
- 1汽车保单查询介绍
- 2从小厂到大厂,从功能测试到自动化测试,做一个不迷茫的技术人!_进厂 功能测试
- 3TCP服务器—实现数据通信_lis 接口 tcp 服务器 发送数据
- 4(内含福利!!) 8月17日,邀您共赴南京Unstructured Data Meetup!
- 5【SCP命令】安全又快捷的linux小技巧scp命令_scp linux
- 6Ubuntu20.04版本命令行设置挂载磁盘,并设置开机自动挂载_ubuntu 自动挂载
- 7微软服务器更新通知,产品技术-微软安全公告 MS17-010 Microsoft Windows SMB 服务器安全更新 (4013389)-新华三集团-H3C...
- 8[Spark]一、Spark基础入门
- 9Hadoop 之分布式计算框架MapReduce_hadoop分布式计算框架
- 10Nvidia系列 之 在搭载 A10 Nvidia GPU 的 OCI Bare Metal 上部署 Llama3 70B 模型(教程含源码)_llama370b需要多少显卡
数据恢复与硬盘修理_pc3000 isa工具软件的组成
赞
踩
目录
第1篇 数据恢复与硬盘修理基础
本篇包括第1章,主要介绍数据恢复的发展现状、硬盘维修的基本知识以及一些基本工具的使用。
第1章 基础知识
1.1 数据恢复技术的发展和研究现状
目前国内的数据恢复服务市场处于一个极不规范的状态。虽然大部分数据恢复服务提供商是有职业道德的,能够为客户提供相对可靠的服务,但也有个别商家的行为极为恶劣——尤其是那些吹嘘自己是“行业领导者”的商家,除了炮制一系列所谓的“成功案例”外,拿不出任何真正的技术,甚至连操作过程都不敢让客户看到。他们不仅对用户数据极不负责任,拿着用户重要的血汗数据去“练手”,而且更为恶劣的是,对那些无法只靠运气来恢复的数据,他们竟采用异常无耻的手段进行破坏,造成用户数据彻底丢失,甚至厚颜无耻地说:“我们恢复不出来,谁也恢复不了!”而用户往往都是第一次接触数据恢复行业,哪里有选择的余地?只能听其摆布。所以笔者曾经说:“现在用户寻找恢复数据服务提供商,就像是一场赌博。”当前国际上对数据恢复技术的基本分类如图1-1所示。
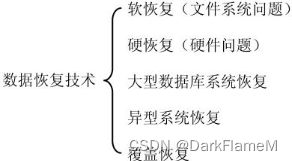
图1-1 数据恢复技术的基本分类
· 软恢复
软恢复指的是恢复存储系统,或操作系统,或文件系统层的数据。这种丢失是多方面的,如系统软/硬件故障、死机等原因造成的数据丢失,以及病毒破坏、黑客攻击、木马破坏、误操作、阵列数据丢失等造成的数据丢失。对于一般的文件系统来说,这方面的研究工作起步较早,国内外研究得都比较深。软恢复的主要难点是文件碎片的恢复处理、文档修复和复杂密码的恢复。
· 硬恢复
硬恢复指的是恢复由于硬件故障而丢失的数据,如硬盘电路板损坏、盘体损坏、磁道损坏、磁盘片损坏、硬盘内部系统区严重损坏等。这些情况几乎都会导致系统不认盘或认盘困难,恢复起来难度较大。如果内部盘片数据区严重划伤,会造成数据彻底丢失。另外,如果硬盘内部系统(即人们常说的“固件系统”)出现问题,也会导致类似不认盘或不能正常读取的现象,而且由于恢复硬盘固件数据通常需要使用专用工具,因此也常常把它归入硬恢复领域。稍有常识的用户,在出现这种情况(如移动硬盘跌落)后,不会尝试对硬盘反复加电,也就不会人为地造成更大面积的划伤,因此,这种情况下一般还是能够恢复大部分数据的。从目前的实践来看,对这类问题有两种处理方法:一种方法是直接找专业的数据恢复服务提供商,这时的故障硬盘称为“一手盘”,其中的数据几乎都能恢复;另一种方法是抱着侥幸心理,自己找熟人尝试修复,或者找所谓的“计算机专家”来处理,甚至去找“牛皮公司”(那种上来就说“没问题,我们什么都可以做”的数据恢复公司——天底下哪有100%的事情?更何况数据恢复本身只是一种补救措施)。这种最终才转到专业数据恢复公司的盘,我们称之为“二手盘”。对二手盘,之前不恰当的操作会对数据造成严重的二次破坏,因此恢复难度与成本会急剧上升。
· 大型数据库系统恢复
大型数据库系统中往往存储着一些非常重要的数据,其组成复杂,一般都有较完善的保护措施,所以通常不会出现小问题,但只要出现问题,基本上都是较难处理的问题,恢复的难度较大。典型的大型数据库系统主要有SQL Server、Informix、Sybase、Oracle和IBM UDB/DB2等。
· 异型系统恢复
异型系统的数据恢复指的是不常用的、比较少见的操作系统下的数据恢复,如MAC、OS2、嵌入式系统、手持系统、实时系统、智能仪器仪表使用的系统等。它们与数据库系统的恢复和文档碎片的修复,是作者所在团队目前致力解决的问题,研究成熟时将尽快公开结果。
· 覆盖恢复
数据被覆盖后,再要恢复的话,难度非常大,与其他4类数据恢复有着质的区别,目前可能只有硬盘厂商及少数国家的特殊部门才能做到。覆盖恢复的应用一般都与国家安全有关。在各种恢复手段中,水平相差最大的就是覆盖恢复。据说,美国军方可以成功恢复被覆盖了6~9次的数据,俄罗斯可以成功恢复被覆盖了3~4次的数据,IBM耗资6亿美元的研究成果是可以成功恢复被覆盖了1~2次的数据。由于这些都涉及国家核心机密,具体的细节和可靠性都尚不可知。目前市场上所说的恢复被GHOST覆盖的数据,也只是恢复硬盘中没有写入新数据的地方,并不是恢复已经写入新数据的地方,是一种非常简单的逻辑恢复。我国也正在进行覆盖恢复的深层技术研究。
1.2 数据恢复技术的层次与体系
从另一个角度来看,数据恢复技术的研究对象是存储系统,而存储系统是有体系、有层次的,因此,数据恢复技术的研究也是有体系、有层次的,如图1-2所示。
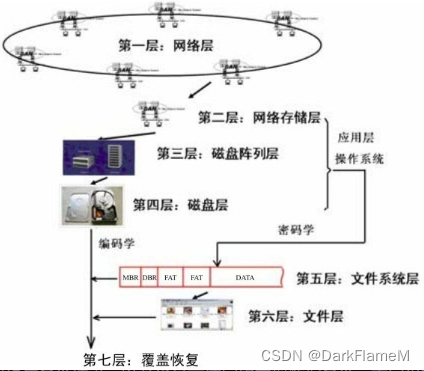
图1-2 存储系统的层次关系
1.网络层
通过网络技术可以实现远程备份。对数据恢复技术的学科体系来说,网络层的应用主要是远程同步与备份技术,以及通过高速网络实现数据备份。本层没有特别的恢复技术,只是在操作中应注意检查备份的有效性,并在出现问题时避免让损坏的数据破坏正常的数据。
2.网络存储层
网络存储层是一种基于独立系统的存储体系,是在传统的直接附加存储(DAS)基础上发展起来的智能存储系统。网络存储层一般都有自己的操作系统,因此可为各种平台应用提供统一的、兼容的数据服务,主要有存储区域网络(SAN)和网络附加存储(NAS)两种形式。
· DAS
DAS是“Direct Attached Storage”的缩写,译为“直接附加存储”。DAS将外置存储设备通过连接电缆直接连接到一台服务器上,如图1-3所示。
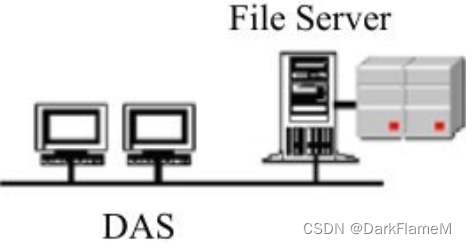
图1-3 直接附加存储(DAS)
采用DAS方案的服务器的结构如同PC的架构,外部数据存储设备采用SCSI技术或光纤通道(Fibre Channel, FC)技术直接挂接在内部总线上,数据存储是整个服务器结构的一部分,这种情况下常常是数据和操作系统都未分离。
DAS直连方式能够解决单台服务器的存储空间扩展与高性能传输需求。当前单台外置存储系统的容量已经发展到亿万字节(TB)级,随着大容量硬盘的推出,单台外置存储系统的容量还会上升。此外,DAS还可以构成基于磁盘阵列的双机高可用系统,以满足数据存储对高可用性的要求。
在这种存储系统体制下,如果因操作系统出现故障而导致存储系统不能读取数据,则往往只与操作系统直接相关。如果操作系统正常,而存储子系统不正常,可以通过对存储子系统的操作来恢复其可用性。
· NAS
NAS是“Network Attached Storage”的缩写,通常译为“网络附加存储”,其结构如图1-4所示。
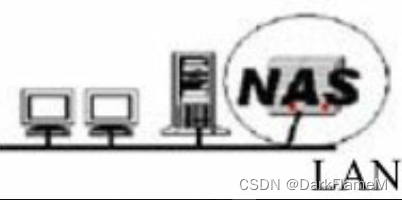
图1-4 网络附加存储(NAS)
NAS作为网络附加存储设备,采用了信息技术中流行的嵌入式技术,使其具有无人值守、高度智能、性能稳定、功能专一等特点。NAS设备内置优化的独立存储操作系统,可以有效地释放系统总线资源,全力支持I/O存储。同时,NAS设备大都集成本地备份软件,可以不经过服务器而直接将NAS设备中的重要数据进行本地备份。而且,NAS设备提供硬盘RAID、冗余电源和风扇以及冗余控制器,可以保证NAS的稳定运行。
NAS设备主要用于实现不同操作系统下的文件共享,与传统的服务器或DAS存储设备相比,NAS设备的安装、调试、使用和管理非常简单。使用NAS设备可以节省一定的管理与维护费用。
NAS设备提供RJ-45接口和单独的IP地址,可以直接将其挂接在主干网的交换机或其他局域网的集线器(Hub)上,通过简单的设置(如设置机器的IP地址等),用户就可以在网络上“即插即用”地使用NAS设备,而且进行网络数据在线扩容时也无须停顿,从而保证了数据的流畅存储。
可见,NAS是一个独立的存储子系统,出现问题后,需要直接对其进行恢复操作。问题可能出在其自身系统上,也可能出在存储设备上。
· SAN
SAN是英文“Storage Area Network”的缩写,通常译为“存储区域网络”,其结构如图1-5所示。
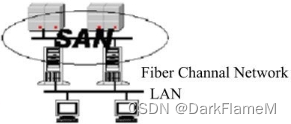
图1-5 存储区域网络(SAN)
SAN采用了FC技术。FC是ANSI(American National Standards Institute,美国国家标准学会)为网络和通道I/O接口建立的一个标准集成,它支持多种高级协议,最大特性是将网络和设备的通信协议与物理传输介质隔离,这样,多种协议可在同一个物理连接上同时传送。宽带网络使用单I/O接口的结构特点,使系统的架设成本和复杂程度大大降低。FC支持多种拓扑结构,主要有点到点结构、仲裁环结构和交换式网络结构。
SAN是企业级存储解决方案。目前,企业级存储解决方案所遇到的两个问题分别是数据与应用系统紧密结合所产生的结构性限制以及小型计算机系统接口(Small Computer System Interface, SCSI)标准的限制。在SAN中,存储设备通过专用交换机连接到一群计算机上。该网络提供了多主机连接,允许任何服务器连接到任何存储阵列,让多主机访问存储器像主机间的互相访问一样方便。这样,不管数据存储在哪里,服务器都可直接存取所需的数据。
SAN和NAS最大的区别在于NAS有文件系统和管理系统,但SAN却没有这样的系统功能(其功能仅仅停留在文件管理的下一层,即数据管理)。SAN却没有这样的系统功能(其功能仅仅停留在文件管理的下一层,即数据管理)。SAN和NAS并不冲突,它们可以共存于一个系统网络中,但NAS能够通过一个公共接口实现空间管理和资源共享,而SAN只是为服务器存储数据提供了一个专门的快速后方通道。随着NAS和SAN应用的发展,其数据恢复需求也越来越大。
3.磁盘阵列层
第二层的存储网络几乎都使用磁盘阵列作为基本的存储设备。在这个层次上,主要需要解决阵列散架、阵列卡损坏、磁盘掉线等故障。显然,要想成功恢复RAID数据,只对单个磁盘进行操作是没有太大意义的。根据不同的RAID类型,对可以保证数据完整性的最小数量的磁盘进行操作,并重建RAID,才能成功恢复RAID数据。
目前RAID主要通过两种方式实现:一种方式是硬RAID,由专门的控制器,也就是常说的RAID卡(有些RAID卡只有数据接口,没有RAID管理功能,效果与软RAID一样)来完成;另一种方式是软RAID,由软件方法来实现。
在过去,RAID一直是高端服务器才会使用的设备,通常与高档SCSI硬盘配合使用。SCSI RAID稳定性高、速度快,但SCSI硬盘和SCSI接口的RAID卡价格都很高。后来,随着技术的发展和产品成本的不断下降,IDE硬盘和SATA硬盘的性能也有了很大提升,加之RAID芯片的普及,使RAID技术也应用到了IDE硬盘和SATA硬盘上,有些主板还直接集成了RAID控制芯片,RAID也因此逐步在个人用户之中得到普及。
RAID的类型主要有RAID 0、RAID 1、RAID 2、RAID 3 ,RAID 4、RAID 5、RAID 6、RAID 7以及一些组合方式(如RAID 10等)。常用的RAID类型主要有RAID 0、RAID 1和RAID 5。
4.磁盘层
无论上层采用什么方式,归根到底,存储系统都离不开基础存储设备——磁盘,尤其是硬盘。因此,硬盘这一级别是整个存储体系的基础。
硬盘是集磁、电、机械装置于一体的精密的智能化设备,在整个数据恢复技术体系中有着重要的地位和作用。同理,存储安全在整个信息安全体系中也有着重要的地位和作用。
磁盘级恢复通常指磁盘数据不能正常访问时的操作和处理,以硬盘为例,通常包括3个层次。第一个层次是硬盘数据的逻辑问题。这种问题比较容易解决,一般对上归入RAID级,对下归入文件系统级。第二个层次是硬盘访问的问题,即硬盘是否能够正常读写。显然,在这种情况下必须首先解决硬盘的正常访问问题,才能进一步恢复数据。这种问题通常由两种情况导致:一种情况是硬盘内部管理系统出现问题,可以通过专业的修复工具进行修复;另一种情况是硬件出现问题,如电机损坏、磁头损坏等,需要在专门的环境下修理。第三个层次是数据被覆盖,必须从存储机理上加以解决。
正逐步走向普通用户的SSD(Solid State Disk或Solid State Drive,固态硬盘)是使用闪存颗粒作为存储部件的新一代存储产品。既然称为“固态硬盘”,可见其数据管理沿用了传统硬盘的技术和方式。
5.文件系统层
当文件系统出现问题而导致数据不可得时,可以通过技术手段重建文件系统。如果只是分区表损坏,那么只要重建分区表,系统就能完全恢复到正常状态,所有的文件都可以正常访问,系统可以直接启动,常见的误分区、误格式化、病毒破坏、误删除等都属于本层的操作。本层与操作系统是紧密联系在一起的,不同的操作系统,不同的文件系统,其恢复手段与恢复效果都不一样。
6.文件层
文件层包含了多种情况。很多时候,文件系统损坏得比较严重,恢复的效果不是很理想。特别是除文本文件外,基本上各种类型的文档都有自己特定的格式,如果有损坏,就不能正常打开,这就需要我们对这些文件格式有所了解。例如,一个受损的Word文档,用Word程序是无法正常打开并显示其内容的,但它可能只是文件头部分损坏,里面大量的文字信息并没有丢失。在这种情况下,就可以通过技术手段,将文字信息提取出来,或者修复文件头,让Word程序能够正常读取该文件。再如,一段视频资料,如果部分损坏,将不能直接播放,但经过处理就可以播放没有损坏的部分,完全有可能重新获得需要的视频资料。还有就是判断文档的出处、加密与解密、信息隐藏等,都是文件层的工作。目前,全世界大约有3万多种文件格式在计算机中使用,所以,文件层是差别最大、应用最复杂、需要解决问题最多的一层,如果将系统本身的一些文件格式也计算在内,这一层的应用就更为复杂了,如NTFS文件系统的日志文件、数据库系统的各种文件、加密文件等中,都隐藏着大量的秘密。
7.覆盖恢复
在以前写有数据的地方写入新的数据,原有的数据就被覆盖了(详见第1.3节)。
1.3 也谈覆盖恢复
如果深入磁盘内部,查看磁盘内部信息以及磁盘中的原始磁信息,就会发现,还有更多的信息是我们在操作系统下不可控或者说不可达的,如图1-6所示。

图1-6 硬盘内部
用户数据经过ECC编码和通道编码,再经过前置放大电路转换成相应的电信号,由控制磁头写入存储介质,形成相应的磁信号,如图1-7所示。
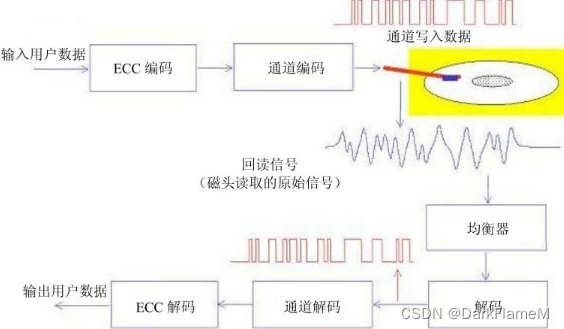
图1-7 数据编码
而写入磁介质中的数据位,也就是磁信息,是一些非常小的磁迹,如图1-8所示。
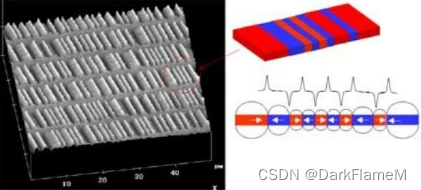
图1-8 磁盘上的磁迹
所谓的“覆盖”与“非覆盖”,则如图1-9所示。在一段存储空间上,原来存储了数据(图1-9上面的部分),当不再需要这些数据时,这些空间就可以分配给新的数据使用。这时,如果有新的数据写入这些空间(图1-9下面的部分,前后有两段空间写入了新数据。通过硬盘接口读取这两部分时,当然只能读取新写入的数据,与原来的数据没有任何关系),其中的原始数据就会被覆盖;而在未写入新数据的部分仍然可以读取原来的数据,因为其中的原始数据没有被覆盖。

图1-9 覆盖与未覆盖
显然,通过正常的硬盘接口只能读取最后写入的数据,而无法读取覆盖之前的数据,这才符合常理。如果既能读取新写入的数据,又能读取原有的数据,数据又怎么能被保存在硬盘中呢?由此可见,我们从硬盘接口读取的用户数据,与最底层的磁信息有着复杂的对应关系,并且各个硬盘厂商采用的编码方式也不统一。那种宣称自己有一套软件,可以解决覆盖恢复问题的“高人”,也未免太幼稚、太“可爱”了。详细的内部机制,留待后续。
1.4 硬盘硬件的组成
从功能结构上看,硬盘主要分为两大部分。一部分以机械部件为主,将磁头与盘片安装在一起,称为头盘组件(Head-and-Disk Assembly, HDA),也就是盘体,与电路板相对应。盘体里面是一个无尘空间,最大的基体是一个铝制的基座,基座上安装着主轴电机、盘片、磁头电机、前置放大器/转接器、磁头、定位夹具等部件,如图1-10所示。

图1-10 硬盘内部的主要部分
磁头与前置放大器/转接器直接固定在磁头臂上,构成磁头组件,如图1-11所示。

图1-11 磁头组件
两款实际硬盘的前置放大器/转接器分别如图1-12和图1-13所示。

图1-12 希捷酷鱼系列硬盘的针脚式前置放大器/转接器

图1-13 日立ATMR系列2.5英寸硬盘的前置放大器/转接器
硬盘电路板一般采用六层板。电路板上主要有以下4大类芯片。
[1] 系统控制芯片(包括读/写通道、磁盘控制和使用精简指令集的微处理器)。
[2] 包含磁盘固件的Flash ROM芯片。
[3] 主轴电机和音圈电机的控制驱动芯片。
[4] 高速缓存。
由于盘体要在无尘环境中才能打开,而超净空间的造价及维护成本较高,因此导致了硬盘的可修性很低。相对来说,电路板的维修受到的限制要小得多,配备热风焊台、电烙铁、万用表、示波器(可选)等,就可以解决一般的问题。一个实际的硬盘电路板如图1-14所示。

图1-14 IBM DTLA-307030硬盘的电路板
硬盘电路的原理如图1-15所示。其中的微处理器指的是硬盘本身的微处理器,与计算机的CPU没有关系。微处理器是电路板上的主控芯片,是整个硬盘的灵魂,就像CPU之于计算机。硬盘的微处理器其实也是CPU的一种,它是一种数字处理芯片,统管并控制硬盘的正常工作,包括加电自检、进入正常工作状态、与计算机进行通信、传输数据、控制完成数字数据与磁信号的转换并读写数据等。
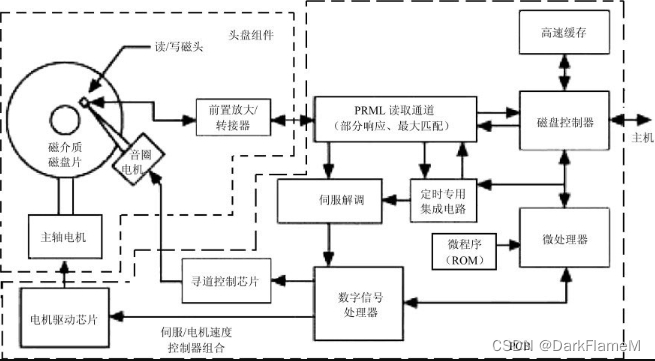
图1-15 硬盘电路原理
微处理器使用RISC(Reduced Instruction Set Computer,精简指令集计算机)体系结构。只要加电或复位,微处理器就开始执行ROM(Read-Only Memory,只读内存)中的程序进行自检,初始化内存工作区和磁盘控制器,并设置好所有与内部数据总线相连的可编程部件。完成这些工作后,如果没有侦测到错误警告,系统就会启动主轴电机,进行内部测试,检查RAM(Random Access Memory,随机存取存储器),然后通过端口向微处理器输入信号,分析脉冲频率,并等待主轴电机达到规定的旋转速率。一旦主轴电机达到规定的旋转速率,控制器就会控制定位电路和磁盘控制器,将磁头移到磁盘服务区,并将磁盘服务区上的固件信息读入内存进行处理。如果读取成功,微控制器将转换到就绪状态,等待主机指令。
磁盘读/写通道包括安装在HDA内部的前置放大器/转接器、读/写电路以及同步时钟等部分。
驱动器的前置放大器有数个通道,每个通道都与各自的磁头相连。这些通道的开、关由微处理器控制。前置放大器中还包括状态记录和错误传感器,可在短路或磁头出现错误时发出错误信号。
读/写通道在写状态下接收由磁盘控制器发送的数据和时钟信号,对数据进行编码,然后进行预补偿,将数据传送至前置放大器并写入硬盘中。在读状态下,信号从前置放大器/转接器传送至自动控制电路,在进行一系列处理并解码后,数据将被传送至外部接口。
磁盘控制器是硬盘中最复杂的部件,负责控制磁盘与主机的数据交换速率。磁盘控制器有4个端口,分别与主机、微处理器、缓存和磁盘的数据交换通道相连,由微处理器控制。
主轴电机控制器控制三相主轴电机。主轴电机由微处理器控制,控制模式共有3种,分别是启动模式、加速模式和稳定旋转模式。音圈电机控制器负责控制将磁头定位到相应的磁道。
但是,实际的硬盘电路中不会有这么多的独立芯片,尤其是现在,芯片的集成度越来越高,硬盘厂商在设计电路时都会尽量选取集成度较高的IC(Integrated Circuit,集成电路)芯片,既减小了硬盘体积,又提高了可靠性。伺服/电机速度控制器组合就是一种集成芯片,昆腾(Quantum)CX/LCT系列硬盘采用的AN8428/TDA5247、旧款西部数据(Western Digital,简称WD)硬盘采用的L6256、希捷U8/U10硬盘采用的23400278-002等都是这样的芯片。在很多设计中,除了上面提及的IC内部的电源部分,还会根据需要设计一些独立电源IC,如磁头电路用8V稳压IC,微处理器用3.3V/2.5V稳压IC等。硬盘接口控制器、微处理器、数字信号处理器也常常被集成在一块主芯片中,如迈拓硬盘就采用了TI(Texas Instruments,美国德州仪器公司)的数字信号处理器,并将这3个部分集成在一起(只有旧型号的西部数据硬盘的电路和图1-15较为接近),其微处理器采用80C196NU芯片,数字信号处理器及接口控制器采用WD69C24芯片。
有些型号的硬盘,将ROM集成在微处理器或数字信号处理器中。在这种方式下,ROM中只有一些基本的固件程序,而主要程序则存储在磁盘服务区中。如果采用独立ROM芯片,则数字信号处理器大多采用TI的M29F102BB、WINBOND的W49L102、ATMEL的AT49F1024等电可擦写芯片。这样设计的好处是硬盘厂商在发现问题时可以让用户使用像刷写主板BIOS一样的方法来更新硬盘的ROM。
IBM AVER系列硬盘电路板的正、反面如图1-16和图1-17所示。

