
- 1使用Python进行页面开发——模板层_{% block content %}
- 2在MacOS系统安装homebrew(2017年末版,持续更新)_mac chmod: unable to change file mode on memoryana
- 3[Unity2D入门教程]简单制作仿植物大战僵尸游戏之⑤制作更多的敌人Attacker以及防御者Defender_unity 2d教程
- 4NLP LLM(Pretraining + Finetuning)——理论篇
- 5想转行互联网方向,有哪些建议?
- 6云中 GPU的AI训练,显卡分配_如何为模型训练显卡算力分配
- 7在Windows10上安全弹出U盘的三种方法,总有一种适合你_硬盘显示为u盘可弹出
- 8字节跳动面试必问:数据对象的底层实现方式你都了解吗?年薪超过80万!_字节跳动 底层数据
- 9基于Flask框架开源自然语言处理模型运用学习系统的设计与实现_语言转换系统模型设计与说明
- 10赢在-人情世故:财富内在心法/气势道术/成事法则/走向成功/社交与人情策略
论文阅读【检测】CVPR2020 | Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Trai
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
论文地址:https://arxiv.org/abs/1912.02424.
code:github
Abstract
几年来,目标检测一直由基于锚点的检测器主导。近年来,由于FPN和Focal loss的提出,无锚点探测器得到了广泛的应用。本文首先指出基于锚点和无锚点检测的本质区别在于如何定义正训练样本和负训练样本,这导致了它们之间的性能差距。如果在训练过程中采用相同的正负样本定义,则无论是从一个盒子还是一个点进行回归,最终的成绩都没有明显的差异。这说明如何选择正负训练样本对于当前的目标检测器来说是非常重要的。在此基础上,提出了一种自适应训练样本选择算法(ATSS),根据对象的统计特性自动选择正负样本。它极大地提高了基于锚点和无锚点检测器的性能,弥合了两者之间的差距。最后,我们讨论了在图像上每个位置平铺多个锚点以检测目标的必要性。在MS Coco上进行的大量实验支持了我们前述的分析和结论。有了新推出的ATSS,我们在不引入任何开销的情况下,大大改进了最先进的检测器,达到50.7%的AP。代码可在https://github.com/sfzhang15/ATSS.上获得
一、Introduction
近年来,随着卷积神经网络(CNN)的发展,基于锚点的检测器在目标检测中占据主导地位,一般可分为一阶段方法和两阶段方法。这两种方法都是先对图像上的大量预设锚点进行平铺,然后对这些锚点进行类别预测,并对这些锚点进行一次或几次坐标细化,最后输出这些细化后的锚点作为检测结果。由于两阶段法比一阶段法细化anchor多次,因此前者具有更高的计算精度,而后者具有更高的计算效率。普通检测基准的最新结果仍然由基于锚的检测器持有。
最近学术界的注意力集中在无锚探测器上。anchor free检测器以两种不同的方式直接查找没有预设锚的对象。一种方法是首先定位几个预定义或自学习的关键点,然后限制对象的空间范围。我们称这种类型的无锚检测器为基于关键点的方法。另一种方法是使用对象的中心点或区域来定义正值,然后预测从正值到对象边界的四个距离。我们称这种无锚检测器为基于中心的方法。这些无锚点检测器能够消除那些与锚点相关的超参数,并取得了与基于锚点的检测器相似的性能,使它们在泛化能力方面更具潜力。
