
- 1sqoop (Hadoop(Hive)与传统的数据库(mysql..)间进行数据的传递工具) 基础概念_在 hadoop 和传统数据库之间进行大数据传输,可以使用
- 2Java官网下载JDK17版本详细教程(下载、安装、环境变量配置)_java17
- 3SpringBoot + ShardingSphere实现读写分离,分库分表_shardingsphere 分库分表和读写分离的配置
- 4内容安全复习 8 - 视觉内容伪造与检测
- 5微信小程序制作 购物商城首页 【内包含源码】_微信小程序购物商城源码
- 6力扣114. 二叉树展开为链表
- 7Spring Cloud Alibaba(三)Sentinel限流实现原理_sphu.entry 限流
- 8数据结构与人工智能: 如何实现高效的知识图谱和自然语言处理
- 9燕山大学——软件用户界面设计(八)原型设计_界面原型设计
- 10OLTP VS OLAP VS HTAP_olap oltp htap
ICLR 2023 | RevCol:给神经网络架构增加了一个维度!大模型架构设计新范式
赞
踩
点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2212.11696.pdf
项目代码:https://github.com/megvii-research/RevCol
计算机视觉研究院专栏
Column of Computer Vision Institute
提出了一种新的神经网络设计范式可逆Column网络(RevCol)。RevCol的主体由多个子网络的副本组成,分别命名为columns,子网络之间采用多级可逆连接。

01
总 述
这样的架构方案使RevCol的行为与传统网络大不相同:在前向传播过程中,RevCol中的特征在通过每一列时都会逐渐解开,其总信息会被保留,而不是像其他网络那样被压缩或丢弃。
实验表明,CNN风格的RevCol模型可以在图像分类、目标检测和语义分割等多项计算机视觉任务上取得非常有竞争力的性能,尤其是在参数预算大、数据集大的情况下。例如,在ImageNet-22K预训练后,RevCol-XL在ImageNet-1K上获得88.2%的准确度。给定更多的预训练数据,最大的模型RevCol-H在ImageNet-1K上达到90.0%,在COCO检测最小值集上达到63.8%的APbox,在ADE20k分割上达到61.0%的mIoU。
据所知,这是纯(静态)CNN模型中最好的COCO检测和ADE20k分割结果。此外,作为一种通用的宏架构方式,RevCol还可以引入到Transformer或其他神经网络中,这被证明可以提高计算机视觉和NLP任务中的性能。

02
背景&动机
Information Bottleneck principle(IB)统治着深度学习世界。考虑一个典型的监督学习网络,如下图a所示:靠近输入的层包含更多的低级信息,而靠近输出的特征具有丰富的语义。
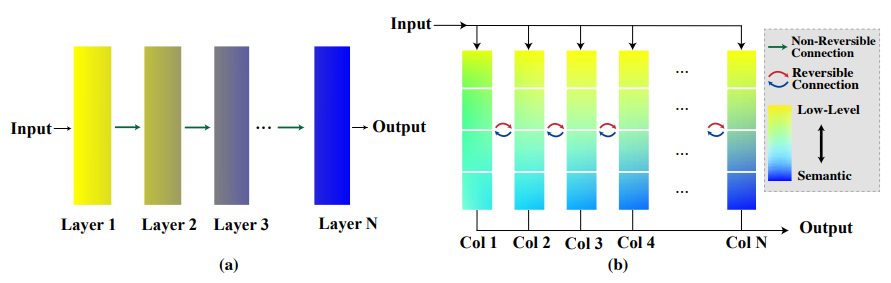
换句话说,在逐层传播期间,与目标无关的信息被逐渐压缩。尽管这种学习范式在许多实际应用中取得了巨大成功,但从特征学习的角度来看,它可能不是最佳选择——如果学习到的特征被过度压缩,或者学习到的语义信息与目标任务无关,则下游任务的性能可能较差,特别是在源任务和目标任务之间存在显著的领域差距的情况下。研究人员付出了巨大的努力,使学习到的特征更加普遍适用,例如通过自监督的预训练或多任务学习。
在今天分享中,研究者主要关注另一种方法:建立一个网络来学习解耦表征。与IB学习不同,去解耦特征学习不打算提取最相关的信息,而丢弃不太相关的信息;相反,它旨在将与任务相关的概念或语义词分别嵌入到几个解耦的维度中。同时,整个特征向量大致保持与输入一样多的信息。这与生物细胞中的机制非常相似,每个细胞共享整个基因组的相同拷贝,但具有不同的表达强度。因此,在计算机视觉任务中,学习解耦特征也是合理的:例如,在ImageNet预训练期间调整高级语义表示,同时,在目标检测等下游任务的需求下,还应在其他特征维度上保持低级信息(如边缘的位置)。
上图(b)概述了主要想法:RevCol,它在很大程度上受到了GLOM大局的启发。网络由结构相同(但其权重不一定相同)的N个子网络(命名列)组成,每个子网络接收输入的副本并生成预测。因此,多级嵌入,即从低级到高度语义表示,存储在每一列中。此外,引入可逆变换以在没有信息损失的情况下将多级特征从第i列传播到第(i+1)列。在传播过程中,由于复杂性和非线性增加,预计所有特征级别的质量都会逐渐提高。因此,最后一列(图中的第N列)1(b))预测了输入的最终解耦表示。