图1-16 IBM AVER系列硬盘电路板正面

图1-17 IBM AVER系列硬盘电路板背面
1.5 基本故障的可维修性
本节将介绍硬盘各部位的常见故障及判断检测方法,并分析这些故障的可维修性。
1.5.1 各部位的常见故障
硬盘各部位的常见故障如下。
1.供电
硬盘供电取自主机,4个接线柱的电压分别是:红色为+5V;黑色为地线(两条);黄色为+12V。通过线性电源变换电路,可以提供硬盘正常工作所需的各种电压。该供电电路如果出现问题,会直接导致硬盘不能工作,故障现象往往表现为无法通电、硬盘检测不到、盘片不转、磁头不寻道等。供电电路中经常出现问题的部位有插座的接线柱、滤波电容、二极管、三极管、场效应管、电感、保险电阻等。
2.接口
接口是硬盘与计算机之间传输数据的通路,接口电路出现故障可能导致硬盘检测不到、乱码、参数误认等现象。接口电路经常出现的故障有接口芯片或与之匹配的晶振损坏、接口插针折断或虚焊、脏污、接口排阻损坏等。部分硬盘的接口塑料损坏会导致厂商不予保修。
3.缓存
缓存用于加快硬盘数据的传输速度。如果缓存出现问题,可能导致硬盘无法被识别,或者虽能认盘但无法进入操作系统等故障的发生。
4.Flash ROM
Flash ROM用于保存硬盘的工作程序。硬盘的所有工作流程都与Flash ROM程序相关,通、断电瞬间可能导致Flash ROM芯片损坏、程序丢失或紊乱。Flash ROM不正常会导致硬盘不能被识别。
5.磁头芯片
磁头芯片贴装在磁头组件上,用于放大磁头信号、进行磁头逻辑分配、处理音圈电机反馈信号等。该芯片出现问题可能导致磁头不能正确寻道、数据不能被写入盘片、硬盘不能被识别、硬盘异响等故障的发生。
6.前置放大器
前置放大器用于加工和整理磁头芯片传来的数据信号。如果该芯片出现问题,可能导致不能正确识别硬盘。
7.数字信号处理器
数字信号处理器用于处理前置放大器传送过来的数据信号,并对该信号进行解码;或者接收计算机传来的数据信号,并对该信号进行编码。
8.电机驱动芯片
电机驱动芯片用于驱动硬盘主轴电机和音圈电机。目前,由于硬盘转速太高,常常导致电机驱动芯片发热量太大,从而造成损坏。据不完全统计,大约有70%的硬盘电路故障是由该芯片的损坏引起的。
9.盘片
盘片用于存储数据,发生轻微划伤时有可能通过软件按一定的算法解码纠错,但发生严重划伤时数据不可恢复。
10.主轴电机
主轴电机用于带动盘片高速旋转。目前的硬盘大多使用液态轴承马达,精度极高,剧烈碰撞后可能会使间隙变大,从而导致数据读取困难、硬盘出现异响或根本检测不到硬盘。出现该故障后,需用专用设备才能读取数据。另外,电机转速必须达到额定转速,因为达到额定转速后,硬盘内部的磁头闭锁机构才会释放磁头。例如,昆腾硬盘主轴驱动损坏会导致盘片转速不稳定,从而导致磁头反复定位,也会导致磁头敲盘而发出响声,当然也就不能完成硬盘初始化且无法识别硬盘了。
11.磁头
磁头用于读取或写入数据。硬盘受到剧烈碰撞时易导致磁头损坏,从而使硬盘无法被识别。碰伤盘片同样会导致数据不可读取。
12.音圈电机
音圈电机即闭环控制电机,用于把磁头准确定位在磁道上。该电机较少损坏。
13.磁头停放卡
以前只有笔记本硬盘和3.5英寸的IBM、日立硬盘有磁头停放卡,用于使磁头停留在启停区,所以这种硬盘容易出现磁头不能从盘片回到磁头停放卡上的故障,导致主轴电机不转(通常叫卡头)。
1.5.2 基本判断方法
系统在启动时,会进行一些基本测试,并根据测试结果给出错误提示,这些错误提示可以帮助我们了解故障的所在。常见故障提示信息的含义如下。
Data error(数据错误):从软盘或硬盘上读取的数据存在不可修复的错误,磁盘上有坏扇区和坏的文件分配表。
Hard disk configuration error(硬盘配置错误):硬盘配置不正确,跳线不对,硬盘参数设置不正确等。
Hard disk failure(硬盘失效):硬盘配置不正确,跳线不对,硬盘物理故障等。
No boot device available(无引导设备):系统找不到作为引导设备的软盘或硬盘。
Non system disk or disk error(非系统盘或者磁盘错误):作为引导盘的磁盘不是系统盘,不含有系统引导文件和核心文件,或者磁盘本身故障。
Sector not found(扇区未找到):不能定位给定扇区。
Seek error(寻道错误):不能定位给定扇区、磁道或磁头。
Reset failed(硬盘复位失败):硬盘或硬盘接口电路故障。
Fatal error bad hard disk(硬盘致命错误):硬盘或硬盘接口故障。
No hard disk installed(没有安装硬盘):没有安装硬盘,但是CMOS参数中设置了硬盘;硬盘没有接好或存在故障。
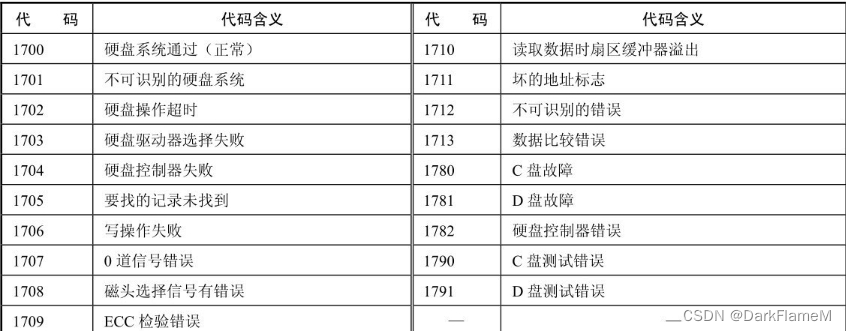
有时,系统会返回相应的硬盘故障代码。常见的硬盘故障代码如表1-1所示。
表1-1 硬盘故障代码
1.5.3 电路板的检测
下面介绍一些常见的硬盘电路板故障和简单的维修方法。
1.故障检测
电路板的检测,通常先采用直接目视法和闻嗅法,查看有没有明显的烧焦痕迹和断路(可使用台式放大镜或普通放大镜进行查看)。如果有烧焦部分,有时即使看不出来,也可能直接闻到烧焦的味道,由此即可判断电路板的状况。在这些方法不能奏效的情况下,还可以使用仪器设备进行测试。
加电自测时如果出现错误提示,一般就可以说明硬盘确实有故障,但也可能是硬盘数据线质量不好或者接触不良而导致的问题。此时,可先检查信号电缆线,查看插头与主板插槽是否插好,有无插错或接触不良,还可尝试更换一些电缆插头进行测试。实际工作中常会遇到这种情况,有些仅仅是电源线接头接触不好造成的硬盘工作不稳定。如果采用以上方法还不能解决故障,应进一步检测+5V、+12V电源是否正常,以此来判断是否存在外电路故障。
另外,还可以在加电情况下,用万用表测量部件或元件的各管脚对地电压值,并将其与逻辑图给出的或其他参考点的电压值进行比较。若电压值与正常参考值相差较大,可判断是该部件或元件有故障;若电压正常,则说明该部分完好,可转入对其他部件或元件的测试。硬盘步进电机额定电压为+12V。由于硬盘启动时电流较大,当电源稳压不良时(电压从+12V下降到+10.5V),会导致转速不稳或启动困难。硬盘驱动器插头、插座都有自己的标准电压,高电平为+2.5~+3.0V。若高电平输出电压小于+2.5V,低电平输出电压大于+0.6V,即说明存在故障。逻辑电平的测量可用示波器或逻辑笔进行。
除了测电压,还可以用万用表电阻档测量部件或元件的内阻,根据阻值的大小或通断情况来分析电路中的故障。一般元器件或部件的输入引脚和输出引脚对地或对电源都有一定的内阻,用普通万用表测量,通常表现为正向电阻小、反向电阻大。一般正向阻值在几十欧姆(记作Ω)至100欧姆左右,而反向电阻多为数百欧姆或更大,但正向电阻决不会等于0或接近0,反向电阻也不会为无穷大,否则就应怀疑管脚是否有短路或开路的情况。当断定硬盘子系统的故障点是在某一板卡或几块芯片上时,就可用电阻法进行查找。关机停电后,可测量元器件或板卡的通断、开路/短路、阻值等,并以此来判断故障点。硬盘步进电机绕组的直流电阻,标称值一般在24欧姆左右,如果测量值为10欧姆左右表示局部短路,如果测量值为0或小于10欧姆则表示绕组短路或烧毁。硬盘驱动器的数据线常用通断法进行测量,而其电源线则既可拔下单独测量,也可在加电状态下测量其对地阻值,如果阻止为无穷大表示断路,如果阻值小于10欧姆应怀疑局部短路,需进一步检查。
目前硬盘电路板上的元器件基本为贴片式元器件,西部数据、迈拓(Maxtor)、IBM、日立等硬盘的PCB控制电路板上的电阻、电容、二极管、三极管等都有统一的标识,如电容标注为“C”、电阻标注为“R”、二极管标注为“[插图] ”、三极管标注为“Q”等。电阻上都标有数字和字母,如接口处的排阻上标注的“510”、“220”等,分别表示其阻值为51×100、22×100,即最后一位表示10的m次方,计算方法为用去掉最后一位数后的数字乘以10的m次方,再如“1002”表示其阻值为100×102, “1102”表示其阻值为110×102。
用万用表电阻档进行测量时要取下电阻的一个脚,因为如果被测电阻在电路板上和其他电阻并联,测得的阻值就会变小,从而使测量结果不够准确。
电容通常不会损坏,测量起来也不方便,而且一般的电容损坏也不会造成太大的影响。
二极管损坏的情况比较多,尤其是希捷和迈拓硬盘,其电源接口处的二极管容易损坏,表现大多为短路,阻值为0。二极管正向导通是有阻值的,锗管大约为1KΩ,硅管约为5~7KΩ,其反向阻值一般大于100KΩ。
维修硬盘的控制电路板时,二极管短路的情况较多,即阻值为0,表现为接通电源后主机电源会进行短路保护。
硬盘电路板上的三极管很少,一般也不易损坏,测量方法同二极管。三极管就是两个二极管而已。
2.维修方法
电路板的维修方法大体可以分以下几步。
第1步 用直接目视法进行观察。
第2步 测量电源接口处的+5V、+12V脚对地阻值,如果短路,一般为+12V脚处的二极管或电容对地短路。此时应找到损坏的二极管或电容,更换损坏的元器件,直到+5V、+12V脚对地不短路为止。
第3步 加电听硬盘主轴电机是否正常转动,磁头是否有初始化的声音(要接上数据线,尤其是有些品牌的串口硬盘,不接数据线磁头不会转动)。
第4步 如果加电后硬盘主轴电机不转也无电流声,要用万用表测量电源接口处标有“F”或者“L”的电阻(保险电阻),如果断路(电阻值很大),应进行更换。
当使用以上方法仍找不出故障点时,最直接的方法就是更换电路板(根据兼容规则用同型号硬盘的控制电路板进行更换),更多时候还需要同时更换ROM芯片(只有很少一部分硬盘的控制电路板可以通用)。
根据经验,控制电路板故障点主要出现在以下方面。
电源接口处的保险电阻烧坏(断路),尤其是2.5英寸和1.8英寸的笔记本硬盘(移动硬盘),表现为加电时硬盘主轴电机不转、无电流声。
电源接口处的稳压二极管烧坏(短路),尤其是3.5英寸的希捷、迈拓硬盘,希捷硬盘居多,表现为加电时主机电源短路保护。
电源接口处的滤波器和稳压器烧坏(短路),尤其是3.5英寸的西部数据、迈拓硬盘,表现为加电时主机电源短路保护。
数据接口处的排阻损坏或者开路,主要出现在IDE硬盘上,表现为硬盘型号被识别成乱码。
磁头读写控制芯片损坏(或者其外围电阻损坏),以2.5英寸硬盘居多,表现为主轴电机正常转动而磁头不动(接上数据线时)。
主控芯片损坏、管脚开路。如果主控芯片损坏,一般在加电时芯片会发烫,硬盘主轴电机不转,测量芯片周围的电容时,电容管脚对地短路。当芯片管脚开路时,硬盘加电后会正常初始化,但硬盘不能被识别或被识别为乱码。
电机驱动控制芯片损坏(烧坏或者不稳定)。一般加电时芯片会发烫或者已经烧焦。芯片烧坏后,硬盘加电时主轴电机不转;不稳定时,硬盘加电主轴电机能够起转但转速不够或发出异响(像磁头损坏后的声音,但是仔细听时其异响没有规律。磁头损坏时磁头会有规律地敲盘),或者硬盘冷却时能正常使用,发热后出现异响。
Flash ROM损坏或者数据丢失,表现为硬盘加电时主轴电机不转。数据丢失后硬盘可以初始化但初始化不完全,硬盘无异响但不能被识别,也不会出现乱码。由于硬盘的Flash ROM数据一般不通用(早期的硬盘大部分通用),所以修理起来难度很大,对硬盘固件的知识研究比较深的工程师才有可能修复此类故障。
前置放大器损坏,表现为磁盘加电时发出异响或者主轴电机正常转动而磁头不转动(接上数据线时)。由于前置放大器位于盘腔内部,更换时需要开盘,而且现在的硬盘前置放大器采用BGA封装,更换难度大,所以一般采用更换磁头的方法来解决。早期更换磁头的数据恢复成功率可达到100%,但随着数据密度的增加,成功率有一定幅度的下降。
维修硬盘时需要特别注意以下几点:
拿到故障硬盘时,在加电检测之前要用“直接目视法”查看控制电路板有无烧伤。
检测电源接口处的+5V、+12V脚对地阻值。如果阻值为0,应找出损坏元件,直到阻值正常为止。
更换控制电路板时,一般要更换Flash ROM。由于Flash ROM很“脆弱”,温度高时会被烧坏,所以更换时要注意温度不能太高,而且只能对其管脚均匀加热,不能对芯片中心加热。当然,更换所有的集成IC时最好都这样做,只是由于Flash ROM的唯一性,所以需要特别注意,因为损坏Flash ROM可能导致数据彻底丢失。
早期生产的SCSI硬盘,如果更换控制电路板后可正常识别,但无法正常读写数据,需要更换Flash ROM。
对1.8英寸的东芝硬盘,特别是孔式接口硬盘,在维修时要注意转接头的方向。一旦错将+5V电源直接接到主控芯片上,主控芯片马上会被烧坏。由于Flash ROM也集成在主控芯片里,所以烧坏后硬盘几乎不能修复,数据也将无法提取。
2.5英寸以下的硬盘只需要+5V供电。3.5英寸及以上硬盘的+12V供电主要给主轴电机供电,+5V供电主要给其他控制电路供电。
更换控制电路板时,最好能使用同型号硬盘的电路板。如果找不到同型号硬盘的电路板,可以使用板号一样的硬盘控制电路板,例如日立的HTS541680J9SA00硬盘可以HTS541660J9SA00硬盘的控制电路板进行更换(其板号为220-0A28613-01),但主控芯片型号必须一样(其主控芯片型号为0A28644),而且需要同时更换Flash ROM。
更换缓存时也要使用同品牌、同型号硬盘的缓存,否则硬盘能被正常识别,但会出现全盘坏扇区。当然,缓存损坏的情况极少。
硬盘的电路非常复杂,集成度越来越高,每一代的硬盘的常见故障点都不一样,需要在维修时归纳总结,不过其中也不是没有规律,只要见得多了,修得多了,就能很快找出故障点。
在修理硬盘时,有时也会用到电流测试法。这是因为局部短路时,短路元件会升温、发热并可能引起保险丝熔断。这时,可将万用表串入故障线路,检查电流是否超过正常值。硬盘电源+12V的工作电流一般为1.1A左右。当硬盘负载电流过大时,会使硬盘启动时好时坏。如果电机短路或负载过大,轻则导致保险丝熔断,重则导致电源控制芯片烧坏、开关调整管损坏。
如果条件许可,可将测试信号送至故障部位进行测试,例如用逻辑笔或示波器按逻辑图进行检测。如果被检测部分出现波形延迟过大、相位不对、波形畸变等现象,则说明故障点就在当前部分,应仔细进行进一步的检查。
维修时,最简单有效的方法就是直接采用替换法确定故障部件。硬盘电路板具有一定的通用性,可根据其通用性标签使用无故障的电路板进行替换,以验证电路板是否损坏。在使用这种方法时,要把需要恢复数据的硬盘电路板替换到不需要恢复数据的盘体上进行检测,尽量避免对需要恢复数据的硬盘造成不必要的意外损坏。
1.5.4 IDE/SATA接口
IDE接口标准中各针脚信号的定义如表1-2所示。“方向”是相对硬盘而言的,“I”表示进入硬盘,“O”表示从硬盘出来,“I/O”表示双向,名称后带有“-”表示低电平有效。
表1-2 IDE接口40针线针脚定义

