
- 1HDShredder 7 企业版案例分享: 依照国际权威标准,安全清除企业数据
- 2数据仓库入门简介_酒店数据仓库最简单三个步骤
- 3文本生成公开数据集/开源工具/经典论文详细列表分享_文案生成数据集
- 4如何使用cp命令复制文件和目录!【Linux命令合集】_cp拷贝目录
- 5windows使用Docker-Desktop部署lobe-chat_lobechat docker
- 6Git版本控制系列:创建分支和分支合并_版本管理分支一定要合并
- 7内网域渗透总结_域渗透知识
- 8【Unity2D好项目分享】用全是好活制作横版卷轴射击游戏③制作血条和能量条UI以及生命值系统和能量值系统_unity2d制作人物生命值
- 9用 YOLO V4训练自己的数据集_yolov4训练自己的数据集
- 10无涯教程-PostgreSQL - Triggers(触发器)_postgresql trigger
Python进程池multiprocessing.Pool_multiprocessing.pool()
赞
踩
一、Python进程池multiprocessing.Pool的用法
Python进程池multiprocessing.Pool的用法 - 海布里Simple - 博客园
一、multiprocessing模块
multiprocessing模块提供了一个Process类来代表一个进程对象,multiprocessing模块像线程一样管理进程,这个是multiprocessing的核心,它与threading很相似,对多核CPU的利用率会比threading好的多
看一下Process类的构造方法:
__init__(self, group=None, target=None, name=None, args=(), kwargs={})
参数说明:
group:进程所属组(基本不用)
target:表示调用对象
args:表示调用对象的位置参数元组
name:别名
kwargs:表示调用对象的字典
示例:

import multiprocessing
def do(n): # 参数n由args=(1,)传入
name = multiprocessing.current_process().name # 获取当前进程的名字
print(name, 'starting')
print("worker ", n)
return
if __name__ == '__main__':
numList = []
for i in range(5):
p = multiprocessing.Process(target=do, args=(i,)) # (i,)中加入","表示元祖
numList.append(p)
print(numList)
p.start() # 用start()方法启动进程,执行do()方法
p.join() # 等待子进程结束以后再继续往下运行,通常用于进程间的同步
print("Process end.")

运行结果:

[<Process(Process-1, initial)>] Process-1 starting worker 0 Process end. [<Process(Process-1, stopped)>, <Process(Process-2, initial)>] Process-2 starting worker 1 Process end. [<Process(Process-1, stopped)>, <Process(Process-2, stopped)>, <Process(Process-3, initial)>] Process-3 starting worker 2 Process end. [<Process(Process-1, stopped)>, <Process(Process-2, stopped)>, <Process(Process-3, stopped)>, <Process(Process-4, initial)>] Process-4 starting worker 3 Process end. [<Process(Process-1, stopped)>, <Process(Process-2, stopped)>, <Process(Process-3, stopped)>, <Process(Process-4, stopped)>, <Process(Process-5, initial)>] Process-5 starting worker 4 Process end.

通过打印numList可以看出当前进程结束后,再开始下一个进程
注意:
在Windows上要想使用进程模块,就必须把有关进程的代码写在当前.py文件的if __name__ == ‘__main__’ :语句的下面,才能正常使用Windows下的进程模块。Unix/Linux下则不需要
二、Pool类
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求
下面介绍一下multiprocessing 模块下的Pool类下的几个方法:
1.apply()
函数原型:apply(func[, args=()[, kwds={}]])
该函数用于传递不定参数,同python中的apply函数一致,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不再出现)
2.apply_async
函数原型:apply_async(func[, args=()[, kwds={}[, callback=None]]])
与apply用法一致,但它是非阻塞的且支持结果返回后进行回调
3.map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到结果返回
注意:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程
4.map_async()
函数原型:map_async(func, iterable[, chunksize[, callback]])
与map用法一致,但是它是非阻塞的
5.close()
关闭进程池(pool),使其不再接受新的任务
6.terminal()
结束工作进程,不再处理未处理的任务
7.join()
主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用
示例1--使用map()函数

import time
from multiprocessing import Pool
def run(fn):
# fn: 函数参数是数据列表的一个元素
time.sleep(1)
print(fn * fn)
if __name__ == "__main__":
testFL = [1, 2, 3, 4, 5, 6]
print('shunxu:') # 顺序执行(也就是串行执行,单进程)
s = time.time()
for fn in testFL:
run(fn)
t1 = time.time()
print("顺序执行时间:", int(t1 - s))
print('concurrent:') # 创建多个进程,并行执行
pool = Pool(3) # 创建拥有3个进程数量的进程池
# testFL:要处理的数据列表,run:处理testFL列表中数据的函数
pool.map(run, testFL)
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
t2 = time.time()
print("并行执行时间:", int(t2 - t1))
运行结果:

1、map函数中testFL为可迭代对象--列表
2、当创建3个进程时,会一次打印出3个结果“1,4,9”,当当创建2个进程时,会一次打印出2个结果“1,4”,以此类推,当创建多余6个进程时,会一次打印出所有结果
3、如果使用Pool(),不传入参数,可以创建一个动态控制大小的进程池


从结果可以看出,并发执行的时间明显比顺序执行要快很多,但是进程是要耗资源的,所以平时工作中,进程数也不能开太大。 对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),让其不再接受新的Process了
示例2--使用map()_async函数

print('concurrent:') # 创建多个进程,并行执行
pool = Pool(3) # 创建拥有3个进程数量的进程池
# testFL:要处理的数据列表,run:处理testFL列表中数据的函数
pool.map_async(run, testFL)
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
t2 = time.time()
print("并行执行时间:", int(t2 - t1))

运行结果:

从结果可以看出,map_async()和map()用时相同。目前还没有看出两者的区别,后面知道后再完善
示例3--使用apply()函数

print('concurrent:') # 创建多个进程,并行执行
pool = Pool(3) # 创建拥有3个进程数量的进程池
# testFL:要处理的数据列表,run:处理testFL列表中数据的函数
for fn in testFL:
pool.apply(run, (fn,))
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
t2 = time.time()
print("并行执行时间:", int(t2 - t1))

运行结果:

可见,使用apply()方法,并行执行和顺序执行用时相同,经过试验,进程数目增大也不会减少并行执行的时间
原因:以阻塞的形式产生进程任务,生成1个任务进程并等它执行完出池,第2个进程才会进池,主进程一直阻塞等待,每次只执行1个进程任务
示例4--使用apply_async()函数

print('concurrent:') # 创建多个进程,并行执行
pool = Pool(3) # 创建拥有3个进程数量的进程池
# testFL:要处理的数据列表,run:处理testFL列表中数据的函数
for fn in testFL:
pool.apply_async(run, (fn,))
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
t2 = time.time()
print("并行执行时间:", int(t2 - t1))

运行结果:

可见,使用apply_async()方法,并行执行时间与使用map()、map_async()方法相同
注意:
map_async()和map()方法,第2个参数可以是列表也可以是元祖,如下图:

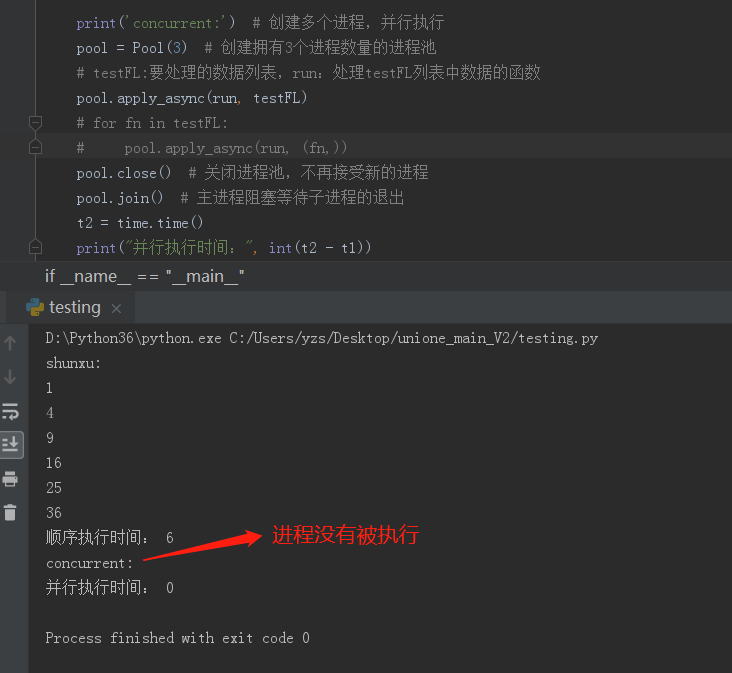
而使用apply()和apply_async()方法时,第2个参数只能传入元祖,传入列表进程不会被执行,如下图:
三、apply_async()方法callback参数的用法
示例:

from multiprocessing import Pool
import time
def fun_01(i):
time.sleep(2)
print('start_time:', time.ctime())
return i + 100
def fun_02(arg):
print('end_time:', arg, time.ctime())
if __name__ == '__main__':
pool = Pool(3)
for i in range(4):
pool.apply_async(func=fun_01, args=(i,), callback=fun_02) # fun_02的入参为fun_01的返回值
# pool.apply_async(func=fun_01, args=(i,))
pool.close()
pool.join()
print('done')