03
新框架
接下来,我们将介绍RevCol的设计细节。上图b说明了顶层体系结构。请注意,对于RevCol中的每一列,为了简单起见,直接重用ConvNeXt等现有结构,因此在以下主要关注如何构建列之间的可逆连接。此外,在每个列的顶部引入了即插即用的中间监督,这进一步提高了训练收敛性和特征质量
MULTI-LEVEL REVERSIBLE UNIT
在新提出的网络中,可逆变换在不损失信息的情况下对特征解耦着关键作用,其见解来自可逆神经网络。其中,首先回顾了RevNet的一部代表作。如下图a所示,RevNet首先将输入x划分为两组,x0和x1。
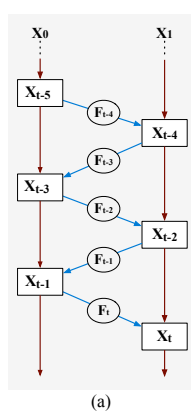
然后,对于后面的块,例如块t,它将前面两个块的输出xt−1和xt−2作为输入,并生成输出xt。块t的映射是可逆的,即xt−2可以由两个后验块xt−1和xt重构。形式上,正向和反向计算遵循方程†:
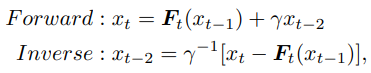
为了解决上面提及的问题,将上面等式概括为以下形式:
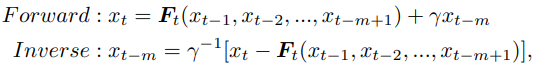
因此,可以将上面方程重组为多列形式,如下图b所示。每列由一组内的m个特征图及其母网络组成。将其命名为多级可逆单元,这是RevCol的基本组成部分。
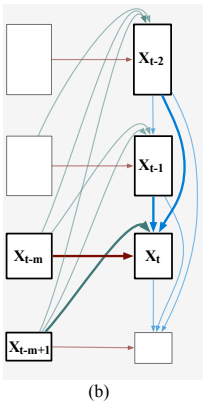
REVERSIBLE COLUMN ARCHITECTURE
宏观设计
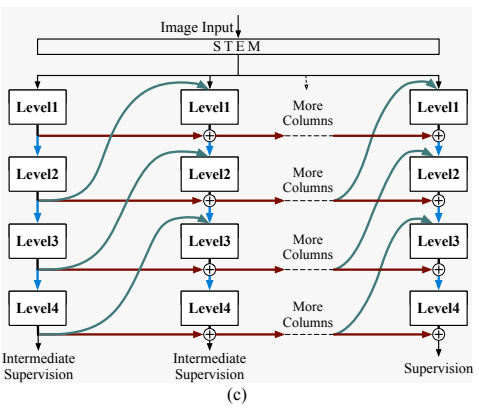
上图2c阐述了框架设计。按照最近模型的常见做法,首先通过补丁嵌入模块将输入图像分割成不重叠的补丁。然后,将补丁馈送到每个子网络(列)中。列可以用任何传统的单列架构来实现,例如ViT或ConvNeXt。从每一列中提取四级特征图,以在列之间传播信息;例如,如果列是用广泛使用的层次网络实现的,可以简单地从每个阶段的输出中提取多分辨率特征。
对于分类任务,只使用最后一列中最后一级(第4级)的特征图来获取丰富的语义信息。
对于其他下游任务,如目标检测和语义分割,在最后一列中使用所有四个级别的特征图,因为它们包含低级和语义信息。
微观设计
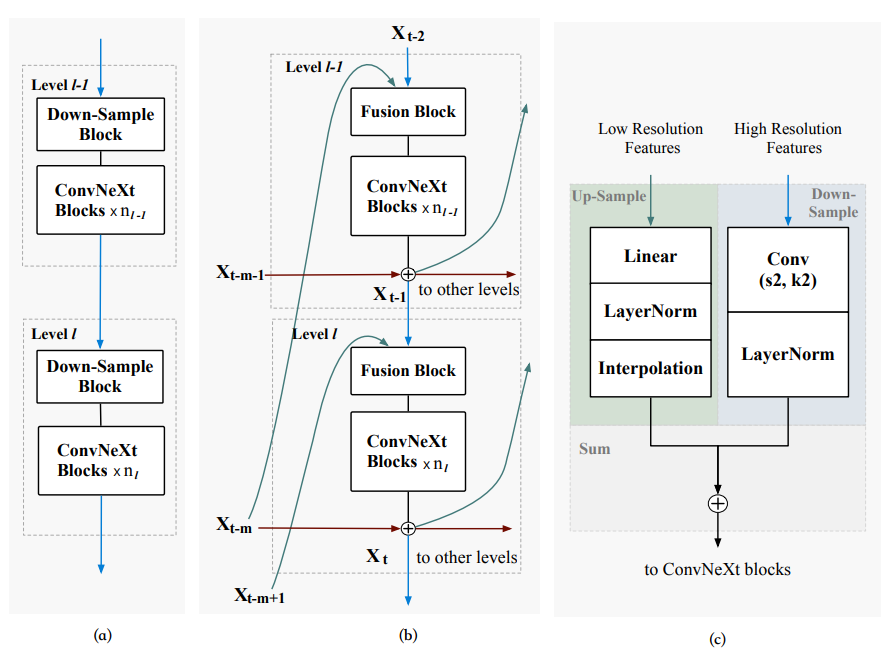
每一个层级中,先用一个Fusion单元把不同尺寸的输入调整到同一个shape,后面再经过一堆ConvNeXt Blocks得到输出,这些就是公式中的Ft(·),然后再和Reversible operation的输入加和得到最终结果。
值得注意的是,把原本的ConvNeXt block中7x7的kernel size改成了3x3,大kernel的收益在Revcol上有限,但小kernel特别快。

