
- 1同时使用github和gitlab_guthub和gitlab通用吗
- 2(超详细,全图)VMware kali安装教程_vmware安装kali
- 3手动安装jar包到本地仓库(mvn install)_手动install jar包
- 4Python机器学习、深度学习技术提升气象、海洋、水文领域实践应用_批量处理台风cma数据
- 5猫头虎推荐:LibreChat,免费的开源 ChatGPT 克隆版!_librechat安装
- 6俄罗斯方块 --基于pygame_俄罗斯方块pyqt pygame
- 7SqlServer CDC 变更数据捕获_sql server cdc无法捕获数据
- 8使用Pycharm 连接内网服务器_pycharm不使用密码连接服务器
- 9【原理】也就一个简单的jquery收缩菜单而已_jquery控制面板左右伸缩
- 10android dumpsys 命令,Android Shell命令dumpsys
serdes基本概念扫盲
赞
踩
一、serdes基本介绍
Xilinx公司的许多FPGA已经内置了一个或多个MGT(Multi-Gigabit Transceiver)收发器,也叫做SERDES(Multi-Gigabit Serializer/Deserializer)。MGT收发器内部包括高速串并转换电路、时钟数据恢复电路、数据编解码电路、时钟纠正和通道绑定电路,为各种高速串行数据传输协议提供了物理层基础。MGT收发器的TX发送端和RX接收端功能独立,而且均由物理媒介适配层(Physical Media Attachment,PMA)和物理编码子层(Physical Coding Sublayer,PCS)两个子层组成,结构如下图所示:
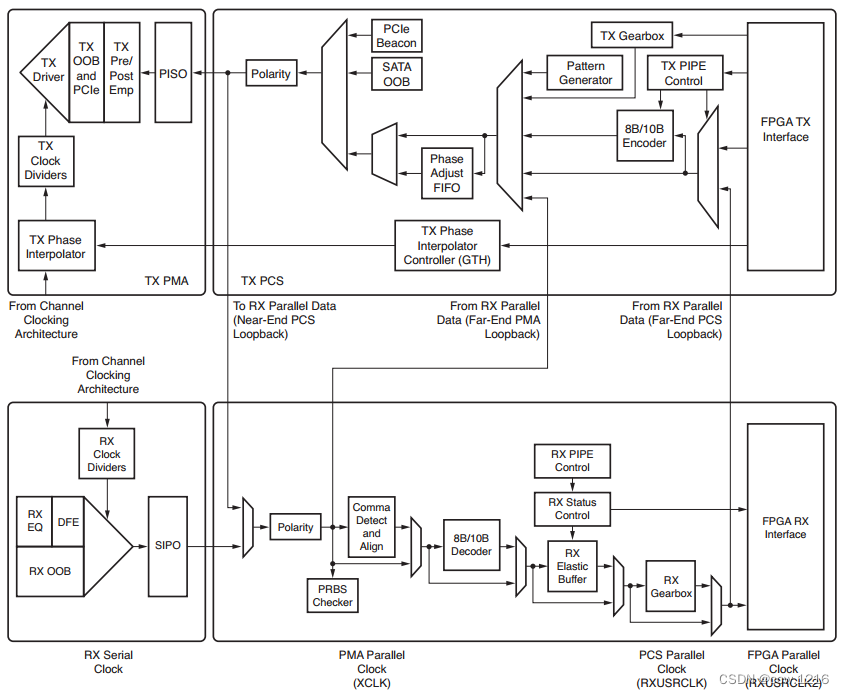
PMA子层内部集成了高速串并转换电路,预加重电路、接收均衡电路、时钟发生电路和时钟恢复电路。(1) 串并转换电路的作用是把FPGA内部的并行数据转化为MGT接口的串行数据。(2) 预加重电路是对物理连接系统中的高频部分进行补偿,在发送端增加一个高通滤波器来放大信号中的高频分量进而提高信号质量,但预加重电路会导致功耗和电磁兼容(Electro Magnetic Compatibility,EMC)增加,所以如非必要一般情况下都把它屏蔽掉。(3) 接收均衡电路主要用来补偿由频率不同引起的阻抗差异。(4) 时钟发生电路与时钟恢复电路在发送端把时钟和数据绑定后发送,在接收端再从接收到的数据流中恢复出时钟,这样可以有效地避免在高速串行传输的条件下时钟与数据分开传输带来的时钟抖动问题。
