
- 1关于无人机,你必须知道的事!!(科技篇)
- 2pycharm下导入pygame模块开发游戏时,出现libpng warning警告的解决办法_libpng warning: unknown itxt compression type or m
- 3yolov5训练出pt模型文件,转换成rknn格式并测试。_yolo5 .pt文件
- 4微软账户 设置 服务器地址,设置Microsoft账户提示此电子邮件地址是保留域怎么办...
- 5Hive总结(五)hive日志_hive 任务的运行日志在哪看
- 6力扣【72. 编辑距离】_力扣72编辑距离
- 7特征工程之特征预处理-文本特征_参见以下代码,构造语料文本数据集 corpus = ['the sky is blue and be
- 8vue+java实现简易AI问答组件(基于百度文心大模型)
- 9仕兰微、华为、汉王、凹凸科技、南山之桥、周立功等公司常见FPGA面试题整理_广东凹凸科技有限公司面试
- 10mysql启动报错 3534错误;unknow suffix‘ ‘;Can‘t connect to MySQL server on ‘localhost‘_unknown suffix '.' used for variable 'mysqlx-port'
机器学习——支持向量机(SVM)
赞
踩
目录
一.SVM介绍
SVM概念
支持向量机(Support Vector Machine,SVM)是一种机器学习算法,用于分类和回归分析。它能够有效地处理线性可分和线性不可分的数据,并在高维空间中构建最优的决策边界。
SVM的核心思想是找到一个超平面,将不同类别的样本点尽可能地分开,并且使得两个类别之间的间隔最大化。这个超平面称为最大间隔超平面,它可以很好地进行分类预测。
具体而言,SVM通过将样本映射到高维特征空间,使得数据在该空间中线性可分。如果在原始输入空间中无法找到一个线性超平面将数据分开,SVM引入了核函数,将计算复杂度从高维特征空间转移到原始输入空间中。常用的核函数有线性核、多项式核和高斯核等。
SVM的训练过程是一个凸优化问题,目标是最小化模型的结构风险。在求解过程中,SVM只关注那些位于决策边界附近的样本,它们被称为支持向量。这种特性使得SVM具有较好的鲁棒性和泛化能力。
总体而言,SVM是一种强大的机器学习算法,能够处理高维空间的数据,并通过寻找最优超平面实现分类和回归分析。它在许多领域如图像识别、文本分类和生物信息学中都取得了广泛的应用。
