
- 1RabbitMQ 之 死信队列
- 2运行pip报错:Fatal error in launcher: Unable to create process using '’路径’'
- 3Android 调节屏幕亮度问题_android params.screenbrightness失效
- 4探究人工智能技术在医疗、交通、金融和教育领域的应用和前景_人工智能医疗和金融等行业的应用领域
- 5uniapp h5端和react native 通信
- 6【优秀课设】基于FPGA的Verilog HDL自动售货机_verilog自动售货机
- 7免费申请使用IBM Cloud Lite(轻量套餐) 详细教程指南_ibm不使用行用卡注册
- 8用文心一言专业版年卡,新的一年为你想尽办法!
- 9PLC-Recorder常用授权功能详解
- 10com.mchange.v2.resourcepool.CannotAcquireResourceException: A ResourcePool could
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
赞
踩
LlaMA 3 系列博客
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(三)
大模型之深入理解Transformer位置编码(Positional Embedding)
大模型之深入理解Transformer Layer Normalization(一)
大模型之深入理解Transformer Layer Normalization(二)
大模型之深入理解Transformer Layer Normalization(三)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(一)初学者的起点
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(二)矩阵操作的演练
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(三)初始化一个嵌入层
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(四)预先计算 RoPE 频率
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(五)预先计算因果掩码
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(六)首次归一化:均方根归一化(RMSNorm)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(七) 初始化多查询注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(八)旋转位置嵌入
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(九) 计算自注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十) 残差连接及SwiGLU FFN
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十一)输出概率分布 及损失函数计算
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(一)加载简化分词器及设置参数
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(二)RoPE 及注意力机制
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(三) FeedForward 及 Residual Layers