运行结果:
start_time: Thu Nov 14 16:31:41 2019 end_time: 100 Thu Nov 14 16:31:41 2019 start_time: Thu Nov 14 16:31:41 2019 end_time: 101 Thu Nov 14 16:31:41 2019 start_time: Thu Nov 14 16:31:41 2019 end_time: 102 Thu Nov 14 16:31:41 2019 start_time: Thu Nov 14 16:31:43 2019 end_time: 103 Thu Nov 14 16:31:43 2019 done

map_async()方法callback参数的用法与apply_async()相同
四、使用进程池并关注结果

import multiprocessing
import time
def func(msg):
print('hello :', msg, time.ctime())
time.sleep(2)
print('end', time.ctime())
return 'done' + msg
if __name__ == '__main__':
pool = multiprocessing.Pool(2)
result = []
for i in range(3):
msg = 'hello %s' % i
result.append(pool.apply_async(func=func, args=(msg,)))
pool.close()
pool.join()
for res in result:
print('***:', res.get()) # get()函数得出每个返回结果的值
print('All end--')

运行结果:

五、多进程执行多个函数
使用apply_async()或者apply()方法,可以实现多进程执行多个方法
示例:

import multiprocessing
import time
import os
def Lee():
print('\nRun task Lee--%s******ppid:%s' % (os.getpid(), os.getppid()), '~~~~', time.ctime())
start = time.time()
time.sleep(5)
end = time.time()
print('Task Lee,runs %0.2f seconds.' % (end - start), '~~~~', time.ctime())
def Marlon():
print("\nRun task Marlon-%s******ppid:%s" % (os.getpid(), os.getppid()), '~~~~', time.ctime())
start = time.time()
time.sleep(10)
end = time.time()
print('Task Marlon runs %0.2f seconds.' % (end - start), '~~~~', time.ctime())
def Allen():
print("\nRun task Allen-%s******ppid:%s" % (os.getpid(), os.getppid()), '~~~~', time.ctime())
start = time.time()
time.sleep(15)
end = time.time()
print('Task Allen runs %0.2f seconds.' % (end - start), '~~~~', time.ctime())
def Frank():
print("\nRun task Frank-%s******ppid:%s" % (os.getpid(), os.getppid()), '~~~~', time.ctime())
start = time.time()
time.sleep(20)
end = time.time()
print('Task Frank runs %0.2f seconds.' % (end - start), '~~~~', time.ctime())
if __name__ == '__main__':
func_list = [Lee, Marlon, Allen, Frank]
print('parent process id %s' % os.getpid())
pool = multiprocessing.Pool(4)
for func in func_list:
pool.apply_async(func)
print('Waiting for all subprocesses done...')
pool.close()
pool.join()
print('All subprocesses done.')

运行结果:
parent process id 84172 Waiting for all subprocesses done... Run task Lee--84868******ppid:84172 ~~~~ Thu Nov 14 17:44:14 2019 Run task Marlon-84252******ppid:84172 ~~~~ Thu Nov 14 17:44:14 2019 Run task Allen-85344******ppid:84172 ~~~~ Thu Nov 14 17:44:14 2019 Run task Frank-85116******ppid:84172 ~~~~ Thu Nov 14 17:44:14 2019 Task Lee,runs 5.00 seconds. ~~~~ Thu Nov 14 17:44:19 2019 Task Marlon runs 10.00 seconds. ~~~~ Thu Nov 14 17:44:24 2019 Task Allen runs 15.00 seconds. ~~~~ Thu Nov 14 17:44:29 2019 Task Frank runs 20.00 seconds. ~~~~ Thu Nov 14 17:44:34 2019 All subprocesses done.

六、其他
1、获取当前计算机的CPU数量

二、Python 多进程pool.map()方法的使用
原文链接:https://blog.csdn.net/weixin_38819889/article/details/107815272
在python中,只有多进程才可以充分利用CPU的资源,适合CPU计算型任务,其他的就不多说了。这里介绍一个 pool.map()方法,很实用!
pool.map()
先直接上代码:
import time
from multiprocessing.pool import Pool
def numsCheng(i):
return i * 2
if __name__ == '__main__':
time1 = time.time()
nums_list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
pool = Pool(processes=5)
result = pool.map(numsCheng, nums_list)
pool.close() # 关闭进程池,不再接受新的进程
pool.join() # 主进程阻塞等待子进程的退出
print(result)
time2 = time.time()
print("计算用时:", time2-time1)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
运行结果:
[2, 4, 6, 8, 10, 12, 14, 16, 18]
计算用时: 0.21639275550842285
1
2
解释说明:
1.看到Pool有一个processes参数,这个参数可以不设置,如果不设置函数会跟根据计算机的实际情况来决定要运行多少个进程,我们也可自己设置,但是要考虑自己计算机的性能。
2.map()函数。需要传递两个参数,第一个参数就是需要引用的函数,第二个参数是一个可迭代对象,它会把需要迭代的元素一个个的传入第一个参数我们的函数中。因为我们的map会自动将数据作为参数传进去
3.pool()开启了,不要忘记pool.close() 和 pool.join() 关闭进程池,以及让主进程阻塞等待子进程的退出。