基于关键点的方法遵循不同于基于锚点的检测器的标准关键点估计pipeline。然而,基于中心的检测器类似于基于锚点的检测器,后者将点视为预设样本,而不是锚定盒。以基于锚点的一级检测器RetinaNet和基于中心的无锚点检测器FCOS为例,它们之间有三个主要区别:(1)每个位置平铺的锚点数量。RetinaNet为每个位置平铺多个锚点框,而FCOS为每个位置平铺一个锚点。(2)正负样本的界定。RetinanNet对正样本和负样本采用并集交集(IOU),而FCOS则利用空间和比例约束来选择样本。(3)回归启动状态。RetinanNet从预设anchor box退回对象边界框,而FCOS从anchor point定位对象。anchor-free的FCOS比基于锚点的RetinaNet取得了更好的性能,这三个差异中的哪一个是造成性能差距的关键因素值得研究。
从实验结果可以看出,这两种方法的本质区别在于正负训练样本的定义,这导致了它们之间的性能差距。如果他们在训练中选择相同的正负样本,无论是从一个盒子还是一个点进行回归,最终的成绩都没有明显的差距。因此,如何选取正负训练样本值得进一步研究。受此启发,我们提出了一种新的自适应训练样本选择算法(ATSS),它可以根据对象特征自动选择正负样本。它在基于锚定的检测器和无锚定检测器之间架起了一座桥梁。此外,通过一系列的实验,可以得出结论:没有必要在图像上的每个位置平铺多个锚点来检测目标。在MS Coco[34]数据集上的大量实验支持我们的分析和结论。最先进的AP 50.7%是通过应用新推出的A TSS实现的,而不会引入任何开销。这项工作的主要贡献可以概括为:
- 指出基于锚点的检测器和无锚点检测器之间的本质区别实际上是如何定义正训练样本和负训练样本。
- 提出了一种自适应训练样本选择方法,根据对象的统计特性自动选择正负训练样本
- 证明在图像上的每个位置平铺多个锚以检测对象是无用的操作
- 在MS Coco上实现最先进的性能,而不会带来任何额外开销。
二、Difference Analysis of Anchor-based and Anchor-free Detection
在不失一般性的前提下,本文采用了具有代表性的基于锚点的RetinaNet和无锚点的FCOS来分析它们之间的差异。在本节中,我们将重点介绍最后两个差异:正/负样本定义和回归开始状态。剩下的一个不同之处是:每个位置平铺的锚点数量,将在后续部分讨论。因此,我们只为Retinanet的每个位置平铺一个正方形锚点,这与FCOS非常相似。在接下来的部分中,我们首先介绍了实验设置,然后排除了所有实现上的不一致,最后指出了基于锚点的检测器和无锚点检测器的本质区别。
2.1 Essential Difference
在应用了普遍改进之后,基于anchor-based的RetinaNet(#A=1)和anchor-free的FCOS之间只有两个不同之处。一个是关于检测中的分类子任务,即定义正样本和负样本的方法。另一个是关于回归子任务,即从anchor box或anchor point开始的回归
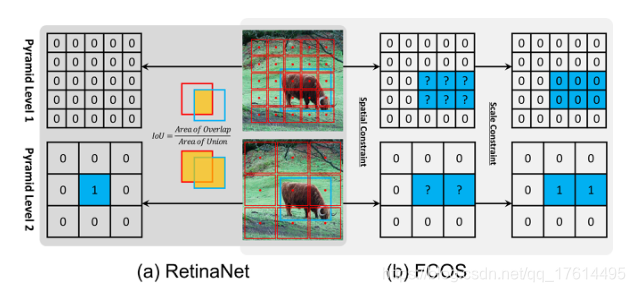