04
实验
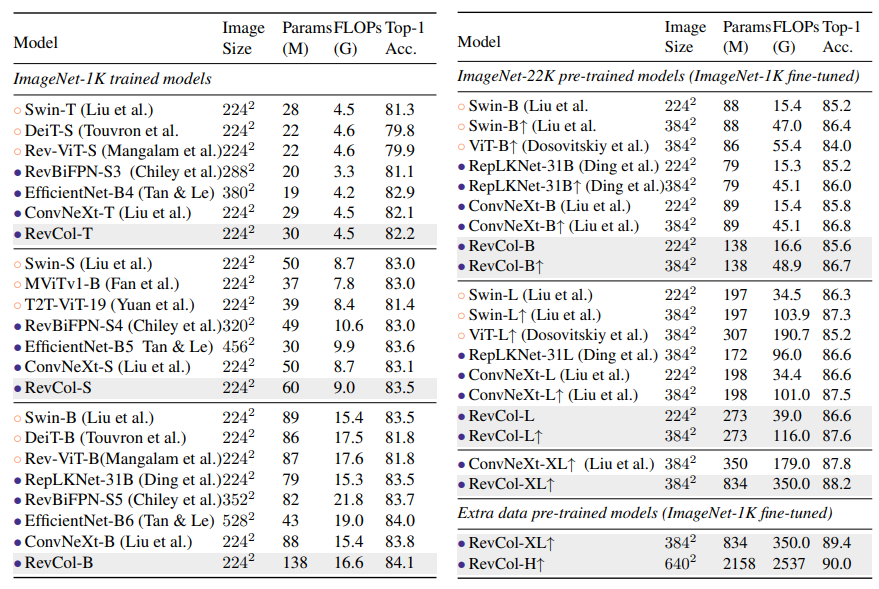
除了2B参数的模型以外,还收集了168Million的私有数据集,weakly-label的标签用来预训练。XL模型(800M param),在22k下能达到88.2%,经过Megdata-168M的训练后能够涨到89.4%。Huge 224 pretrain,640x640 Finetune能够达到90.0%Top-1 Accuracy。这个模型的训练开销:预训练总共1600个ImageNet Epochs,训练一次使用80块A100,14天。


© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期回顾

