- 1ScheduledExecutorService执行周期性或定时任务_scheduledexecutorservice实现每个周日执行
- 2深度学习从零开始_安装d21
- 3嵌入式系统Boot Loader启动全过程详解_boot to edload
- 4Docker常用命令(三)
- 5linux把文件从光驱复制到,Linux_在Windows上制作CentOS自动安装的光盘的教程,1 复制光盘文件 1)挂载iso镜 - phpStudy...
- 6探索 Java 8 中的 Stream 流:构建流的多种方式
- 7openfeign实现远程调用_openfeign远程调用
- 8stata回归?固定效应模型(组内变换OR LSDV最小二乘法)_stata固定效应回归命令
- 9U-Net图像语义分割实战:训练自己的数据集_使用u-net分割自己的数据集
- 10PyQt5保姆级入门教程——从安装到使用_pyqt5安装教程
94%预测准确率!手把手搭建CNN-AlexNet卷积神经网络框架_alexnet模型评估
赞
踩
前言:本篇文章是卷积网络的搭建,若不太理解CNN卷积神经网络相关概念
请参考文章:【通俗理解】CNN卷积神经网络 - 附带场景举例
一. AlexNet网络
AlexNet网络结构相对简单,使用了8层卷积神经网络,前5层是卷积层,剩下的3层是全连接层,网络结构具体如下所示。模型可利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
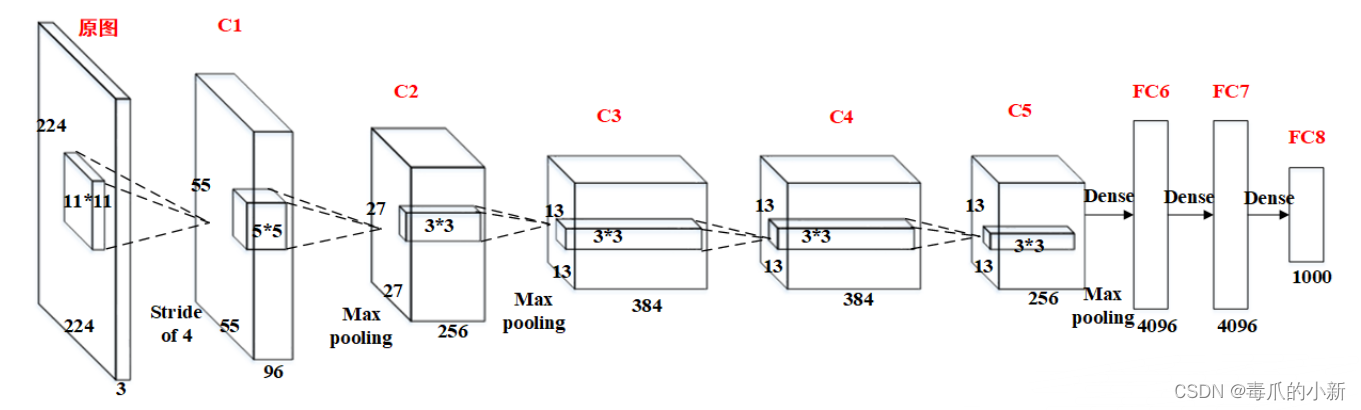
其中有卷积层输出张量大小计算公式为:
输出特征图大小
=
(
(
输入大小
−
卷积核大小
+
2
∗
填充值的大小
)
/
步长大小
)
+
1
输出特征图大小 = ((输入大小-卷积核大小+2*填充值的大小)/步长大小) + 1
输出特征图大小=((输入大小−卷积核大小+2∗填充值的大小)/步长大小)+1
则如上图所示,第一个卷积层输入为224*224*3的图像,取11*11*3的卷积核,填充值为0,步长为4,计算输出张量大小为:
( ( 224 − 11 + 2 ∗ 0 ) / 4 ) + 1 ≈ 55 ((224-11+2*0)/4)+1≈55 ((224−11+2∗0)/4)+1≈55
同理,可以计算池化层输出张量大小,计算公式为:
特征特征图大小 = ( ( 输入大小 − 卷积核大小 ) / 步长大小 ) + 1 特征特征图大小 = ((输入大小-卷积核大小)/步长大小) + 1 特征特征图大小=((输入大小−卷积核大小)/步长大小)+1
二. 模型搭建
实验数据集:
- 训练集:包含五种标签的图片集,拥有12万张图片
- 测试集:包含五种标签的图片集,拥有2万张图片
实验目的:
- 利用训练集对模型进行训练,产出准确率较高的模型
- 利用该模型对测试集图片进行预测
2.1 CNN模型
CNNMould.py:用于构建CNN卷积神经网络,这里搭建类AlexNet模型,也就是采用其模型结构,但不构建那么多数量的卷积层和全连接层。其中包括两个卷积层-两个池化层-一个全连接层-一个输出层。
#导入torch.nn模块 from torch import nn # nn.functional:(一般引入后改名为F)有各种功能组件的函数实现,如:F.conv2d import torch.nn.functional as F # 定义AlexNet网络模型 # MyLeNet5(子类)继承 nn.Module(父类) class MyAlexNet(nn.Module): # 子类继承中重新定义Module类的__init__()和forward()函数 # init():进行初始化,申明模型中各层的定义 def __init__(self,out): # super:引入父类的初始化方法给子类进行初始化 super(MyAlexNet, self).__init__() # 使用ReLU作为激活函数 self.ReLU = nn.ReLU() # 第一个卷积层,输入通道为4(对应RGBA图像),输出为32,卷积核为3 # 步长为1,即每次卷积核在水平和垂直方向上移动1个像素 # 边缘像素为1,以便在卷积操作中保持输入和输出的尺寸相似 # 计算公式:特征图大小 = ((输入大小-卷积核大小+2*填充值的大小)/步长大小) + 1 self.c1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, padding=1) # 第一个最大池化层,池化核为2,步长为2 # 计算公式:特征图大小 = (输入大小-卷积核大小)/步长大小 + 1 self.s1 = nn.MaxPool2d(kernel_size=2, stride=1) # 第二个卷积层,输入通道为32,输出为64,卷积核为3,步长为1,扩充边缘为1 self.c2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1) # 第二个最大池化层,池化核为2,步长为2 self.s2 = nn.MaxPool2d(kernel_size=2, stride=1) # Flatten():将张量(多维数组)平坦化处理,神经网络中第0维表示的是batch_size,所以Flatten()默认从第二维开始平坦化 self.flatten = nn.Flatten() # 全连接层,第一个参数表示样本的大小,第二个参数表示样本输出的维度大小 self.f3 = nn.Linear(6400,512) # softmax输出层,此时第二个参数代表了该全连接层的神经元个数(或者说分类个数),此时需要实现5种分类 self.f4 = nn.Linear(512, out) # forward():定义前向传播过程,描述了各层之间的连接关系 def forward(self, imageTensor): # 第一次卷积-激活 imageTensor = self.ReLU(self.c1(imageTensor)) # 第一次池化 imageTensor = self.s1(imageTensor) # 第二次卷积-激活 imageTensor = self.ReLU(self.c2(imageTensor)) # 第二次池化 imageTensor = self.s2(imageTensor) # 平坦化处理 imageTensor = self.flatten(imageTensor) # 全连接 imageTensor = self.f3(imageTensor) # Dropout:随机地将输入中50%的神经元激活设为0,即去掉了一些神经节点,防止过拟合 # “失活的”神经元不再进行前向传播并且不参与反向传播,这个技术减少了复杂的神经元之间的相互影响 imageTensor = F.dropout(imageTensor, p=0.5) # 输出 imageTensor = self.f4(imageTensor) return imageTensor

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
2.2 训练模型
注意:当加载数据集合图片时,需要预先对图片进行分类,并分别存储到不同的文件夹中。比如:利用下述代码我加载的父图片目录为TrainImage,我需要实现五种分类,那么我的TrainImage文件夹下需要存在五个不同的文件夹,图片分别放入文件夹中。
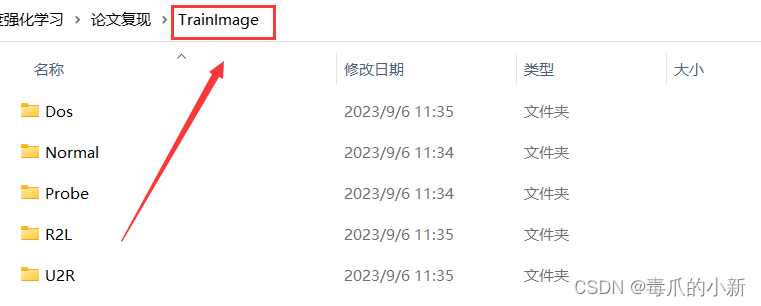
Train.py:利用图片集合对构建的模型进行训练。
# 训练模型 import torch from torch import nn from CNNMould import MyAlexNet from torch.optim import lr_scheduler from torchvision import transforms from torchvision.datasets import ImageFolder from torch.utils.data import DataLoader import matplotlib.pyplot as plt # 解决中文显示问题 # 运行配置参数中的字体(font)为黑体(SimHei) plt.rcParams['font.sans-serif'] = ['simHei'] # 运行配置参数总的轴(axes)正常显示正负号(minus) plt.rcParams['axes.unicode_minus'] = False # 训练集和测试集的位置 ROOT_TRAIN = "C:/Users/29973/Desktop/论文/深度强化学习/论文复现/TrainImage" # Compose():将多个transforms的操作整合在一起 train_transform = transforms.Compose([ # Resize():把给定的图像随机裁剪到指定尺寸 transforms.Resize((12, 12)), # ToTensor():数据转化为Tensor格式 transforms.ToTensor()]) # 加载训练数据集 # ImageFolder:假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下: # root:在root指定的路径下寻找图像,transform:对输入的图像进行的转换操作 train_dataset = ImageFolder(ROOT_TRAIN, transform=train_transform) # batch_size=16表示每个batch加载多少个样本(默认: 1) # shuffle=True表示在每个epoch重新打乱数据(默认: False) train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True) # 如果有NVIDA显卡,可以转到GPU训练,否则用CPU device = 'cuda' if torch.cuda.is_available() else 'cpu' # 模型实例化,将模型转到device model = MyAlexNet(5).to(device) # 定义损失函数(交叉熵损失) loss_fn = nn.CrossEntropyLoss() # 定义优化器(随机梯度下降法) # params(iterable):要训练的参数,一般传入的是model.parameters() # lr(float):learning_rate学习率,也就是步长 # momentum(float, 可选):动量因子(默认:0),矫正优化率 optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 学习率每隔10轮变为原来的0.5 # StepLR:用于调整学习率,一般情况下会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果 # optimizer (Optimizer):更改学习率的优化器 # step_size(int):每训练step_size个epoch,更新一次参数 # gamma(float):更新lr的乘法因子 lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5) # 定义训练函数(数据加载器、CNN模型、损失函数[现成的]、优化器[现成的]) def train(dataloader, model, loss_fn, optimizer): # 损失值,准确率,训练次数 loss, current, n = 0.0, 0.0, 0 # dataloader: 传入数据(数据包括:训练数据和标签) # enumerate():用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中 # enumerate返回值有两个:一个是序号,一个是数据(包含训练数据和标签) # x:训练数据(inputs)(tensor类型的),y:标签(labels)(tensor类型) for batch, (image, label) in enumerate(dataloader): # 前向传播 image, label = image.to(device), label.to(device) # 计算训练值 output = model(image) # 计算观测值(label)与训练值的损失函数 cur_loss = loss_fn(output, label) # torch.max(input, dim)函数 # input是具体的tensor,dim是max函数索引的维度,0是每列的最大值,1是每行的最大值输出 # 函数会返回两个tensor,第一个tensor是每行的最大值;第二个tensor是每行最大值的索引 _, pred = torch.max(output, axis=1) # 计算每批次的准确率 # output.shape[0]为该批次的多少,output的一维长度 # torch.sum()对输入的tensor数据的某一维度求和 cur_acc = torch.sum(label == pred) / output.shape[0] # 反向传播 # 清空过往梯度 optimizer.zero_grad() # 反向传播,计算当前梯度 cur_loss.backward() # 根据梯度更新网络参数 optimizer.step() # item():得到元素张量的元素值 loss += cur_loss.item() current += cur_acc.item() n = n + 1 train_loss = loss / n train_acc = current / n # 计算训练的错误率 print('错误率==' + str(train_loss)) # 计算训练的准确率 print('准确率==' + str(train_acc)) return train_loss, train_acc # 定义画图函数 # 错误率 def matplot_loss(train_loss): # 参数label = ''传入字符串类型的值,也就是图例的名称 plt.plot(train_loss, label='train_loss') # loc代表了图例在整个坐标轴平面中的位置(一般选取'best'这个参数值) plt.legend(loc='best') plt.xlabel('loss') plt.ylabel('epoch') plt.title("训练集Loss图") plt.show() # 准确率 def matplot_acc(train_acc): plt.plot(train_acc, label='train_acc') plt.legend(loc='best') plt.xlabel('acc') plt.ylabel('epoch') plt.title("训练集Acc图") plt.show() # 开始训练 loss_train = [] acc_train = [] # 训练次数 epoch = 20 for t in range(epoch): print(f"当前第{t + 1}轮训练\n----------") # 训练模型 train_loss, train_acc = train(train_dataloader, model, loss_fn, optimizer) loss_train.append(train_loss) acc_train.append(train_acc) # 保存最后一轮权重 if t == epoch - 1: # 存储模型 torch.save(model.state_dict(), 'Mould/best_model.pth') lr_scheduler.step() matplot_loss(loss_train) matplot_acc(acc_train) print('done')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
2.3 图像预测