表注:1— CSEL:一条排线上有两个存储设备时,可通过该信号确定某存储设备为设备0(主设备)或设备1(从设备)。
2— PDIAG-/CBLID-:一条排线上有两个存储设备时,设备1通知设备0,设备1已检测通过;也用于确定是否有80芯的排线连接到接口上。
主机对IDE硬盘的控制是通过硬盘控制器上的两组寄存器实现的,其中一组为命令寄存器组,另一组为控制/诊断寄存器,如表1-3所示。
表1-3 寄存器组
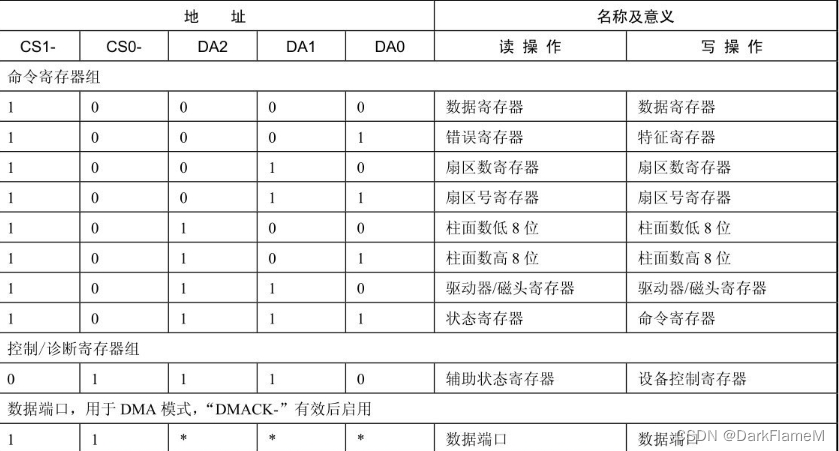
特征寄存器中的内容作为命令的一个参数,其作用随命令而变化。扇区数寄存器用于指示该次命令所需传输数据的扇区数。扇区号寄存器、柱面数寄存器(低、高)、驱动器/磁头寄存器合称介质地址寄存器,用于指示该次命令所需传输数据首扇区的地址,寻址方式可以用柱面/磁头/扇区(Cylinder/Head/Sector, CHS)方式或逻辑块地址(Logical Block Addressing, LBA)方式在驱动器/磁头寄存器中指定。
命令寄存器用于存储执行的命令代码。当向命令寄存器写入命令时,相关的参数必须先行写入。写入命令后,硬盘立即开始执行命令。状态寄存器保存硬盘执行命令后的结果供主机读取,其主要位有BSY(驱动器忙)、DRDY(驱动器准备好)、DF(驱动器故障)、DRQ(数据请求)、ERR(命令执行出错)。辅助状态寄存器与状态寄存器的内容完全相同,但读取该寄存器时不会清除中断请求。错误寄存器中包含了命令执行出错时硬盘的诊断信息。
数据寄存器是在PIO(Programming Input/Output)传输模式下主机和硬盘控制器的缓冲区之间进行数据交换的寄存器,是数据端口在DMA(Direct Memory Access,直接存储器访问)传输模式下专用的数据传输通道。
后来出现的80针线硬盘对40针线硬盘是兼容的,增加的40条线是在原有40芯排线的每条线芯之间都增加了1条线,并将这40条新线与原有40芯排线之中的7条地线相连,把构成串扰(Crosstalk)现象的电磁波滤走(在高速电子信号传输系统中,当大量带着高频信号的电线互相靠近的时候,信号线上发出的电磁波便会互相干扰,这就是Crosstalk现象),以提高数据传输的稳定性。
笔记本的2.5英寸硬盘是44针的,1~40针与3.5英寸硬盘针脚的定义相同,后4针是电源针脚,按照与前面40针相同的顺序数下来,依次为+5V、+5V、Ground、空。
SATA的全称是“Serial Advanced Technology Attachment”(串行高级技术连接),是由Intel、IBM、Dell、APT、Maxtor和Seagate公司共同提出的硬盘接口规范。在IDF Fall 2001大会上,Seagate发布了Serial ATA 1.0标准,正式宣告了SATA规范的确立。SATA规范将硬盘外部传输速率的理论值提高到150MB/s,比PATA标准的ATA/100高出50%,比ATA/133也高出约13%,而SATA接口2X和4X标准的传输速率更是达到300MB/s和600MB/s。
SATA硬盘数据接口为7针,如图1-18所示,电源接口为15针。笔记本硬盘接口与台式机硬盘接口一样,只是没有提供+12V的额定电压,如图1-19所示。
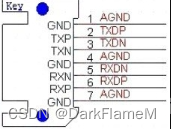
图1-18 SATA串行数据接口定义
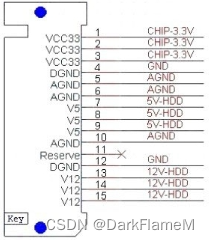
图1-19 SATA电源接口定义
1.5.5 基本故障的可维修性
下面简单分析硬盘基本故障的可维修性。
1.引导出错,不能正常启动
这种情况下,有时候可能只是操作系统或文件系统出错,清除MBR、重新分区就可以修好,如若不行,归入以下第3点。
2.出现坏道
硬盘出现坏道时,可正常分区,可格式化,但SCANDISK扫描会发现“B”标记,也就是通常所说的有了“坏道”,并且常常出现系统变慢、长时间无响应等现象。无论是物理坏道还是逻辑坏道,“B”标记数量少的话,基本上都可以修好,使用MHDD、THDD等工具软件就可以解决。
3.不能正常分区或分区后无法格式化
这种情况需要使用专业维修软件修理。视不同品牌、不同型号的硬盘,修复成功率有所不同。
4.通电后主轴电机不转
这种情况一般是电路板发生了故障,换掉电路板IC或整个电路板(需要根据电路板兼容性标签选择可替换的电路板)均可修复,起转后视不同情况进行处理。当然,极个别情况下也有可能是主轴电机出现问题,只是这种问题出现的概率很低,有时可能只是主轴电机被卡住。
5.自检声正常,BIOS不认盘
这种情况可能由多种原因造成。如果是电路板的问题,则修复电路板;如果是硬盘进入内部保护模式,则需用专业软件切换。富士通硬盘出现这种问题的情况较多,修复成功率也较高。如果是其他问题,需进一步进行处理。
6.通电后磁头敲击不止或敲击延续一段时间后停止
这种情况多由磁头损坏引起,可以通过更换磁头来恢复数据(根据磁头兼容性规则),但各个品牌硬盘恢复的成功率差别很大,需要谨慎选择。如果不需要挽救数据,就没有必要更换磁头,因为市场上没有单独的磁头出售。
7.遗忘密码
大部分硬盘可以设置密码保护,如不慎忘记密码,将极难解开。不过办法还是有的——大部分型号的硬盘都可以用专业软件或设备去除密码保护(如PC3000、硬盘维修指令等)。
8.受损严重,坏扇区过多
如果硬盘受到严重破坏,坏扇区太多(有些型号的硬盘坏扇区不允许超过3 000个,有些不允许超过8 000个,有些却允许超过10 000个),解决方法是切除有问题的磁头,用降低容量并更改型号的方式把原硬盘当做低一级的硬盘使用,也就是通过专业软件将集中出现问题的盘片存储区域除去不用。在后面的章节中,将针对各品牌的硬盘详细介绍其操作过程。
1.6 电路板的修理
当硬盘出现硬件类型的故障时,应本着先易后难的原则,首先考虑电路板的问题。
1.6.1 典型硬盘芯片的电阻值
硬盘电路板损坏,部分情况下可通过维修来解决,部分情况下可通过更换能够相互替换的电路板来解决。
在第1.5节中已经介绍过,硬盘电机驱动芯片是硬盘电路部分最易损坏的芯片。早期的硬盘,如昆腾硬盘,有高达70%的硬盘电路故障都是由该芯片的损坏引起的。现在生产的硬盘电机驱动芯片由于工艺的改进以及外围保护电路的增加,一般已经很少损坏。
电机驱动芯片是否损坏可以通过芯片周围引脚的对地阻值来大致判断。表1-4列出了常见硬盘电机驱动芯片各引脚的对地反向阻值,可用于确认电机驱动芯片是否损坏。表1-4中的数据均采用9205型数字万用表红表笔接地、黑表笔指向被测引脚测得。对只有2面引脚的芯片,从第一个引脚开始,按逆时针方向,用2列数字来表示引脚,其中第一列表示的是第一面的阻值,第二列表示的是第二面的阻值。对4面都有引脚的芯片,从第一个引脚开始,按逆时针方向,用4列数字来表示引脚,其中第一列表示的是第一面的阻值,第二列表示的是第二面的阻值,以此类推。
表1-4 Conner CT210硬盘电机驱动芯片各引脚对地反向阻值
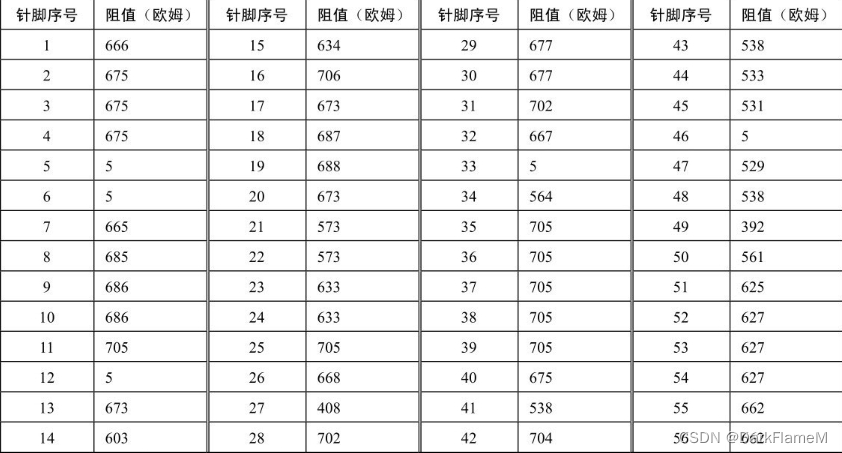
表1-5 IBM系列硬盘电机驱动芯片各引脚对地反向阻值
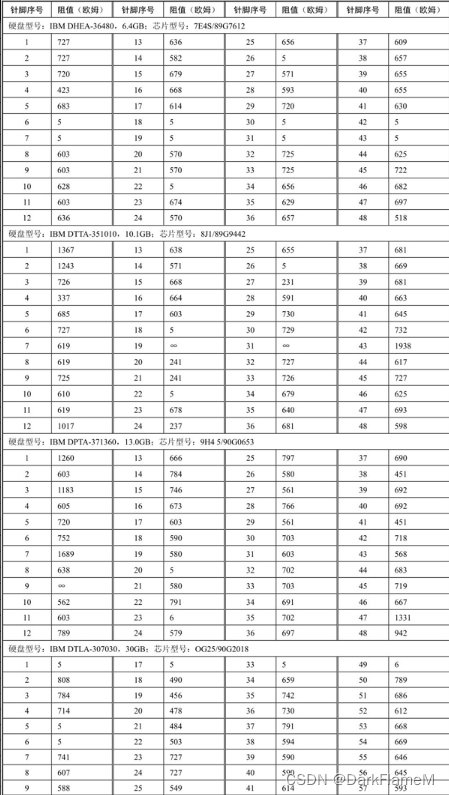
续表
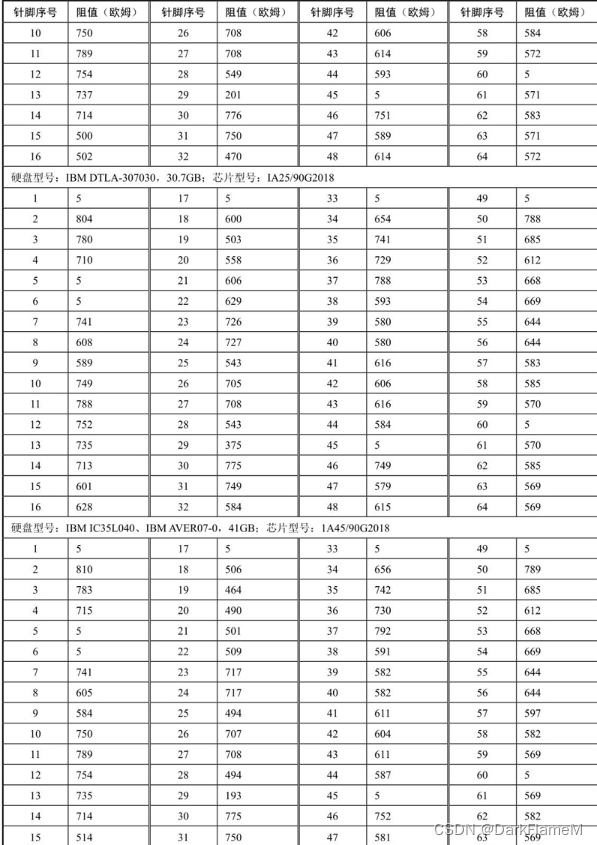
续表
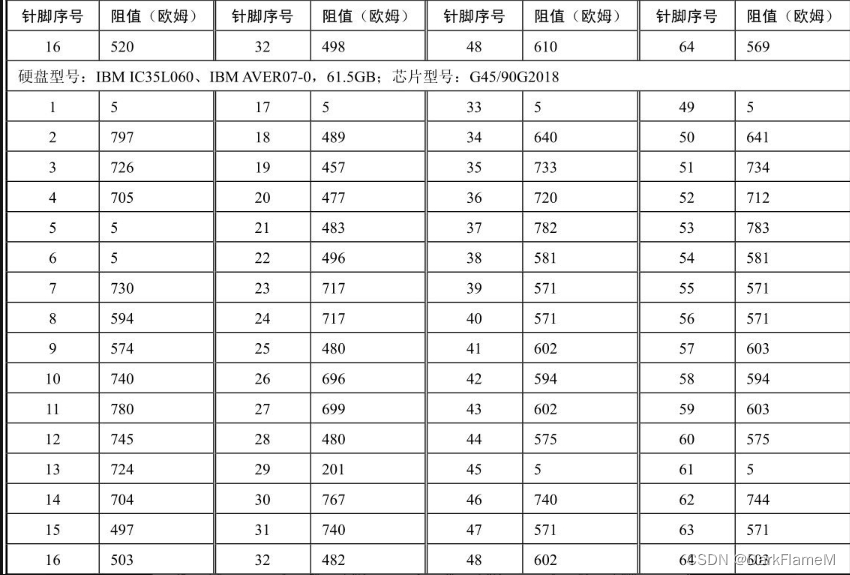
表1-6 Maxtor系列硬盘电机驱动芯片各引脚对地反向阻值
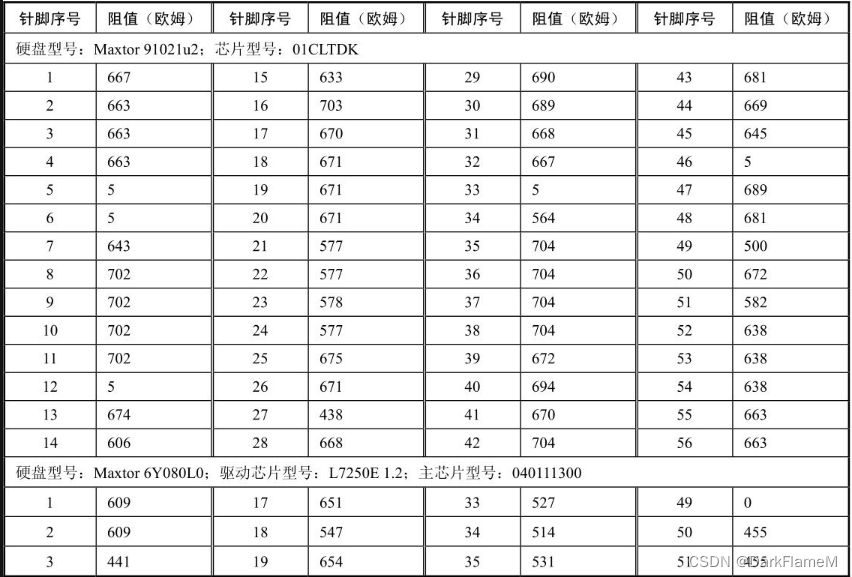
续表
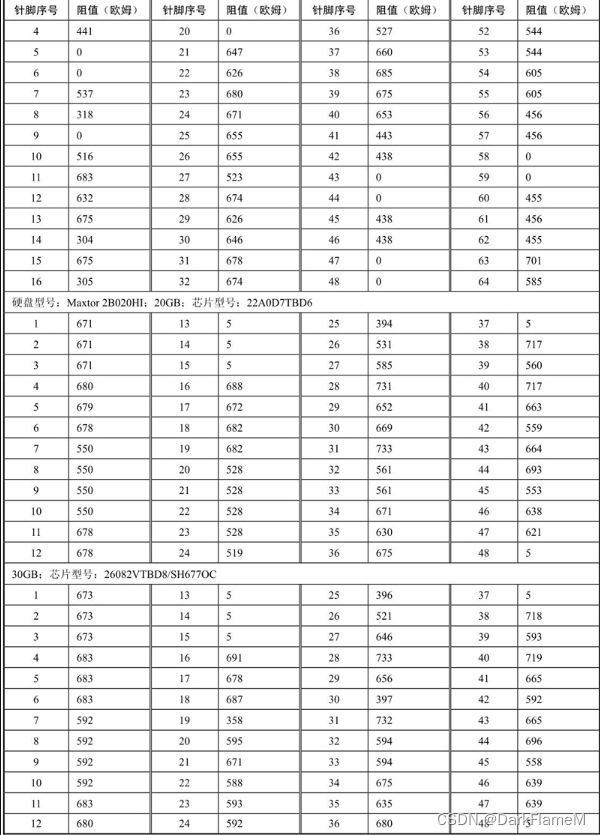
表1-7 Seagate系列硬盘电机驱动芯片各引脚对地反向阻值
续表
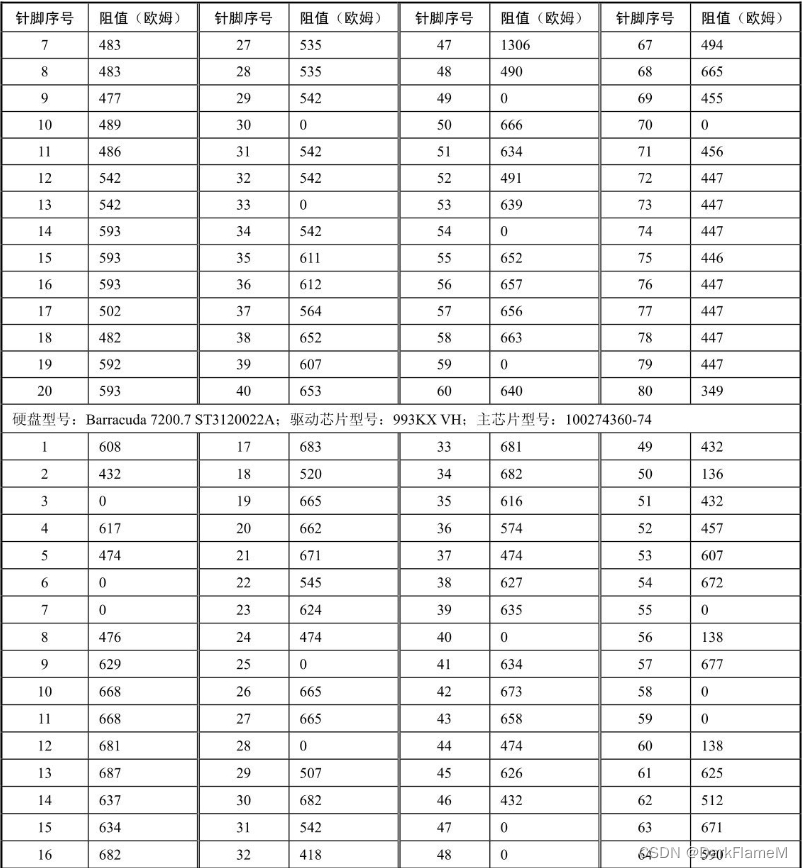
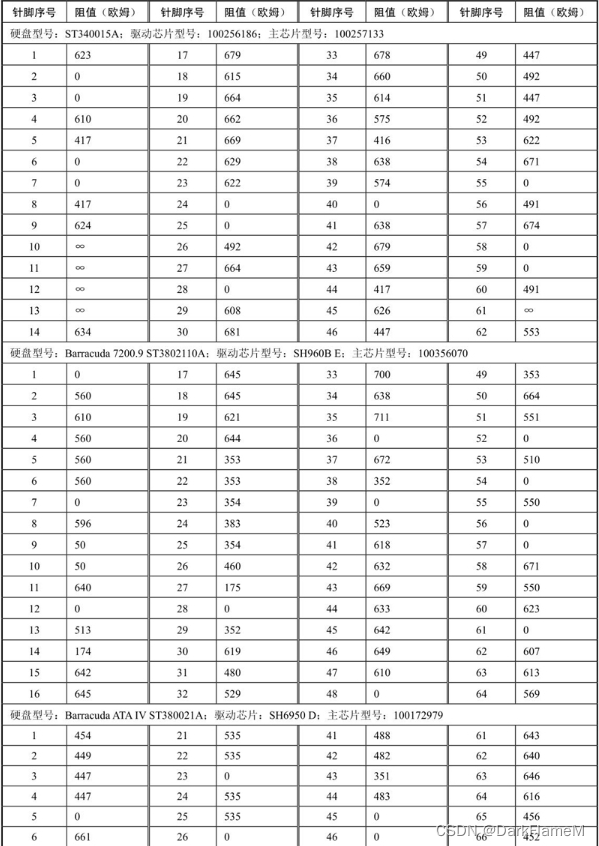
表1-8 Quantum系列硬盘电机驱动芯片各引脚对地反向阻值

续表
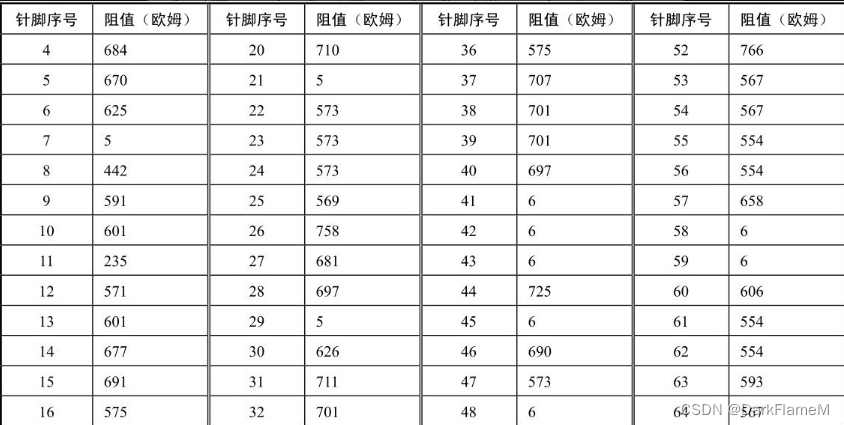
表1-9 Western Digital系列硬盘电机驱动芯片各引脚对地反向阻值
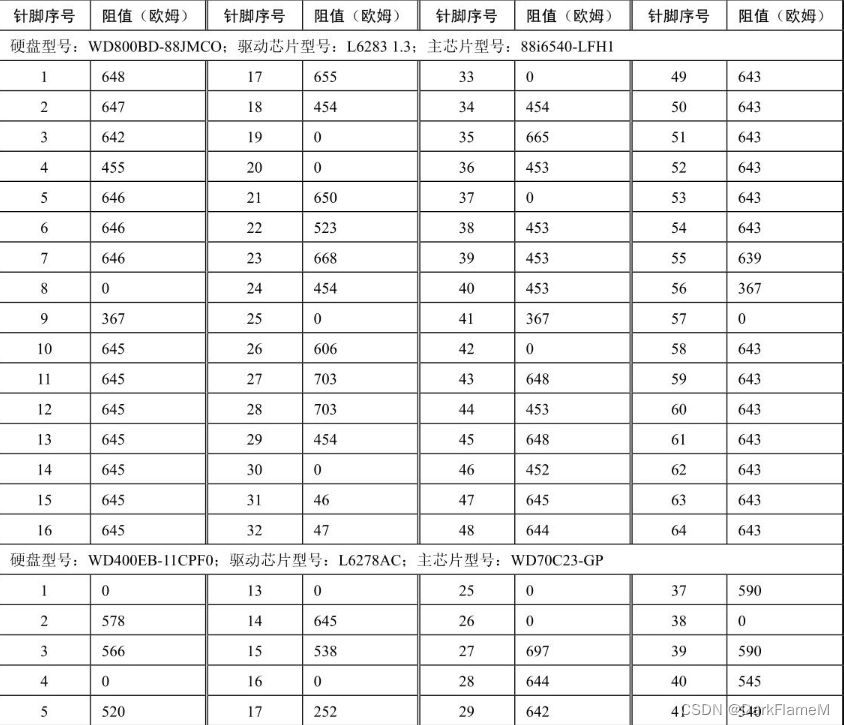
续表
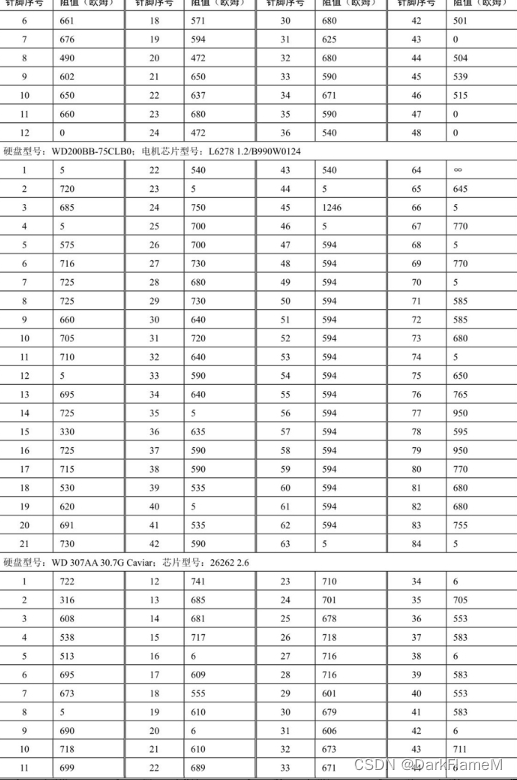
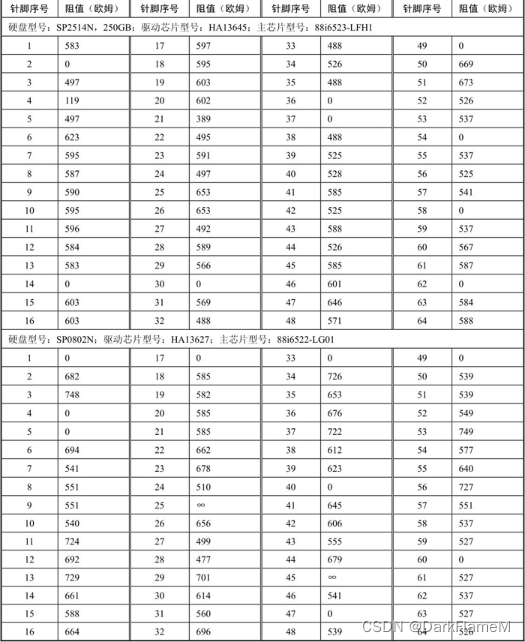
表1-10 Samsung系列硬盘电机驱动芯片各引脚对地反向阻值
电路板的修理,都是基于基本的电路维修原理,没有什么特别的知识,因此这里只是简单介绍一些。
1.6.2 电路板的兼容性
各个厂商生产的硬盘,既有属系,又有型号,这些硬盘的电路板,有些可以通用,有些不能通用,因此,了解其兼容性是更换电路板的基础。各品牌硬盘电路板的兼容性问题,将在各系列硬盘中进行介绍。
1.7 硬盘缺陷
在老式硬盘中,采用的都是比较古老的CHS结构体系。这是因为当时硬盘的容量非常小,自然就直接采用了与软盘类似的结构。这种结构的硬盘,盘片的每一条磁道都具有相同的扇区数,由此产生了所谓“3D参数”(Disk Geometry),即磁头数(Heads)、柱面数(Cylinders)、扇区数(Sectors)及相应的3D寻址方式。其中,磁头数表示硬盘总共有多少个磁头,也就是使用了多少个盘面,最大值为255(用8个二进制位存储);柱面数表示硬盘每一面盘片上有多少条磁道,最大值为1 023(用10个二进制位存储);扇区数表示每一条磁道上有多少个扇区,最大值为63(用6个二进制位存储);扇区容量一般是512字节。
所以,磁盘最大容量为:
255×1023×63×512/1048576=8024MB(1MB=1048576Byte)
或按硬盘厂商常用的单位计算,最大容量为:
255×1023×63×512/1000000=8414MB(1MB=1000000Byte)
由于在老式硬盘的CHS结构体系中,每个磁道的扇区数相等,外道的记录密度远低于内道,因此会浪费很多磁盘空间。为了进一步提高硬盘容量,现在硬盘厂商都改用(近似)等密度结构的方式生产硬盘。也就是说,每个扇区的磁道长度近似相等,外道的扇区比内道多。这两种方式的对比如图1-20所示。

