的管理
优先副本的选举
分区使用多副本机制来提升可靠性,但只有leader副本对外提供读写服务,而follower 副本只负责在内部进行消息的同步。如果一个分区的leader 副本不可用,那么就意味着整个分区变得不可用,此时就需要Kafka 从剩余的follower 副本中挑选一个新的leader副本来继续对外提供服务。虽然不够严谨,但从某种程度上说,broker节点中 leader副本个数的多少决定了这个节点负载的高低。
在创建主题的时候,该主题的分区及副本会尽可能均匀地分布到Kafka集群的各个broker节点上,对应的leader副本的分配也比较均匀。比如我们使用kafka-topics.sh脚本创建一个分区数为3、副本因子为3的主题topic-partitions,创建之后的分布信息如下:

可以看到leader副本均匀分布在 brokerId为0、1、2的broker节点之中。针对同一个分区而言,同一个 broker 节点中不可能出现它的多个副本,即Kafka集群的一个broker中最多只能有它的一个副本,我们可以将leader副本所在的 broker节点叫作分区的leader节点,而 follower副本所在的broker节点叫作分区的follower节点。
随着时间的更替,Kafka集群的broker节点不可避免地会遇到宕机或崩溃的问题,当分区的leader节点发生故障时,其中一个follower节点就会成为新的leader 节点,这样就会导致集群的负载不均衡,从而影响整体的健壮性和稳定性。当原来的leader节点恢复之后重新加入集群时,它只能成为一个新的follower节点而不再对外提供服务。比如我们将brokerld为2的节点重启,那么主题topic-partitions 新的分布信息如下:

可以看到原本分区1的 leader节点为2,现在变成了0,如此一来原本均衡的负载变成了失衡:节点0的负载最高,而节点1的负载最低。
为了能够有效地治理负载失衡的情况,Kafka引入了优先副本(preferred replica)的概念。
所谓的优先副本是指在AR集合列表中的第一个副本。比如上出土必top1ICHp相rt犯下,优牛副的AR集合列表(Replicas)为[1,2,0],那么分区0的优先副本即为1。理想情况下,优先副本就是该分区的leader副本,所以也可以称之为preferred leader。Kafka要确保所有主题的优先副本在Kafka集群中均匀分布,这样就保证了所有分区的leader均衡分布。如果leader分布过于集中,就会造成集群负载不均衡。
所谓的优先副本的选举是指通过一定的方式促使优先副本选举为leader副本,以此来促进集群的负载均衡,这一行为也可以称为“分区平衡”。
需要注意的是,分区平衡并不意味着Kafka集群的负载均衡,因为还要考虑集群中的分区分配是否均衡。更进一步,每个分区的leader副本的负载也是各不相同的,有些leader副本的负载很高,比如需要承载TPS为30000的负荷,而有些leader副本只需承载个位数的负荷。也就是说,就算集群中的分区分配均衡、leader分配均衡,也并不能确保整个集群的负载就是均衡的,还需要其他一些硬性的指标来做进一步的衡量,。
分区重分配
- 当集群中的一个节点突然宕机下线时,如果节点上的分区是单副本的,那么这些分区就变得不可用了,在节点恢复前,相应的数据也就处于丢失状态;如果节点上的分区是多副本的,那么位于这个节点上的 leader副本的角色会转交到集群的其他f ollower副本中。总而言之,这个节点上的分区副本都已经处于功能失效的状态,Kaf ka并不会将这些失效的分区副本自动地迁移到集群中剩余的可用broker节点上,如果放任不管,则不仅会影响整个集群的均衡负载,还会影响整体服务的可用性和可靠性。
- 当要对集群中的一个节点进行有计划的下线操作时,为了保证分区及副本的合理分配,我们也希望通过某种方式能够将该节点上的分区副本迁移到其他的可用节点上。
- 当集群中新增broker节点时,只有新创建的主题分区才有可能被分配到这个节点上,而之前的主题分区并不会自动分配到新加入的节点中,因为在它们被创建时还没有这个新节点,这样新节点的负载和原先节点的负载之间严重不均衡。
