
- 1软件开发常用文档模板(开发+实施+运维+安全+交付)_软件需求文档 生成
- 2微信小程序导航退回及跳转 传参(navigateBack,navigateTo)_微信小程序navigateback传参
- 3超详细,手把手带你快速入门GitHub_github 的 10 分钟快速入门教程(1)_github的install怎么创建
- 4数据结构——链表的实现(Java版)_java链表结构的实现
- 5Mysql跳过密码的验证(修改配置文件)_mysql跳过密码验证
- 6python 文本聚类可视化_使用K-means及TF-IDF算法对中文文本聚类并可视化
- 7Unity2D新手教程[安装和创建项目]_2021.3.34f1
- 8【vulnhub靶场】Fristileaks靶机提权
- 9Curator与zookeeper版本问题_curator4.0版本冲突
- 10AI大模型战场之争通用与垂直,各领风骚,谁将领跑落地新篇章?
今日arXiv最热NLP大模型论文:伯克利&DeepMind联合研究,RaLMSpec让检索增强LLM速度提升2-7倍!_大语言模型最新进展
赞
踩
引言:知识密集型NLP任务中的挑战与RaLM的潜力
在知识密集型自然语言处理(NLP)任务中,传统的大语言模型面临着将海量知识编码进全参数化模型的巨大挑战。这不仅在训练和部署阶段需要大量的努力,而且在模型需要适应新数据或不同的下游任务时,问题更加严重。为了应对这些挑战,近期的研究提出了检索增强型语言模型(Retrieval-augmented Language Models, RaLM),它通过检索增强将参数化的语言模型与非参数化的知识库结合起来。
RaLM通过一次性(one-shot)或迭代(iterative)的检索与语言模型的交互,来辅助生成过程。尽管迭代式RaLM在生成质量上表现更好,但它由于频繁的检索步骤而遭受高昂的开销。因此,本文提出了一个问题:我们能否在不影响生成质量的情况下减少迭代式RaLM的开销?
为了解决这一问题,我们提出了RaLMSpec框架,它采用推测性检索(speculative retrieval)和批量验证(batched verification)来减少迭代式RaLM的服务开销,同时保证模型输出的正确性。RaLMSpec利用了计算机体系结构中的推测执行概念,通过更高效但不那么精确的推测性检索步骤来替代昂贵的迭代检索步骤。通过进一步引入预取(prefetching)、最优推测步长调度器(optimal speculation stride scheduler)和异步验证(asynchronous verification),RaLMSpec能够自动地充分利用加速潜力。