图1-20 扇区划分的两种方式
采用这种结构后,硬盘不再具有实际的3D参数,寻址方式也改为线性寻址,即以扇区为单位寻址。为与使用3D寻址的软件(如使用BIOS Int 13H接口的软件)兼容,厂商通常会在硬盘控制器内部安装一个地址翻译器,负责将新的线性参数翻译成老式的3D参数。这也是现在硬盘的3D参数可以有多种选择的原因。
在逻辑0扇区之前还有物理0扇区。从物理0扇区到逻辑0扇区是硬盘的系统服务区(Service Area, SA),可用来存储硬盘的各种信息、参数及一些控制程序,有些硬盘的Firmware(固件)也存放在系统服务区。这样虽然可以进一步简化生产流程,加快生产速度,降低生产成本,但是从另一方面看,却又大大增加了硬盘出现致命性损坏的几率,并且缩短了硬盘的使用寿命。例如,十几年前生产的200MB容量的硬盘和8年前生产的1.xGB容量的硬盘到现在还能非常好地工作,别说是坏道,运行时几乎连噪音都没有,但是后来出现的4.3GB、6.4GB、10GB、20GB容量的硬盘,使用年限就短一些,现在的高密度硬盘,其寿命就更难说了。
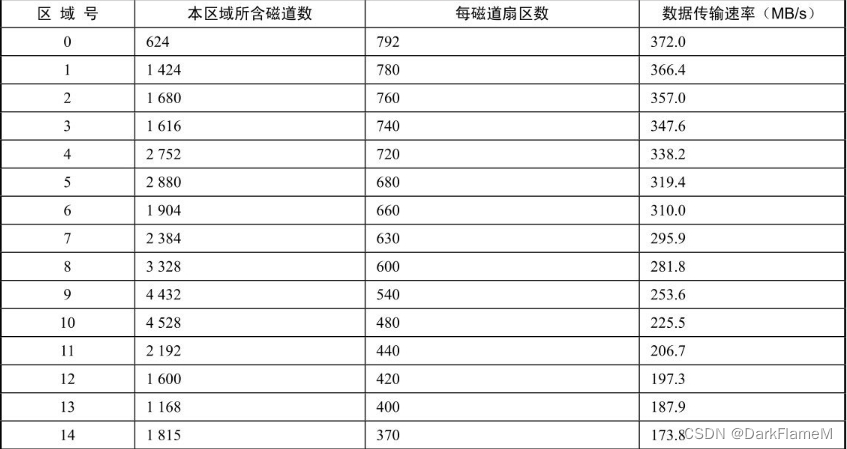
新式硬盘也不是简单地采用等密度结构生产的硬盘,而是对硬盘盘面进行区域划分,且每个区域的参数都不一样。这些参数可通过专用工具(如PC3000)查看。例如,IBM的桌面之星40GV和75GXP硬盘将盘面划分为15个区域,各个区域的参数如表1-11所示。
表1-11 IBM桌面之星40GV和75GXP盘面划分
这么复杂的系统,在使用一段时间后,难免会出现各种各样的故障。一般来说,硬盘的损坏按大类可以分为硬损坏和软损坏。硬损坏包括磁头组件损坏、控制电路损坏、综合性损坏和扇区物理性损坏4种,软损坏包括磁道伺服信息出错、系统服务区出错和扇区逻辑错误等。
磁道伺服信息出错,是指因为某个物理磁道的伺服信息受损或失效,导致部分物理磁道无法被访问。伺服信息可以散布在磁道中,也可以集中在柱面内,如图1-21所示。

图1-21 伺服信息的分布方式
系统服务区出错,是指硬盘的系统服务区在通电自检时读不出某些模块,或者模块信息校验不正常,导致硬盘无法进入就绪状态。
扇区逻辑错误会导致扇区失效,具体如下。
UNC校验错误:ECC错误和CRC错误。
IDNF错误:扇区标志错误。
AMNF错误:地址标记错误或磁道地址没有被发现。
BBK错误:坏块标记错误。
一般来说,硬盘的软损坏是可以修复的,很多硬盘厂商发布的硬盘管理和维护软件都具备修复硬盘软损坏的能力。像扇区逻辑错误这样的问题,即使是一般的低级格式化软件,也是完全可以胜任的。不过在所有的软损坏当中,系统服务区出错属于比较难以修复的种类,因为即使是同一家厂商生产的同一种型号的硬盘,系统服务区也不一定相同,而且硬盘厂商一般不会公开自己产品的系统服务区的内容和读取的指令代码。目前只有IBM和日立硬盘的系统服务区有公开的修复程序。日立的DFT和IBM的DDD-SI软件对系统服务区出错的修复成功率还是很高的。这两款软件都是由硬盘厂商发布的,有非常强大的功能,效果和可靠性比第三方软件要好,当然,它们只分别对IBM和日立的产品有效。
其实即使是刚刚出厂的全新硬盘,其盘片上也不可能没有瑕疵。由于磁盘盘片非常精密,对生产环境和移动都有非常高的要求,即使是一粒灰尘、一次很轻微的碰撞,都可能导致几个到几百个坏扇区的产生。所以,一般的,120GB容量的全新硬盘,其盘片上有几千个坏扇区也是很正常的,只不过硬盘厂商会使用专门的设备去扫描盘片,把那些坏扇区和磁介质不稳定的扇区都记录下来,做成一个硬盘缺陷列表(通常称为P-List),并将它写进系统保留区,然后通过控制程序将这些扇区屏蔽,使硬盘的控制程序在读取硬盘数据的时候不会再去读取这些区域。这样,由于在控制层就已经屏蔽了有问题的扇区,所以用户无论使用哪种格式化和分区软件,都不会看到这部分扇区,硬盘看起来就像真的完全没有坏道一样。同时,硬盘里面还有另外一种封闭区域,称为保留容量。这是完全没有问题的区域,只是因为某种原因被封闭起来了。例如,一块硬盘的容量是60GB,而盘片单片容量为40GB,那么由两片盘片构成的硬盘就必须封闭20GB的容量(盘片的生产线都是一定的,厂商为了降低成本,一般只生产一种容量的盘片,所以要通过封闭不同容量的区域来获得不同的实际硬盘容量)。
弄清楚硬盘的生产原理,就很容易理解厂商是如何维修硬盘的了。对于控制电路、磁头等部件的故障,用最简单的替换法,换上新的零件就可以了。对于IC芯片,可以通过重写信息内容或者替换IC芯片等方式修理。对于磁盘盘片的问题,情况会比较复杂。首先,厂商会用专门的仪器或设备对盘片表面按照实际的物理地址重新进行全面扫描,找出所有坏的、不稳定的扇区,形成一个新的硬盘缺陷列表,然后将该列表写进硬盘系统服务区,以替换原来的硬盘缺陷列表,再调用内部低级格式化程序对硬盘进行内部低级格式化。硬盘修复软件会根据新的系统服务区信息,重新对所有的磁道和扇区进行编号、清零,并重写磁道伺服信息和扇区信息,减少扇区的容量则从保留扇区中提取。经过这样的处理,返修的硬盘就又可以像新的硬盘一样使用了。
目前,软件修复硬盘扇区的物理性损坏一般有两种主要方式,分别是反向磁化和修改硬盘缺陷列表。
反向磁化是最先被应用的一种修复硬盘扇区物理性损坏的方式。一般的,硬盘的磁头只能负责读取和写入信号,而读取、写入数据信号所需的电平信号与磁盘表面的磁介质本身是不一样的。而反向磁化就是通过用软件指令迫使磁头产生与磁介质本身相应的高低电平信号,通过多次的往复运动给损坏或者失去磁性的扇区加磁,使这些扇区的磁介质重新获得磁能力,HDD Regenerator是最先采用这种方式的软件。反向磁化最大的缺点是速度慢,对一个磁介质不稳定或失去磁能力的扇区进行磁化,磁头很可能要往复成百上千次。如果硬盘上只有几十个或几百个坏扇区,这种方法或许还可行,但是现今硬盘的容量动辄数百千兆字节(GB)甚至数万亿字节(TB),有上万个坏扇区是很平常的事情,如果再用这种方法去修理,则会大大加快硬盘报废的速度。另外,这些扇区的磁介质本身就不稳定,即使再次被磁化,在一段时间内可以使用,但仍随时有重新失去磁能力的危险,硬盘其实并不稳定。同时,这种方法不能修复物理划伤之类的硬损坏。
对这种硬盘,在需要恢复数据时,一般通过扇区克隆或者镜像工具(如PC3000、MTL、COPR等),将硬盘分区或整个磁盘克隆到正常硬盘上或者做成镜像文件,然后使用手工方式或者软件(常用工具如Runtime、Winhex、R-Studio、UFS Explorer、File Scavenger等)提取数据。
修改硬盘缺陷列表的方式就是对反向磁化的改进,这种方法和上面所介绍的硬盘厂商的维修方法非常相似。由第三方服务商根据厂商公开的技术资料,结合分析和逆向工程,逐步破解厂商的部分指令代码甚至固件,编制出程序软件,实现读取、修改和重写硬盘系统服务区信息的功能。这样,第三方服务商就可以像硬盘厂商一样,对磁盘盘面按照物理地址进行扫描,重新构造缺陷扇区列表,并将该列表写进系统服务区来替换原有的列表。经过这样的软件方法维修的硬盘,从理论上说,与硬盘厂商维修的硬盘是没有差别的。PC3000、MHDD、HRT、效率源等就属于这种工具。
1.8 硬盘初始化过程与固件维修基础知识
硬盘电路板上放置了支持硬盘工作的各种电路,包括接口、DSP处理器、ROM、内存(硬盘DSP处理器使用的内部内存,作用与主机内存类似)、信号处理电路和电机驱动电路等。DSP处理器用于控制信号和数据的转换、进行编/解码等操作。ROM中存储了硬盘初始化操作所需的部分程序。ROM可能分为两部分:一部分是集成在DSP内的ROM,这是一定要有的;除了集成在DSP内的ROM,还有扩展ROM,表现为PCB上独立的ROM芯片(可能是EPROM、Flash ROM等)。如果有扩展ROM,则DSP首先从扩展ROM启动。信号处理电路负责对信号进行编/解码和变换。电机驱动电路负责精确控制盘片的转速和进行磁头定位。
正常情况下,硬盘在接通电源之后,都要进行初始化过程,这个过程也称为自检。自检时硬盘都会发出一阵自检声,这些声音的长短和规律视不同品牌而异,但同型号的正常硬盘的自检声是一样的。
自检声是由硬盘内部的磁头寻道及归位动作发出的。为什么硬盘刚通电就需要执行这些动作呢?简单地说,是因为硬盘正在读取记录在盘片中的初始化参数,这些参数就是硬盘的“固件”。由于现在固件的概念用得比较滥,这里姑且约定:DSP使用的微代码,称为程序或微程序;硬盘服务区(有时也称为系统服务区),指的是硬盘上从物理0扇区至逻辑0扇区之间的区域,也就是我们常说的“负磁道”的位置;而固件是没有严格定义的一个词汇,有时候指硬盘内部所有的系统软件和参数,有时候仅指系统服务区内的参数与表格,本书也不加以区分,请读者根据上下文自行判断。以上各部分的位置关系如图1-22所示。
图1-22 微程序、固件等的位置关系
硬盘有一系列基本参数,包括品牌、型号、容量、柱面数、磁头数、每磁道扇区数、系列号、缓存大小、转速、适配数据、区域分配表、S.M.A.R.T值等,这些参数就是固件。其中的一部分会标注在硬盘标签上,有些则只能通过专用软件才能检测出来。这些参数仅仅是初始化参数的一小部分,盘片中记录的初始化参数有数十甚至数百个。重要的是,没有这些参数,硬盘就不能正常工作。
硬盘的DSP处理器在通电后首先运行ROM中的程序(如果有扩展ROM,就从扩展ROM启动;如果没有扩展ROM,就从内部ROM启动),一部分硬盘还会检查各部件的完整性。然后,主轴电机起转,当转速达到预定转速时,磁头开始移动并定位到盘片的服务区,读取存储在硬盘服务区中的微程序和固件。固件在硬盘上的物理位置并不是一定的,完全由硬盘的设计决定。参数以模块的形式表现出来,可能每个参数占用一个模块,也可能几个参数共同占用一个模块。模块的大小也不一样,有些模块只有1字节,有些则达到几十千字节(KB)。参数不是连续存储的,而是各有各的固定位置。同时,也不是所有固件都一定要写在盘片上。一部分硬盘会先将ROM中的系列号与盘片上的系列号进行比较,如果不一致,硬盘会终止初始化工作。如果固件的关键扇区或文件损坏,硬盘就可能出现敲盘、不能被BIOS识别或识别错误等故障。
当所有必需的固件被正常读出后,磁头会定位到硬盘的0柱面、0磁头、1扇区,也就是我们常说的“0道”。一般来说,硬盘的0磁头靠近盘片电机,也就是硬盘的底部,而0道靠近盘片的边缘。硬盘向主机报告就绪后,我们才能对硬盘进行操作。
如果某一项重要参数找不到或出错,启动程序将无法完成正常启动过程,硬盘会进入保护模式,DSP程序结束,无法进入正常的工作状态。在保护模式下,用户可能看不到硬盘的型号与容量等参数,或者无法进行任何读写操作。近来有些系列的硬盘就是因为固件出错而出现类似的问题,如富士通的MPG系列自检声正常却不认盘,迈拓的美钻系列认不出正确型号及自检后停转,西部数据的BB、EB系列能正常认盘却拒绝进行读写操作等。
对一块硬盘来说,并不是所有的空间都用于存储用户的数据信息,有相当一部分空间对用户来说是不可见的,包括系统服务区和备用区(Reserve Area,也称为保留区)。而用户数据、文件系统等,都存储在用户数据区。系统服务区用于存储服务信息,即硬盘的内部程序和一些辅助表格,以保证硬盘能够正常工作。备用区用于替换用户工作区内的故障扇区和磁道。这两个区域在日常使用时是无法访问的,需要在特定模式下通过专用指令进行访问。用户访问的工作区,称为硬盘的逻辑空间,硬盘的容量标签中标注的就是这一部分空间的容量。这一部分空间的容量也是操作系统管理的容量。
而要访问系统服务区,就必须使用相应的指令系统,并在某种条件下进行。一旦进入这个指令系统,我们就可以借助这些技术指令进行很多操作,如读/写系统服务区的扇区信息、获取系统服务区的模块和表格配置图、获取扇区分配表、进行LBA与PCHS(Physical Cylinder Head Sector,物理柱面、磁头、扇区)互换、进行低级格式化、读/写硬盘ROM等,这些都是在通常模式下无法进行的操作。
硬盘是一个复杂的智能系统,要完成复杂的工作,需要很多条件。一个DSP处理系统的工作原理如图1-23所示。
图1-23 DSP处理系统的工作原理
DSP是“Digital Singal Processing”的缩写,使用RISC常采用指令和数据分开的哈佛结构,并采用多线程操作方式,一般用在实时控制系统中,硬盘就是其典型应用之一。DSP的运行需要程序和参数的支持,而程序和参数就存储在ROM和系统服务区中,它们对硬盘的运行来说是必需的。系统服务区的内容可以分为以下几类。
微程序模块(overlay,重载或覆盖,意思是可根据需要加载到内存中运行)。
配置和设置表。
缺陷表(P-List、G-List)。
工作记录表,如自测(SelfScan)、校验(Calibrator)程序的工作结果等。
DSP程序也是分开存储的,其地址空间分为ROM空间和RAM空间,而ROM通常又分为内部ROM和扩展ROM。内部ROM是在硬盘生产过程中写入的固定指令。这部分指令的作用是对DSP进行有限初始化,搜索有效的外部扩展ROM。如果外部扩展ROM存在,则将控制权交给扩展ROM中的程序,或者在检测到安全模式时接受从IDE接口传输的指令,并将控制权交给扩展ROM中的程序,这也是我们能够借助工具操作固件的基础。
外部ROM多采用25P102等串行Flash ROM存储硬盘操作系统的初始化部分。这部分指令的作用是设置DSP的各项参数,从存储介质盘片中加载指令、数据及各种指针、表格,并执行相应的自检和自校准程序,完成后就将相应的寄存器置于就绪(Ready)状态,等待主机指令。
ROM用于存储指令,RAM用于存储数据。由于RAM在断电后内容会丢失,所以RAM中的内容应存储在硬盘服务区中。事实上,ROM虽然在断电后不会丢失内容,但一些意外情况(如温度过高、电源瞬间变化等)也会导致ROM信息丢失或错乱,因此很多硬盘在服务区中会保留ROM的备份,并且其大部分内容也是以overlay的方式存储在磁盘盘片上的,ROM中只有基本的部分。ROM和RAM在盘片的负磁道上采用UBA(Util Block Addressing,用于访问服务区的地址编址)方式分区域存储,并映射0000~7FFF的DSP地址空间。例如,迈拓硬盘固件区主要分为数据区、代码区、缺陷表区、自校区、交换区和保留区,各区域的地址和长度在不同的硬盘中是不一样的,其6E系列的地址空间如下。
数据区:UBA 0000~04B7。
代码区:UBA 04B8~15F7。
缺陷表区:UBA 15F8~2D67。
自校区:UBA 2D68~3A4B。
以上每个区域中又有若干子区域,其中最重要的就是ULIST扇区,负责固件模块地址的转换工作。
硬盘微处理器的工作程序包括初始诊断程序、伺服电机旋转控制程序、磁头定位程序、硬盘控制器及缓冲存储器的信息交换程序等,这些程序合称硬盘程序或硬盘系统。在有些型号的硬盘中,工作程序存储在微处理器的内部ROM或外部闪存中,但是对大部分型号的硬盘来说,一部分工作程序存储在磁盘的服务区内,而在电路板的ROM中只存储了初始化程序、定位程序以及从磁盘服务区向内存读取和复制其他程序的工作程序。由于程序是从服务区向微处理器的内存中加载的,而内存又是微处理器的工作地点,因此这些程序只在需要时才会运行,而不需要时就会被其他程序覆盖,所以也可以其称为管理程序或overlay程序。
在服务区内,overlay是以模块的形式存储的,包括模块头部、模块主体以及用于检测该模块完整性的校验区。当overlay加载到内存中时,硬盘微处理器计算其校验值,并将其与模块的检测值进行比较。如果与校验值不一致,就认为该模块已损坏,不能加载到内存中。这也是大多数具有overlay程序的硬盘发生故障的常见原因。通常在出现这种故障时,硬盘是不能够完整地运行的,也就是说,不是所有的overlay程序都能加载到内存之中并参与硬盘的工作。不同的overlay程序出现损坏,会表现出不同形式的故障。例如,硬盘一直处在忙碌(Busy)状态,不能就绪,或者在硬盘的识别过程中,BIOS会将硬盘认成出厂名称,或者虽然能认出硬盘型号,但容量不对,再或者识别出来的硬盘容量没有问题,却不能正常读写硬盘用户区的数据等。
硬盘的配置和设置表包含磁盘空间的逻辑和物理信息。这些表格对于电路板(一个属系的所有型号的硬盘电路板都是统一的)来说是必需的,其目的是让电路板独立地设置到这一属系的具体型号上,也就是说,使电路板正确地选择型号名称、最大LBA值,并正确地指定物理磁头的数量和Zone分配表。
配置表与工作程序一样,也是以模块的形式存储在硬盘的服务区内,同样包括模块头部、模块主体(表格)和校验值。在鉴别硬盘时,配置表以与工作程序相同的方式加载到微处理器的内存之中,并计算其校验值。配置表和工作程序一样,对硬盘的工作是至关重要的。通常情况下,一旦配置表发生损坏,那么硬盘在计算机的BIOS中便无法得到识别和确认,或者在识别过程中显示的硬盘容量、型号、名称及系列号等会出现错误。
目前的技术还不能确保每一片磁盘都没有任何缺陷。载体材料的非单一性、抛光和打磨上的缺陷,以及制作磁层时杂质的介入等因素,都有可能使硬盘的某些区域在读写过程中产生错误。硬盘都有一部分富余容量用于替换工作区中的坏扇区和坏道。在使用了这样一种替换机制后,即使磁盘表面出现了一定数量的缺陷磁道,硬盘的总体容量也不会减少。为了进行这样的替换,硬盘中设置了一个专门的缺陷隐藏程序,叫做“Defect Management”(缺陷管理)。设计该程序的主要目的是发现硬盘中的缺陷区域,并将其放置在一种名为“缺陷表”的专门表格之中,之后,再对逻辑空间向物理空间转换的系统重新进行计算,从而达到隐藏缺陷的目的。
缺陷表是在硬盘厂商的内部试验过程中填写的,厂商发现的所有“坏”扇区序号均在该表之中,这种操作被称为更新(隐藏)缺陷(Update Defect)。这样,当硬盘工作时,就不会访问被隐藏的缺陷扇区,因为它们已经被备用区替换了。所以,新硬盘的用户数据区内是看不到缺陷扇区的。
大部分型号的硬盘都有两个缺陷表,分别称为初始缺陷表(Primary或P-List)和生长缺陷表(Grown或G-List)。初始缺陷表由生产厂商在进行工厂内部检测(SelfScan)的过程中生成。生长缺陷表则不同,它用于记录在硬盘使用过程中所发现的缺陷扇区信息。因此,几乎所有硬盘的用户指令表中都有一个叫做“Assign”的指令,通过该指令,就可以将对坏扇区的访问转向备用区。这一指令被许多检测程序所使用,其中自然也包括厂商推荐的用于修复硬盘坏扇区的程序。在西部数据硬盘中,有一个Data Lifeguard(数据救生)系统,可用于重新指定坏扇区。Data Lifeguard系统可将有缺陷的扇区打上“BAD”(坏)标志,并将用户数据挪到备用区内,以后就由备用扇区代替原来的坏扇区。从隐藏缺陷的类型上讲,这种方法与执行Assign指令一致。富士通、昆腾、迈拓和IBM硬盘可以在“写”的过程中自动隐藏缺陷扇区,也就是说,在将数据写入有缺陷的扇区时,硬盘会自动给缺陷扇区打上“BAD”标志,并将访问指向备用区中用以替换这个坏扇区的扇区,其编号同时被填写到G-List中。
工作记录表包含硬盘生产和运行过程中的一些辅助信息,如检测结果、检测程序运行记录等。在通常情况下,这些表格中的内容并不重要,而且在用户的一般工作状态下,它们的损坏不会影响硬盘的工作。但是,在用户准备对硬盘进行二次使用(刷新),以及执行SelfScan和Calibrator等操作时,就需要使用这些模块了。
一般来说,可以使用两种方法来隐藏有缺陷的扇区,一种是上面介绍的重新指定扇区法(Assign),另一种是忽略缺陷扇区法。重新指定扇区法的示意图如图1-24所示。
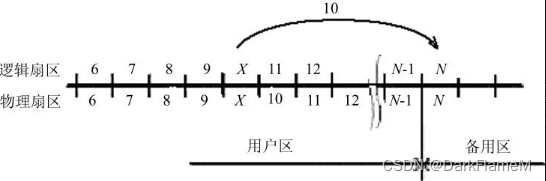
图1-24 重新指定扇区法
硬盘厂商隐藏缺陷扇区的方法称为忽略缺陷扇区法。使用这种方法时,缺陷扇区会被忽略,而下一个扇区将被冠以缺陷扇区的序号(以此类推)。这样,原先用户区的最后一个扇区将被移到磁盘的备用区,如图1-25所示。
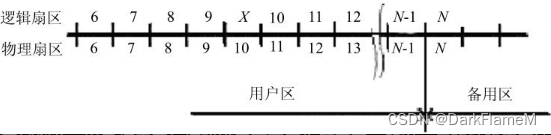
图1-25 忽略缺陷扇区法
这种隐藏方法会破坏低级格式化的连续性和完整性。LBA向PCHS的转换系统应该考虑坏扇区,并在访问数据时将其忽略。逻辑磁盘空间与物理格式之间的关系可借助一种专用的程序——译码器——来实现。这种专用程序考虑了磁盘的物理格式、区域划分,以及坏扇区与坏磁道已不再工作等因素。所以,忽略缺陷扇区法要求必须对译码表重新进行计算,而且会破坏用户事先写入数据的完整性。正因如此,这种隐藏方法只在硬盘处于一种专门的工作状态时才能使用。
ROM里的程序就是DSP运行的代码,它可以通过反编译进行分析。服务区的内容可以用ROM中的程序读取到内存中运行。DSP内部本身也有ROM和RAM,不过容量都很小,如果程序无法存储,就需要对其进行扩展,扩展后在电路板上就可以看到独立的ROM芯片。有些型号的硬盘只在ROM中保留基本代码,而将真正的引导程序放在硬盘服务区上。由于服务区没有ROM可靠,所以这些硬盘更容易出现问题。
硬盘在正常启动时会与BIOS进行通信,如果启动失败,硬盘中的引导程序就会结束。而处理固件需要通过ROM中的程序来执行,因为只有它才能访问硬盘,所以在处理硬盘固件时,常常需要进行DSP复位。
PC3000能读出硬盘内部的固件信息,以分析每个固件所处的模块是否正常,并且能修正这些参数,将其重新写回盘片中的指定位置,这样就可以把一些因为固件参数错乱而无法正常使用的硬盘恢复到正常状态。另外,服务区也不一定位于盘片的边缘,品牌不同,其位置也不同,而且每个盘片上都有备用服务区。
1.9 ATA Command基础
要处理硬盘固件,就必须与硬盘内部的程序系统进行通信,自然也少不了与硬盘接口打交道,因此这里再简单介绍一下硬盘接口的相关知识。
在计算机存储系统中,硬盘的地位举足轻重,相应的,其接口技术的发展也经历了一代又一代的演变。在过去几十年的发展历程中,衍生出如ATA、SCSI、SATA、SAS(Serial Attached SCSI,串行连接SCSI)等多个体系,且每一个体系又都包含多项子标准,并由此构成了一个庞大的接口技术家族。而每次接口技术的变革,都为硬盘的新一轮发展打下了基础,使硬盘性能的提升成为可能。正是由于接口的重要作用,业界普遍以接口类型作为硬盘换代的主要标志。下面先回顾一下硬盘接口的历史沿革:从最早的ST-506/412接口,到后来的IDE、EIDE和同时代的SCSI接口,再到目前流行的SATA和SAS接口。由此我们可以了解这些技术的产生背景、特征以及随之而来的存储业界的变迁。
1.硬盘接口的初始时代
1956年9月,IBM的一个工程小组向世界展示了第一台磁盘存储系统—— IBM 350RAMAC(Random Access Method of Accounting and Control),硬盘时代从此开始。不过,早期的硬盘主要用在飞机预约、自动银行、医学诊断及航空航天等专业领域,未涉及民用市场。直到20世纪80年代初PC诞生之后,这种情况才逐渐得到改善。而业界也广泛认为,硬盘接口技术应该从PC时代开始,因此,希捷公司提出的ST-506/412可以说是当今硬盘接口的始祖。
1981年8月,IBM推出了型号为5150的第一台PC。这台PC采用DOS 1.0操作系统,但不支持任何硬盘,直到后来改用DOS 2.0操作系统之后才引入了子目录技术,并增加了对大容量存储设备的支持。看到其中蕴含的商机,一些公司就研发出了专供IBM PC使用的外置硬盘。这套外置硬盘系统包含1个硬盘、1块控制卡和1个独立电源,硬盘在与控制卡相连的同时借助一条电缆与插在PC扩展槽中的适配器相连。
IBM很快就意识到硬盘对于PC的巨大价值,在1983年推出的PC/XT机型中,直接内置了一块容量为10MB的硬盘。同时,IBM还将独立的控制卡功能集成到硬盘的接口控制卡上,硬盘控制器的概念由此产生。在连接方面,IBM也首度引入希捷公司提出的ST-506/412硬盘接口。这种接口将硬盘的编解码器放置在PC的硬盘适配卡上,并使用一根34芯的控制电缆(Control Cable)和一根20芯的数据电缆(Data Cable)将硬盘与计算机连接起来。由于使用较为方便,IBM遂将该技术大规模引入PC/XT的硬盘系统,而ST-506/412也就顺理成章地成为PC硬盘接口的事实标准。IBM后来推出的PC/AT机型也采用了同样的技术方案。
由于那个时代的硬盘尚处于发展初期,容量低,性能也很差,因此作为第一代硬盘接口的ST-506/412,其速度并不重要。然而,PC的出现给硬盘厂商打了一支强心针。面对这个潜力巨大的市场,所有硬盘厂商都投入空前的精力开发新技术,在很短的时间内,硬盘的存储容量和读写性能就获得了快速提升,占据统治地位的ST-506/412接口很快遭遇瓶颈。有鉴于此,迈拓公司在1983年开发出一种名为ESDI(Enhanced Small Drive Interface,增强型小型设备接口)的新型接口技术,如图1-26所示。ESDI虽然也使用两根电缆来连接硬盘,但它对电缆的定义作了改变——最关键的是,它将编解码器直接放在硬盘的本体而非计算机的适配卡上,从而有效提高了硬盘的读写效率和工作稳定性,其传输速率也达到10Mb/s,是ST-506/412接口的2~4倍。