为了解决上述问题,需要让分区副本再次进行合理的分配,也就是所谓的分区重分配。Kafka提供了kafka-reassi gn-partitions.sh脚本来执行分踵分配的工作,它可以在集群扩容、broker节点失效的场景下对分区进行迁移。kafka-reassign-partitions.sh脚本的使用分为3个步骤:首先创建需要一个包含主题清单的JSON文件,其次根据主题清单和 broker 节点清单生成一份重分配方案,最后根据这份方案执行具体的重分配动作。
分区重分配对集群的性能有很大的影响,需要占用额外的资源,比如网络和磁盘。在实际操作中,我们将降低重分配的粒度,分成多个小批次来执行,以此来将负面的影响降到最低,这一点和优先副本的选举有异曲同工之妙。
还需要注意的是,如果要将某个broker下线,那么在执行分区重分配动作之前最好先关闭或重启 broker。这样这个broker就不再是任何分区的 leader 节点了,它的分区就可以被分配给集群中的其他 broker。这样可以减少broker间的流量复制,以此提升重分配的性能,以及减少对集群的影响。
复制限流(先增加新的副本,然后进行数据同步,最后删除旧的副本来达到最终的目的)
在4.3.2节中我们了解了分区重分配本质在于数据复制,先增加新的副本,然后进行数据同步,最后删除旧的副本来达到最终的目的。数据复制会占用额外的资源,如果重分配的量太大必然会严重影响整体的性能,尤其是处于业务高峰期的时候。减小重分配的粒度,以小批次的方式来操作是一种可行的解决思路。如果集群中某个主题或某个分区的流量在某段时间内特别大,那么只靠减小粒度是不足以应对的,这时就需要有一个限流的机制,可以对副本间的复制流量加以限制来保证重分配期间整体服务不会受太大的影响。
副本间的复制限流有两种实现方式: kafka-config.sh脚本和kafka-reassign- part it ions.s脚本。
首先,我们讲述如何通过 kafka- configsh脚本来实现限流,如果对这个脚本的使用有些遗
- #添加配置
- bin/kafka-configs.sh
- --zookeeper localhost:2181/kafka
- --entity-type brokers
- --entity-name 1
- --alter
- --add-config
- follower.replication.throttled.rate=l024 , leader.replication.throttled.rate=l024
- #查看配置
- bin/kafka-configs.sh
- --zookeeper localhost:2181/kafka
- --entity-type brokers
- --entity-name 1
- --describe
-
- #删除配置
- bin/kafka-configs.sh
- --zookeeper localhost:2181/kafka
- --entity-type brokers
- --entity-name 1
- --alter
- --delete-config
- follower.replication.throttled.rate=l024 , leader.replication.throttled.rate=l024

在topic级别也有2个参数来限制复制的速度
- follower.replication.throttled.replicas
- leader.replication.throttled.replicas
- #1、首先创建一个主题topic-throttled,partitions=3,replication-factor=2
- bin/kafka-topics.sh --create --zookeeper localhost:2181 --partitions 3 --replication-factor 2 --topic topic-throttled
-
- #2、查看创建的topic的详情
- bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic topic-throttled
-
- #3、添加限制复制流量的配置
- bin/kafka-config.sh
- --zookeeper localhost:2181/kafka
- --entity-type topics