注意:当加载预测数据集合图片时,也需要先分类图片到不同的文件夹中,这是为了验证图片正确的分组,否则不知道图片原始标签。
Predict.py:利用保存好的模型对图像进行分类预测。
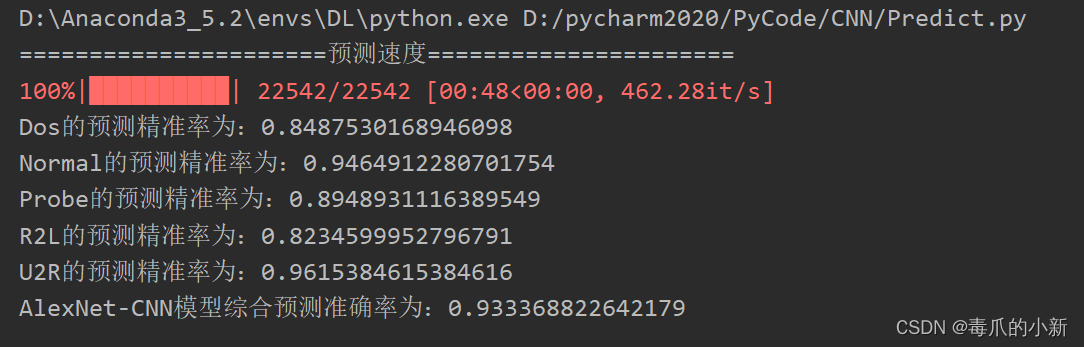
# 用模型预测 import torch from CNNMould import MyAlexNet from torch import nn from torch.autograd import Variable from torchvision import transforms from torchvision.datasets import ImageFolder from torch.utils.data import DataLoader from tqdm import tqdm import time ROOT_TEST = "C:/Users/29973/Desktop/论文/深度强化学习/论文复现/PredictImage" val_transform = transforms.Compose([ transforms.Resize((12, 12)), transforms.ToTensor()]) # 加载训练数据集 val_dataset = ImageFolder(ROOT_TEST, transform=val_transform) # batch_size=16表示每一轮预测都放入16张图片 val_dataloader = DataLoader(val_dataset,batch_size=16, shuffle=True) # 如果有NVIDA显卡,转到GPU训练,否则用CPU device = 'cuda' if torch.cuda.is_available() else 'cpu' # 模型实例化,将模型转到device model = MyAlexNet(5).to(device) # 加载train.py里训练好的模型 model.load_state_dict(torch.load('Mould/best_model.pth')) model.eval() # 单个测试 def predictOneByOne(): # 结果类型 classes = ["Dos","Normal","Probe","R2L","U2R"] # 记录每种结果的预测概率 preList = [0,0,0,0,0] actList = [0,0,0,0,0] # 最终总的结果预测概率 succeed = 0 lengthData = len(val_dataset) print("======================预测速度======================") for i in tqdm(range(lengthData)): x, y = val_dataset[i][0], val_dataset[i][1] # torch.unsqueeze(input, dim),input(Tensor):输入张量,dim (int):插入维度的索引,最终扩展张量维度为4维 x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device) with torch.no_grad(): pred = model(x) # 返回预测值所在的索引编号 # argmax(input):返回指定维度最大值的序号 predIndex = torch.argmax(pred[0]) # 预测值和实际值所在索引编号加一 preList[predIndex] += 1 actList[y] += 1 if predIndex == y: succeed += 1 for i in range(5): if preList[i] <= actList[i]: print(f"{classes[i]}的预测精准率为:{str(preList[i] / actList[i])}") else: print(f"{classes[i]}的预测精准率为:{str(actList[i] / preList[i])}") print(f"AlexNet-CNN模型综合预测准确率为:{str(succeed/lengthData)}") predictOneByOne()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
2.4 评估标准
精准率和准确率是不一样的属性,其中有:
-
TP 真阳性:预测为正,实际也为正
-
FP 假阳性:预测为正,实际为负
-
FN 假阴性:预测与负、实际为正
-
TN 真阴性:预测为负、实际也为负
精准率: P r e c i s i o n = T P / ( T P + F P ) Precision = TP / (TP+FP) Precision=TP/(TP+FP)
准确率 : A c c u r a c y = ( T P + T N ) / ( T P + F P + F N + T N ) Accuracy = (TP+TN) / (TP+FP+FN+TN) Accuracy=(TP+TN)/(TP+FP+FN+TN)
在上述模型的预测下,图片预测准确率如图