图1-26 IBM DNES 309270 90X6806硬盘(ESDI接口)
在那个年代,ESDI接口所拥有的10Mb/s的传输速率绝对是一个可观的高指标,它的出现理所当然地终结了ST-506/412接口的主导地位,ESDI也就成为新的标准,被众多OEM厂商用于IBM兼容机中。ST-506/412接口则逐渐被淘汰出局,到1987年前后,它便基本从市场上消失。以今天的眼光来看,这两种接口都非常原始,但它们的存在对规范硬盘接口标准起到了非常重要的作用,使PC硬盘的硬件兼容性得到了充分的保证,同时也为后续标准的提出打下了良好的基础。
ESDI接口一直使用到20世纪90年初。虽然迈拓公司一直积极发展其新版本,但ESDI接口成本高、设计较为复杂的问题一直难以克服。在IDE接口出现之后,ESDI接口也很快退出市场,IDE成为新的技术标准。今天我们使用的SATA硬盘,在本质上仍然隶属于IDE体系。
2.ATA-1 —— IDE硬盘出现
IDE接口最初是在1986年由CDC(Control Data Corporation,控制数据公司,1989年10月,其硬盘驱动器生产部门被希捷公司并购)、康柏和西部数据3家厂商共同开发的,全称为“Integrated Drive Electronics”,意思是将控制器与硬盘集成在一起的新型硬盘驱动器。这种硬盘的专用接口也被外界直接冠以“IDE”之名,但它真正的名称应该是“ATA接口”(Advanced Technology Attachment,ATA)。
IDE硬盘出现后,计算机的存储系统变得更为简单,不再需要额外的控制器,只需使用一根专门的40针线缆将硬盘与PC主板的对应接口或硬盘适配卡直接连接即可。由于硬盘与控制器的整合,首先,硬盘厂商不必再考虑自己生产的硬盘与其他厂商生产的控制器能否完全兼容,只要硬盘自身不发生故障,就能够在任何计算机系统中稳定地运行,大大减轻了硬盘厂商的负担,硬盘的兼容性与可靠性有了保证;其次,整合结构也有效减少了硬盘接口的电缆数目与长度,数据传输的可靠性得到了明显的提升。加之IDE硬盘成本明显低于ESDI硬盘,非常适合应用于PC系统中,所以该技术被提出后很快开始流行,而IDE硬盘附带的ATA接口也自然而然成为新的硬盘接口标准。
1990年,ATA-1标准被提交给ANSI(美国国家标准局)进行标准化。虽然在这时ATA-1已然成为事实标准,但ANSI内部的认证工作仍然花费了较长的时间,原因很可能是ATA-1是世界上第一个关于硬盘接口的标准,所以ANSI工作组对此非常慎重。但非常离谱的是,这项工作居然拖到1994年才完成,ATA-1标准才得以正式颁布,此时距离ATA-1的实际使用已经过去了四五年。
ATA-1标准有3项技术亮点,分别是支持双硬盘、引入PIO传输模式、支持DMA传输模式。在硬盘连接方面,ATA-1允许两块硬盘分享一个通道,两者分别定义为Master和Slave,也就是我们熟知的“主/从盘”的概念。在传输方面,ATA-1主要采用PIO传输中的0、1、2模式,三者支持的速度分别为3.3MB/s、5.2MB/s和8.3MB/s。另外,它还支持单字(Single Word)DMA 0、DMA 1、DMA 2和多字(Multi Word)DMA 0共4种DMA传输模式。但是,DMA模式在ATA-1标准中并没有得到实质性的应用。
ATA-1标准出现之后,自然是考虑接替它的ATA-2标准。但对ATA-2,西部数据和希捷出现了严重的分歧。西部数据公司于1994年提出EIDE(Enhanced IDE,增强型IDE)的概念,它实际上包含ATA-2和ATA PI(ATA Packet Interface)两项标准。其中,ATA-2为ATA-1的升级,而ATA PI则供CD-ROM、磁带机等存储设备使用。而希捷公司提出的Fast-ATA概念只针对硬盘,未考虑光存储设备的需求。但由于Fast-ATA的定义比EIDE更为清晰,从而获得了另一硬盘大厂昆腾的支持,在一定程度上具有更大的影响力。可另一方面,CD-ROM在当时发展迅速,西部数据公司提出的ATA PI标准也得到了广泛的应用,导致业界经常将Fast-ATA和EIDE两种技术混为一谈。需要明确的是,二者都是企业标准而非ANSI认可的国际标准,ANSI认可的ATA-2标准直到1996年才发布,该标准很好地将Fast-ATA和EIDE两项技术的特长融合在一起。
相比ATA-1标准,ATA-2标准在许多方面都有长足的进步。首先,ATA-2标准提供PIO 3、PIO 4和多字DMA 1、DMA 2模式,最高数据传输率可达16.6MB/s,相当于ATA-1接口的2倍;其次,ATA-2标准引入了区块传输机制,有效提升了数据传输速率;第三,ATA-2标准支持LBA技术,使计算机的可管理硬盘空间突破了ATA-1接口528MB的容量限制,达到当时被视为“超级海量”的8.4GB。
尽管技术提升明显,但业界并没有在ATA-2标准上停留太长时间。1997年,ATA-3标准由ANSI正式发布。与上一次升级不同,ATA-3并没有增加更高速率的工作模式,所允许的最高传输率仍维持在16.6MB/s的水准。ATA-3标准的主要侧重点在于提升数据传输的可靠性:其一,引入S.M.A.R.T(Self-Monitoring Analysis and Reporting Technology),让硬盘具备自主检测、分析和报告功能,这被广泛认为是一项划时代的改进;其二,ATA-3标准增加了一个简单的密码保护机制,在一定程度上提升了计算机系统的安全性;第三,针对传统40针排线容易造成传输错误的问题,ATA-3标准采取了一些改良措施。经过一番优化之后,ATA-3具备了很高的实用价值,在很短的时间内就完全取代了ATA-2,成为IDE硬盘的主导接口标准。
随后出现的ATA/ATA PI-4标准开创了Ultra DMA时代。20世纪90年代中后期,PC高速普及,硬盘领域的技术发展非常活跃,接口技术自然首当其冲。ATA-3标准同样没有使用太长的时间,因为Intel和昆腾早在1996年便联手制定了更先进的Ultra DMA/33标准,并于1998年获得ANSI认证,成为ATA/ATA PI-4正式标准,ATA接口由此迎来新一轮的重大技术变革。此时,ANSI标准的名称从纯粹的“ATA”演变为“ATA/ATA PI”,原因就在于CD-ROM驱动器已成为PC的标准配置,将ATA PI接口标准化恰逢其时。ATA/ATA PI-4标准拥有大量的技术改进。第一,支持Ultra DMA 0、DMA 1、DMA 2模式。Ultra DMA可以将时钟脉冲的上升沿和下降沿都用于数据传输,即1个时钟周期内可完成2次数据传输,由此将硬盘的接口速率提升到了33MB/s。也正因如此,ATA/ATA PI-4标准也被业界称为Ultra ATA/33、Ultra DMA/33或ATA-33。第二,引入80针结构的高性能数据线,其中40针为原有的数据线,新增的40针为接地线,可有效增强线路的抗干扰性。在ATA/ATA PI-4标准中,80针排线只是一个可选项,主板和硬盘厂商都倾向于使用廉价的40针排线,这种情况直到ATA/ATA PI-5标准出现之后才彻底改观。第三,引入CRC(循环冗余校验码)机制,优化了数据操作指令。这些细节方面的改进同样明显提升了ATA/ATA PI-4接口的传输品质。
在此之后,Intel与昆腾在1998年2月又拿出Ultra DMA/33的升级版本Ultra DMA/66。ANSI也在2000年通过对该版本的认证,颁布了对应的ATA/ATA PI-5标准。为实现66MB/s的翻倍效能,Ultra DMA/66标准对信号的时钟边沿特性进行了改进,令上升沿信号和下降沿信号各被识别为1个时钟周期,传输频率比Ultra DMA/33标准提高了1倍。由于效能大幅提升,数据线的信号干扰问题也越来越严重,所以Ultra DMA/66标准要求强制使用80针结构的高性能数据线,在一定程度上缓解了这个问题。此外,它也继承了CRC技术,有效保障了数据在高速传输过程中的完整性。
Ultra DMA/66标准同样在很短的时间里就占据了主导地位,Ultra DMA/33标准退居二线。但很快,业界发现Ultra DMA/66接口的速度仍然不够快。当时正处于硬盘技术的快速发展期,硬盘内部传输速率快速提升,Ultra DMA/66接口大有成为瓶颈的可能,因此,Intel和昆腾又着手于2000年6月推出了Ultra DMA/100标准。此时,硬盘市场竞争的激烈程度超乎想象,IBM、迈拓和希捷在该标准公布前就推出相关产品,VIA、SiS等芯片组厂商更是迫不及待,掌控标准主导权的昆腾反而落后。Ultra DMA/100标准构建在Ultra DMA/66标准的基础之上,但它将LBA模式扩展到28位,从而使支持的硬盘容量达到137GB。除此之外,Ultra DMA/100标准还引入了噪音管理和多媒体数据流命令这两项革新。前者允许用户在BIOS中设定硬盘的工作状态,分别是高性能或低噪音。因为当时的硬盘普遍存在工作噪音较高的问题,噪音管理技术就显得十分有用。而新增的多媒体数据流命令主要针对音/视频压缩而设立,这些应用都要求硬盘写入动作连续进行。尽管这项技术在Ultra DMA/100时代并没有得到实质性的推行,但后来多数硬盘厂商都采纳了这项技术。2002年,ANSI通过Ultra DMA/100认证,并颁布了相应的ATA/ATA PI-6标准,但此时Ultra DMA/100接口早已遍地开花,甚至连Ultra DMA/133接口都已广为使用。
到此为止,ATA标准族的发展宣告终止。Intel公司认为,基于并行原理的ATA接口失去了继续发展的价值。因为随着传输性能的提升,信号干扰越来越严重,数据在传输过程中频频出错,传输率每提升一小步都极为困难。为彻底解决这个问题,Intel在2000年春季的开发者论坛上率先提出串行ATA的概念,希望以高频率串行传输的方式实现硬盘接口的性能飞跃。随后,Intel宣布组建串行ATA工作小组,成员包括IBM、希捷、迈拓、昆腾(2000年10月被迈拓收购)、Dell等厂商,其中担负核心开发任务的是希捷公司。然而,工作小组中的迈拓公司别有想法,在收购昆腾之后便掌握了Ultra DMA系列标准的主导权。但进入串行时代后,标准的主导权落到了希捷手中,迈拓因此失去了制定硬盘接口标准的权力。显然,迈拓公司不甘于此。加之根据串行工作小组的开发计划,串行ATA至少要等到2003年才能进入实用阶段,两代标准过渡间隔时间太长,迈拓便萌生进一步升级Ultra DMA标准的想法。2001年7月,迈拓推出Ultra DMA/133接口规范,将硬盘接口的数据传输速率提高到133MB/s,理论性能十分接近串行ATA 1.0。遗憾的是,这套标准只是Ultra DMA/100标准的高频率版本,两者的技术特性如出一辙。虽然这样做可以实现“无缝兼容”,但并行总线的缺陷也因此暴露无遗——高频率让Ultra DMA/133接口在传输数据的过程中信号干扰更为严重,数据出错率甚高。加上当时硬盘的内部传输速率远未突破100MB/s, Ultra DMA/133接口的性能优势并没有在实践中获得丝毫体现。也正因如此,ANSI没有接纳Ultra DMA/133作为新一代硬盘接口标准,它仅是迈拓公司的自有规范,其余几个硬盘大厂也都没有对该标准提供支持。不过,芯片组厂商和控制器厂商对此态度十分积极,VIA、SiS、ALi、Promise、Highpoint、Adaptec纷纷响应号召,开发兼容Ultra DMA/133接口的芯片组或磁盘控制器,Ultra DMA/133接口因此也获得了一定程度的应用。到此为止,并行ATA接口体系画上了句号,PC迎来了崭新的串行ATA时代。
3.串行ATA
在ATA-7协议发布之前,ATA协议等同于PATA协议。从ATA-7协议开始,到后来发布的ATA-8协议,ATA协议中加入了SATA这一新的实现形式。现在的ATA协议是由PATA协议和SATA协议共同构成的—— ATA-8协议的第一卷给出了ATA协议的基本内容,第二卷给出了PATA协议的实现规范,第三卷给出了SATA协议的实现规范。在ATA-7之前的ATA协议中,第一卷和第二卷的内容是合并在一起的,而且没有第三卷的内容。
随着ATA-8协议的正式发布,经过两年的反复修订,作为ATA-8协议一部分的《ATA体系结构模型》也浮出水面。在这一文档中,明确区分了ATA体系结构模型、ATA实现标准和ATA具体实现的概念。这一文档给出了现有ATA协议实现方式中应共同遵循的抽象结构,并指明各种实现方式只要兼容这一标准,可以采用各种形式。如此一来,只要提出新的实现标准,ATA协议就可以实现新的兼容形式。ATA体系结构模型如图1-27所示。
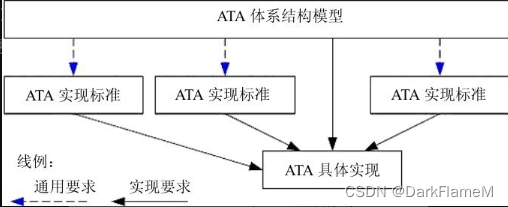
图1-27 ATA体系结构模型
在这一体系结构模型中,提出了ATA协议的分层模型和ATA协议的“客户端-服务器”模型。设备作为“服务器”,具有和主机同等的地位和层次结构,如图1-28和图1-29所示。ATA协议在主机端和设备端都获得了巨大的发展空间。