PCS子层内部集成了8B/10B编/解码电路、弹性缓冲电路、通道绑定电路和时钟修正电路。(1) 8B/10B编/解码电路可以有效的避免数据流中出现连续的‘0’或者‘1’,以保证数据传输的平衡性。(2) 通道绑定电路的作用是通过在发送数据流中加入K码字符,把多个物理上独立的MGT通道绑定成一个时序逻辑上同步的并行通道进而提高传输的吞吐率。(3) 弹性缓冲电路用来解决恢复的时钟与本地时钟不一致的问题并可以通过对缓冲区中的K码进行匹配对齐来实现通道绑定功能。
下面将详细讨论SERDES用到的各种关键技术。
二、SERDES关键技术
简化的SERDES结构图如下图所示:

SERDES的优势在于其带宽很高,引脚数目较少而且支持目前多种主流的工业标准,比如Serial RapidIO ,FiberChannel(FC),PCI-Express(PCIE),Advanced Switching Interface,Serial ATA(SATA),1-Gb Ethernet,10-Gb Ethernet(XAUI),Infiniband 1X,4X,12X等。它的线速度能达到10Gb/s甚至更高,主要原因是因为它采用了多种技术来实现这些功能。
2.1 多重相位技术
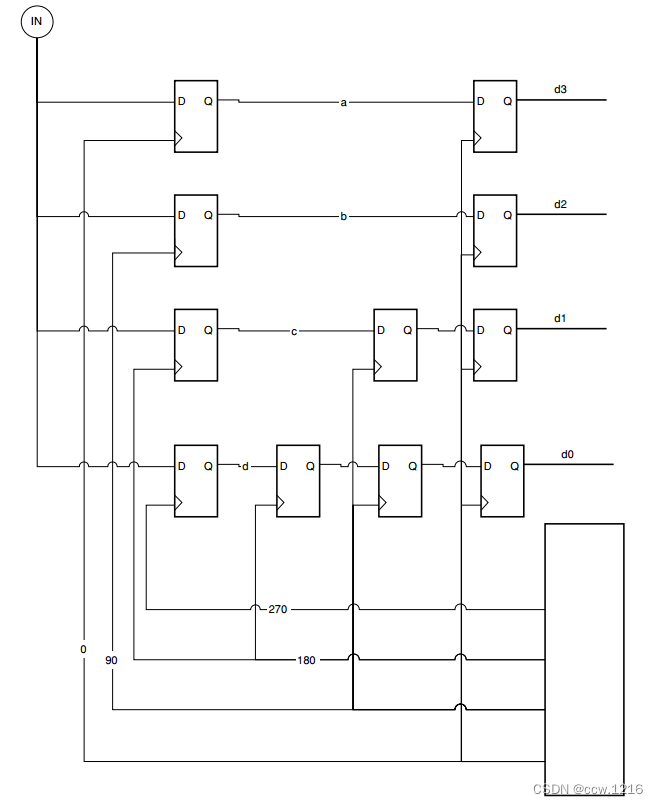
如果输入的串行数据流比特率为x, 那么可以使用多重相位以x/4的低速时钟来重新组织数据流。输入的数据流直接连接到4个触发器,每一个触发器运行在时钟的不同相位上(0、90、180以及270)。多重相位技术的数据提取电路如下图所示
对应的时序图如下图所示
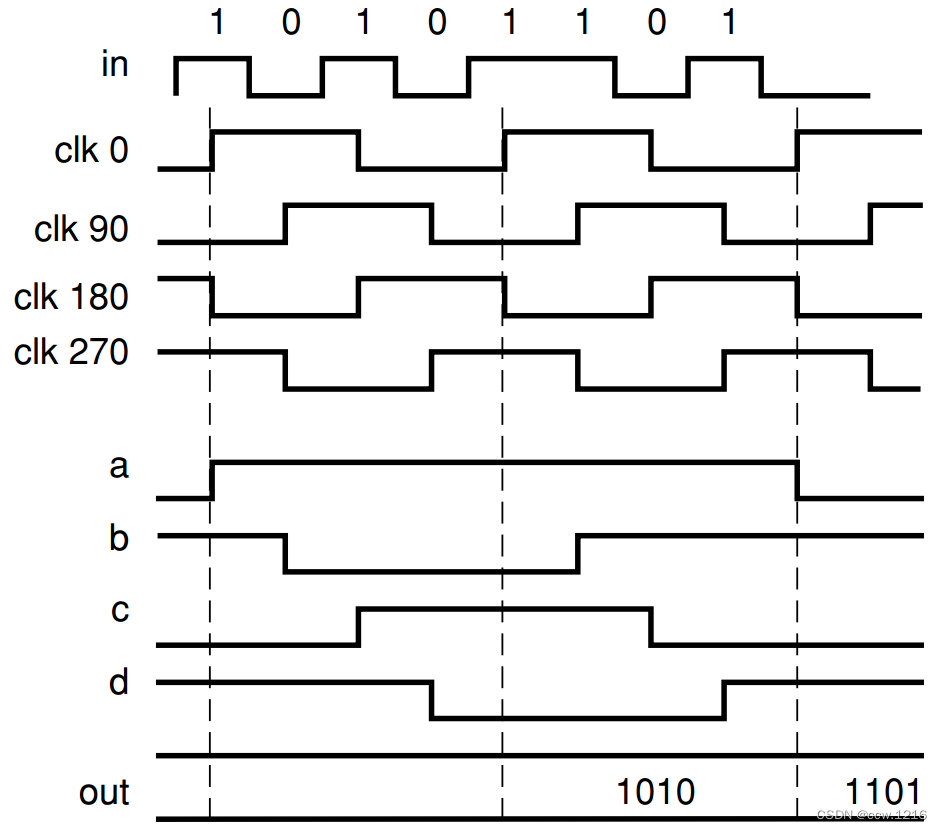
每个触发器的输出连接到时钟相位小90度的触发器,直到到达时钟相位为0 的触发器。这样,输入数据流就被分解成了1/4输入速率, 4bit宽度的并行数据流。
在上述的示例电路中,相位等差排列,时钟频率严格等于输入数据流速率的1/4。怎样才能实现呢?我们必须和输入的数据流保持锁定。我们可以使用典型的锁相环来实现这一点,但是锁相环需要一个全速率的时钟,这是很难满足的。锁相环是高速SERDES设计中最重大的改进之一,它主要用于时钟和数据恢复。一般的锁相环需要有运行在数据速率上的时钟,不过可以通过多种技术来避免这种要求,包括分数鉴相器、多重相位锁相环、并行采样以及过采样数据恢复。
2.2 线路编解码技术
线路编码机制将输入的原始数据转变成接收器可以接收的格式,并保证有足够的切换提供给时钟恢复电路。编码器还提供一种将数据对齐到字的方法,同时线路可以保持良好的直流平衡。线路编码机制也可选择用来实现时钟修正、块同步、通道绑定和将带宽划分到子通道。线路编码机制主要有两种方式,分别为数值查找机制和扰码机制。