在对三种语言模型在四个下游QA数据集上的广泛评估中,RaLMSpec在保持与基线相同的模型输出的同时,实现了显著的速度提升。这些结果表明,RaLMSpec可以作为一个通用的加速框架,用于服务迭代式RaLM。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
论文标题:
ACCELERATING RETRIEVAL-AUGMENTED LANGUAGE MODEL SERVING WITH SPECULATION
论文链接:
https://arxiv.org/pdf/2401.14021.pdf
RaLM与传统语言模型的对比
传统语言模型的局限性
传统的大型语言模型(如GPT-3、LLaMA-2、PaLM)在多样化的自然语言处理(NLP)任务中表现出色,但它们在训练和部署时需要巨大的努力来编码大量知识。当基础模型需要适应新数据或不同的下游任务时,这种情况会进一步恶化。例如,将知识编码到完全参数化的模型中,如GPT-3,需要在训练和部署中投入大量的努力。此外,当基础模型需要适应新数据或多种下游任务时,这种情况会变得更加严峻。
RaLM的优势与应用
为了解决这一挑战,最近的工作引入了检索增强型语言模型(RaLM),它通过检索增强将参数化语言模型与非参数化知识库集成。RaLM在低成本适应最新数据和更好的源归因机制方面表现出色。与传统语言模型相比,RaLM通过结合非参数化知识库与参数化语言模型,展现了解决知识密集型NLP任务的潜力。例如,迭代RaLM由于检索器和语言模型之间更频繁的交互,提供了更好的生成质量。然而,迭代RaLM通常由于频繁的检索步骤而遇到高开销。
RaLMSpec框架的提出
迭代RaLM的效率瓶颈
现有的迭代RaLM方法的一个关键瓶颈是检索的低效率。由于生成性语言模型的自回归特性,检索步骤通常是以单个查询进行的,该查询总结了当前的上下文。现有的迭代RaLM方法通过不断地使用最新的上下文依赖查询(例如q0、q1和q2)从知识库中检索,交错执行检索步骤和生成步骤。相应检索到的内容(如A、B、C)然后通过提示或注意力级组合帮助生成过程,提供相关信息。然而,顺序发出这些查询以检索知识库在本质上是低效的。