图1-28 ATA层次模型
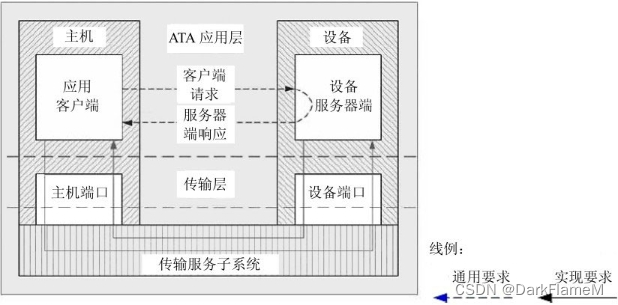
图1-29 ATA传输实现
纵观ATA协议的发展历史,通过从ATA协议中抽象出ATA体系结构模型(AAM),PATA和ATA终于分清了形式和内容的关系—— PATA和SATA一样,都是ATA协议的特例,是ATA协议具体的实现方式,并各自遵循特定的实现标准。
以ATA-8为例,该命令集包括ATA协议的实现,指明了主机系统访问存储设备的命令集。该命令集为系统制造商、系统集成商、软件供应商和智能存储设备制造商提供了一个通用命令集。ATA文档之间的关系如图1-30所示。
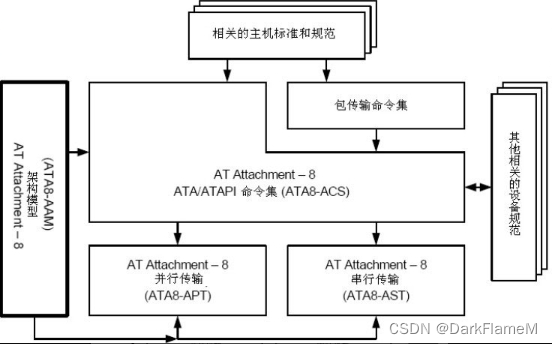
图1-30 ATA文档关系
ATA设备指的是仅实现了通用特征集但没有实现包特征集的设备。ATA8-ACS设备指的是按ATA8-ACS标准实现的设备。而ATA PI设备指的是实现了包特征集却没有实现通用特征集的设备。设备对部分通用特征集和包特征集的支持情况如表1-12所示。
表1-12 设备对部分特征集的支持情况
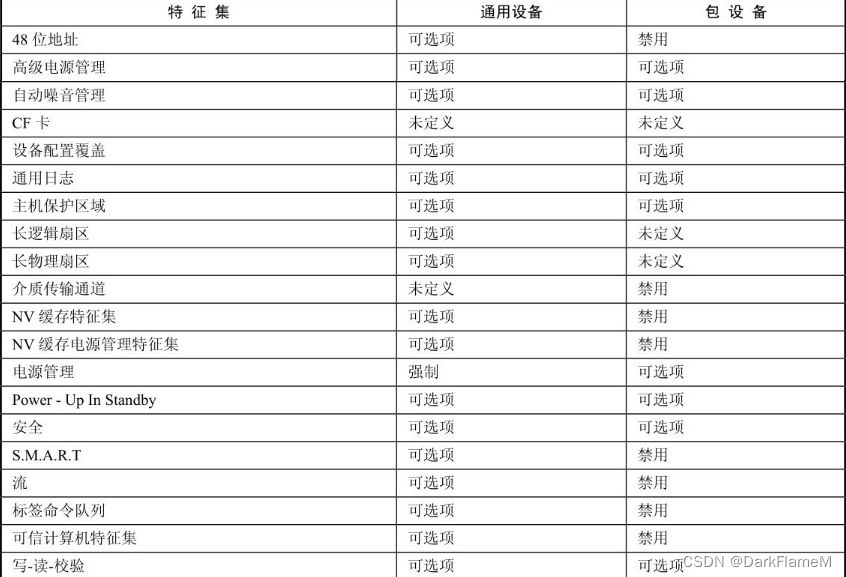
命令可以通过两种方式进行传送。对实现通用特征集的设备,通过向设备传送一个命令块来实现所有命令和命令参数的传送。对实现包特征集的设备,使用设备重置和包命令集来控制,类似通用特征集的子集。一般的主板都集成了两个IDE控制器(分别是主控制器和次控制器),并使用不同的端口地址(主控制器为1F0H~1F7H、3F6H~3F7H,次控制器为170H~177H、376H~377H)。每个I/O地址对应IDE控制器的一个寄存器。主控制器的I/O地址所对应的寄存器如下。
1F0(读、写):数据寄存器。
1F1(读):错误寄存器。
1F1(写):特征寄存器。
1F2(读、写):扇区数寄存器。
1F3(读、写):LBA低字节寄存器。
1F4(读、写):LBA中间字节寄存器。
1F5(读、写):LBA高字节寄存器。
1F6(读、写):驱动器/磁头寄存器。
1F7(读):状态寄存器。
1F7(写):命令寄存器。
3F6(读):备用状态寄存器。
3F6(写):设备控制寄存器。
3F7(读):驱动器地址寄存器。
状态寄存器是一个8位寄存器,从左到右各位的意义分别如下。
BSY(Busy):忙。
DRDY(Device Ready):设备就绪。
DF(Device Fault):设备故障。
DSC(Seek Complete):寻道完成。
DRQ(Data Transfer Requested):数据传输请求。
CORR(Data Corrected):按ECC算法校正从硬盘中读取的数据。
IDX(Index Mark):索引标志。
ERR(Error):错误。
错误寄存器也是一个8位寄存器,从左到右各位的意义分别如下。
BBK(Bad Block):坏块。
UNC(Uncorrectable Data Error):读扇区时出现无法校正的ECC错误。
MC(Media Changed):介质变化。
IDNF(ID Mark Not Found):没找到要访问的扇区或CRC错误。
MCR(Media Change Requested):介质变化请求。
ABRT(Command Aborted):命令失败。
TK0NF(Track 0 Not Found):重校准时没有发现0磁道。
AMNF(Address Mark Not Found):没找到要访问的扇区。
以希捷Barracuda ATA IV系列硬盘为例,该系列硬盘支持16位数据传输以及PIO模式0~4、DMA模式0~2、Ultra DMA模式0~5,支持的ATA标准命令集如表1-13所示,与主机的电路连接如图1-31所示(详细描述请参考ATA-5标准)。

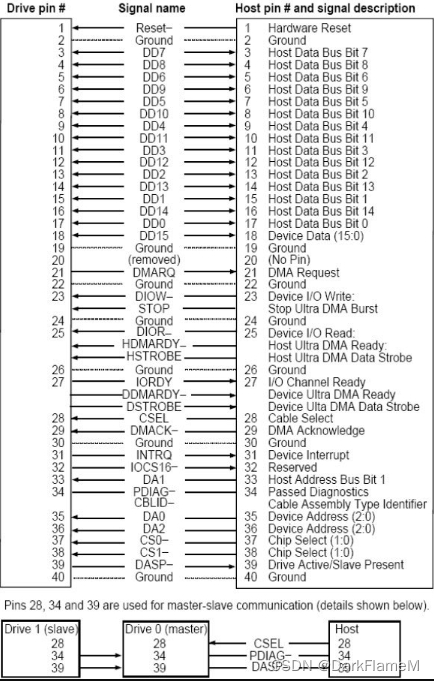
图1-31 希捷Barracuda ATA IV系列硬盘与主机连接图
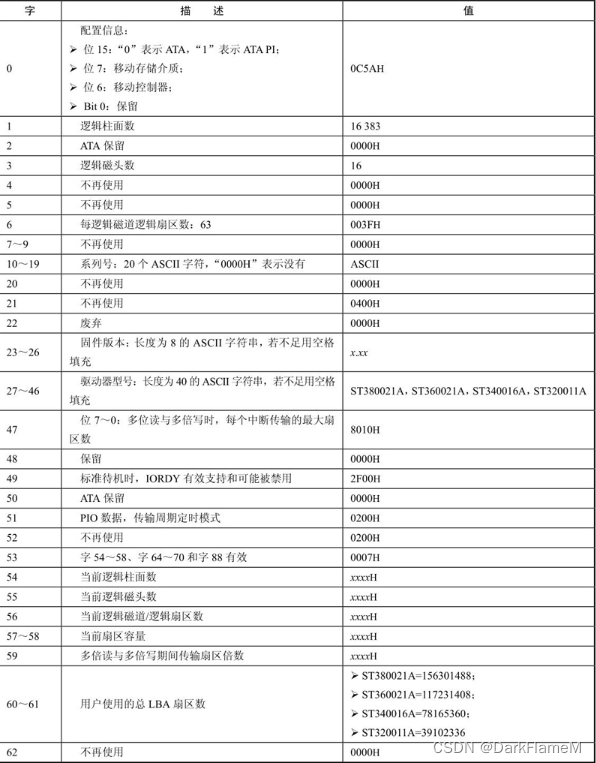
以设备识别命令(命令代码ECH)为例,该命令在加电后将设备信息传送到主机。这些信息组织成一个单一的512字节的数据块,该Barracuda ATA IV硬盘的内容如表1-14所示。其中所有保留的位或字都应置0。
表1-14 设备识别命令
续表

其他命令(如设置特征集命令、SMART命令等)大都类似。
在ATA体系高速发展的同时,针对服务器/工作站设计的SCSI接口同样也在高速前进。SCSI是一种总线型的系统接口,可连接多种不同类型的存储设备,这一点与专为硬盘服务的ATA接口有明显的区别。而在工作模式上,SCSI也与ATA截然不同。SCSI系统拥有专门的总线控制卡,所有与数据的读写和传输相关的运算工作都由SCSI卡独立完成,无须耗费CPU资源。因此,SCSI设备的CPU占用率非常低,这对读/写操作极度频繁的服务器/工作站系统来说非常重要。而ATA接口则不同,它的接口控制器只能实现信号转接,实际运算工作都得由CPU完成。所以,可以看到,ATA硬盘在读写大数据量时,系统CPU的占用率非常高,用户除了等待没有别的选择。这种特性注定ATA不可能在服务器领域生存,SCSI总线将成为服务器/工作站厂商唯一的选择。
SCSI总线的诞生时间最早可以追溯到1979年。当时,美国的Shugart Associates公司(希捷公司的前身)开发出了一种8位宽度的并行总线,用于小型机与外部设备的连接。该接口被Shugart Associates命名为“SASI”(Shugart Associates System Interface)。在基本结构上,SASI接口采用了IBM提出的I/O通道方式,允许单台或多台计算机在单一的总线上与多台外设进行通信。在那个年代,SASI的出现堪称一大创举,Shugart Associates公司也对该技术寄予厚望。1980年,Shugart Associates将SASI提交给ANSI委员会,希望它能够成为业界公认的总线标准,但ANSI认为SASI不够完善而未予批准。Shugart Associates没有就此放弃,而是迅速根据ANSI的反馈意见对SASI总线技术进行了修订,在1981年底重新将它提交给ANSI并成功获得批准。ANSI下属的X3T9.2委员会接受了SASI接口,并决定在SASI接口的基础上设计更具通用性的SCSI接口。1984年,X3T9.2委员会将SCSI-1标准草案提交给ANSI。经过两年的讨论,ANSI于1986年6月正式认可SCSI-1,将之纳为ANSI X3.131-1986标准,SCSI标准正式诞生。不过在这之前,已有一些计算机厂商迫不及待地引入了SCSI技术,如苹果公司在1985年推出的Macintosh机型中就率先采用SCSI-1作为计算机与外部设备的连接总线。
与初始SASI接口规格相同,SCSI-1接口也采用8位结构的并行总线,工作频率为5MHz,数据传输率为5MB/s。在1986年,这样的规格非常可观。不过最富远见的是,SCSI-1不仅支持标准的单端信号(Single-End, SE)传递方式,还支持差分信号(Differential)传递方式。传统的信号传递方式只使用1条线路,高电平表示“1”、低电平表示“0”;而差分信号则要求使用一对线路,以它们的电压差作为二进制数据的区分标志,如电压差为正值表示“1”、为负值表示“0”(或相反)。这样,即便在数据传输过程中遇到严重的干扰,导致传输信号的异常变大或变小,但两条线路的电压差值总可以保持在一个相对固定的范围内,最终的二进制数表示不会受到影响。也就是说,差分信号具有很强的抗干扰性能。这项设计也为后续SCSI技术所采纳并成为标准。在传输模式方面,SCSI-1可支持同步模式(Synchronous)和异步模式(Asynchronous),具有良好的适应性。
超强的连接能力是SCSI-1技术的主要亮点之一,它使用50针扁平电缆(单端信号,称为A型线缆)或25对双绞线电缆(差分信号)与外部设备相连。如果使用单端信号,数据线缆的长度限制在6米;而如果采用差分信号,线缆的长度最大可达到25米,抗干扰能力明显优于前者。由于信号的表达方式和连接总线都不相同,单端SCSI-1设备与差分SCSI-1设备自然无法兼容——两者既不能同时串接到一条线缆上,也不能相互转换连接。不过,真正获得广泛应用的还是单端信号技术,原因在于它的成本较为低廉,6米长的线缆也足够使用。差分信号技术固然在抗干扰方面胜出一筹,但其高昂的成本令多数厂商难以接受。不论采用何种信号技术,SCSI-1都能在一条总线上同时连接8个SCSI设备(包括计算机主机,可连接的外设数量为7个)。
SCSI-1标准的概念不仅局限于总线传输和接口连接,也深入到外设的逻辑控制层面。例如,SCSI硬盘采用LBA方式寻址,逻辑块的大小通常被默认设定为512Byte,用户也可根据需要进行更改。这种方式与IDE硬盘的CHS寻址方式存在本质的区别。SCSI-1标准还包含许多可选的基本控制命令,这些命令分别针对不同的外设产品。但由于外设种类繁多,SCSI的命令集显得非常烦琐。后来,业界干脆在这些命令集中抽取了18条基本命令,组成由所有外设共享的公共命令集(Common Command Set, CCS),该命令集也成为SCSI-2规范的基础。
SCSI-1标准推出不久,后续的SCSI-2标准草案就于1988年诞生了,硬盘厂商也迫不及待地开始相关产品的研制工作。1990年8月,ANSI的X.3T9委员会正式批准了SCSI-2标准(对应于ANSI X3.131-1990标准),但在4个月后,ANSI又作出召回决定,对SCSI-2标准进行了进一步的修改,并直到1994年1月才正式发布(对应于ANSI X3.131-1994标准)。
与单纯的SCSI-1标准不同,SCSI-2标准先后出现了FAST SCSI、WIDE SCSI和FAST WIDE SCSI共3个分支规范:FAST SCSI为8位总线,工作频率提升至10MHz,总线传输率提升至10MB/s,无缝兼容之前所有的SCSI-1设备;WIDE SCSI采用16位总线、5MHz频率设计,接口速度为10MB/s,支持15个外部设备;FAST WIDE SCSI采用16位总线、10MHz频率设计,数据传输率达到20MB/s。为适应这种改变,16位宽度的WIDE SCSI和FAST WIDE SCSI都使用+5V的高压差分信号(High Voltage Differential Signal,简称HVDS)技术,并引入新型的68针扁平线缆(称为B型线缆)和连接器,但线缆的长度由先前的6米缩短至3米。也是在SCSI-2时代,出现了一种80针的D型SCA(Single Connector Attachment,单一连接器附属装置)接口。该接口由Sun、希捷和Conner共同提出,通过将SCSI-2的50针或68针接口与电源线、SCSI ID信号、LED信号、主轴马达同步信号整合,有效提高了SCSI设备连接的方便性,主要用于服务器的热插拔环境中。
SCSI-2标准带来的另一项重大变革是命令队列(Command Queuing)功能,该功能可以对硬盘的读/写命令队列进行优化,使操作任务能够在最短的时间内完成,达到提升硬盘性能的目的。
在SCSI-2还没有成为正式标准时,SCSI-3标准就被提上了日程。SCSI-3标准与前两代标准在概念上存在巨大的差异,它不仅包含SCSI的传统范畴,而且将所有的物理连接、电气接口、主要命令集和具体协议都纳入SCSI-3体系中。为适应这种变化,SCSI-3采用了层级(Layer)的概念,在协议和互连方面增加了FC、IEEE 1394、SSA等串行接口。继承原来的SCSI-1和SCSI-2的并行接口称为SPI-1(SCSI-3 Parallel Interface-1)。但为通俗起见,仍然将SCSI-3 Parallel Interface简称为SCSI-3或Ultra SCSI,这样做也符合业界的习惯。需要明确的是,SCSI-3 Parallel Interface-1/Ultra SCSI只是SCSI-3标准的一个基本组成部分。
SCSI-3标准颁布于1995年,细分为标准型Ultra SCSI和扩展型WIDE Ultra SCSI两项子规范(SCSI-3 Parallel Interface-1又称为Ultra SCSI便出于此)。Ultra SCSI仍沿用传统的8位总线,但工作频率被提升至20MHz,对应于20MB/s的数据传输率,使用传统的50针线缆;WIDE Ultra SCSI则使用16位总线、20MHz频率的设计,这样便获得了40MB/s的高性能,但它必须使用68针B型线缆。由于工作频率较高,信号干扰就成了大问题。为保证数据传输的可靠性,Ultra SCSI和WIDE Ultra SCSI不得不将线缆长度进一步缩短到1.5米,这大大减弱了其扩展能力。
1997年,SCSI行业协会(SCSI Trade Association,简称STA)颁布了Ultra 2SCSI规范,这被广泛认为是SCSI技术史上的里程碑。为解决Ultra SCSI标准存在的信号干扰严重的问题,Ultra 2 SCSI标准引入了更为先进的低压差分(Low Voltage Differential,简称LVDS,电压为+3.3V)技术来表达和传输信号。LVDS的工作原理类似于前面提到过的高压差分(HVDS),两者都具有卓越的抗干扰性能,区别在于LVDS技术拥有更低的功耗。LVDS的引入让Ultra 2 SCSI标准的工作频率轻易攀升到40MHz,而Ultra 2 SCSI标准自身又包含标准型Ultra 2 SCSI接口和WIDE Ultra 2 SCSI接口两种方案,前者使用8位总线、后者使用16位总线,使它们的数据传输率分别达到40MB/s和80MB/s,性能大幅领先ATA技术体系。此外,LVDS技术也让Ultra 2 SCSI标准的线缆长度从之前的1.5米大幅度跃升至25米,而16位WIDE Ultra 2 SCSI标准的线缆长度也达到了12米,充分满足了服务器系统的扩展要求。
尽管技术先进,性能也足够使用,但Ultra 2 SCSI标准并没有风光太久。仅在Ultra 2 SCSI标准发布一年后,它的接替者—— Ultra 3 SCSI就诞生了,SCSI总线两三年升级一次的惯例也被打破。Ultra 3 SCSI标准基于Ultra 2 SCSI标准的设计,沿用LVDS技术和40MHz总线,但引入了DDR双倍传输率设计,允许在1个时钟周期内进行2次数据传输,这样,其数据传输频率实际上达到了80MHz。Ultra 3 SCSI标准彻底抛弃了过时的8位总线,只提供16位总线,这样,它所提供的数据传输速率便达到了160MB/s。可非常遗憾的是,Ultra 3 SCSI标准的出台太过匆忙,导致其自身仍存在一些没有及时修正的技术缺陷,后果便是Ultra 3 SCSI设备与控制卡之间出现严重的不兼容现象,令其无法稳定工作在160MB/s的高速模式下,不得不以低速模式运行。后来,Adaptec公司(SCSI控制卡厂商)对Ultra 3 SCSI标准进行了必要的技术修订,并于1998年9月颁布了新的标准,也就是Ultra 160 SCSI标准。
Ultra 160 SCSI标准几乎继承了Ultra 3 SCSI标准的所有技术特性——使用LVDS信号、DDR双倍率总线,总线数据传输率为160MB/s。此外,它还具有域确认和循环冗余检测等功能。更重要的是,它彻底解决了Ultra 3 SCSI标准存在的兼容性问题,在推出之后便迅速获得各厂商的响应并成为事实上的新标准,应用范围也相当广泛。在那个年代,几乎所有的服务器和工作站都采用Ultra 160 SCSI存储系统,甚至今天还有不少Ultra 160 SCSI产品活跃在市场上,足见其生命力之顽强。
Ultra 320 SCSI是最后一代并行技术体系的SCSI标准,诞生于2001年。在基础技术上,Ultra 320 SCSI标准与Ultra 160 SCSI标准并没有本质上的区别,只是将总线的工作频率提高了1倍,达到80MHz,这样便拥有了高达320MB/s的数据传输率。除接口性能提升外,Ultra 320 SCSI标准还带来了SCSI封包、快速仲裁与选择等多项新特性,前者可以有效缩短命令过程的管理时间,后者则能将总线控制权的转交时间大大缩短,其目的都是为了提高SCSI系统的总线使用效率。
Ultra 320 SCSI同样最多可以连接15个外设。如果只连接单个设备,Ultra 320SCSI允许的线缆长度可达25米;但如果连接多个设备,线缆的长度就被限制在12米,这样才能保证数据传输的稳定性。虽然如此,Ultra 320 SCSI线缆的长度还是非常可观的,毕竟现实中不会有多少计算机需要使用超过12米的SCSI线缆。Ultra 320 SCSI标准推出之后,硬盘厂商态度甚为积极,IBM、日立、希捷、迈拓纷纷推出相关产品,Ultra 320 SCSI时代很快到来。Ultra 320 SCSI标准提供的宽裕的总线带宽也让服务器可以无障碍地挂接多个SCSI设备,因此在高端系统中,Ultra320SCSI迅速成为标准,而且这种情况一直延续到现在。
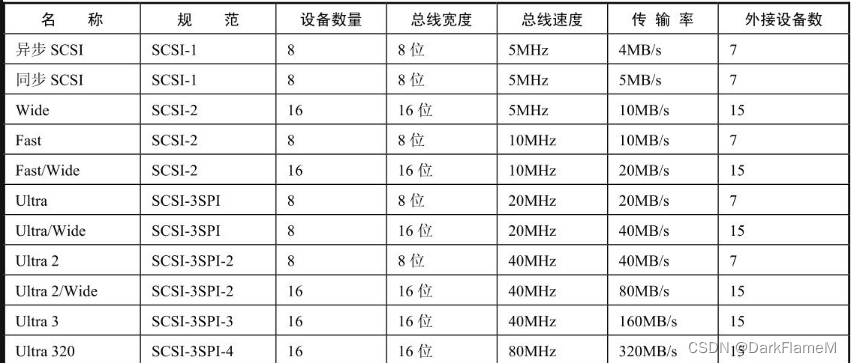
SCSI接口汇总如表1-15所示。
表1-15 SCSI接口汇总
通过抽象出SCSI体系结构模型(SAM), SCSI协议能够拥有各种实现形式,如并行SCSI、串行SCSI、iSCSI、光纤通道、IEEE 1394,如图1-32所示,其中的缩略语含义如下。
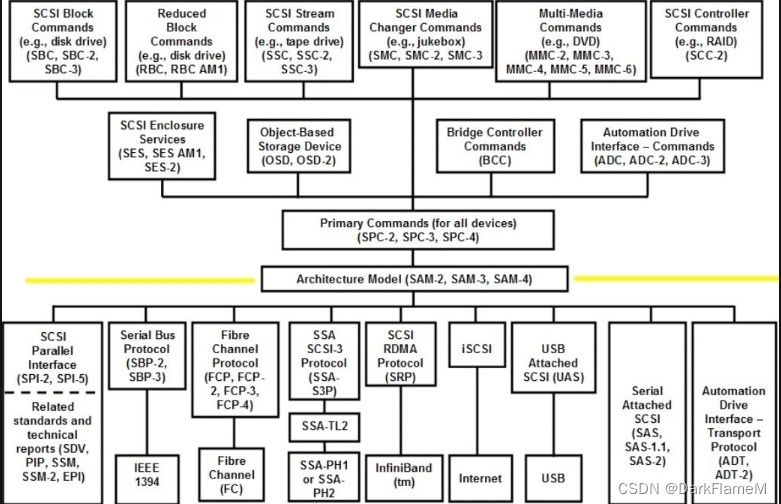
图1-32 SCSI标准体系
SBC:SCSI-3块命令集,第一代磁盘驱动器命令集。
SBC-2:SCSI块命令集-2,第二代磁盘驱动器命令集。
SBC-3:SCSI块命令集-3,第三代磁盘驱动器命令集。
RBC:精简块命令集,简化的磁盘驱动器命令集。
RBC_AM1:精简块命令集修订版本1, RBC的第一个修订版本。
SSC:SCSI-3流命令集,第一代磁带驱动器命令集。
SSC-2:SCSI流命令集-2,第二代磁带驱动器命令集。
SSC-3:SCSI流命令集-3,第三代磁带驱动器命令集。
SMC:SCSI-3介质更换命令集,第一代自动介质更换命令集。
SMC-2:SCSI介质更换命令集-2,第二代自动介质更换命令集。
SMC-3:SCSI介质更换命令集-3,第三代自动介质更换命令集。
MMC:多媒体命令集,第一代CD-ROM命令集。
MMC-2:多媒体命令集-2,第二代CD和DVD命令集。
MMC-3:多媒体命令集-3,第三代CD和DVD命令集。
MMC-4:多媒体命令集-4,第四代CD和DVD命令集。
MMC-5:多媒体命令集-5,第五代CD和DVD命令集。
MMC-6:多媒体命令集-6,第六代CD和DVD命令集。
SCC-2:SCSI控制器命令集,第二代RAID控制器命令集。
SES:SCSI-3管理命令集,用于管理的命令集,如风扇、电源等的管理。
SES_AM1:SCSI-3管理命令集修订版本1, SES的第一个修订版本。
SES-2:SCSI-3管理命令集-2,第二代管理命令集。
OSD:基于对象的存储设备,基于磁盘上的对象(如文件)导向的命令集。
OSD-2:基于对象的存储设备-2,第二代基于磁盘上的对象导向的命令集。
BCC:桥控制器命令集,描述了不同的SCSI协议,如SPI、FCP、SRP和iSCSI间的SCSI协议桥控制器设备的命令集。
ADC:自动控制设备与驱动器接口命令集。
ADC-2:自动控制设备与驱动器接口命令集-2,第二代自动控制设备与驱动器接口命令集。[插图] ADC-3:自动控制设备与驱动器接口命令集-3,第三代自动控制设备与驱动器接口命令集。[插图] SPC-2:SCSI主要命令集-2,适用于所有SCSI设备的第二代主要命令集。
SPC-3:适用于所有SCSI设备的第三代主要命令集。
SPC-4:适用于所有SCSI设备的第四代主要命令集。
SAM:第一代SCSI设备结构模型。
SAM-2:第二代SCSI设备结构模型。
SAM-3:第三代SCSI设备结构模型。
SAM-4:第四代SCSI设备结构模型。
SPI-2:第二代SCSI并行接口(Ultra 2)。
SPI-5:第五代SCSI并行接口(Ultra 640)。
SDV:SCSI域确认,是NCITS用于描述测试和确认SCSI物理层通信能力的技术报告。
PIP:描述测试和测量如线缆、底板等SCSI连接部件性能的标准。
SSM-2:模拟SCSI信号的条件与方法集。
EPI:如并行SCSI接口扩大器等增强的定义。
SBP-2:串行总线协议-2,第二代通过IEEE 1394进行SCSI传输的协议。
SBP-3:串行总线协议-3,第三代通过IEEE 1394进行SCSI传输的协议。
FCP:光纤通道协议,第一代通过光纤通道进行SCSI传输的协议。
FCP-2:光纤通道协议-2,第二代通过光纤通道进行SCSI传输的协议。
FCP-3:光纤通道协议-3,第三代通过光纤通道进行SCSI传输的协议。
FCP-4:光纤通道协议-4,第四代通过光纤通道进行SCSI传输的协议。
SSA-S3P:串行存储架构传输协议。
SSA-TL2:第二代串行存储架构传输层标准。
SSA-PH1:第一代串行存储架构物理层标准。
SSA-PH2:第二代串行存储架构物理层标准。
SRP:定义了一个功能类似于簇的将SCSI协议映射到InfiniBandTM架构的协议。
SAS:串行连接的协议和物理接口。
SAS-1.1:增强的串行连接的协议和物理接口-1.1。
SAS-2:增强的串行连接的协议和物理接口-2,速率高达6Gb/s。
ADT:自动控制器/驱动器接口-传输协议。
ADT-2:自动控制器/驱动器接口-传输协议-2。
UAS:USB连接SCSI协议。
SDI:SCSI驱动器接口。
SAT:第一代SCSI/ATA转换。
SAT-2:第二代SCSI/ATA转换。
无论是ATA体系还是SCSI体系,最终都将采用高速串行技术作为共同的目标,SATA和SAS(Serial Attached SCSI)总线由此诞生,而且两者基于共同的工作原理,在物理层完全兼容(同样的点对点串行总线、LVDS信号技术、7针L型盲插接口等)。只是在逻辑层面上,SATA仍属于传统的IDE体系,而SAS则使用SCSI命令集,其自身便可处理与数据读写相关的所有运算任务,同时也保持了对SATA设备的无缝兼容。也就是说,SATA设备可以在SAS系统中直接工作,改变了以前SCSI、ATA两大体系老死不相往来的局面。另外,SATA 1.0标准提供的接口速率是150MB/s,而SAS 1.0标准可提供300MB/s的高速率。虽然低于已有的Ultra 320SCSI标准(接口速率为320MB/s),但SAS 1.0总线为点对点设计,每个设备都独自占有整条SAS通道,实际性能非常可观。不仅如此,SAS总线还支持多端口绑定机制(如采用双端口、全双工协议), SAS 1.0系统的带宽峰值将提高至1.2Gb/s;而如果采用4端口技术,SAS 1.0系统的带宽峰值则将达到2.4Gb/s。在2009年春季于美国奥兰多开幕的SNW(存储网络世界)大会上,作为SAS技术倡导者的LSI公司展示了其6Gb/s传输速率的SAS技术。
1.10 S.M.A.R.T简介
SMART错误也会导致驱动器无法被识别。在维修驱动器的过程中要大量使用S.M.A.R.T信息,因此,这里再简要介绍一下S.M.A.R.T的相关知识。
1.10.1 S.M.A.R.T的起源
S.M.A.R.T技术就是自我监测、分析和报告技术(Self Monitoring Analysis and Reporting Technology)。S.M.A.R.T监测的对象包括磁头、磁盘、马达、电路等驱动器的主要部分,由驱动器的监测电路和监测软件对被监测对象的运行情况、历史记录及预设的安全值进行分析、比较,当出现安全值范围以外的情况时,会自动向用户发出警告。更先进的技术还可以提醒网络管理员有故障发生,自动降低驱动器的运行速度,把重要的数据文件转存到其他安全扇区中,甚至把文件备份到其他存储设备上。S.M.A.R.T技术可以对驱动器潜在故障进行有效预测,提高数据的安全性。
S.M.A.R.T技术的发展已经经历了3个版本。S.M.A.R.T Ⅰ仅能累计计算驱动器运行中出现的错误,当错误累计达到一定的次数时发出安全警告。S.M.A.R.T Ⅱ改进了错误预防系统,能够自动对驱动器进行系统操作指令之外的读扫描。这比S.M.A.R.T Ⅰ前进了一大步,平常磁头不读写的地方也能被检测和报告。S.M.A.R.T Ⅲ不但能自动对驱动器进行读扫描、累计错误出现的次数、达到一定次数后发出安全警告,还增加了ECC(Error-Correction Code)纠错功能,以便对磁盘工作中和自动读扫描中出现的错误进行ECC纠错。但即使是S.M.A.R.T Ⅲ,对磁盘的监测和对数据的保护也是有限的,因为S.M.A.R.T仅能对扇区进行读扫描,而不能对扇区状态进行写回测试,且无法修复ECC不能修正的错误。因此,仅仅依靠S.M.A.R.T技术是不够的。所以,在这个基础上,各厂商开发出了各具特色的驱动器保护性固件,比较出色的有西部数据的数据卫士,昆腾的DPS、SPS,迈拓的Maxsafe、ShockBlock,希捷的Seashield、DST,IBM的DFT等。它们分别在S.M.A.R.T的基础上进行了不同程度的扩展和延伸,使驱动器数据更加安全。
S.M.A.R.T实际上是存储在固件中的一套诊断程序,用于实现相应的诊断功能。主板BIOS只是在启动时检查驱动器上的S.M.A.R.T状态,用于设置启用还是禁用S.M.A.R.T,它本身并不参与诊断测试。
S.M.A.R.T技术最早由IBM和康柏(Compaq)提出,IBM的可靠性预报技术称为故障分析预报(Predictive Failure Analysis, PFA)。PFA通过测量包括磁头飞行高度在内的一系列属性值来预报故障,并通报主机将会发生的故障,这样,用户就可以采取必要的措施来保护数据。一段时间之后,康柏宣布在诊断设计上取得了突破,并将这种技术命名为“IntelliSafe”。后来,康柏又联合希捷、昆腾和Conner进一步发展了该技术。1995年5月,康柏向SFF(Small Form Factor)委员会提交了IntelliSafe的技术标准报告(SFF-8035i),1996年1月进行了1.0版的修正(SFF-8035R2),1996年6月进行了1.3版的修正(SFF-8055),并联合IBM等厂商向SFF正式申请将IntelliSafe技术加入ATA-3行业标准,正式将其更名为S.M.A.R.T。
1.10.2 S.M.A.R.T的规格
驱动器为了具备可靠性管理能力,必须监控多种因素。常见的驱动器故障可以分为两大类,分别是不可预测故障和可预测故障。
不可预测故障通常指不可预料的电子和机械故障。这类故障发生在瞬间,例如驱动器加电状态下的意外碰撞导致的驱动器磁头撞击盘片,或者瞬间电流过大引起的芯片或电路故障等。通常,在S.M.A.R.T反映性能下降之前,驱动器就已经不能工作了。S.M.A.R.T只能通过质量、设计、工艺、制造等方面的改进以及规范使用过程中的操作来降低故障的发生率,例如驱动器防震技术的开发成果有效降低了驱动器震动物理故障发生的概率。
可预测故障具有在驱动器完全不能工作前其相应的参数会随时间发生变化的特点。根据这一特点,可以对这些实时信息进行检测,通过监控其属性来进行故障预测、分析,并根据分析结果提出建议,从而加以防范。此类故障包括软件故障和硬件故障。例如,许多机械故障都被看做是典型的可预测故障,而S.M.A.R.T技术对此类故障大有用武之地——在发生故障前发出提醒用户备份数据的通知,以保护用户数据。
研究数据表明,在S.M.A.R.T技术可以预测的硬盘故障中,60%左右为机械性质,40%左右是软性故障。随着S.M.A.R.T及相关技术的逐步成熟,可预测故障的种类将越来越多,对故障的防范措施也会变得越来越有效。
S.M.A.R.T有两份规范,分别对应于ATA标准和SCSI标准。两种环境下的S.M.A.R.T技术基本相似,只是在一些参数设定上存在差异,最终报告的信息也不一样。在ATA/IDE环境下,由主机上的软件对由S.M.A.R.T的“报告状态”命令生成的、来自硬盘的报警信号进行解读。主机对驱动器进行查询,检查这一命令的状态,如果显示马上要发生故障,就将告警信号送至最终用户或系统管理员处。系统管理员安排关机时间,以备份数据和更换驱动器。主机系统除了可以对来自驱动器的“报告状态”命令进行评估外,还可以对属性和告警报告进行评估。对这种结构还可以进行改进,以使其适用于其他应用,例如进行CD-ROM、TAPE和其他I/O设备的热故障预报等。
在SCSI环境下,失效与否的判定权在驱动器,主机只负责将信息通报给用户。S.M.A.R.T只报告“状况完好”或“出现故障”,然后由驱动器进行故障判断,再由主机通知用户采取措施。在SCSI标准中有一个检测位,当确定驱动器的可靠性出现问题时,检测位就会被打上标记并通知最终用户或系统管理员,以采取相应的措施。
通常来说,SCSI驱动器内部有更强的可靠性预报能力,在关键参数上,SCSI驱动器比ATA驱动器更为复杂。S.M.A.R.T对ATA/IDE系统的干预比对SCSI系统的干预要多,而对SCSI故障的判定更为专业和准确。例如,以下的SCSI驱动器参数就是ATA/IDE驱动器不具备的,而它们只是SCSI驱动器特有参数的一小部分。
Primary Temp:驱动器盘体工作温度。
Secondary Temp:PCB板周围工作温度。
Min and Max Temp:一段时间内驱动器盘体的最高和最低工作温度。
Velocity Observer Count:一段时间内伺服寻道时偏离指定磁道的次数。
12V:+12V供电电压值。
5V:+5V供电电压值。
Sectors Read:一段时间内从驱动器读取的扇区数。
Sectors Written:一段时间内数据写入驱动器的扇区数。
作为行业标准,S.M.A.R.T规定了驱动器制造厂商应遵循的标准。S.M.A.R.T标准的条件主要包括:设备制造期间完成S.M.A.R.T需要的各项参数、属性的设定;在特定系统平台上能够正常使用S.M.A.R.T;通过BIOS检测,能够识别设备是否支持S.M.A.R.T并可显示相关信息,并辨别有效和失效的S.M.A.R.T信息;允许用户自由开启和关闭S.M.A.R.T功能;在用户使用过程中提供S.M.A.R.T的各项有效信息,确定设备的工作状态,发出相应的修正指令或警告。在驱动器和操作系统都支持S.M.A.R.T技术并且该技术默认开启的情况下,当有不良状态出现时,屏幕上将显示英文警告信息“WARNING: IMMEDIATLY BACKUP YOUR DATA AND REPLACE YOUR HARD DISK DRIVE, A FAILURE MAY BE IMMINENT”(警告:立刻备份你的数据同时更换驱动器,可能有错误出现)。
S.M.A.R.T信息存储在驱动器的系统保留区内,这个区域一般位于驱动器0物理柱面的前几十个物理磁道,相关内部管理程序由厂商写入。除S.M.A.R.T信息,系统保留区中还有低级格式化程序、加密/解密程序、自监控程序、自动修复程序等。监测软件通过“SMART RETURN STATUS”命令(命令代码为B0h)对S.M.A.R.T信息进行读取,且不允许最终用户对信息进行修改。
S.M.A.R.T标准采用二进制代码作为基本指令,并规定将代码写入标准的寄存器中,形成特定的S.M.A.R.T信息表,供正常检测和运行时使用。S.M.A.R.T指令分为主指令(Command)和次指令(Sub Command)。主指令主要提供设备是否支持S.M.A.R.T或忽略某一次指令特征的信息,而次指令则提供支持S.M.A.R.T设备的检测信息。这些指令主要由设备制造厂商写入,一些专业驱动器维修软件可以通过这些代码对设备进行检测。
S.M.A.R.T技术的原理是通过侦测驱动器的各项属性,如数据吞吐性能、马达启动时间、寻道错误率等,对属性值和标准值进行比较、分析,以推断驱动器的故障情况,并给出提示信息,从而帮助用户避免数据损失。S.M.A.R.T因此规定了专门的检测参数。由于驱动器结构、性能和定位上的不同,除ATA-3标准规定的参数外,厂商可以根据自己产品的特性提供不同的S.M.A.R.T检测参数。普通用户可使用常用的系统工具来查看这些参数,并通过这些参数了解驱动器的“健康”状况。
1.10.3 S.M.A.R.T属性
S.M.A.R.T属性是指被监控的磁盘的一些特性。每一个S.M.A.R.T属性都有一套参数,包括属性值、阀值、最大出错值和实际值。每个属性都有自己特定的阀值,一旦某个属性值降到阀值以内,S.M.A.R.T就认为磁盘有故障。
S.M.A.R.T通过ID检测代码向主机报告故障的发生。不过,ID检测代码不是唯一的,厂商可以根据需要使用不同的ID代码,或者根据检测参数的多少增减ID代码的数量。例如,西部数据公司产品的ID检测代码“04”的含义是“Start/Stop Count”(加电次数),而富士通公司同样代码的检测参数却为“Number of times the spindle motor is activated”(电机激活次数)。与ID对应的是属性描述(Attribute Description),即检测项目的名称,同样可由厂商自行定义。由于ATA标准的不断更新,有时即使是同一品牌的不同型号的产品,其属性描述也会有所不同。但是,硬盘厂商必须确保S.M.A.R.T规定的几个主要检测项目是一致的(虽然不同厂商对检测项目都有特定的命名规则,但这些监测项目的实质是一样的),具体如下。
Read Error Rate:错误读取率。
Start/Stop Count:启动/停止次数,又称加电次数。
Relocated Sector Count:重定位扇区数。
Spin Up Retry Count:电机重试次数,即主轴马达启动没有达到规定转速时的启动重试次数。
Drive Calibration Retry Count:驱动器校准重试次数。
Ultra DMA CRC Error Rate:Ultra DMA奇偶校验错误率。
Multi-Zone Error Rate:多区域错误率。
Vendor-Specific:厂商特性。
常用S.M.A.R.T属性如表1-16所示(由于资料来源不同,对不同厂商生产的驱动器,有些ID的描述会有所不同)。
表1-16 S.M.A.R.T属性表

