
- 1c++ stringstream_c++ stringstream清空
- 2【小程序】发布商品(上传图片、数据校验)_10rpx
- 3GPT磁盘及ID号介绍_gpt分区id
- 4实验4《算符优先分析法设计与实现》(java版)_实验4《算符优先分析法设计与实现》(java版)
- 5Linux ln命令 软链接和硬链接_linux lvm创建分区
- 6实验三、SPARK RDD基础编程方法二_ubuntu的spark实验rdd
- 7代码逻辑分析_借助Elaborated Design优化RTL代码
- 8如何解决mfc100u.dll丢失问题,关于mfc100u.dll丢失的多种解决方法
- 9数据挖掘十大经典算法_数据挖掘十大经典算法及各自优势
- 10数据结构(用 JS 实现栈和队列【三种方式】)
机器学习--处理分类问题常用的算法(一)_机器学习中对于多变量二分类问题方法
赞
踩
下面的题都是来自于牛客网的面试宝典
1.交叉熵
交叉熵损失函数一般用于求目标与预测值之间的差距。
信息量:假设一个离散型随机变量x,某事件发生的概率为p(x0) ,p(x0) 的取值范围在[0,1],该事件发生的信息量为
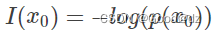
熵:对于某个问题而言,可能存在n个可能发生的事件,每个可能发生的事件都有各自的一个概率,也有对应的信息量。熵是用来表示所有信息量的期望,公式如下:
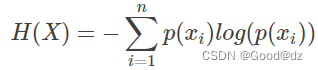
相对熵(KL散度):在机器学习中,P往往用来表示样本的真实分布,比如[1,0,0]表示当前样本属于第一类。Q用来表示模型所预测的分布,比如[0.7,0.2,0.1]。KL散度的计算公式:
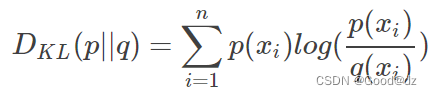
交叉熵的公式为:KL散度-熵
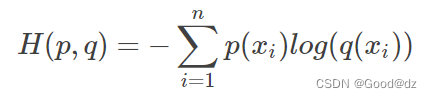
注:交叉熵损失函数能适用于二分类和多分类问题
2.LR公式
???
3.逻辑回归怎么实现多分类
方式一:修改逻辑回归的损失函数,使用softmax函数构造模型解决多分类问题,softmax分类模型会有相同于类别数的输出,输出的值为对于样本属于各个类别的概率,最后对于样本进行预测的类型为概率值最高的那个类别
方法二:根据每个类别都建立一个二分类器,本类别的样本标签定义为1,其他分类样本标签定义为0,则有多少个类别就构造多少个逻辑回归分类器。
若所有类别之间有明显的互斥,则使用softmax分类器;若所有的类别不互斥有交叉的情况,则构造相应的类别个数的逻辑回归分类器。
4.SVM中什么时候用线性核?什么时候用高斯核?
当数据的特征提取的较好,所包含的信息量足够大,问题是线性可分,那么采用线性核。若特征数较少,样本数适中,对于时间不敏感,遇到的问题是线性不可分的,那么使用高斯核
5.什么是支持向量机,SVM与LR的区别?
支持向量机为一个二分类模型,它的基本模型定义为特征空间上的间隔最大的线性分类器。而它的学习策略为最大化分类间隔,最终可转换为凸二次规划问题求解。
LR是参数模型,SVM为非参数模型。LR采用的损失函数为logisticalloss,而SVM采用的是hingeloss。 在学习分类器的时候,SVM只考虑与分类最相关的少数支持向量点。LR的模型相对简单,在进行大规模线性分类时,比较方便。
6.监督学习和无监督学习的区别
输入的数据有真实标签为监督学习
输入的数据无真实标签为非监督学习
7.机器学习中的距离计算方法?
在很多研究问题中,常常需要估算不同样本之间的相似度,这时通常采用的方法就是计算样本间的“距离”。
(1)欧式距离
欧式距离是一个通常采用的距离定义,指的是两个点之间的真实距离。
二维:
 三维:
三维:
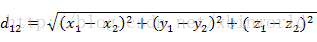 n维:
n维:
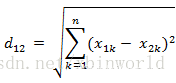
(2)曼哈顿距离
我们可以定义曼哈顿距离的正式意义为L1-距离或城市区块距离,也就是:在欧几里德空间的固定直角坐标系上两点所形成的线段对轴产生的投影的距离总和
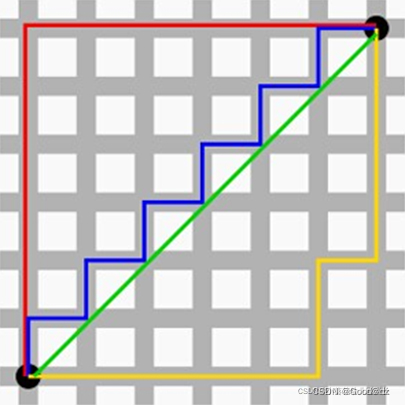
在平面上,坐标点(x1,y1)与坐标点(x2,y2)的曼哈顿距离为:
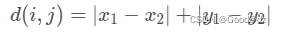
(3)余弦距离
一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小
余弦值接近1,夹角趋于0,表明两个向量越相似
余弦值接近0,夹角趋于90度,表明两个向量越不相似
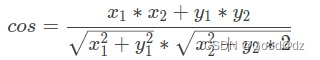
(4)切比雪夫距离
切比雪夫距离是向量空间中的一种度量,二个点之间的距离定义是其各坐标数值差绝对值的最大值.
二维平面两点:
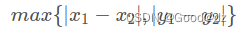
两个n维向量:
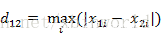
8.朴素贝叶斯法的要求?
要求是贝叶斯定理、特征条件独立假设
朴素贝叶斯属于一个生成式模型,学习输入和输出的联合概率分布。给定输入x,利用贝叶斯概率定理求出最大的后验概率作为输出y
9.训练集中类别不均衡。哪个参数最不准确?
准确度
举例:对于二分类问题来说。正负样例比相差较大为99:1,模型更容易被训练成预测较大占比的类别。因为模型只需要对每个样例按照0.99的概率预测正类,该模型就能达到99%的准确度。
10.SVM的作用,基本实现原理
SVM可以用于解决二分类或者多分类问题,此处以二分类为例。SVM的目标是寻找一个最优化超平面在空间中分割两类数据,这个最优化超平面需要满足的条件是:离其最近的点到其的距离最大化,这些点被称为支持向量
11.SVM的物理意思是什么?
构造一个最优化的超平面在空间中分割数据
12。如果数据有问题,怎么处理?
1上下采样平衡正负样例比
2.考虑缺失值
3.数据归一化