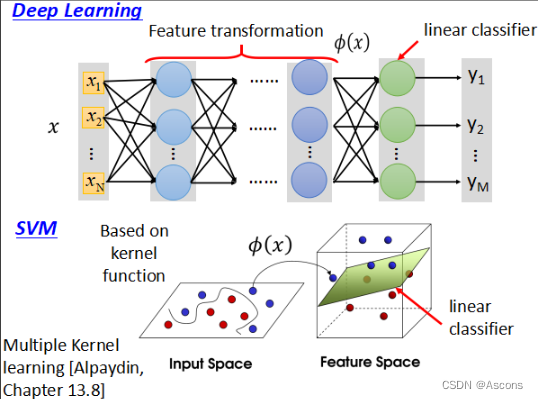
SVM的优缺点与应用场景
优点:
-
适用于高维空间:SVM在高维空间中处理数据效果良好。它可以有效地处理具有大量特征的数据集,并且不易受到维度灾难的影响。
-
处理线性和非线性问题:SVM在处理线性可分和线性不可分的数据时都能够取得良好的效果。通过使用核函数,SVM可以将数据映射到高维特征空间,从而处理非线性问题。
-
泛化能力强:SVM通过最大化分类间隔来构建最优的决策边界,从而在训练数据之外的新数据上表现出很好的泛化能力。这意味着SVM对未见过的数据也能进行准确的分类预测。
-
鲁棒性强:SVM在构建模型时只关注支持向量,即位于决策边界附近的样本点。这使得SVM对于噪声和异常值具有较好的鲁棒性,能够减少模型的过拟合风险。
缺点:
-
难以处理大规模数据集:SVM的计算复杂度随着训练样本数量的增加而增加。当处理大规模数据集时,训练时间和内存消耗可能会变得非常高,甚至难以承受。
-
对参数和核函数选择敏感:SVM中有一些关键参数需要选择,如正则化参数C和核函数的参数。选择不当的参数值可能导致模型性能下降。此外,选择合适的核函数也是一个挑战,不同的数据集可能需要不同的核函数。
-
对缺失数据敏感:SVM对于缺失数据比较敏感。如果数据中存在缺失值,需要进行额外的处理,如填充缺失值或者使用特定的方法处理缺失数据,否则可能影响模型的性能。
应用场景:
-
二分类问题:SVM最初被设计用于解决二分类问题,特别是在数据线性可分的情况下,SVM能够找到最优的超平面来准确地将两个类别分开。
-
多分类问题:虽然SVM最初是为二分类问题设计的,但也可以通过一对多或一对一策略扩展到多类别分类问题。一对多策略将每个类别与其他所有类别进行区分,而一对一策略则构建一组分类器来处理每对类别。
-
文本分类与情感分析:SVM在文本分类任务中表现出色,可以用于将文本分为不同的类别,如垃圾邮件识别、情感分析等。通过将文本表示为特征向量,SVM可以学习一个决策边界来准确地分类新的文本样本。
SVM的理论知识
线性可分支持向量机
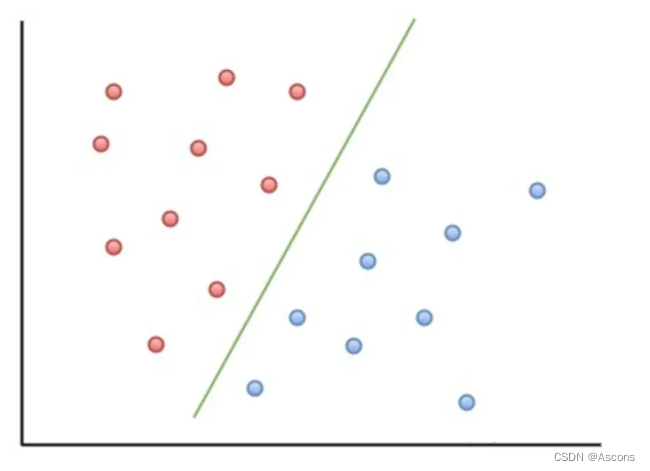
如图,当两类点被一条直线完全分开叫做线性可分。
严格的数学定义是:
D0 和 D1 是 n 维欧氏空间中的两个点集。如果存在 n 维向量 w 和实数 b,使得所有属于 D0 的点Xi都有 wXi+b>0 ,而对于所有属于 D1 的点 �� 则有 wXi+b<0 ,则我们称 D0 和 D1 线性可分。
由于情况不同,分割直线可能不止一条。

为了保证鲁棒性,将会选择中间的一条直线。
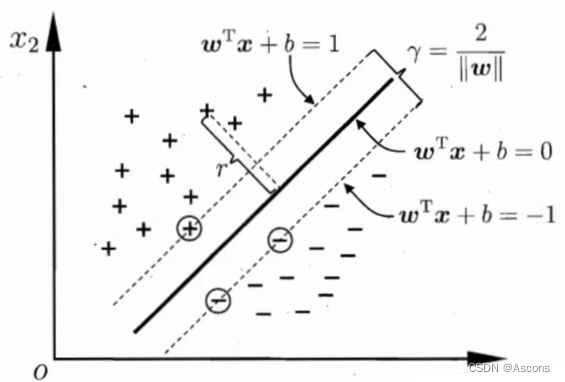
最大间隔超平面
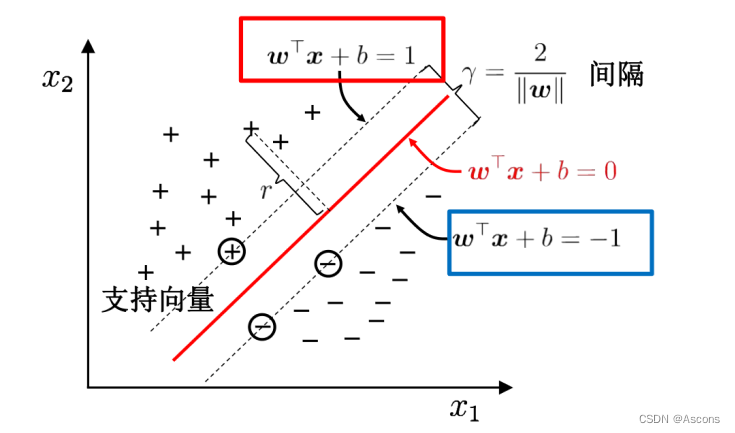
从二维扩展到多维空间中时,将 D0 和 D1 完全正确地划分开的 wx+b=0 就成了一个超平面。
为了使这个超平面更具鲁棒性,我们会去找最佳超平面,以最大间隔把两类样本分开的超平面,也称之为最大间隔超平面。
- 两类样本分别分割在该超平面的两侧;
- 两侧距离超平面最近的样本点到超平面的距离被最大化了。
支持向量
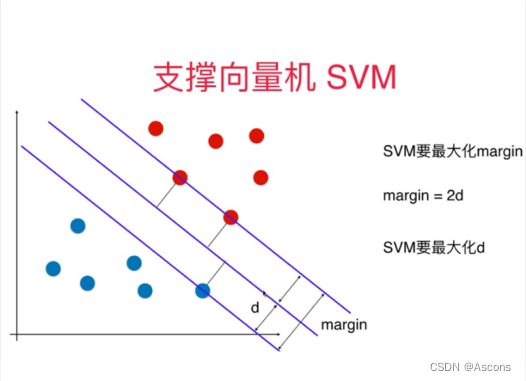
样本中距离超平面最近的一些点,这些点叫做支持向量。
SVM最优化问题

如图所示,根据支持向量的定义我们知道,支持向量到超平面的距离为 d,其他点到超平面的距离大于 d。
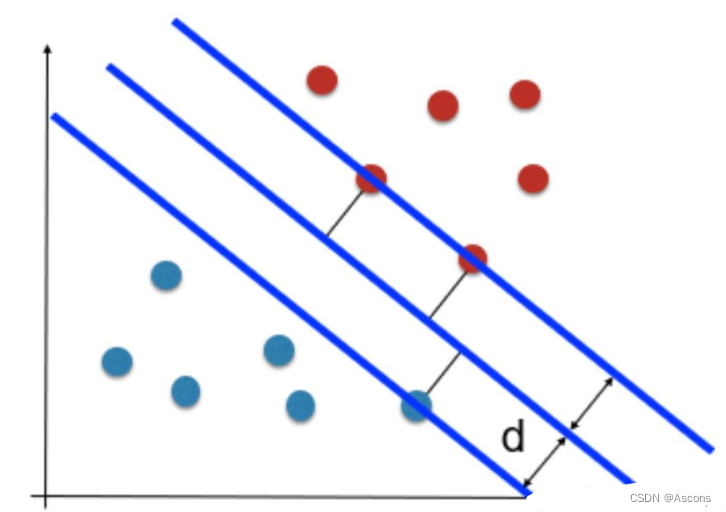
于是我们有这样的一个公式:
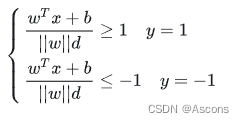

将两个方程合并,我们可以简写为:
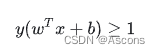
至此我们就可以得到最大间隔超平面的上下两个超平面:
每个支持向量到超平面的距离可以写为:
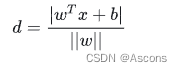
再做一个转换:
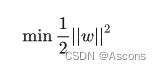
得到的最优化问题是:
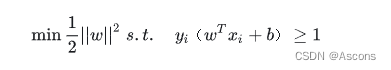
对偶问题
对偶问题是在支持向量机(SVM)算法中的一种转化形式,通过引入拉格朗日乘子将原始优化问题转化为一个更简化的等价问题。对偶问题的求解可以帮助我们更好地理解和求解SVM的优化过程。
在SVM的原始优化问题中,涉及到大量的变量和约束条件,求解起来可能比较复杂。而对偶问题通过引入拉格朗日乘子,将原始问题转化为一个等价的、涉及少量变量的问题。