分类。如图1(a)所示,RetinaNet利用IoU将来自不同金字塔级别的锚盒分为正面和负面。该算法首先将每个对象的主锚盒和IOU> θ p θ_{p} θp的锚盒标记为正值,然后将IOU< θ n θ_{n} θn的锚盒标记为负值,最后在训练过程中忽略其他锚盒。如图1(b)所示,FCOS使用空间和比例约束来划分不同金字塔级别的锚点。它首先将ground-truth框内的anchor points作为候选正样本,然后根据为每个金字塔级别定义的尺度范围从候选中选择最终的正样本,最后未选择的anchor points为负样本。
如图1所示,FCOS首先使用空间约束来查找空间维度中的候选正数,然后使用比例约束来选择比例维度中的最终正数。相比之下,RetinaNet利用IoU同时直接选择空间和尺度维度上的最终正数。这两个不同的样本选择策略会产生不同的正面和负面样本。如RetinaNet表2第一列所列(#A=1),使用空间和规模约束策略而不是IOU策略可将AP性能从37.0%提高到37.8%。对于FCOS,如果使用IOU策略选择正样本,AP性能将从37.8%下降到36.9%,如表2第二栏所示。这些结果表明,正样本和负样本的定义是基于锚点的检测器和无锚点检测器的本质区别。

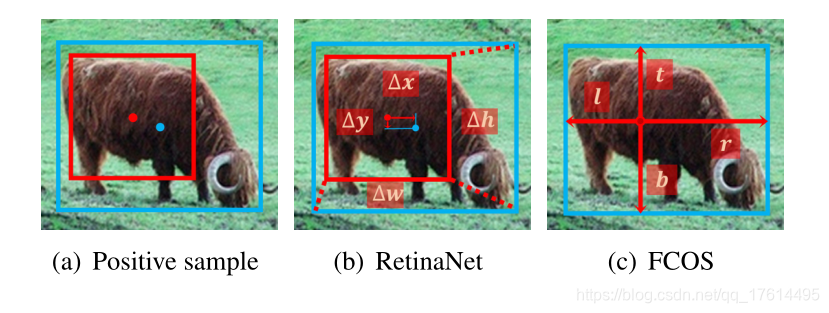
回归。在确定阳性和阴性样本之后,物体的位置从正样品回归,如图2(a)所示。RetinaNet从锚盒回归,锚盒与对象框之间有四个偏移,如图2(b)所示,而FCOS从锚点回归,以四个距离到物体的绑定,如图2(c)所示。这意味着对于正样本,Retinanet的回归起始状态是一个框,而FCOS是一个点。然而,如表2的第一行和第二行所示,当RetinaNet和FCOS采用相同的样本选择策略时具有一致的正/阴性样本,最终性能没有明显的差异,无论从点或a开始都会回归盒子,即37.0%与36.9%和37.8%与37.8%。这些结果表明回归启动状态是无关的差异而不是基本差异。
结论。根据这些实验,我们表明one-stage 基于锚的探测器和中心的锚定探测器的基本差异实际上是如何定义正负训练样本,这对于当前对象检测和应得的重要性是重要的进一步研究
三、Adaptive Training Sample Selection
培训对象检测器时,我们首先需要定义用于分类的正负样本,然后使用正样本进行回归。根据先前的分析,前者是至关重要的,anchor-free探测器FCOS改善了这一步骤。它引入了一种定义正样本和负样本的新方法,比传统的基于IoU的策略获得了更好的性能。受此启发,我们深入研究了目标检测中最基本的问题:如何定义正负训练样本,并提出了自适应训练样本选择(A TSS)。与这些传统策略相比,我们的方法几乎没有超参数,对不同的设置具有鲁棒性。
3.1 Description
以前的样本选择策略有一些敏感的超参数,例如基于锚的检测器中的IoU阈值和无锚检测器中的标度范围。设置这些超参数后,所有的地面真值盒都必须根据固定的规则选择它们的正样本,这适用于大多数对象,但一些外部对象将被忽略。因此,这些超参数的不同设置会有非常不同的结果。
为此,我们提出了ATSS方法,该方法根据统计特性自动划分正样本和负样本。算法1描述了所提出的方法如何对输入图像起作用。对于图像上的每个ground-truth box g g g,我们首先找出它的候选阳性样本。如第3行到第6行所述,在每个金字塔层次上,我们选择k个锚框,这些锚框的中心基于L2距离最接近 g g g的中心。假设有 L L L个特征金字塔层次,ground-truth框 g g g将有 k × L k × L k×L个候选正样本。