RaLMSpec框架的核心思想
RaLMSpec框架采用了推测性检索与批量验证的方法,以减少迭代RaLM的服务开销,同时在理论上保留模型输出。RaLMSpec通过推测性检索替代现有RaLM方法中昂贵、迭代的检索步骤,采用更高效但准确度较低的推测性检索步骤。因此,RaLMSpec使用批量验证步骤来纠正任何不正确的推测结果,并保持模型的生成质量。更具体地说,经过一系列推测性检索步骤后,RaLMSpec通过执行批量检索(即图1(b)中的➅),启动验证步骤,其中批次中的查询对应于推测性检索步骤中的查询。如果推测的文档与验证步骤中检索到的真实文档之间存在不匹配,RaLMSpec会通过回滚到第一个错误推测的位置并使用真实文档重新运行语言模型解码来自动纠正不匹配。结果显示,RaLMSpec通过高效的批量检索,即使用n个查询从知识库检索比顺序执行n次检索更高效,从而节省了延迟。
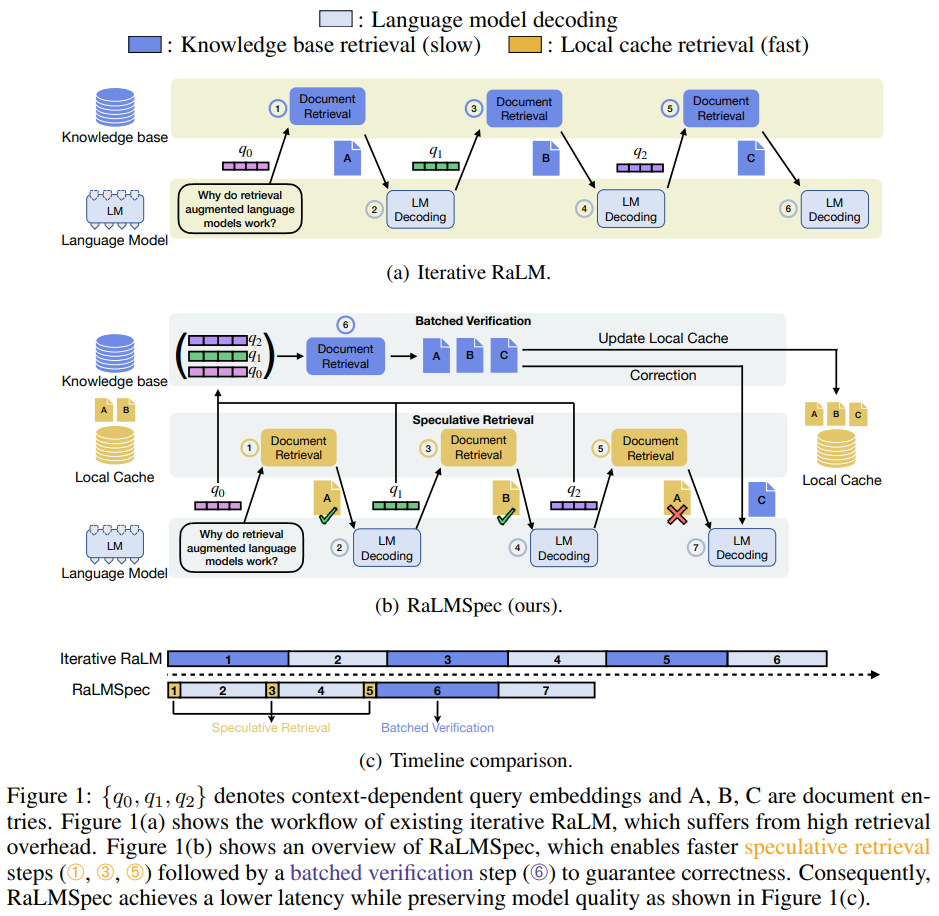
RaLMSpec的工作原理
推测性检索与批量验证
RaLMSpec框架通过推测性检索(speculative retrieval)与批量验证(batched verification)来减少迭代式检索增强语言模型(iterative RaLM)的服务开销,同时保证模型输出的正确性。推测性检索的概念源自计算机架构中的推测执行(speculative execution),其核心思想是用更高效但准确度较低的推测性检索步骤替代昂贵的迭代检索步骤。在进行了一定数量的推测性检索后,RaLMSpec会启动一个批量验证步骤,其中批量查询对应于推测性检索步骤中的查询。如果推测得到的文档与验证步骤中检索到的真实文档不匹配,RaLMSpec会自动回滚到第一个错误推测的位置,并使用真实文档重新运行语言模型解码。
本地缓存与预取技术
RaLMSpec利用本地缓存(local cache)来存储每个请求的过去文档,并在推测性检索中使用本地缓存而非知识库进行检索。这种方法利用了检索文档的时空局部性(temporal and spatial locality),即在生成过程中可能会多次检索到相同或连续的文档。为了提高推测成功率,RaLMSpec在每次验证步骤中更新本地缓存,直接添加从知识库检索到的相同或连续文档。此外,RaLMSpec支持缓存预取(cache prefetching),通过在本地缓存中预先存储来自知识库的top-k检索文档,以提升推测性能。