2.2.1 8B/10B编解码
8b/10b编码机制是由IBM开发的,已经被广泛采用。 8b/10b编码机制是Infiniband,千兆位以太网, FiberChannel以及XAUI 10G以太网接口采用的编码机制。它是一种数值查找类型的编码机制,可将8位的字转化为10位符号。这些符号可以保证有足够的跳变用于时钟恢复。下表是两个8-bit数据编码为10-bit数据的例子。
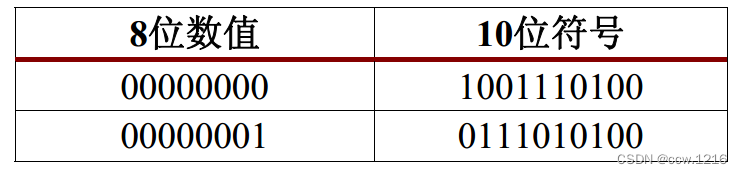
在上面的例子中8-bit数据会导致线路很长时间不出现切换而丢失同步信息。 所以8B/10B编解码电路采用了一种叫做运行不一致(Running Disparity)的技术来保证线路良好的直流平衡性能。
2.2.2 运行不一致(Running Disparity)
8B/10B编解码机制中的直流平衡是通过一种称作“运行不一致性”的方法来实现的。实现直流平衡的最简单办法是:只使用有相同个数0和1的符号,但是这将限制符号的数量。而8B/10B则为各个数值分配了两个不同的符号。其中一个符号有6个0和4个1,这种情况称为正运行不一致符号,简写为RD+,另一个符号则有4个0和6个1,这种情况称为负运行不一致符号,简写为RD-。编码器会检测0和1的数量,并根据需求选择下一个符号,以保证线路的直流平衡。下表给出了一些符号示例
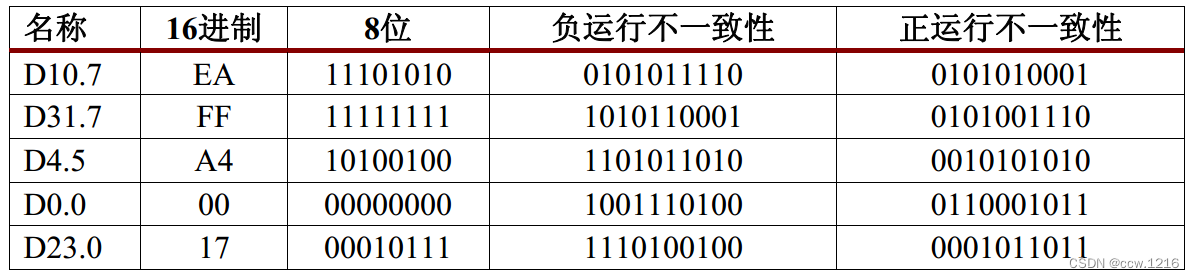
“运行不一致性”技术的另一个优点是如果数据违反了运行不一致性规则,那么接收器可以通过监控输入数据的运行不一致性规则来检测数据中的错误。
2.2.3 控制字符(Control Characters)
8B/10B编解码技术将12个特殊字符编码成12个控制字符,通常也称作“K”字符。这些控制字符用于数据对齐,控制以及将带宽划分成为子通道。下表是12种控制字符的编码情况

2.2.4 Comma检测
Comma指的是用于对齐序列的一个7-bit符号。数据的对齐是解串器的一项重要功能,下图给出了串行流中的有效8B/10B数据示例。
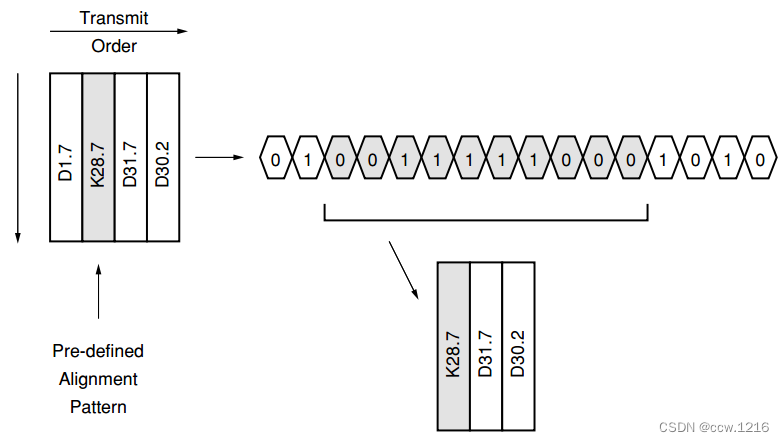
在Serdes中,数据被Comma序列隔开,Comma序列可以自行设置,也可以预先定义好。接收器在输入数据流中扫描搜寻特定的比特序列。如果找到序列,解串器调整字符边界以匹配检测到的Comma字符序列。扫描是连续进行的,一旦对齐确定,所有后续的Comma字符均会发现对齐已经确定。当然,在任意的序列组合里comma字符序列必须是唯一的。