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(四) 构建 Llama3 类模型本身
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(五)训练并测试你自己的 minLlama3
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(六)加载已经训练好的miniLlama3模型
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (六)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (七)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (八)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(四)
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(一)Code Shield简介
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(二)防止 LLM 生成不安全代码
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(三)Code Shield代码示例
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(二) LLaMA-Factory训练方法及数据集
大模型之Ollama:在本地机器上释放大型语言模型的强大功能
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(三)通过Web UI微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(四)通过命令方式微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(五) 基于已训练好的模型进行推理
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(六)Llama 3 已训练的大模型合并LoRA权重参数
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
使用 LoRA 微调 LLM 的实用技巧
学习率调度器
学习率调度器在整个训练过程中降低学习率,以优化收敛并避免超过损失最小值。
余弦退火是一种学习率调度程序,它按照余弦曲线调整学习率。它从较高的学习率开始,然后平稳下降,以类似余弦的方式接近零。一种常用的变体是半周期变体,其中在训练过程中仅完成半个余弦周期,如下图所示。
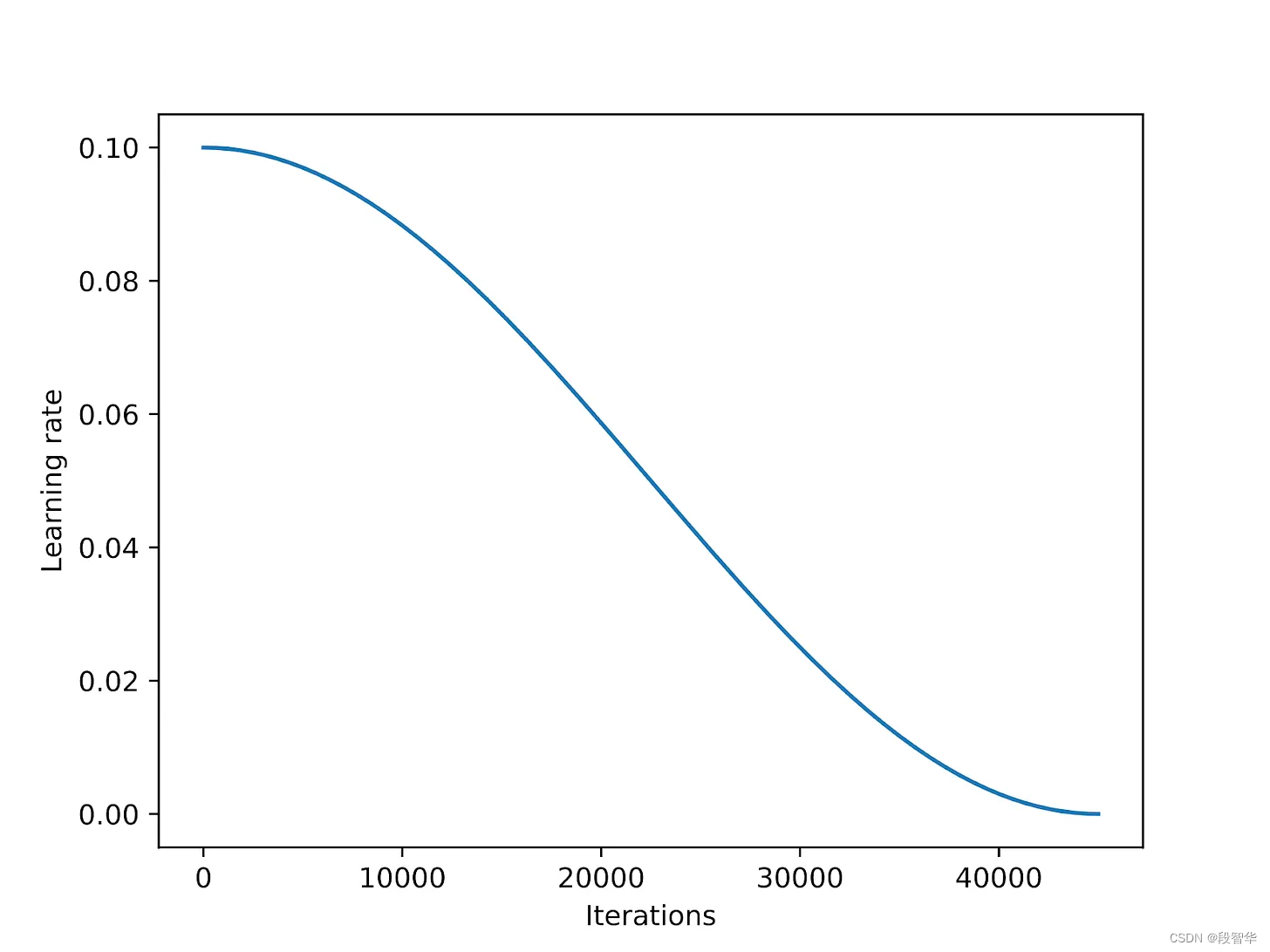
作为实验的一部分, 在 LoRA 微调脚本中添加了一个余弦退火调度程序,并观察到它显著提高了 SGD 性能。然而,它对 Adam 和 AdamW 优化器的影响较小,几乎没有任何区别。
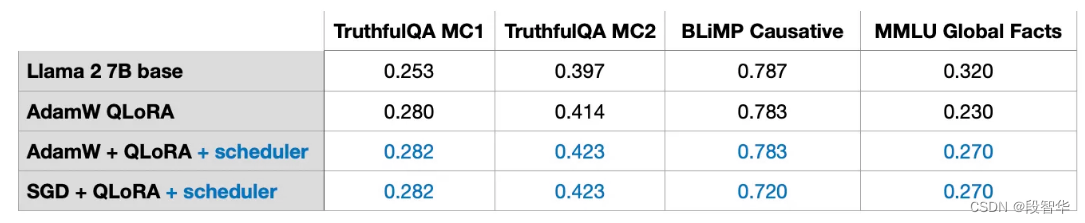
Adam 对阵 SGD
Adam 和 AdamW 优化器在深度学习中仍然是很受欢迎的选择,尽管它们在处理大型模型时占用大量内存。原因是 Adam 优化器为每个模型参数维护两个移动平均值:梯度的一阶矩(平均值)和梯度的二阶矩(非中心方差)。换句话说,Adam 优化器在内存中为每个单个模型参数存储两个额外的值。如果使用 7B 参数模型,那么在训练期间需要跟踪额外的 14B 参数。
SGD 优化器在训练期间不需要跟踪任何其他参数,所以问题是:在训练 LLM 时,用 SGD 替换 Adam 对峰值内存需求有什么优势?