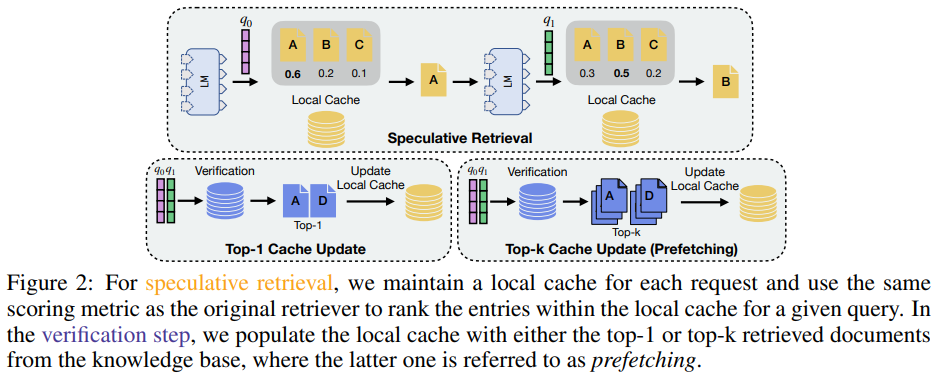
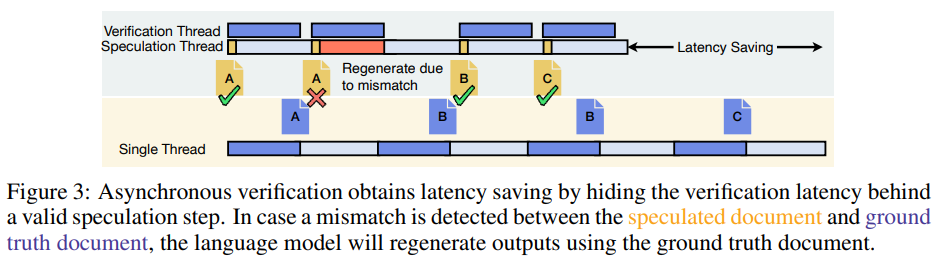
异步验证与最优推测步长调度器
RaLMSpec通过允许异步验证(asynchronous verification)来提高并发性,使得额外的推测步骤可以与验证步骤异步执行。这种技术在验证延迟小于语言模型解码延迟的情况下特别有益。此外,RaLMSpec引入了最优推测步长调度器(Optimal Speculation Stride Scheduler, OS3),它动态调整推测步长(speculation stride),即两次验证步骤之间连续推测步骤的数量,以最小化推测开销。
实验设置与评估方法
语言模型与数据集选择
实验中选用了三种标准的自然语言生成(NLG)模型类别:GPT-2、OPT和LLaMA-2。这些模型被广泛用作RaLM的基础语言模型,并覆盖了不同的模型大小。实验涉及的知识密集型开放域问答任务数据集包括Wiki-QA、Web Questions、Natural Questions和Trivia-QA。
检索器类型与基线比较
为了展示RaLMSpec的一致性,实验中测试了包括密集型检索器(dense retrievers)和稀疏检索器(sparse retrievers)在内的不同检索器。对于密集型检索器,进一步区分了精确(exact)和近似(approximate)方法。基线实现对于迭代式RaLM服务,直接遵循了现有的实现,其中检索是在语言模型生成每四个令牌后触发。对于KNN-LM服务,基线使用了Khandelwal等人(2019)的实现,其中检索在生成每个令牌时执行。
实验结果与分析
RaLMSpec在不同检索器上的性能
RaLMSpec框架在不同类型的检索器上表现出了显著的加速效果。具体来说,当使用精确的密集检索器(Exact Dense Retriever, EDR)时,RaLMSpec能够实现最高2.39倍的加速比;而在使用近似的密集检索器(Approximate Dense Retriever, ADR)时,加速比为1.04至1.39倍;对于稀疏检索器(Sparse Retriever, SR),加速比介于1.31至1.77倍之间。这些结果表明,RaLMSpec在处理迭代式检索增强语言模型(iterative RaLM)的服务时,能够有效减少检索步骤所带来的高开销,同时保持模型输出的质量。