例如,如果我们使用符号K28.7作为Comma字符,则我们必须确保任意有序符号集xy中都不包含比特序列K28.7。使用预定义协议时是不会出现这个问题的,因为Comma字符都是已经定义好的。
常用的K字符是全部控制字符中的一个或多个特定子集。这些子集中包含K28.1,K28.5,K28.7,这些字符的头7位都是1100000。这种比特序列模式只可以在这些控制字符中出现。其他任意的字符序列或者其他K字符都不包含这一比特序列。因此,这些控制字符是非常理想的对齐序列。在使用自定义协议的情况下,最安全且最常用的解决方案是从比较著名的协议中“借”一个序列。千兆位以太网使用K28.5作为Comma字符。鉴于这个原因,尽管在技术上还有其他的选择,这个字符还是经常被当作Comma字符。
控制字符的命名方式源于编码器和解码器构建方式,例如: D0.3和K28.5,下图描述了这种方法。
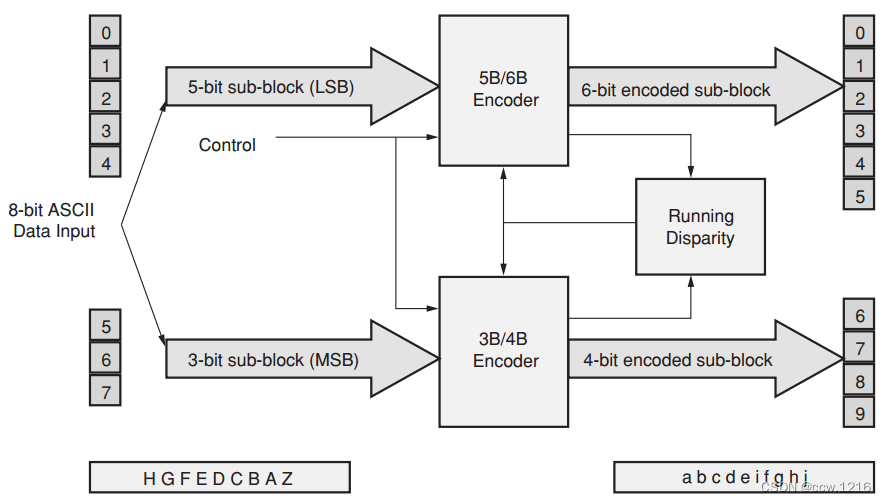
输入的8位比特被分成5位和3位的数据分别进行5B/6B编码和3B/4B编码,这就是其名字的来源。举例说明, Dx.y表示最低5位的数值对应十进制值x,而最高3位的数值对应十进制值y的输入字节。字母D表示数据字符,而字母K表示控制字符。另一种命名方式中, 8位比特对应于HGF EDCBA,而10位比特对应于abcdei fghj。开销是8b/10b机制的一个缺陷。为了获得2.5Gbit的带宽,需要3.125Gb/s的线路速率。但使用扰码技术可以很容易地解决时钟发送和直流偏置问题,并且不需要额外的带宽。
2.2.4 扰码(Scrambling)
扰码是一种将数据重新排列或者进行编码以使其随机化的方法,但是必须能够解扰恢复。我们希望打乱长的连0和长的连1序列,将数据随机化。显然,我们希望解扰器在解扰时不需要额外的对齐信息。具有这种特性的码称作自同步码。
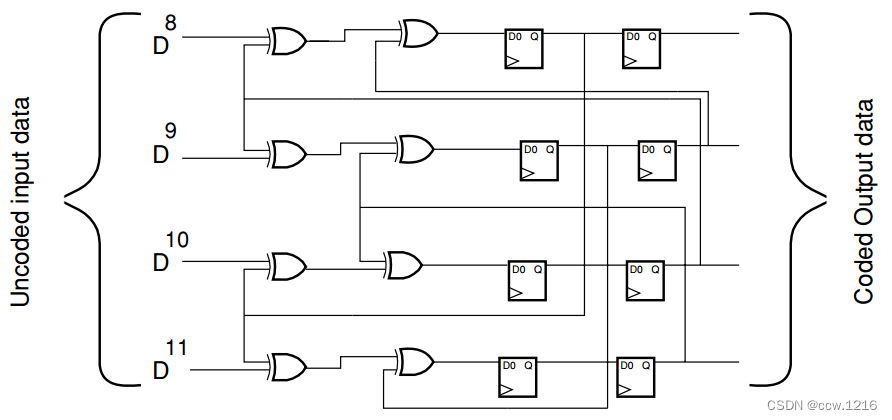
一个简单的扰码器包含一组排列好的触发器,用于移位数据流。大部分的触发器只需要简单地输出下一个比特即可,但是某些触发器需要和数据流中的历史比特相与或者相或。下图描述了此概念。

扰码方法通常是伴随着多项式出现的,因为扰码的数学原理中使用了多项式。多项式的选择通常是基于扰码的特性,包括生成数据的随机度,以及打乱长的连0、连1的能力。扰码必须避免生成长的连0或连1序列。
我们希望能够加快触发器的时钟速率。但是想要达到诸如10Gb/s的高速率不是能轻易办到的。但是,还是有方法可以将任意形式的串行数据并行化为y位宽度的并行数据,从而加快进程。如下图所示。
扰码器消除了长连0、连1序列以及其他会对接收器接收能力有负面影响的序列。但是线路编码机制(例如: 8B/10B)的其他功能不是由扰码器提供的,包括:
1、 字对齐(Word Alignment)
2、 时钟修正机制(Clock Correction Mechanism)
3、 通道绑定机制(Channel Bonding Mechanism)
4、 子通道生成(Sub-Channel Creation)
某些情况下后三种功能可能是不需要的,而字对齐通常是必要的。如果线路编码使用了扰码,那么字对齐也必须采用相应的方法。例如,我们可以将某些数值排除在容许的数据(或者有效载荷)数值之外。此后,我们可以使用这些禁用的值来创建一个比特流,这个比特流不会在序列的数据部分中出现。如下图所示

通常,因为存在不允许的数值,所以需要设计数据流中不能出现连0或连1的长度。长的连0、连1会被扰码器打乱,并在解扰时进行恢复。接收数据流的解扰逻辑在数据流中搜寻这些符号并对齐数据。类似的技术还可用于建立其他特性。
2.2.5 4B/5B与64B/66B编解码技术
4B/5B和8B/10B是类似的。顾名思义,这种机制将4个比特编码成5个比特。4B/5B的编码器和解码器要比8B/10B简单一些。4B/5B的控制字符要少一些,并且不能处理直流平衡和运行不一致性问题。由于编码开销相同但是功能却比较少,所以4B/5B编码机制并不经常使用。它的最大优势是设计的尺寸,不过随着逻辑门价格的降低这个优势也不再明显。4B/5B仍用在各种标准中,包括低速率版本的FiberChannel、音频工程协会-10(AES-10)以及多通道数字音频接口(MADI,一种数字音频复接标准)。
还有一种新的编码方式称作64B/66B 。我们可以认为64B/66B是8B/10B的简化版本,它具有更低的编码开销,但是实现细节相当不同。在现有的技术用户需求下,人们开发出了64B/66B机制。10G以太网协会要求实现基于以太网的10Gb/s通信。他们可以通过使用4条有效载荷速率为2.5Gb/s、线路速率为3.125Gb/s的链路来实现,但此时SERDES已经可以在单个链路上实现10Gb的解决方案。此时新型SERDES的运行速率已经可以略高于10Gb/s了,但还不能达到12.5Gb/s以支持8B/10B的开销。
更多的64B/66B编解码技术的实现细节请查看参考文献1。
2.3 包传输技术
包是一种确切定义的字节集合,包括头部、数据和尾部。
注意,定义中没有包括源地址和目的地址、 CRC校验码、最小长度、或者开放系统互连协议层。包只不过是一个定义了起点和终点的数据结构。局域网的包通常有很多特性,但是其他用途的包则通常要简单得多。
包用于各种场合下的信息传递。例如汽车动力布线、手机以及家庭娱乐中心等等。但是,包和千兆位串行链路有什么关系呢?
