
- 1配置YOLOv7训练自己是数据集【踩坑记录】_yolov7训练自己的数据集出现的问题
- 2python植物大战僵尸辅助_【python面向对象实战练习】植物大战僵尸
- 3机器学习实战-员工离职预测-分类预测模型(决策树、朴素贝叶斯、支持向量机)_分别利用决策树算法(id3)、朴素贝叶斯算法分类模型预测样本是否会离职?结果有没有
- 4导出 Whisper 模型到 ONNX_whisper onnx
- 5【JAVA毕设|课设】基于SpringBoot+Vue的进销存(库存)管理系统-附下载方式_vue进销存系统csdn下载
- 6OpenCV 车道检测_实现图片车道线检测
- 7大数据毕业设计:微博情感分析可视化系统 舆情分析 爬虫 python 大数据 TF-IDF算法 Flask框架(源码)✅_基于大数据的舆情系统源码
- 8tf-idf关键词提取算法_tf-idf关键字提取
- 9spring boot 1.5.9 整合redis
- 10机器学习 鸢尾花分类的原理和实现(三)_机器学习鸢尾花的研究起源
大模型究竟和传统AI有什么区别,未来是否会重塑AI行业,对我们的生活会带来哪些改变?_大模型和传统ai的区别
赞
踩
2023年最火的行业一定是“AI大模型”,从年初一直火到年尾,甚至有人认为它会给世界带来新一轮技术革命,推动人类科技的进步。那么究竟什么是“大模型”?它和前几年的人工智能有什么区别?它能带给我们什么改变?中国在大模型领域的布局如何?接下来本文将给大家一一道来。并且从本期开始,我们将做一个AI系列专题,把AI产业链上下游好好梳理一遍,共同学习,寻找其中的投资机会。
2022年11月30日,OpenAI发布聊天机器人程序ChatGPT,全称是Chat Generative Pre-trained Transformer(生成式预训练transformer模型)。该程序一经上线,用户数量5天突破100万人,月活数量2个月内突破1亿,成为史上用户增长速度最快的消费级应用程序,引发市场对人工智能的强烈关注。
不同于此前的任何AI聊天机器人,ChatGPT令人震惊的理解能力和上下文联系能力使得人们相信人工智能正在成为现实。同时,ChatGPT所具备的理解能力、推理能力、学习能力更使得人工智能帮助人类提高生产力。
根据对字面意思的理解,ChatGPT重点在于“生成式”和“预训练”。1)生成式:可以生成新的数据,适用于无监督学习任务,具备多模态,泛化性和创造力,有智能涌现现象;2)预训练:是指在一个较小的、特定任务的数据集上进行微调之前,在一个大数据集上训练一个模型的过程。预训练允许模型先从数据中学习一般的特征和表征,然后针对具体任务进行微调,令其适应特定任务;预训练的意义在于,减少对大量特定任务、标记数据的需求,同时提升模型的效果,所以通用性****是ChatGPT的一大特征。
大模型的“大”主要指的是“参数量”
以ChatGPT为代表的大语言模型需要的巨大的参数量级是其有别于之前人工智能模型的关键点。并且随着参数量的提升也出现了量变引起质变的神奇效果。
大语言模型的“涌现”(Emergent)现象是指在模型训练参数和数据量超过一定数值之后,模型突然出现了意想不到的能力,令AI变得非常智能。谷歌、DeepMind、斯坦福的16位专家合作的论文《Emergent Abilities of Large Language Models》(大语言模型的涌现能力)阐述了大模型所展现的神奇能力正来自于其模型参数规模。
下图可以看出,大语言模型随着规模的增长,实现了性能的大幅提升,在突破10的22次方量级后,智慧能力出现了质的飞跃。
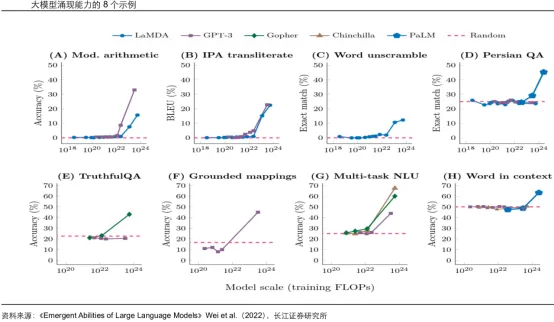
每一代GPT的参数量成指数级增长,GPT-4已经达到万亿级别
AI大模型能力的提升主要有三条路径:模型参数量的提升、训练数据量的提升以及训练轮数的提升。