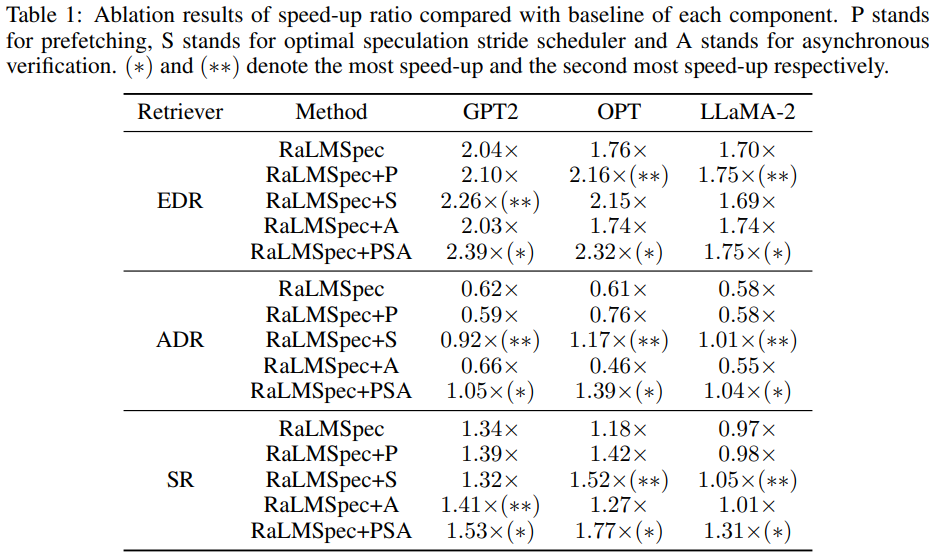
各组件对加速效果的贡献
RaLMSpec的加速效果归功于几个关键组件的协同工作。首先,本地缓存的使用为推测性检索提供了基础,通过存储过去的文档来加速后续的检索步骤。其次,批量验证步骤通过并行处理多个查询来校正任何不正确的推测结果,从而保证了模型输出的正确性。此外,预取机制(prefetching)通过将知识库中的前k个检索文档添加到本地缓存中,进一步提高了推测性能。最后,通过动态调整推测步长(speculation stride)和允许异步验证,RaLMSpec能够自动地发掘出最大的加速潜力。
KNN-LM服务的RaLMSpec评估
KNN-LM的挑战与RaLMSpec的适用性
KNN-LM(K-Nearest Neighbour Language Models)是一种在生成下一个词分布时,会通过插值方式结合来自检索到的k个最近邻文档的分布和语言模型输出的方法。尽管KNN-LM在提高基础语言模型的困惑度(perplexity)方面非常有效,但它在推理过程中的开销是极其高昂的,因为每一步生成都需要进行检索。RaLMSpec通过修改缓存更新规则和验证协议,能够显著提高KNN-LM的服务速度,即使在k值较大时(例如k=1024)也能实现高达3.88倍的加速比。
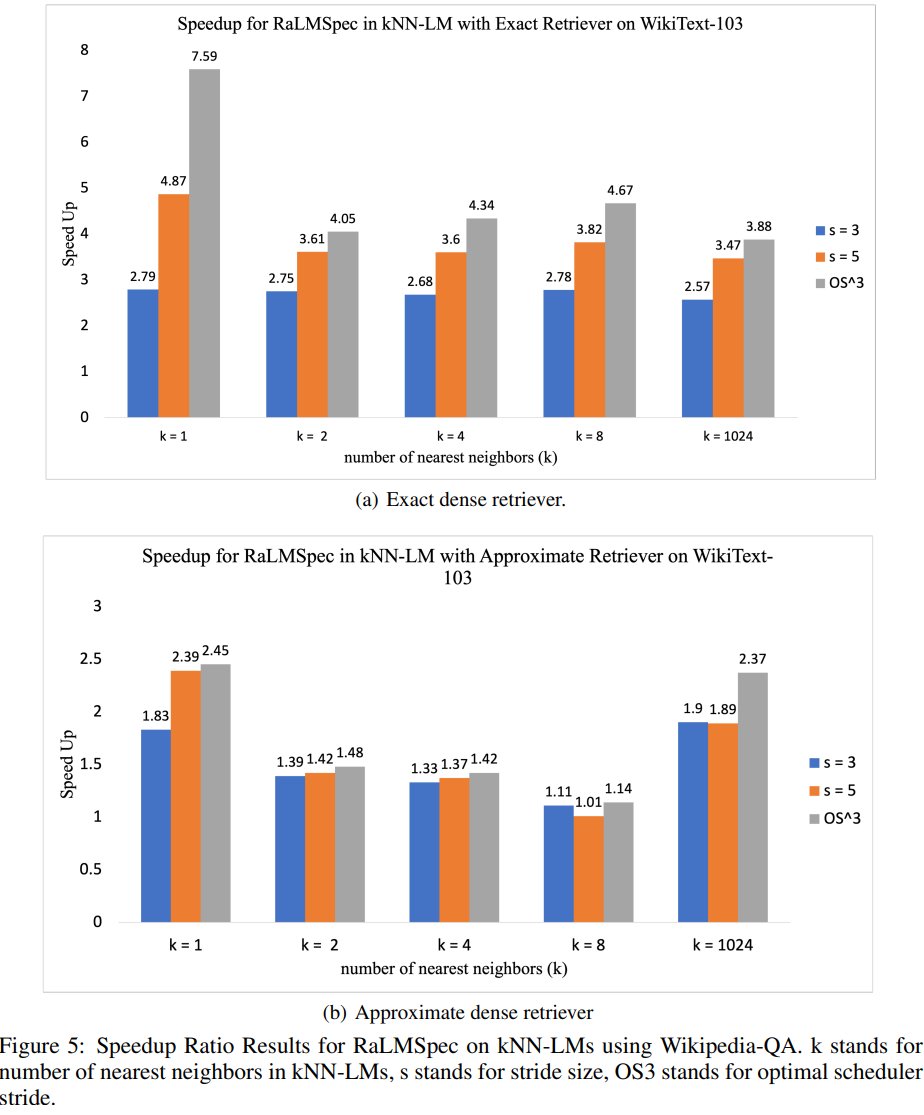
RaLMSpec在KNN-LM上的加速效果
在KNN-LM的服务中,RaLMSpec通过推测性检索和批量验证,显著减少了每个令牌生成步骤所需的检索开销。实验结果显示,当使用精确的密集检索器时,RaLMSpec能够实现最高7.59倍的加速比;而在使用近似的密集检索器时,加速比可达2.45倍。这些结果证明了RaLMSpec在处理检索密集型工作负载时的有效性,并且通过启用最优推测步长调度器(OS3),RaLMSpec能够在不同的场景中一致地实现最佳性能。
讨论与未来工作
RaLMSpec的潜在应用与扩展