之后,第7行我们计算这些候选值和ground-truth g( D g D_{g} Dg)之间的IoU,其平均值和标准偏差计算为 m g m_{g} mg和 v g v_{g} vg在第8行和第9行。根据这些统计数据,在第10行中,该ground-truth g g g的IoU阈值为 t g = m g + v g t_{g}=m_{g}+v_{g} tg=mg+vg。最后,我们在第11行到第15行中选择IoU大于或等于阈值 t g t_{g} tg作为最终正值样本的候选对象。值得注意的是,我们还将正值样本的中心限制在地面实值框中,如第12行所示。此外,如果一个锚点框被分配给多个地面实况框,则将选择IoU最高的那个。其余的都是阴性样本。我们方法背后的一些动机解释如下。

根据anchor box和对象之间的中心距离选择候选对象。对于RetinaNet,锚盒中心越靠近对象中心,IoU越大。对于FCOS,离对象中心越近的anchor point将产生更高质量的检测。因此,离对象中心越近的anchor是更好的候选对象。
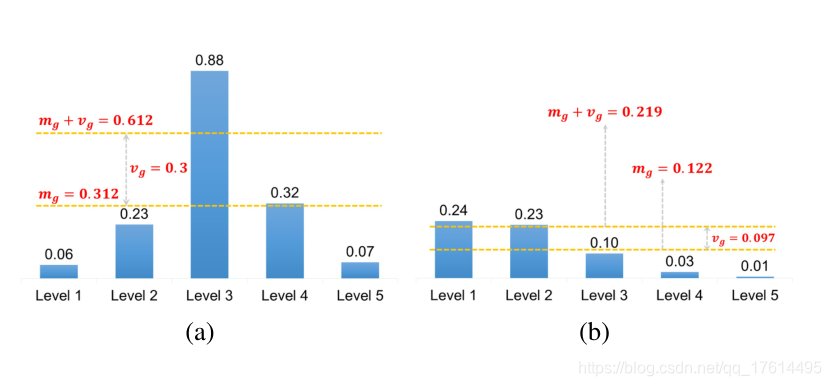
用均值和标准差之和作为IoU阈值对象的IOU平均值 m g m_{g} mg是对该对象的预置anchor的适合性的度量。图3(a)中显示的高 m g m_{g} mg表明它拥有高质量的候选者,并且IOU阈值应该很高。图3(b)中显示的较低的 m g m_{g} mg表示其大多数候选者质量较低,IOU阈值应该较低。此外,对象的IOU标准差 v g v_{g} vg是哪些层适合检测该对象的度量。图3(a)中所示的高 v g v_{g} vg意味着存在专门适合于该对象的金字塔级别,将 v g v_{g} vg加到 m g m_{g} mg获得仅从该级别选择正值的高阈值。图3(b)中所示的低 v g v_{g} vg意味着有几个适用于该对象的金字塔级别,将 v g v_{g} vg加到 m g m_{g} mg具有低阈值以从这些级别中选择适当的正值。以均值 m g m_{g} mg和标准差 v g v_{g} vg之和作为IOU阈值 t g t_{g} tg,可以根据对象的统计特性,自适应地从合适的金字塔层次中为每个对象选择足够的正值。
将正样本的中心限制在物体上。对象外有中心的锚点是差的候选,会被对象外的特征预测,不利于训练,应该排除。
维护不同对象之间的公平性。根据统计理论,理论上大约16%的样本在置信区间[ m g + v g m_{g}+v_{g} mg+vg,1]内。虽然候选对象的IoU不是标准正态分布,但统计结果显示,每个对象约有 0.2 ∗ k L 0.2 * kL 0.2∗kL个正样本,对其尺度、长宽比和位置不变。相比之下,RetinaNet和FCOS的策略往往对更大的对象有更多的正样本,导致不同对象之间的不公平。
保持几乎无超参数。方法只有一个超参数k,随后的实验证明它对k的变化非常不敏感,所提出的A TSS可以被认为几乎没有超参数。
3.2 other
结果表明,在传统的基于IoU的样本选择策略下,每个位置平铺更多锚boxer是有效的。使用我们提出的方法后,将得出相反的结论.只要正确选择阳性样本,无论每个位置平铺多少个锚,结果都是一样的。我们认为,在我们提出的方法下,每个位置平铺多个锚是无用的操作,需要进一步研究才能发现其正确的作用。
总结
张士峰团队的又一新作。刚看摘要就感觉有点像他们的风格,没想到一看作者真是他们。一贯的风格喜欢研究正负样本的问题和检测任务中一些本质的影响。非常nice。最近面试经常被问到这个ATSS 哈哈哈哈。