通过千兆位串行链路传输的数据多数都是嵌入在某种类型的包中的。Serdes自然需要一种将输入的数据流对齐成字的方法。如果系统需要时钟修正,还必须发送特殊的比特序列或者Comma字符。 Comma字符是指示帧的开始和结束的天然标识。如果需要时钟修正,时钟修正序列常常是比较理想的字符。加入有序集合用于指示包的开始、结束以及包的特殊类型之后,我们就有了一个简单而又强大的传输通道。
idle符号或序列是包的概念的另一要点。如果没有信息需要发送,则发送idle符号。数据的连续传输保证链路能够维持对齐,同时PLL可以保持恢复时钟锁定。下图给出了一些不同标准的包格式。
2.4 参考时钟要求
千兆位级收发器的输入时钟、或是参考时钟的规格定义是非常严格的。其中包含非常严格的频率要求,通常用每百万次容许频率错误的单位PPM来定义。抖动要求也是十分严格的,通常用时间(皮秒)或者时间间隔(UI)定义。
如此严格的规定才使得PLL和时钟提取电路能够正常工作。通常系统的每一个印刷电路板都需要有一个精确石英晶体振荡器供MGT使用。这些晶体振荡器的精确度比大多数用在数字系统中的晶体振荡器要高一个级别,而且价格也要高出一截。很多情况下,一般的时钟发生芯片和PLL因为带有很大的抖动,而不能用于MGT。
2.5 时钟修正技术
千兆位Serdes对传输时钟有非常严格的抖动要求,所以通常不能将恢复时钟作为传输时钟。每一个PCB集合都有唯一的振荡器和唯一的频率。如果两个1GHz的振荡器仅仅有1PPM的频差,同时提供1/20th的参考时钟,则数据流的时钟每秒钟可能会增加或者缺失20,000个周期。因此,在8B/10B编码的系统中,每秒将会额外增加或者损失2万个符号。
大多数的Serdes都有时钟修正功能。时钟修正需要使用唯一的符号或者符号序列,它们在数据流中是不会出现的。因为时钟修正是对齐的后续处理,所以可以比较容易地通过保留一个K字符、或者一组有序的K字符、或者一个时钟修正数据序列来实现。
某些情况需要使用4个符号的时钟修正序列。时钟修正通过检测接收FIFO来完成其工作。如果FIFO接近于满,则查找下一个时钟修正序列而不将数据序列写入FIFO。这种操作称作丢弃。相反地,如果FIFO接近于空,则查找下一个时钟修正序列,同时它会被两次写入FIFO。这种操作通常也称作重复。
时钟修正进行的频数必须足够多,从而可以通过丢弃或者重复来补偿时钟的差异。时钟修正序列和idle序列通常也是一样的。