Ø模型参数量的提升: 以OpenAI的GPT模型为例,第一代GPT模型GPT-1的参数量仅有1.17亿,GPT-2参数量提升至15亿,GPT-3参数量进一步提升至1750亿,GPT-4的参数量达到1.8万亿级别;模型代际之间参数量呈现指数级增长,大模型能力亦随模型参数量的增长而大幅提升;
Ø训练数据量的提升: 1)语言模态训练数据量提升;2)多模态训练数据的加入:例如图片、视频等也作为训练数据,训练数据集大小大幅提升;
Ø训练轮数的提升: 1)新模型:通过多轮训练,模型能力得到提升,但过多的训练亦会导致模型过拟合;2)已有模型:定期训练(每周、每月),对模型的能力和数据的时效性进行提升和更新。


激增的参数量也带动了成本的大幅上涨
训练成本:OpenAI在GPT-4的训练中,使用了大约25,000个A100芯片,在90至100天的时间内进行了约32%至36%的MFU(平均功能利用率)。如果他们在云中的成本约为每小时1美元的A100芯片,仅这次训练的成本就约为6300万美元。 这还没有考虑到所有的实验、失败的训练运行和其他成本,比如数据收集、强化学习和人员成本等。目前,使用约8,192个H100芯片,以每小时2美元的价格,在约55天内可以完成预训练,成本约为2150万美元。
推理成本: 据估计,在用128 个A100 GPU 进行推理的情况下,8k 版本GPT-4推理的成本为每 1,000个token 0.0049 美分。如果使用128 个H100 GPU 进行推理,同样的8k版本GPT-4 推理成本为每1,000个token 0.0021美分。
用水量惊人: 加州大学河滨分校的研究员Shaolei Ren 表示:ChatGPT 在今年晚些时候将会发表的一篇论文中,每次你向它提问一系列介于 5 到 50 个提示或问题之间,它就会消耗 500 毫升的水(接近于一个 16 盎司水瓶的水量)。这个范围取决于服务器的位置和季节。这个估算包括公司没有测量的间接用水,比如用于冷却供电数据中心的发电厂。
据悉,微软用几亿美元,耗费上万张英伟达A100芯片打造超算平台,只为给ChatGPT和新版必应提供更好的算力。不仅如此,微软还在Azure的60多个数据中心部署了几十万张GPU,用于ChatGPT的推理。大模型的训练需要几亿打底,再算上未来海量用户的推理需求,需要的算力成本可能就是百亿量级了。
大模型是如何从传统AI进化而来
大模型是这两年刚提出来的概念,但它所处的AI行业我们并不陌生,前几年国内知名的“AI四小龙”还历历在目。那么我们再回顾下整个AI历史,看看大模型处于什么阶段?
AI大模型为人工智能发展的新里程碑。 以1956年达莱茅斯会议为起点,人工智能的发展历史可以归纳为四个阶段,随着互联网、云技术的兴起,人工智能逐步从符号主义向联结主义演进,整体呈现出波浪式前进态势。本轮人工智能由AI大模型推动,将迎来通用人工智能时代。
Ø阶段一(1956-1986年):基于推理逻辑和规则匹配技术的符号主义为主;
Ø阶段二(1987-2010年):联结主义复兴、神经网络崛起以及深度学习算法突破;
Ø阶段三(2011-2017年):联结主义为主,人工智能迎来深度学习的爆发期;
Ø阶段四(2018年-至今):大模型掀起第四次科技革命,迎来通用人工智能时代。

近十年来,通过**“深度学习+大算力”获得训练模型成为实现人工智能的主流技术途径**。由于深度学习、数据和算力可用这三个要素都已具备,全球掀起了“大炼模型”的热潮,也催生了一大批人工智能公司。然而,在深度学习技术出现的近10年里,AI模型基本上都是针对特定的应用场景进行训练的,即小模型属于传统的定制化、作坊式的模型开发方式。传统AI模型需要完成从研发到应用的全方位流程,包括需求定义、数据收集、模型算法设计、训练调化、应用部署和运营维护等阶段组成的整套流程。这意味着除了需要优秀的产品经理准确定义需求外,还需要AI研发人员扎实的专业知识和协同合作能力才能完成大量复杂的工作。

在传统模型中,研发阶段为了满足各种场景的需求,AI研发人员需要设计个性定制化的专用的神经网络模型。 模型设计过程需要研究人员对网络结构和场景任务有足够的专业知识,并承担设计网络结构的试错成本和时间成本。一种降低专业人员设计门槛的思路是通过网络结构自动搜索技术路线,但这种方案需要很高的算力,不同的场景需要大量机器自动搜索最优模型,时间成本仍然很高。一个项目往往需要专家团队在现场待上几个月才能完成。其中,数据收集和模型训练评估以满足目标要求通常需要多次迭代,从而导致高昂的人力成本。
落地阶段,通过“一模一景”的车间模式开发出来的模型,并不适用于垂直行业场景的很多任务。 例如,在无人驾驶汽车的全景感知领域,往往需要多行人跟踪、场景语义分割、视野目标检测等多个模型协同工作;与目标检测和分割相同的应用,在医学影像领域训练的皮肤癌检测和AI模型分割不能直接应用于监控景点中的行人车辆检测和场景分割。模型无法重复使用和积累,这也导致了AI落地的高门槛、高成本和低效率。
大模型是从庞大、多类型的场景数据中学习,总结出不同场景、不同业务的通用能力,学习出一种特征和规律,成为具有泛化能力的模型库。 在基于大模型开发应用或应对新的业务场景时可以对大模型进行适配,比如对某些下游任务进行小规模标注数据二次训练,或者无需自定义任务即可完成多个应用场景,实现通用智能能力。因此,利用大模型的通用能力,可以有效应对多样化、碎片化的人工智能应用需求,为实现大规模人工智能落地应用提供可能。
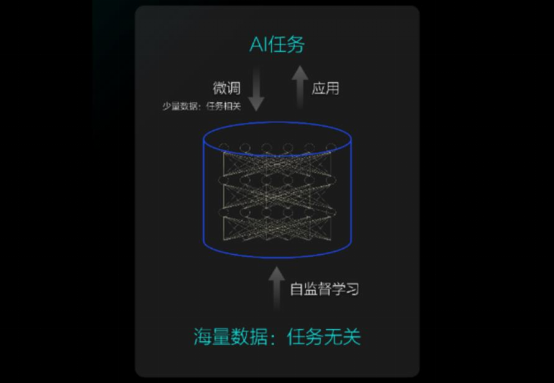
大模型具有自监督学习能力,能够降低AI开发以及训练成本
传统的小模型训练过程涉及大量调参调优的手动工作,需要大量AI专业研发人员来完成;同时,模型训练对数据要求高,需要大规模的标注数据。但很多行业的数据获取困难,标注成本高,同时项目开发者需要花费大量时间收集原始数据。例如,人工智能在医疗行业的病理学、皮肤病学和放射学等医学影像密集型领域的影响不断扩大和发展,但医学影像通常涉及用户数据隐私,很难大规模获取到用于训练 AI 模型。在工业视觉瑕疵检测领域,以布匹瑕疵为例,市场上需要检测的织物种类有白坯布、色坯布、成品布、有色布、纯棉、混纺织物等缺陷种类繁多,颜色和厚度难以识别,需要在工厂长时间收集数据并不断优化算法才能做好缺陷检测。
大模型利用自监督学习功能,对输入的原始数据进行自动学习区分,合理构建适合模型学习的任务,不需要或者很少用人工标注的数据进行训练,很大程度上解决了人工标注的数据标签成本高、周期长、精确度的问题,减少了训练所需的数据量。这在很大程度上减少了收集和标记大型模型训练数据的成本,更适合小样本学习,有助于将传统有限的人工智能扩展到更多的应用场景。
大模型带来更强大的智能能力
除通用能力强、研发过程标准化程度高外,大模型最大的优势在于“效果好”。它通过将大数据“喂”给模型来增强自学习能力,从而具有更强的智能程度。例如,在自然语言处理领域,百度、谷歌等探索巨头已经表明,基于预训练大模型的NLP技术的效果已经超越了过去最好的机器学习的能力。OpenAI 研究表明,从 2012 年到 2018 年的六年间,在最大规模的人工智能模型训练中所使用的计算量呈指数级增长,其中有 3.5 个月内翻了一番,相比摩尔定律每 18 个月翻一番的速度快很多。下一代AI大模型的参数量级将堪比人类大脑的突触水平,可能不仅可以处理语言模型,将更是一个多模态AI模型,可以处理多任务,比如语言、视觉和声音。

ChatGPT的发展历程
GPT模型性能随结构、规模的提升不断优化。
(1)GPT-1: 通过无监督预训练和有监督微调两个步骤训练模型,在文本生成和理解任务上表现出了很好的性能。
(2)GPT-2: 去除了GPT-1中的有监督微调步骤,通过更大规模的模型参数和训练数据集进行无监督预训练。GPT-2在多项自然语言处理任务上表现出了卓越的性能,包括文本生成、文本分类、语言理解等。
(3)GPT-3: 通过无监督学习训练模型,模型参数和数据集进一步扩大,模型在自然语言生成、对话生成和其他语言处理任务上表现出了惊人的能力,在一些任务上甚至能够创造出新的语言表达形式。

(4)GPT-3.5引入人工反馈机制(RLHF),缩小模型输出。与人类回答之间的差距。GPT-3.5在GPT-3的基础上进行有监督微调(Supervised Fine-Tuning)、奖励模型训练(Reward Modeling)和来自人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),其中后两步训练可进行多次迭代。RLHF采用PPO(近端策略优化)训练模型,在数据集中随机抽取问题,由PPO生成回答,再由上一步的奖励模型打分,以此更新PPO模型参数,令ChatGPT的回应更加简洁、公正,学会拒绝不当问题和知识范围外的问题。
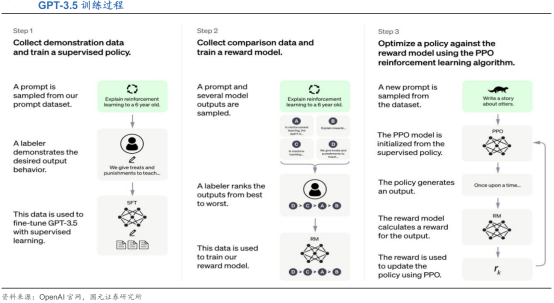
(5)GPT-4性能明显提升。GPT-4在多个基准任务上取得了非常好的成绩,包括图像字幕、图文问答、代码生成和法律推理,在SAT、USABO等多项考试中表现优于人类水平的平均值。

GPT-4迈入多模态时代,可接受图片输入。 GPT-4可以接受文本和图像提示,允许用户指定任何视觉或语言任务。根据给定由穿插的文本和图像组成的输入,它能够生成自然语言、代码等文本输出,包括描述图片内容并发现不合理之处,根据图片推理作答,理解漫画含义等具体场景下的任务。
(6)GPT-4 Turbo——更聪明、更便宜、更快速。根据OpenAI的开发者大会披露,新版本具备:1)更长的上下文长度:支持128K上下文窗口,相当于300页文本;2)更便宜:新模型的价格是每千输入token1美分,而每千输出token3美分,输入和输出费用分别降至GPT-4的1/3和1/2,总体使用上降价约2.75倍;3)更聪明:内部知识库更新至2023年4月,并支持上传外部数据库或文件;4)视听多模态:支持文生图模型DALL·E3、文本转语音模型TTS,未来还将支持自动语音识别模型Whisperv3;5)更快的速度:用户每分钟的Token速率限制将会翻倍,可通过API账户申请进一步提速。
(7)OpenAI正在研发更强大的GPT-5。OpenAI联合创始人Sam Altman在接受《金融时报》采访时表示,公司正在开发下一代人工智能模型"GPT-5",但没有给出具体的时间表。该模型比GPT-4更先进,但从技术上很难准确预测该模型会有哪些功能。此外,GPT-5需要用更多的数据进行训练,包括互联网上公开可用的数据集以及一些公司的专有数据。
ChatGPT引爆了全球大模型行业,主流互联网公司争相入局
从参数规模上看,AI 大模型先后经历了预训练模型、大规模预训练模型、超大规模预训练模型三个阶段,参数量实现了从亿级到百万亿级的突破。从模态支持上看, AI 大模型从支持图片、图像、文本、语音单一模态下的单一任务,逐渐发展为支持多种模态下的多种任务。
国外超大规模预训练模型始于2018年,并在2021年进入“军备竞赛”阶段。2017年Vaswani等人提出Transformer架构,奠定了大模型领域主流算法架构的基础; Transformer提出的结构使得深度学习模型参数达到上亿规模。2018年谷歌提出BERT大规模预训练语言模型,是一种基于Transformer的双向深层预训练模型。这极大地刺激了自然语言处理领域的发展。此后,基于BERT、ELNet、RoberTa、T5的增强模型等一大批新的预训练语言模型相继涌现,预训练技术在自然语言处理领域得到快速发展。
2019年,OpenAI将继续推出15亿参数的GPT-2,可以生成连贯的文本段落,实现早期阅读理解和机器翻译等。紧接着,英伟达推出了83亿参数的Megatron-LM,谷歌推出了110亿参数的T5,微软推出了170亿参数的Turing-NLG。2020年,OpenAI推出GPT-3超大规模语言训练模型,参数达到1750亿,用了大约两年的时间,实现了模型规模从1亿到上千亿级的突破,并能实现作诗、聊天、生成代码等功能。此后,微软和英伟达于2020年10月联合发布了5300亿参数的Megatron Turing自然语言生成模型(MT-NLG)。2021年1月,谷歌推出的Switch Transformer模型成为历史上首个万亿级语言模型多达 1.6 万亿个参数;同年 12 月,谷歌还提出了具有 1.2 万亿参数的 GLaM 通用稀疏语言模型,在7项小样本学习领域的性能优于 GPT-3。最新的GPT-4已经支持1.8万亿参数量。可以看出,大型语言模型参数数量保持着指数增长势头。

ChatGPT的诞生引发了大模型的研发浪潮,应用前景十分广阔,有望推动人工智能产业进一步快速发展。经过2023年这一年的快速发展,大模型产业初具规模,下游应用百花齐放,我们认为2024年仍然会有不错的投资机会。
大模型商业化落地加速,市场规模快速增长。目前,大模型落地模型主要可分为三种,即大模型、大模型+算力、大模型+应用,其中大模型指企业用户可以直接买断大模型产品,也可以租用大模型(例如中软国际的模型工厂);大模型+算力指厂商将模型与算力进行组合销售;大模型+应用指厂商向企业用户销售融入了大模型能力的上层应用,要求用户支付软件授权费等。短期大模型+算力为主流的收费模式,后随着模型应用、生态的进一步完善,大模型+应用模式占比有望逐步提升。
Ø**全球市场:**根据钛媒体国际智库数据,2022年全球大模型市场规模108亿美金,预计2028年达到1095亿美金,对应22-28年CAGR为47%,全球大模型市场规模快速增长。
Ø**中国市场:**根据钛媒体国际智库数据,2022年中国大模型市场规模70亿人民币,预计2028年达到1179亿人民币,对应22-28年CAGR为60%,中国大模型市场规模快速增长,且快速全球市场。
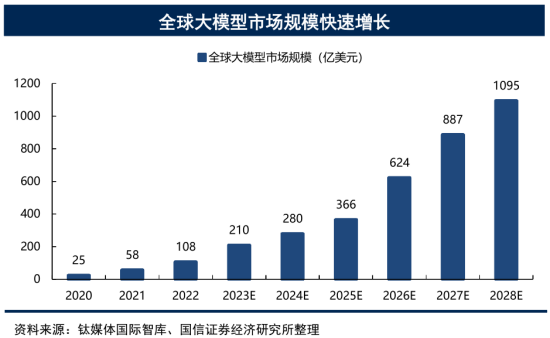

大模型在整个产业链中只占据了一小部分,它更是撬动了几十倍的行业规模。
伴随着以大模型为代表的人工智能技术的不断演进,AI有望深度赋能千行百业,展望2024年,我们认为:构成大模型产业链的AI芯片、算力租赁、模型层和应用层将充分受益于AI技术的繁荣发展,有望给资本市场带来较好的投资机遇。

根据沙利文《AI大模型市场研究报告(2023)——迈向通用人工智能,大模型拉开新时代序幕》的数据,2022年中国人工智能市场规模达3716亿元,预计市场规模将以34%的复合增速在2027年达到15732亿元。
国内互联网公司也在加紧布局大模型
在国内,超大模型的研发发展异常迅速,2021年是中国AI大模型爆发的一年。2021年,商汤科技发布了大规模模型(INTERN),拥有100亿的参数量,这是一个巨大的训练工作。在训练过程中,大约有10个以上的监控信号帮助模型适应各种不同视觉或NLP任务。截至到2021年中,商汤科技已经构建了全球最大的计算机视觉模型,其中该模型拥有超过300亿个参数;同年4月,华为云联合循环智能发布千亿参数规模的盘古NLP超大规模预训练语言模型;联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。阿里达摩院发布270亿参数的PLUG中文预训练模型,联合清华大学发布千亿参数规模的M6中文多模态预训练模型;7月,百度推出 ERNIE 3.0 Titan模型;10月,浪潮信息发布预估2500亿的超大规模预训练模型“源 1.0”;12月,百度推出了拥有2600亿尺度参数的ERNIE 3.0 Titan模型。而达摩院的M6模型的参数达到10万亿,直接将大模型的参数提升了一个量级。2022年,基于清华大学、阿里达摩院等研究成果以及超算基础实现的“脑级人工智能模型”八卦炉完成建立,其模型参数将超过174万亿。
2023年无疑是人工智能的“爆发年”,各种基于AI的新技术如雨后春笋般拔地而出,其中AI大模型更是成为了全球科技公司的“角逐场”。日前,中国移动研究院发布国内AI大模型发展报告指出,百度、阿里巴巴、腾讯、华为是业界公认国内大模型第一梯队,在大模型研发投入、技术能力和人才团队实力较强,具备追赶GPT-4实力。
如今,中国已经出现了“百模大战”盛况。不知不觉国内都已经有100+大模型了,还有不少正在研发过程中。


大模型的应用将会深入到各个细分领域
海外 AI 应用新星持续涌现,陪伴类和内容生成类 AI 应用增势迅猛。 风险投资公司a16z(Andreessen Horowitz)于 9 月份发布报告,根据截至 2023 年 6 月 LikeWeb统计的网页端和移动端 App 的流量数据,访问量前五的生产式 AI 产品分别为:ChatGPT(OpenAI)、Character.AI、Bard(Google)、Poe、QuillBot。排名第二的Character.AI 是一个聊天机器人平台,用户在网站上自定义对话角色并与之交互;排名第四的是问答网站 Quora 下的 Poe,用户可以通过该平台和不同大型语言模型构建的聊天机器人对话,包括 OpenAI 的 GPT-3.5 和 GPT-4、Google 的 PaLM、Meta的 Llama 2 等;排名第五的是由美国在线辅导网站 Course Hero 推出的 QuillBot,是一款主要面向学生群体的写作工具。此外,前五十榜单的绝大部分产品都是新产品,只有 5 款产品来自大型科技公司旗下。
AI Agent使基座大模型成为模型的操作系统。 人工智能代理(AI Agent)是一种能够感知环境、做出决策并执行动作的智能实体。通过赋予大型语言模型(LLM)代理能力,AI Agent能够自主地理解、规划并执行复杂任务,实质上成为一个控制LLM解决问题的系统。这不仅改变了传统的人机交互方式,而且是拓展大模型应用潜力的关键进化方向。随着基座模型提供更先进的开发工具和开源社区的持续创新,AI Agents预计将成为未来大模型应用的关键竞争领域。
未来,大模型将会和各个细分行业相结合,探索更加多样化的应用, 比如:
AI+自动驾驶:特斯拉的FSD
AI+机器人:Google PaLM-E模型
AI+ 网络安全:谷歌的Google Cloud Security AI,微软Security Copilot
AI+金融:哥伦比亚大学联合上海纽约大学推出全新大模型产品FinGPT
AI+教育:Duolingo for school
AI+医疗:谷歌医疗大模型Med-PaLM 2
AI+办公软件:金山办公、微软推出Microsoft 365 Copilot
AI+企业服务:汉得信息
AI+数字创意:万兴科技
近日,在清华大学举行的演讲中,360集团创始人周鸿祎对2024年大模型的发展趋势进行了深刻的预测,引发了业界的广泛关注。
周鸿祎首先指出,与操作系统不同,大模型将呈现无处不在的趋势,更类似于电脑的普及。在他看来,大模型不会被垄断,而是将成为各领域的关键支持技术。其中,他特别强调了多模态能力在国产大模型中的重要性,预言明年多模态能力将成为国产大模型的标配。
据周鸿祎透露,2024年大模型将在两个方向迅猛发展。 一方面,大模型将追求更大规模,拓展应用领域;另一方面,它们也将追求更小规模,迅速搭载在手机和各种物联网设备上,实现本地化运行,不再仅限于云端。特别是在智能汽车领域,大模型有望部署更多,推动智能驾驶技术的快速发展。
随着GPT-4、Gemini等大模型在多模态上的突破,周鸿祎预测未来国产大模型将标配多模态能力,不仅能理解文字,还能处理图片、视频,甚至能够理解声音。他认为,大模型在中国的发展方向是产业化和垂直化,预计明年将涌现出许多真正解决实际问题的垂直大模型。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
-END-
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/709174
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