对于这些检测项目,需要给定阈值(Threshold,也称门限值)。如果有一个属性值低于相应的阈值,就意味着驱动器变得不可靠,保存在驱动器里的数据也很容易丢失。可靠属性值的组成和大小对不同的驱动器来说是有差异的。在这里需要注意的是,ATA标准中只规定了一些S.M.A.R.T参数,而没有规定具体的数值,而阈值是厂商根据自己产品的特性确定的,因此,使用厂商提供的检测软件得到的检测结果往往会与使用Windows下的检测软件得到的检测结果有较大出入,推荐以厂商提供的检测软件得到的检测结果为准。
驱动器记录S.M.A.R.T信息有两种方式。第一种是在线(On-Line)收集方式。所谓在线收集,就是指驱动器根据在实际工作状态下收集到的信息实时或在指定时间段内更新自身的S.M.A.R.T数据。举例来说,如果在向一个ATA驱动器扇区写入数据时遇到一个不可修正的错误,驱动器会及时把这个信息更新到S.M.A.R.T数据中。对于SCSI驱动器,如果设定的S.M.A.R.T更新周期是4分钟,则会把4分钟内收集到的相关S.M.A.R.T信息更新到S.M.A.R.T数据区,然后再开始下一个周期的跟踪。在线收集状态对系统性能没有影响。第二种方式是离线(Off-Line)收集。离线收集是驱动器收到主机发来的一些特定指令时进行的自检测试,此时驱动器处于“idel”(停止)状态或错误修正状态。在这种情况下,驱动器自身将作出大量动作以测试“健康”状态,但这会导致驱动器对主机发出的正常要求产生反应延迟。所以,离线收集状态会造成系统性能的下降。
对SCSI驱动器而言,记录S.M.A.R.T信息是有周期性的,一般情况下周期在4~120分钟之间。这个值在驱动器出厂时就已设定,并且只能通过专业软件修改。而对于ATA驱动器,S.M.A.R.T信息的记录没有周期性。
有些厂商生产的驱动器的S.M.A.R.T参数中有“Fly Height”(磁头飞行高度)这一项。不过,准确地说,驱动器的磁头飞行高度是无法侦测的,因为驱动器中没有任何装置可以测量磁头的飞行高度。虽然驱动器生产厂商可以根据磁头读取到的磁信号的强度来推测磁头的飞行高度,但这样推测出来的磁头飞行高度很多时候与实际情况相比有较大偏差,所以只能作为参考。
1.10.4 S.M.A.R.T的应用
这里以希捷驱动器S.M.A.R.T检测参数为例进行介绍。检测参数分为8列,分别是ID检测代码、属性描述、原始值、属性状态、属性值、最大错误值、阈值和预测失效时间(Threshold Exceed Condition, TEC),如图1-33所示。
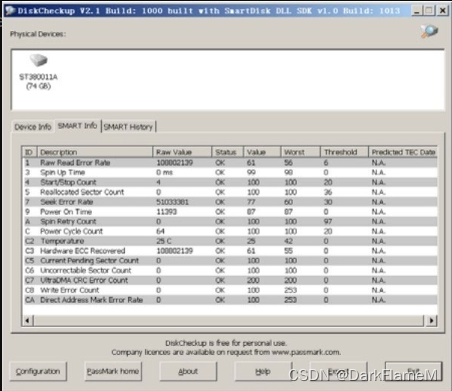
图1-33 通过DiskCheckup查看S.M.A.R.T信息
以参数“Raw Error Rate”为例:该参数的计算公式为10×log10(主机和驱动器之间传输数据的扇区数)×512×8/重读的扇区数。其中,“×512×8”是把扇区数转化为所传输的数据位(bits),这个值只在传输的数据位处于1010~1012时才进行计算,当其大于或等于1012时,此值将复位。在Windows操作系统启动后,主机和驱动器之间传输的数据扇区往往很大,从而触发重新计算,这就是为什么有些值在不同的操作环境和检测程序下波动较大的原因。
属性值(Attribute Value)是指驱动器出厂时预设的最大正常值,一般范围为1~253。通常最大的属性值等于100(适用于IBM、昆腾、富士通驱动器)或253(适用于三星驱动器)。当然也有例外,例如西部数据部分型号的驱动器就使用了两个不同的属性值,最初生产的驱动器属性值设置为200,但后来生产的驱动器属性值又改为100。
最大出错值(Worst)是驱动器运行过程中曾出现过的最大的非正常值,它是对驱动器累计运行的计算值。根据运行周期,该数值会不断被刷新,并且会非常接近阈值。S.M.A.R.T分析和判定驱动器的状态是否正常的依据就是这个数值和阈值的比较结果。新驱动器开始使用时有最大的属性值,随着日常使用或出现错误,该值会不断减小。因此,较大的属性值意味着驱动器质量较好、可靠性较高,而较小的属性值意味着故障发生的可能性增大。
原始值(Raw Value)指驱动器各检测项目运行中的实际数值,很多项目是累计值。
属性状态(Status)指S.M.A.R.T针对前面的各项属性值进行比较和分析后提供的驱动器各属性的目前状态,也是直观判断驱动器“健康”状况的重要信息。根据S.M.A.R.T的规定,这种状态一般分为正常、警告和报告故障或错误3种。S.M.A.R.T对这3种状态的判定与S.M.A.R.T的“Pre failure/advisory BIT”(预知错误/发现位)参数的赋值密切相关。
由于每一个参数所给出的值都是经过一些特定的公式计算得出的,因此作为用户,只要观察“Worst”和“Threshold”值的关系,并注意状态信息,即可大致了解驱动器的健康状况。使用S.M.A.R.T. Vision查看驱动器的显示结果如图1-34所示。
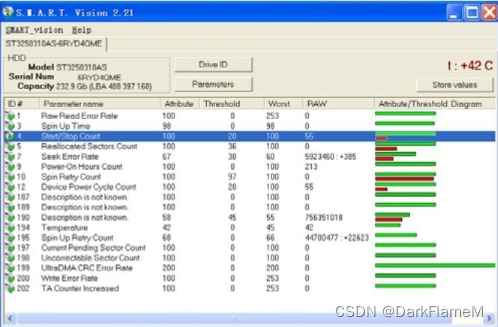
图1-34 S.M.A.R.T. Vision
单击“Drive ID”按钮,可以看到如下内容。
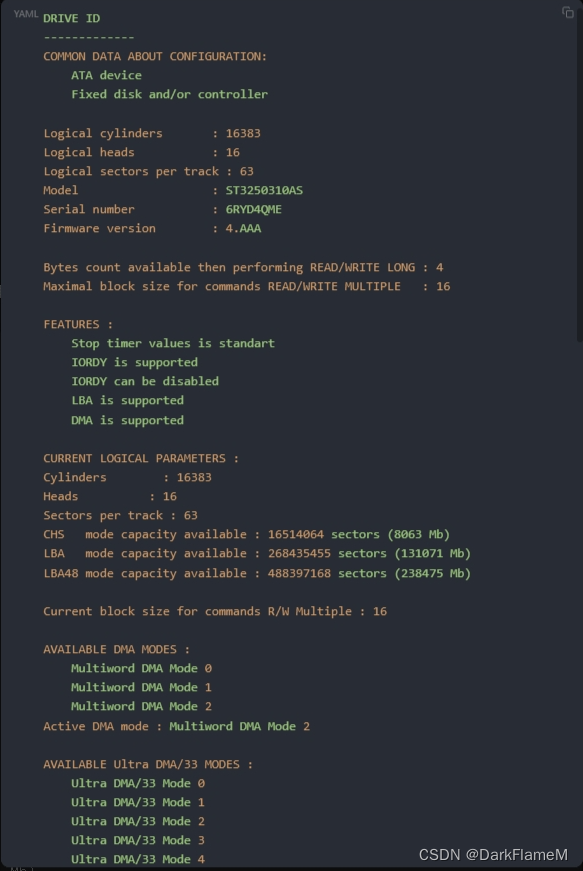
1.11 基本工具使用简介
工欲善其事,必先利其器。与做任何事情一样,硬盘维修也需要专业的工具。这些工具,除了硬件形态的仪表、烙铁、各种改锥外,还包括能够检测硬盘、对硬盘固件进行操作的专业工具软件,如HRT、PC3000、效率源等。在介绍专业工具之前,本章先介绍一些检测与维修硬盘的基本工具。这些基本工具提供了一些常用功能,虽然不能与专业工具相媲美,但它们简单、实用,因此特别适合入门使用。这些工具包括各硬盘厂商提供的专用检测维修工具,如DM、DFT、DDD-SI等,也包括其他工具,如MHDD、THDD、HDDL、HP(HDD SPEED)、HDDREG、ADM等。
1.11.1 MHDD使用简介
MHDD是俄罗斯Maysoft公司出品的硬盘检测和维修工具,虽然操作简单,但却具有很多其他硬盘工具软件所无法比拟的强大功能,分为免费版和收费完整版,这里介绍的是免费版的用法。
MHDD无论是以CHS模式还是以LBA模式,都可以访问超过137GB的超大容量硬盘(可访问的扇区范围为512~137 438 953 472)。它不依赖主板BIOS直接访问IDE接口,但与个别原装Intel主板有兼容性问题。因为无须BIOS支持,也无须任何中断支持,所以即使使用的是286处理器,也一样可以处理新式大容量硬盘。
MHDD虽然在一定条件下也可以在Windows环境中运行,但最好是在纯DOS环境下运行。同时,为了安全,也不要在要检测的硬盘中运行MHDD。目前,MHDD只对主盘进行操作,所以一般是在第一主硬盘上运行MHDD(端口1),并对IDE2上的主盘进行操作(端口3)。MHDD还可以对接在PC-3000测试卡上的硬盘进行操作,由端口5表示。由于MHDD在运行时需要记录数据,因此它不能在处于写保护状态的存储设备中运行,例如写保护的软盘、光盘等,但可以在没有处于写保护状态的软盘上运行。对主盘的选择,可使用PORT命令来进行。由于我们常常需要在第一个IDE接口的主硬盘中运行MHDD,所以在配置文件mhdd.cfg中,一般要禁止对第一个IDE接口进行操作。
mhdd.cfg文件的内容如图1-35所示,其中的第一项就是禁止对第一IDE通道上的硬盘进行操作,其他行的意思很明显,很多都是根据参数自动生成的,不需要解释,一般也不需要进行修改。
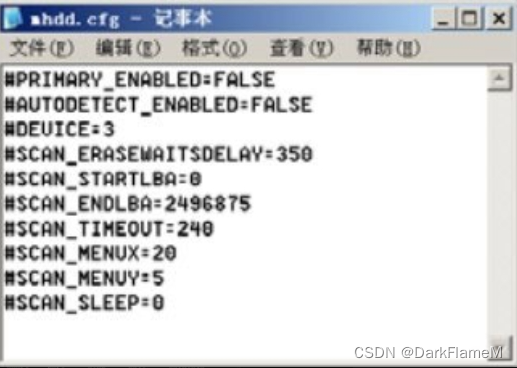
图1-35 mhdd.cfg文件内容示例
在DOS下启动MHDD 2.9,其界面如图1-36所示。
图1-36 MHDD 2.9
屏幕第一行的左半部分为状态寄存器,右半部分为错误寄存器。在屏幕第一行的中间,即“BUSY”和“AMNF”之间,有一段空白区域,如果硬盘设置了密码,此处会显示“PWD”,如果硬盘用HPA做了剪切,此处会显示“HPA”。寄存器中各项的含义如下。
ERR:上一步的操作结果有错误,具体错误可根据错误寄存器的代码来识别。
INDX:索引。
CORR:已纠正ECC错误。
DREQ:硬盘需要和主机交换数据。
DRSC:硬盘初检通过。
WRFT:写入失败。
DRDY:硬盘准备就绪。
BUSY:硬盘忙且对指令不反应。当“ERR”指示闪烁时,屏幕的右上角将显示错误的位置,其含义如下。
AMNF:地址标志出错。
T0NF:0磁道没找到。
ABRT:指令被中止。
IDNF:找不到扇区ID。
UNCR:不可纠正的错误。
BBK:块错误。
这些指示与PC3000中相应指示的意义基本上是一致的。
EXIT(快捷键为【Alt】+【X】):退出,返回DOS环境。[插图]
ID:硬盘检测,包括硬盘容量、磁头数、扇区数、序列号、固件版本号、LBA值、支持的DMA级别、是否支持HPA、是否支持AAM、S.M.A.R.T开关状态、安全模式级别、开关状态等。执行ID命令后的效果如图1-37所示。检测到硬盘后,屏幕第二行的左边会显示CHS和LBA参数,右边会显示当前的LBA和柱面值。
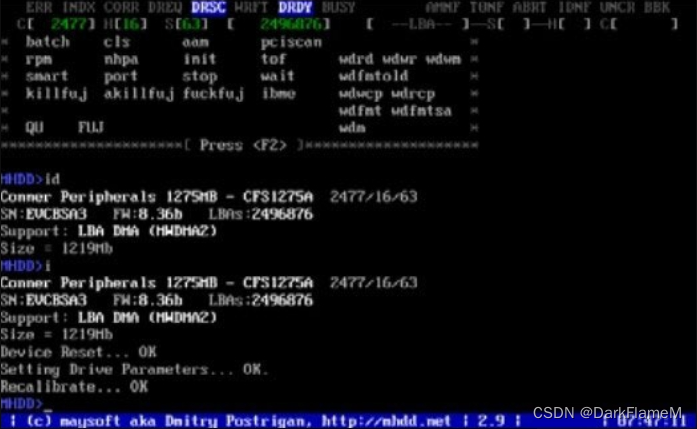
图1-37 ID命令
HPA:硬盘容量剪切功能,可用于减少硬盘的容量,使BIOS检测到的硬盘容量变小。但DM之类的独立于BIOS检测硬盘容量的软件仍会显示出硬盘的原始容量。
PWD:给硬盘添加USER密码,最多32位,不输入任何内容表示取消,被锁的硬盘将完全无法读写,一切读写操作都将无效。如果密码设置成功,按【F2】键后可以看到“Security”项后面有红色的“ON”标记。需要注意的是,设置完密码后必须关闭硬盘电源再打开,才能使密码起作用。 FDISK:快速地将硬盘分为1个分区,并设为激活。但要使用分区,还需用FORMAT命令进行格式化。
RX:接收缓冲器数据。
SCAN(快捷键为【F4】):盘面扫描,可以用特定模式修复坏扇区,选项如图1-38所示。
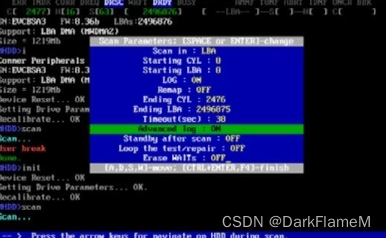
图1-38 SCAN命令选项
Scan in(CHS/LBA):以CHS或LBA模式扫描。CHS模式只对容量为500MB以下的老式硬盘有效。
Starting CYL:设定开始扫描的柱面。
Starting LBA:设定开始扫描的LBA值。
Log(On/Off):设定是否写入日志文件。
Remap(On/Off,坏扇区重映射):设定是否修复坏扇区。采用重映射的方式隐藏坏扇区,数据不会偏移。但由于MHDD默认当扇区访问时间大于500ms时会自动将其标为坏扇区并采用重映射的方式隐藏该坏扇区,所以该扇区的数据将会丢失。如果该扇区的数据是关键位置的数据,后果就会很严重。而使用MTL、COPYR、PC3000等软件时,扇区访问时间小于15 000ms的扇区上的数据都可以成功读取。所以,在进行数据恢复时,最好不要打开本项(默认为“Off ”)。
Ending CYL:设定终止扫描的柱面。
Ending LBA:设定终止扫描的LBA值。
Timeout (sec):设定超时值,1~200,默认值为30。
Advanced log(高级LBA日志):打开此项,在开始扫描前输入记录文件。
Standby after scan:设定扫描结束后是否关闭硬盘马达。这样可在SCAN扫描结束后自动关闭硬盘电源,但不自动关闭主机。✧
Loop the test/repair:循环检测和修复,主要用于反复修复顽固型坏道,需要人工停止检测或修复过程。✧
Erase WAITs(删除等待):此项主要用于修复坏道,而且修复效果要比REMAP方式更理想,尤其对IBM硬盘的坏道最为奏效。但此修复方式将破坏硬盘上的数据,导致数据不可恢复。此修复方式每次处理255个扇区,默认时间为250ms,可设置范围为10~10 000。要修改默认时间,只要打开“/CFG”目录下的mhdd.cfg文件,修改相应项目即可。此值主要用来设定MHDD确定坏道的读取时间(即读取某区块时如果读取时间达到或超过该值,就认为该块为坏块,并开始尝试修复)。一般情况下,不必更改此数值,否则会影响坏道的界定和修复效果。选择“Advanced log”选项,并给定日志名为“alog”,扫描过程如图1-39所示。
选择“Advanced log”选项,并给定日志名为“alog”,扫描过程如图1-39所示。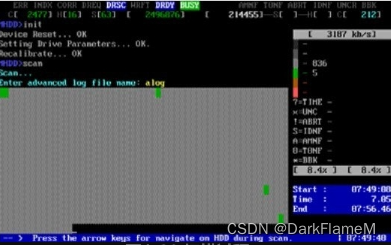
图1-39 扫描过程
在扫描时使用箭头键可以灵活地控制扫描进程,这很像使用VCD播放机:【↑】键表示前进2%;【↓】键表示后退2%;【←】键表示后退0.1%;【→】键表示前进0.1%。灵活运用箭头键,可以对不稳定的及坏道顽固的区段进行反复扫描和修复。在扫描时,每个方块代表255个扇区(在LBA模式下)或63个扇区(在CHS模式下)。在扫描过程中,可随时按【Esc】键终止。在扫描过程中,不同的颜色可以表示不同的访问速度,并在扫描结束后给出不同速度下的统计数值,如果有坏道和不稳定的扇区,也会给出其LBA地址。方块从上到下依次表示从正常到异常、读写速度由快到慢。在正常情况下,应该只出现第一个和第二个灰色方块。如果出现浅灰色方块(第三个方块),代表该处读取耗时较长;如果出现绿色和褐色方块(第四个和第五个方块),代表此处读取异常,但未产生坏道;如果出现红色方块(第六个方块,即最后一个方块),代表此处读取吃力,马上就要产生坏道;如果出现问号(?),表示此处读取错误,有严重物理坏道,无法修复。老式硬盘(3GB以下)由于性能较低、速度较慢,因此在扫描时很少出现第一个方块,而是出现第二个和第三个方块,甚至会出现第四个方块(绿色方块),这种情况是由老式硬盘读写速度低引起的,并不说明那些扇区读写异常,如图1-40所示。
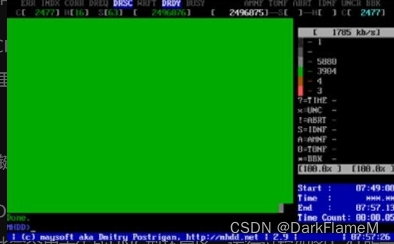
图1-40 扫描结束
FUJLST:查看富士通硬盘缺陷表(P-List)。此时要记录大量数据,缺陷表越大,生成的文件(在“FUJLST”目录下)也就越大。如果是在软盘上运行MHDD,有可能出现空间不足的情况。
UNLOCK:对硬盘解锁。先选择“0”(USER),再正确输入密码。注意,在这里选择“1”(Master)将无法解开密码,密码错误当然也无法解锁。
I(快捷键为【F2】):相当于同时执行ID命令和INIT命令。
RANDOMBAD:随机在硬盘的各个地方生成坏扇区,按【Esc】键可以停止生成。此命令用于生成UNC型坏扇区,运行过程如图1-41所示。
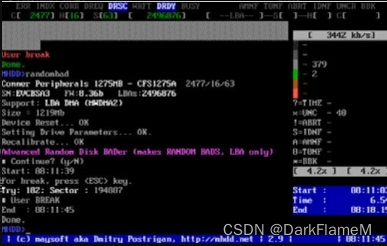
第2篇 PC3000 ISA版本的操作
本篇包括第2章至第7章,介绍PC3000 ISA版本的使用及一些基础知识。PC3000 ISA版本虽然已经不再使用,但操作中所蕴含的理论知识却是后续学习的基础。
第2章 使用PC3000 ISA版本前的准备工作
2.1 PC3000 ISA版本的安装
数据恢复和硬盘修理界最知名的工具莫过于PC3000,它是由俄罗斯ACE实验室经过十几年的不断研究,成功破解了市面上大部分硬盘DSP芯片的内部指令集和内部固件调用命令,解读各种硬盘固件后开发出来的专业硬盘维修工具套件。PC3000通过解读内部指令,实现了硬盘内部参数模块读写和硬盘程序模块调用,从而实现了修改硬盘工作参数、调用缓冲数据、刷写外部ROM程序、修复缺陷扇区、重写伺服信息、调用内部自检程序对硬盘进行自检修复以及屏蔽区域和磁头等功能,最终达到以软件修复多种硬盘缺陷的目的。其最专业的功能有:重写硬盘内部几乎所有参数,按工厂方式扫描硬盘内部缺陷并将其记录在硬盘内部相应的参数模块中,按工厂方式进行内部低级格式化等。概括起来,PC3000的主要功能如下。
内部低级格式化。
重写硬盘内部微代码集。
改写硬盘参数标识。
检查缺陷扇区或缺陷磁道,并用重置、替换或跳过忽略缺陷的方式修复。
重新调整内部参数。
逻辑切断(即禁止使用)有缺陷的磁头。
S.M.A.R.T参数复位。
在缺陷情况下通过DE获取用户数据。
PC3000产品套件通常由一套软/硬件设备共同组成,如UDMA版本包括以下部分。
加密狗Protection Key 1块(安装在PC-3000 UDMA卡上)。
PC-3000 UDMA控制卡1块。
PC3K PWR2电源控制接口1块。
PC-USB-TERMINAL接口1块。
PC-2接口(适用于1.8英寸和2.5英寸硬盘)1块。
PC-CF接口(适用于1.0英寸的HDD CF卡)1块。
PC PATA-SATA接口1块。
PC-SEAGATE接口1块。
PC-SEAGATE.SATA接口1块。
PC-QUANTUM接口1块。
PC-MX-SAFE接口1块。
IDE数据线(80针)2根(80cm、34cm各1根)。
HDD-10 PIN线缆1根。
HDD电源线。
PC-MX-SAFE电源线。
USB连接线。
ATMR、HTS548、HTS726探针。
AVV2、VLAT探针。
PC-3000 for Windows UDMA安装软件光盘1张。
英文说明书1本。
PC3000测试软件由通用程序和专用程序组成。通用程序可以快速对硬盘进行诊断,给修复硬盘提供有效的信息,支持3.5英寸、2.5英寸、1.8英寸的串口或PATA硬盘及1.0闪存接口硬盘。专业程序提供在工厂模式下诊断和修复硬盘的功能,该模式不能通用,因为它对每一个系列的硬盘都是唯一的。这就是PC3000要为每个系列的硬盘准备单独的工厂模式程序的原因。专业程序提供更深层次的驱动器故障检测和修复功能。另外,在很多时候,即使硬盘不能被修复,通过DE也可以获取用户数据。所有对硬盘的操作都能通过测试卡来实现,所有切换至工厂模式的专业接口和适配器也均包含在此套装中。这个套装中同样包含工厂硬盘资源的数据库,如硬盘ROM内容、服务区模块和磁道等。所有的资源都根据系列、型号和固件版本来分组。用户可以在数据库中搜索特定资源,也可从最新型号的硬盘中增加新的对象。至于PC3000的发展历史及对硬盘型号的支持情况,可以在其官方网站上方便地查到。
PC3000的PCI版本与UDMA版本的对比见表2-1和表2-2。
表2-1 PC3000的PCI版本与UDMA版本的硬件对比
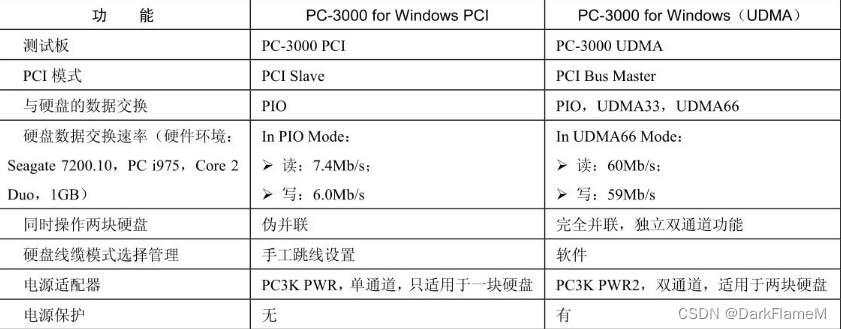
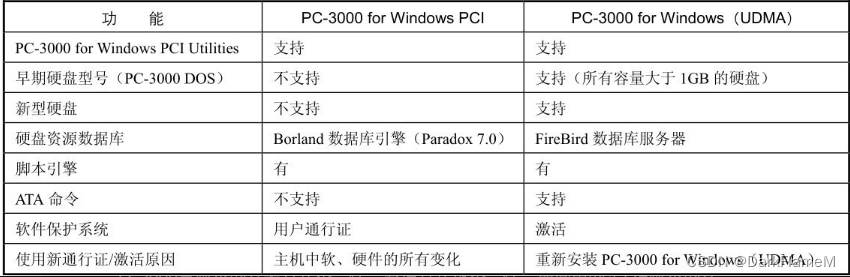
表2-2 PC3000的PCI版本与UDMA版本的软件对比
至于PC3000各版本之间的关系,简单地说,PCI版本不完全兼容ISA版本,而UDMA版本则完全兼容ISA版本和PCI版本(ACE也不再对前两个版本进行技术更新)。
PC3000各版本的安装方式不一样,激活方式也不一样,最简单的是ISA版本的安装,以ISA v10.10为例,其发行套件如图2-1所示。