有些系统并不需要时钟修正。例如,在很多芯片到芯片(chip-to-chip) 的应用中,同一个振荡器为所有收发器提供参考时钟。相同的参考时钟和相同的速率意味着不需要进行时钟修正。同样,如果所有接收电路的时钟都来自恢复时钟,那么时钟修正也是不需要的。如果FIFO的写入速率和读出速率相等,也没有必要进行时钟修正。
如果所有的传输参考时钟都是通过一个外部的PLL锁定在一个公共的参考频率上,那么也不需要时钟修正。对于高精确度的串行数字视频链路来说,这是常用的一种结构。所有的传输时钟都是从一个公共的视频参考中获取的。无法锁定到这个信号往往将导致自由滑动的视频流,相对于其他的锁定信号。在1G或2G速率上实现是比较简单的,但是设计一个能够用于10Gb链路且有足够精度的参考时钟是非常有挑战性的。
下表给出了在不同晶振频率和晶振精度下时钟修正序列之间的最大时钟周期数。

2.6 接收和发送缓冲器
接收和发送缓冲器,即FIFO,是千兆位级收发器的主要数字接口。 FIFO通常是数据写入和读出的地方。发送端通常有一个小型的FIFO,它要求读取和写入的时钟是等时同步(isochronous)的(等时同步是指频率匹配但相位不一定匹配)。
如果tx_write和tx_read选通信号不是工作在精确相同的频率,则通常采用另外的方法。此时,需要使用一个较大的FIFO,同时要求持续不断地检测FIFO的当前状态。如果FIFO被不断地填充,将最终导致溢出。在这种情况下,必须在输入数据流中检测idle符号。如果检测到idle符号,则不把idle符号写入FIFO。
反过来,如果FIFO运行较慢则在输出数据流会出现idle符号,数据被传送给用户。此时写指针保持不动,不断重复idle符号。使用idle符号而不使用字节对齐、 Comma字符、时钟修正序列或者通道绑定序列,这一点是非常重要的。为了保证一定的发送速率,所有这些序列都是必需的。
相对于发送缓冲器而言, MGT内建的接收FIFO通常需要有更深层次的考虑。它的主要目的是为了实现时钟修正和通道绑定。
2.7 通道绑定
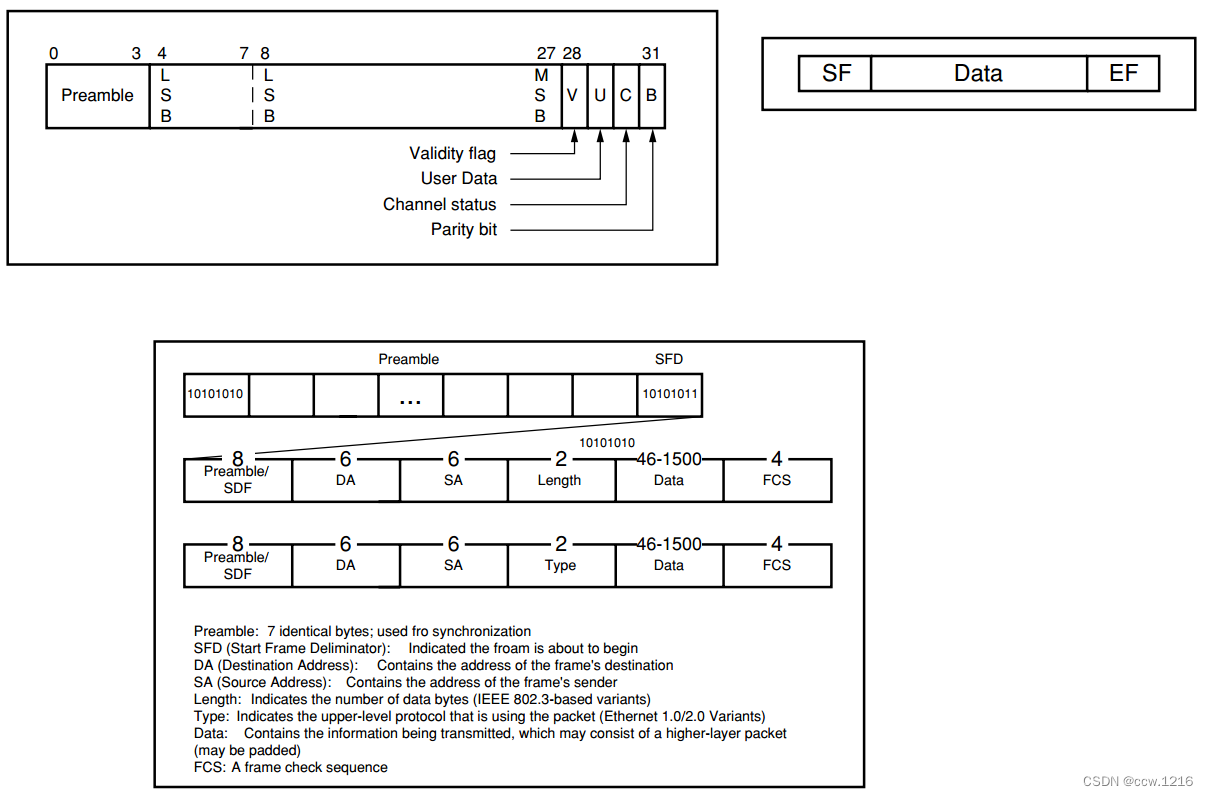
有时候我们需要传送的数据会超过一条串行链路的承载能力。在这种情况下,可以同时使用多条链路来并行传输数据。如果使用这种方式,则输入的数据流必须是对齐的。这个过程通常称作通道绑定。通道绑定可以吸收两个或多个MGT之间的偏差,将数据提交给用户,就像只使用一条链路进行传送一样。通道绑定的过程如下图所示