实验中,训练使用 AdamW 和 LoRA 默认值 ( r=8 )训练的 7B 参数 Llama 2 模型需要 14.18 GB 的 GPU 内存。使用 SGD 训练同一模型则需要 14.15 GB 的 GPU 内存。换句话说,节省的内存 (0.03 GB) 微乎其微。
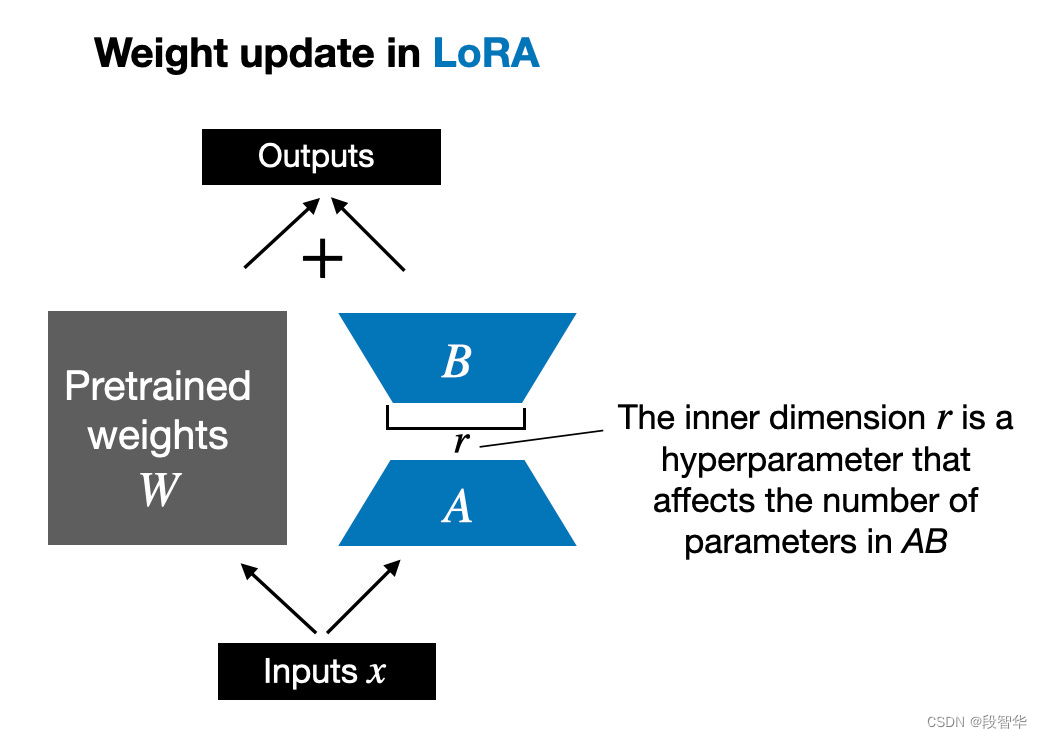
为什么内存节省如此之少?这是因为使用 LoRA,只有少量可训练参数。例如,如果r=8 ,则在 7B Llama 2 模型的所有 6,738,415,616 个参数中,有 4,194,304 个可训练的 LoRA 参数。
如果我们只看数字,4,194,304 个可训练参数听起来仍然很多,但如果我们进行计算,我们只有 4,194,304 × 2 × 16 位 = 134.22 兆位 = 16.78 兆字节。(我们观察到 0.03 Gb = 30 Mb 的差异,因为在存储和复制优化器状态时有额外的开销。)
- 2 表示 Adam 存储的额外参数的数量
- 16 位是指模型权重的默认精度。
然而,如果 将 LoRA 的 r 增加到 256 ,Adam 和 SGD 优化器之间的差异就会变得更加明显: - 17.86 GB(含 AdamW)
- 14.46 GB(含 SGD)
需要注意的是,当 LoRA 的 r 较小时,用 SGD 替换 Adam 优化器可能不值得。但是,当增加 r 时,这可能是值得的。
多次训练
在传统的深度学习中,经常对训练集进行多次迭代——对训练集的迭代称为一个 epoch。例如,在训练卷积神经网络时,通常会运行数百个训练 epoch。多 epoch 训练对指令微调也有用吗?
当将50k 个示例 Alpaca指令微调数据集的迭代次数增加两倍(类似于 2 个训练时期)时,注意到模型性能有所下降。

结论是,多轮训练可能不利于指令微调,因为它可能会降低结果。 在 1k 示例 LIMA 数据集中观察到了同样的情况。这种性能下降可能是由于过度拟合增加造成的,这值得进一步调查。
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。