具体而言,对偶问题通过构建拉格朗日函数,并对其进行最大化,来求解一组合适的拉格朗日乘子。这个对偶问题的目标是找到满足一定条件的最大化拉格朗日函数。
对偶问题的求解步骤如下:
-
构建拉格朗日函数:将原始问题的目标函数和约束条件转化成拉格朗日函数。
-
对拉格朗日函数进行最大化:对拉格朗日函数进行求导,并令导数为0,求解得到最大化的拉格朗日函数。
-
求解原始问题的最优解:通过求解对偶问题得到的最大化拉格朗日函数,可以得到原始问题的最优解。
对偶问题的优势在于,通过对原始问题进行转换,可以简化优化过程并减少计算的复杂度。此外,对偶问题还能够帮助我们获得更多关于SVM模型的信息,例如支持向量的识别和核函数的选择。
总结起来,对偶问题是通过引入拉格朗日乘子,将原始的SVM优化问题转化为一个更简化的等价问题。通过求解对偶问题,我们可以得到原始问题的最优解,并且获得与SVM相关的其他重要信息。
拉格朗日乘数法
等式约束优化
本科高等数学学的拉格朗日程数法是等式约束优化问题:
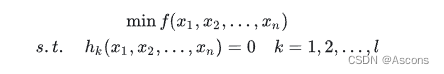
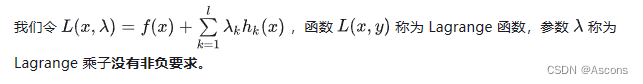
利用必要条件找到可能的极值点:
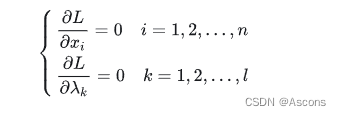
具体是否为极值点需根据问题本身的具体情况检验。这个方程组称为等式约束的极值必要条件。
不等式约束优化
例:
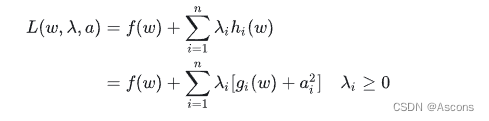


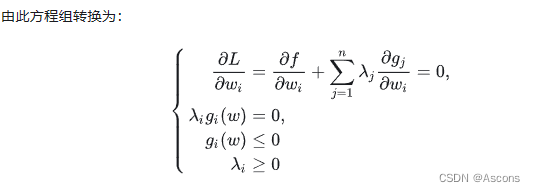
以上便是不等式约束优化优化问题的 KKT(Karush-Kuhn-Tucker) 条件, 为 KKT 乘子。
核函数
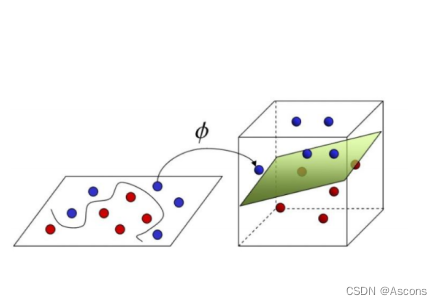
在SVM算法中,核函数是用于将数据从原始特征空间映射到一个高维空间中的一种技术。它能够克服在低维特征空间中线性不可分的问题,从而实现对非线性问题的分类。核函数主要作用是计算样本之间的内积,以度量它们之间的相似性。在SVM的求解过程中,核函数被用于替代原始优化问题中的内积运算,从而将样本映射到一个高维的特征空间中进行处理。