- --entity-name topic-throttled
- --alter
- --add-config
- leader.replication.throttled.replicas=[0:0,1:1,2:2],follower.replication.throttled.replicas=[0:1,1:2,2:0] #其中0:0等代表分区号与代理的映射关系
kafka-reassign-partitions.sh
该脚本也提供了限流的功能,只需要传入一个throttled参数就行,具体用法如下:
bin/kafka-reassign-partitions.sh --zookeeper localhost:2181/kafka --execute --reassign-json-file project.json --throttled 10 # 这里的10表示10B/S
修改副本因子
创建主题之后我们还可以修改分区的个数,同样可以修改副本因子(副本数)。修改副本因子的使用场景也很多,比如在创建主题时填写了错误的副本因子数而需要修改,再比如运行一段时间之后想要通过增加副本因子数来提高容错性和可靠性。
如何选择合适的分区数(根据具体的业务来定)
如何选择合适的分区数﹖这是很多Kafka的使用者经常面临的问题,不过对这个问题而言,似乎并没有非常权威的答案。而且这个问题显然也没有固定的答案,只能从某些角度来做具体的分析,最终还是要根据实际的业务场景、软件条件、硬件条件、负载情况等来做具体的考量。本节主要介绍与本问题相关的一些重要决策因素,使读者在遇到类似问题时能够有参考依据。
性能测试工具
在Kafka中,性能与分区数有着必然的关系,设定分区数时一般也需要考虑性能的因素。不同的硬件而言,其对应的性能也会不太一样。在实际生产环境中,我们需要了解一套硬件所对应的性能指标之后才能分配其合适的应用和负荷,所以性能测试工具必不可少。
性能测试工具是Kafka本身提供的用于生产者性能测试的 kafka-producer-perf-test.sh和用于消费者性能测试的kafka-consumer-perf-test.sh。
分区数越多吞吐量就越高吗
分区是Kafka中最小的并行操作单元,对生产者而言,每一个分区的数据写入是完全可以并行化的;对消费者而言,Kafka只允许单个分区中的消息被一个消费者线程消费,一个消费组的消费并行度完全依赖于所消费的分区数。如此看来,如果一个主题中的分区数越多,理论上所能达到的吞吐量就越大,那么事实真的如预想的一样吗?
消息中间件的性能一般是指吞吐量(广义来说还包括延迟)。抛开硬件资源的影响,消息写入的吞吐量还会受到消息大小、消息压缩方式、消息发送方式(同步/异步)、消息确认类型(acks)、副本因子等参数的影响,消息消费的吞吐量还会受到应用逻辑处理速度的影响。本案例中暂不考虑这些因素的影响,所有的测试除了主题的分区数不同,其余的因素都保持相同。
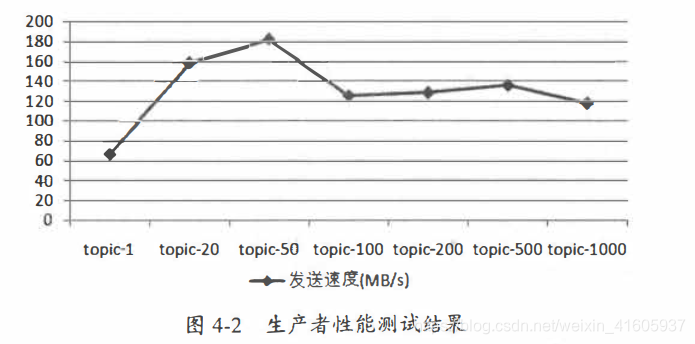
在图4-2中,我们可以看到分区数为Ⅰ时吞吐量最低,随着分区数的增长,相应的吞吐量也跟着上涨。一旦分区数超过了某个阈值之后,整体的吞吐量是不升反降的。也就是说,并不是分区数越多吞吐量也越大。这里的分区数临界阈值针对不同的测试环境也会表现出不同的结果,实际应用中可以通过类似的测试案例(比如复制生产流量以便进行测试回放)来找到一个合理的临界值区间。
分区数的上限
一味地增加分区数并不能使吞吐量一直得到提升,并且分区数也并不能一直增加,如果超过默认的配置值,还会引起Kafka进程的崩溃。读者可以试着在一台普通的Linux机器上创建包含10000个分区的主题,比如在下面示例中创建一个主题topic-bomb:

执行完成后可以检查Kafka 的进程是否还存在(比如通过jps命令或ps -aux /grepkafka命令)。一般情况下,会发现原本运行完好的Kafka 服务已经崩溃。此时或许会想到,创建这么多分区,是不是因为内存不够而引起的进程崩溃﹖我们在启动 Kafka进程的时候将
JVM堆设置得大一点是不是就可以解决问题了。其实不然,创建这些分区而引起的内存增长完全不足以让Kafka“畏惧”。为了分析真实的原因,我们可以打开Kafka 的服务日志文件(SKAFKA_HOME/logs/ser ve .log)来探究竟,会发现服务日志中出现大量的异常:


