
热门标签
热门文章
- 1环境安装 (angular+ionic+cordova+Vue)
- 2【考研】数据结构考点——堆排序(含408真题)_数据结构堆排序例题
- 32023第一届机器人与软件工程前沿国际会议_长沙理工大学阮昌
- 4AI大预言模型——ChatGPT在地学、GIS、气象、农业、生态、环境应用_chatgpt store
- 5git clone下载文件到指定目录_git clone 如何将repo直接下载到某个文件夹
- 6CentOS 8 Steam & Docker_hcs 安装工具 fcd hcsd
- 7WPS Office JS宏实现批量处理Word中的表格样式_wps宏编辑器
- 8ionic/cordova环境搭建_ionic和cordova环境搭建分析
- 9【大数据处理】广州餐饮店铺爬虫并可视化,上传至hdfs_如和将爬虫数据存储到hdfs
- 10千年庭院 -余秋雨
当前位置: article > 正文
Spark读取文件系统的数据_spark统计hdfs文件行数
作者:IT小白 | 2024-06-24 17:45:12
赞
踩
spark统计hdfs文件行数
(1)在pyspark中读取Linux系统本地文件“/home/hadoop/test.txt”(如果该文件不存在,请创建并自由添加内容),然后统计出文件的行数;
- cat /home/hadoop/test.txt
- pyspark
- lines = sc.textFile("file:///home/hadoop/test.txt")
- line_count = lines.count()
- print("Line count:", line_count)

(2)在pyspark中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请创建并自由添加内容),然后统计出文件的行数;
- hadoop fs -cat /user/hadoop/test.txt
- pyspark
- lines = sc.textFile("hdfs:///user/hadoop/test.txt")
- line_count = lines.count()
- print("Line count:", line_count)

(3)编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请创建并自由添加内容),然后统计出文件的行数;通过 spark-submit 提交到 Spark 中运行程序。
- cd /opt/module/spark-3.0.3-bin-without-hadoop/mycode/
- touch File_Count.py
- vim File_Count.py
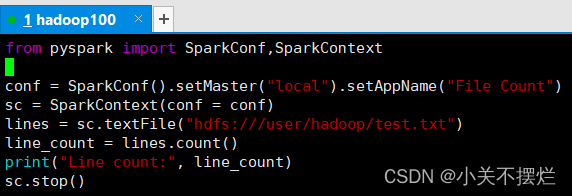
- from pyspark import SparkConf,SparkContext
- conf = SparkConf().setMaster("local").setAppName("File Count")
- sc = SparkContext(conf = conf)
- lines = sc.textFile("hdfs:///user/hadoop/test.txt")
- line_count = lines.count()
- print("Line count:", line_count)
- sc.stop()
- spark-submit File_Count.py


容易遇到的问题:
1.通过spark-sumbit运行程序时,会产生很多其他信息,执行结果会与其他信息混合在一起显示。可以通过修改log4j的日志显示级别,设置不显示INFO级别的信息,只输出自己的控制台输出的信息。
2.如果不想使用spark-submit提交,而尝试使用python运行程序时,显示no moudle named pyspark,这时需要vim ~/.bashrc配置环境变量,配置PYTHONPATH环境变量用来在python中引入pyspark库,PYSPARK_PYTHON变量用来设置pyspark运行的python版本,要特别注意/opt/module/spark-3.0.3-bin-without-hadoop/python/lib目录下的py4j-0.10.9-src.zip文件名,在PYTHONPATH的设置中需要使用。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/IT小白/article/detail/753492
推荐阅读
相关标签