常用的核函数类型包括线性核函数、多项式核函数、径向基核函数(RBF)和Sigmoid核函数。线性核函数通过计算两个向量的内积来度量它们之间的相似性,在处理线性可分的问题时效果较好。多项式核函数将向量映射到高维空间中进行处理,效果取决于选择的多项式次数和系数。RBF核函数是最常用的核函数类型之一,通过计算向量之间的欧几里得距离来度量它们之间的相似性。Sigmoid核函数通过将向量映射到高维空间中进行处理,通常用于二元分类问题。
选择合适的核函数对于SVM的性能至关重要。根据数据的特点和实际需求来进行选择。例如,在处理图像分类问题时,常用的核函数是RBF核函数,而在自然语言处理(NLP)中,使用线性核函数或多项式核函数可能更为合适。
总之,核函数是SVM算法中的一个重要步骤,它能够将样本映射到高维特征空间中,从而实现对非线性问题的分类。不同的核函数类型都有各自的优缺点,需要根据实际情况进行选择。
我们常用核函数有:
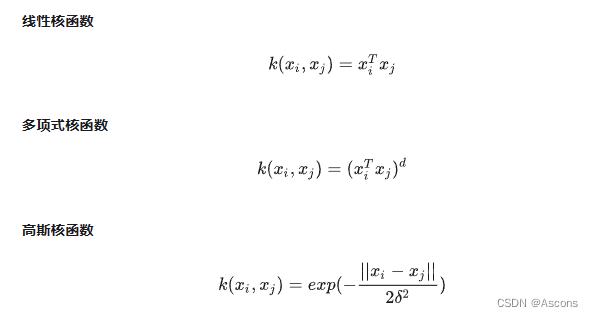
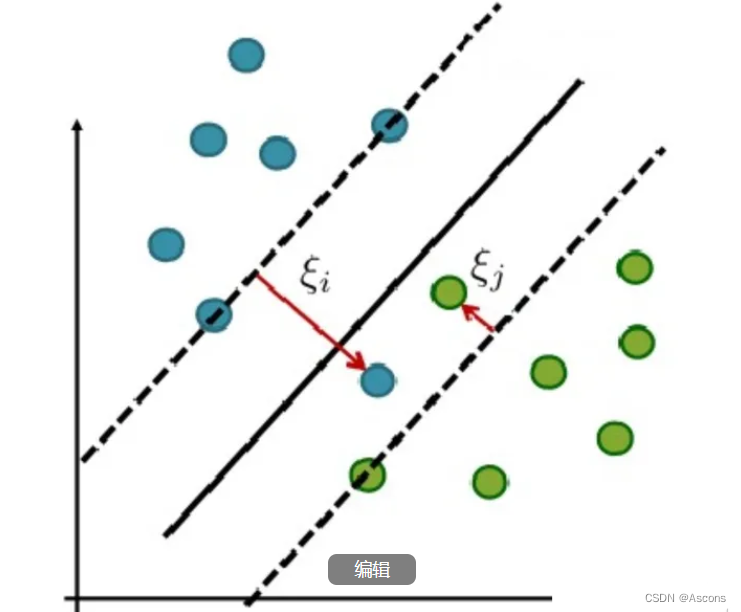
软间隔
在实际应用中,完全线性可分的样本是很少的,如果遇到了不能够完全线性可分的样本,我们应该怎么办?比如下面这个: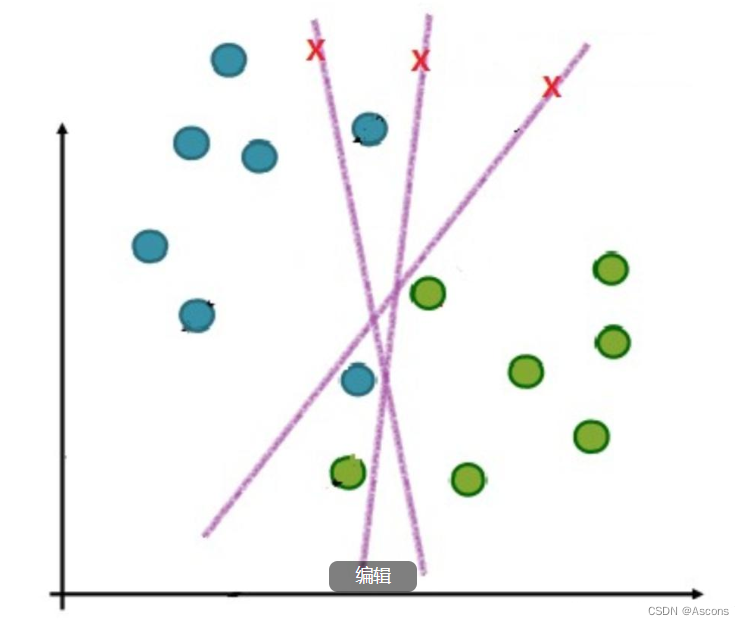
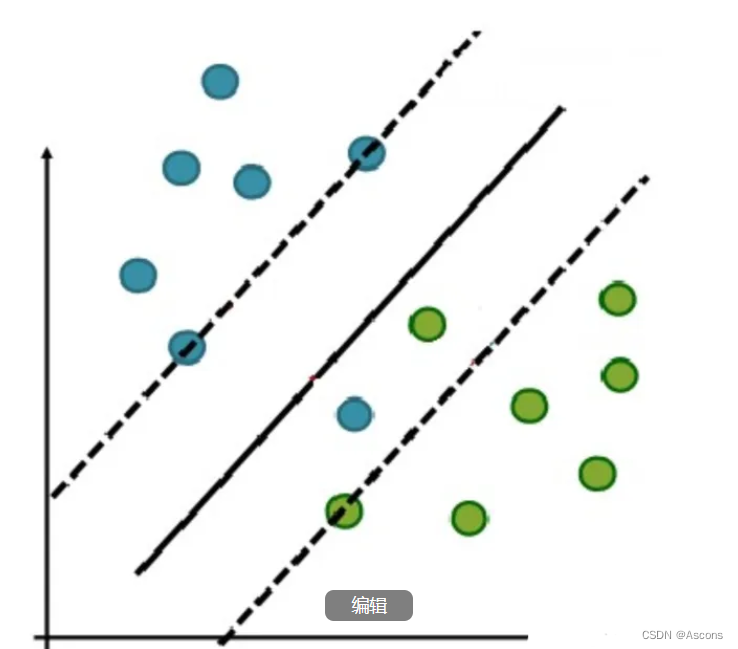
于是我们就有了软间隔,相比于硬间隔的苛刻条件,我们允许个别样本点出现在间隔带里面,比如:

支持向量回归
支持向量回归(Support Vector Regression,SVR)是一种基于支持向量机(SVM)的回归算法。与传统的回归算法不同,SVR通过使用支持向量机的思想和技巧,可以处理非线性问题,并具有较好的泛化能力。
SVR的目标是找到一个函数,使其尽可能拟合训练数据的分布,并且使得预测值与真实值之间的误差最小化。在SVR中,我们通过构建一个ε-tube(ε-管)来确定超平面,其中ε被称为容错范围,允许一定程度的误差。我们的目标是使所有的训练样本都落在这个管道内,并且最大化管道的边界。
SVR的求解过程可以概括为以下几个步骤:
-
数据预处理:对输入数据进行归一化或标准化处理,以便更好地进行模型训练和预测。
-
核函数选择:选择适当的核函数,将输入数据映射到高维空间中,以处理非线性问题。常用的核函数包括线性核函数、多项式核函数和径向基核函数(RBF)等。
-
模型训练:通过最小化目标函数,寻找最优的超平面或ε-tube,以使拟合误差最小化。在训练过程中,支持向量被识别为对模型拟合最重要的样本点。
-