图2-1 PC3000工具套装
PC3000的硬件部分以专用于控制硬盘的测试卡为主,如图2-2所示为一块ISA版本接口的PC3000测试卡;软件部分分为俄文版本和英文版本,其中包括若干个针对不同品牌、不同系列的硬盘而开发的程序模块。

图2-2 ISA版本的PC-3000测试卡
PC3000的安装分为硬件安装和软件安装。由于ISA版本的PC3000运行在DOS操作系统下,因此一般都是在主IDE接口上安装工作用盘,并在这个盘上安装DOS操作系统。启动盘一般使用Windows 98的启动盘,命令为“format c:/s”,也就是说,使用Windows 98的3个系统文件就可以了。然后,将PC3000光盘中的所有文件复制到启动硬盘的C盘根目录下,包括子目录、config.sys文件和autoexec.bat文件。因为要用到俄文的EMM386.EXE文件,而PC3000运行时会记录一些信息,所以还需要去掉相关文件的“只读”属性。
当然,我们也可以先安装Windows 98操作系统,然后将PC3000文件复制到其中(因为DE运行在Windows 98下)。我们可以修改MSDOS.SYS文件,让计算机启动后直接进入DOS环境,也可以在启动时按【F8】键进行选择。
PC3000对宿主计算机的要求并不高:带有EGA/VGA/SVGA显示器的386/486/Pentium计算机均可使用PC3000;操作系统为MS-DOS 5.00或更高;软件运行时要求至少有600KB的自由RAM,因此要用到俄文的EMM386.EXE应用程序,并将DOS移至高端内存;光盘中的CONFIG.SYS文件和AUTOEXEC.BAT文件已经配置好。PC-3000AT测试卡工作时使用IRQ12和100h~10Fh的I/O地址。由于有些工具使用了重载模式,因此推荐运行SMARTDRV.EXE应用程序。
PC3000的主要安装步骤如下。
第1步 将PC-3000AT测试卡插入控制计算机的空闲ISA插槽内。
第2步 将电子狗连接到LPT1。
第3步 在控制计算机的硬盘上创建PC3000的子目录,将光盘中“/PC-3000.xxx”目录下的所有文件复制到该目录下,“xxx”代表电子狗号。
第4步 去除所复制文件的“只读”属性。
第5步 连接电源线与数据线。
第6步 加载SHELL.EXE应用程序,集成工作环境准备完成。如果测试卡没有插入ISA插槽,或者测试卡不工作,加载SHELL.EXE应用程序和技术工具时会导致死机,此时可以通过RESET命令重启计算机。如果没有连接电子狗,或电子狗不工作,套件将不会工作。
数据线接在测试卡的正面,红线对准“1”,接在HDD PORT0和HDD PORT1上均可,待修硬盘接在从测试卡上引出的数据线上。电源线可以直接使用主机电源线,而更简单的方法是使用电源控制模块。电源控制模块如图2-3所示。

图2-3 电源控制模块
电源控制模块可以安装在测试卡上,测试卡已经为电源控制模块预留了安装孔。安装了电源控制模块的测试卡如图2-4所示。

图2-4 安装了电源控制模块的测试卡
电源控制模块和PC3000测试卡的连接关系如图2-5所示,模块底部那个10针的接口就插在测试卡上,通过它可以实现电源控制模块和PC3000测试卡的通信。

图2-5 电源控制模块和PC-3000测试卡的连接关系
电源控制模块可以在PC3000软件环境下实现对待修硬盘的电路开关转换控制,这在硬盘修复、数据恢复、安全拆卸等方面都非常有用。除此之外,还有一些非常好的应用技巧。例如,修理32049H2系列硬盘时,如果加载完LDR引导文件后硬盘不能进入标准模式,或者出现超时提示,或者出错,我们就可以借助电源控制模块对硬盘进行开/断电操作。这样做常常能收到意想不到的效果。
电源控制模块上安装了2个高耐压值电解电容、2个稳压管、1个集成电路;+5V和+12V电源指示灯各1个;两侧各有1个电源接口,左侧是由主机电源供电的输入口(POWER IN),右侧是电源输出口(POWER OUT),用以与待修硬盘进行连接。系统启动后,待修硬盘不会通电,在运行PC3000的外壳程序PC-3000 Shell以后,按【F11】键,电源就会给待修硬盘供电,按【F12】键则将关闭电源。
PC3000 PCI版本的安装按照产品手册的说明进行即可。但是,硬件变化会导致需要重新授权,而PC3000对授权的次数有限制,还可能与网卡发生冲突。国内的PCI版本较多,主要的有正版、810复制版和845复制版。安装UDMA版本时,可按照产品手册通过3种方式生成注册申请,得到注册文件后即可完成最终的安装。
2.2 PC3000 ISA工具软件的组成
PC3000的ISA版本,以v10.10为例,用于诊断和修复所有厂商的所有IDE接口(ATA、ATA-2、ATA-3、ATA-4、UltraATA、E-IDE、UDMA66)的驱动器(v10.10完成于2001年,这里指当时的IDE硬盘),以及在专用技术工具的支持下以高级工厂模式修复Conner、Daeyoung、Fujitsu、HITACHI、IBM、Kalok、Maxtor、NEC、Quantum、Samsung、Seagate、Teac、Western Digital、Xebec等厂商生产的硬盘。