RaLMSpec框架通过引入推测性检索(speculative retrieval)和批量验证(batched verification)的概念,为迭代式检索增强语言模型(iterative RaLM)提供了显著的服务加速,同时保持了模型输出的质量。这一机制的潜在应用范围广泛,不仅限于当前的问答(QA)任务,也可能扩展到其他知识密集型自然语言处理(NLP)任务中,例如机器翻译、文本摘要或对话系统。
在未来的工作中,RaLMSpec可以进一步与新兴的大语言模型(如LLaMA-2, GPT-3, PaLM)集成,以提高这些模型在实际应用中的效率。此外,RaLMSpec的推测性检索和批量验证机制也可以与其他类型的检索器(如TF-IDF或BM25)结合,以探索在不同检索精度和效率权衡下的性能表现。
挑战与未来研究方向
尽管RaLMSpec在多个数据集和语言模型上展示了其加速能力,但在实际部署时仍面临一些挑战。例如,推测性检索的成功率高度依赖于检索的时空局部性(temporal/spatial locality),这可能在某些任务或数据集中不那么显著。此外,批量验证步骤的效率取决于并行处理能力,这可能受限于硬件资源。
未来的研究可以探索如何优化RaLMSpec的各个组件,例如改进本地缓存策略、调整预取(prefetching)大小或进一步优化异步验证(asynchronous verification)机制。此外,研究者也可以探索自适应调整推测步长(speculation stride)的算法,以便在不同的运行时环境中动态平衡推测性能和验证开销。
总结:RaLMSpec在提升RaLM服务效率中的贡献
RaLMSpec通过引入推测性检索和批量验证,显著提高了迭代式检索增强语言模型的服务效率。实验结果表明,RaLMSpec能够在保持模型输出质量的同时,实现对不同检索器(包括精确密集检索器、近似密集检索器和稀疏检索器)的显著加速。特别是在使用精确密集检索器时,RaLMSpec+PSA(结合预取、最优推测步长调度器和异步验证)能够与基线相比,在不同的语言模型和数据集上实现高达2.39倍的加速比。
此外,RaLMSpec的三个附加技术——预取、最优推测步长调度器(OS3)和异步验证——进一步降低了RaLM服务的延迟。这些技术的组合使用,使得RaLMSpec能够在各种场景中自动地、一致地实现最佳的加速比,证明了其作为迭代式RaLM服务的通用加速框架的潜力。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接!