模型预测:使用训练好的模型对新的输入数据进行预测,并根据实际需求对预测结果进行后处理。
SVR具有以下特点和优势:
- 可以处理非线性问题:通过核函数的引入,SVR可以处理非线性关系,从而更好地拟合非线性数据分布。
- 具有较好的泛化能力:SVR通过最小化目标函数,使得模型对训练数据的误差最小化,并通过支持向量来表示训练数据的关键特征,从而具有较好的泛化能力。
- 可以控制拟合的复杂度:通过调整超参数,如容错范围ε和惩罚因子C,可以控制模型的复杂度,并避免过拟合。
- 对离群点具有较好的鲁棒性:由于SVR通过支持向量来表示训练数据的关键特征,对于离群点具有较好的鲁棒性。
需要注意的是,SVR的性能和效果受到核函数的选择、超参数的调整以及数据预处理等因素的影响。因此,在实际应用中,需要根据具体问题进行调优和优化,以获得最佳的SVR模型。
SVM基础代码实现
- from sklearn import datasets
- from sklearn.model_selection import train_test_split
- from sklearn.svm import SVC
-
- # 加载数据集
- data = datasets.load_iris()
- X = data.data
- y = data.target
-
- # 将数据集拆分为训练集和测试集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
-
- # 创建SVM分类器
- svm = SVC()
-
- # 在训练集上训练模型
- svm.fit(X_train, y_train)
-
- # 在测试集上进行预测
- y_pred = svm.predict(X_test)
-
- # 输出预测结果
- print("预测结果:", y_pred)
-
- # 输出准确率
- accuracy = svm.score(X_test, y_test)
- print("准确率:", accuracy)

使用了scikit-learn库中的SVC类来实现支持向量机分类器。数据集为鸢尾花数据集。
输出结果:
![]()
总结:
支持向量机是一种强大的机器学习算法,用于分类和回归。它通过最优超平面来分隔不同类别的样本,并具有较好的泛化能力和鲁棒性。然而,SVM在计算复杂度和参数选择方面存在挑战。在实际应用中,需要适当调整参数和进行模型优化。