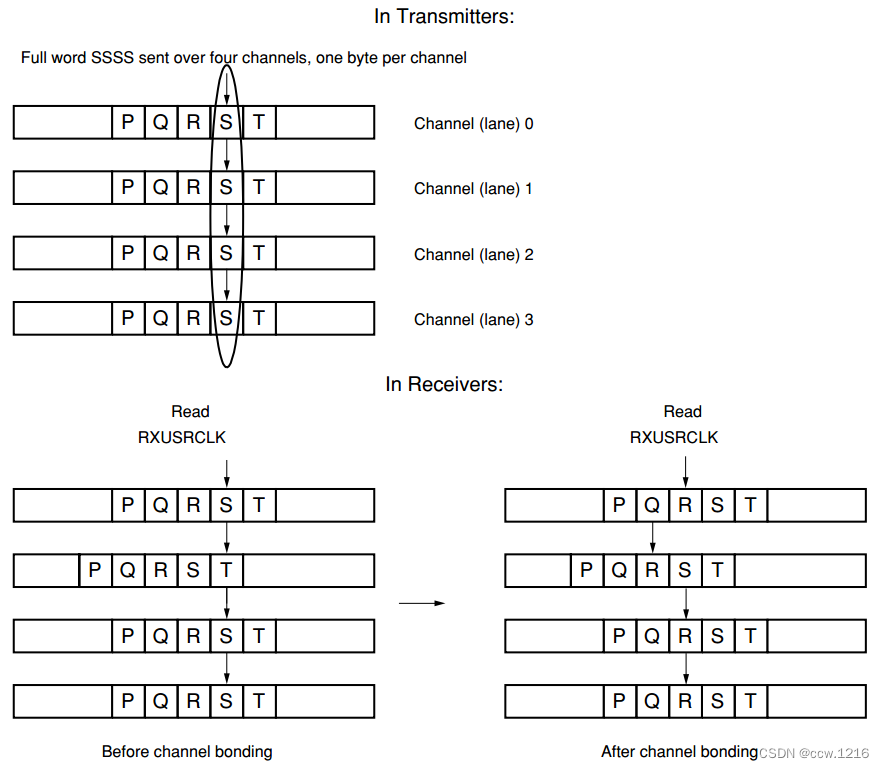
不同MGT间数据偏差的一些主要原因:
1、 传输通道长度的偏差
2、 传输通道的有源中继器
3、 时钟修正引起的偏差
4、 锁定和字节对齐引起的时间偏差
因为通道绑定需要涉及到收发器之间的通信,所以具体的细节因厂家、器件而异。但是它们有一些共同的特性,例如:指定一个通道作为主通道,指定从通道,还可能需要指定前向从通道。三级通道绑定包括一个主通道和前向从通道,所以通常也称为两-跳通道绑定。
通道绑定序列必须是唯一的而且是可扩展的,因为可能会添加或丢弃通道绑定序列,所以下行链路中必须忽略。通常时钟修正序列和通道绑定序列之间会有最小间隔符号数。很多基于8B/10B的标准协议规定时钟修正序列和通道绑定序列之间至少需要间隔四个符号。因此,四个符号或字节是比较常用的间隔距离。
2.8 物理信号
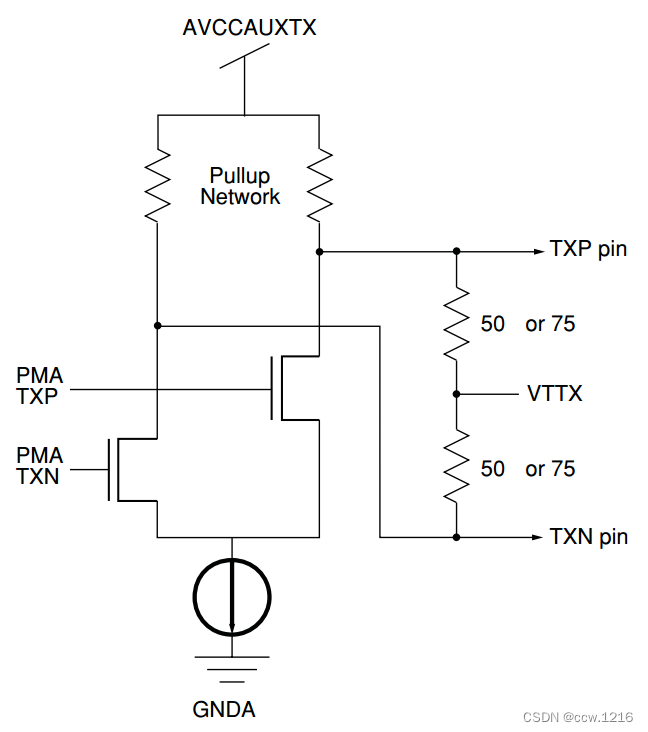
千兆位级Serdes的物理实现普遍采用基于差分的电气接口。常用的差分信号方法有三种:低电压差分信号(LVDS)、低电压伪射级耦合逻辑(LVPECL)和电流模式逻辑(CML)。千兆位链路通常使用CML。CML采用最常用的接口类型,并且通常都会提供AC或DC端接以及可选的输出驱动。部分输入还提供了内建的线路均衡和/或是内部端接。通常端接的阻抗也是可选的。
下图给出了一个CML型的驱动电路。这些高速驱动电路的原理非常简单。两个电阻中的一个始终都有电流通过,并且此电流和通过另一个电阻的电流不同。
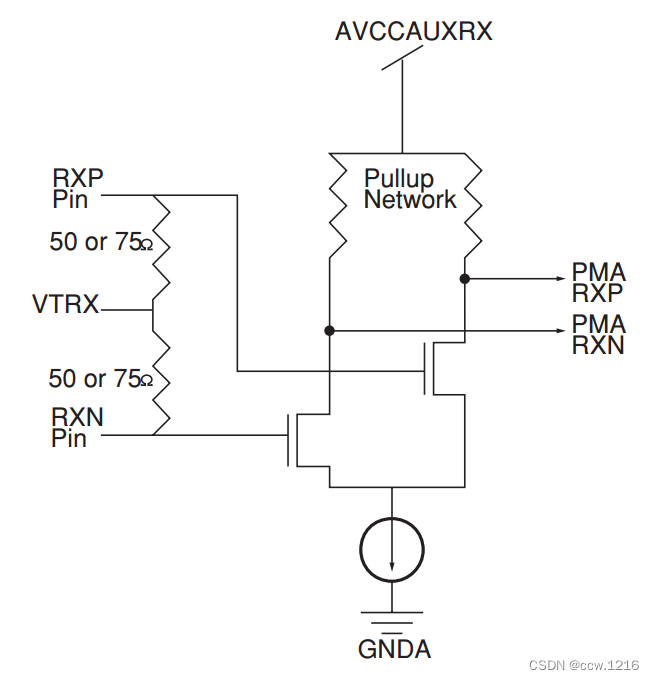
下图给出了一个MGT接收器的示意图。
2.9 预加重
千兆位级驱动器最重要的特性可能就是预加重的能力。预加重是在转变开始前的有意过量驱动。如果没有相关的经验,这看起来会像是一个缺陷;看起来就象是一个不好的设计可能发生的上冲和下冲。为了弄懂这么做的意图,我们需要理解符号间干扰。
如果串行流包含多个比特位时间的相同数值数据,而其后跟着短比特位(1或2)时间的相反数据数值时,会发生符号间干扰。介质(传输通道电容)在短位时间过程中没有足够的充电时间,因此产生了较低的幅度。符号间干扰的示意图如下:
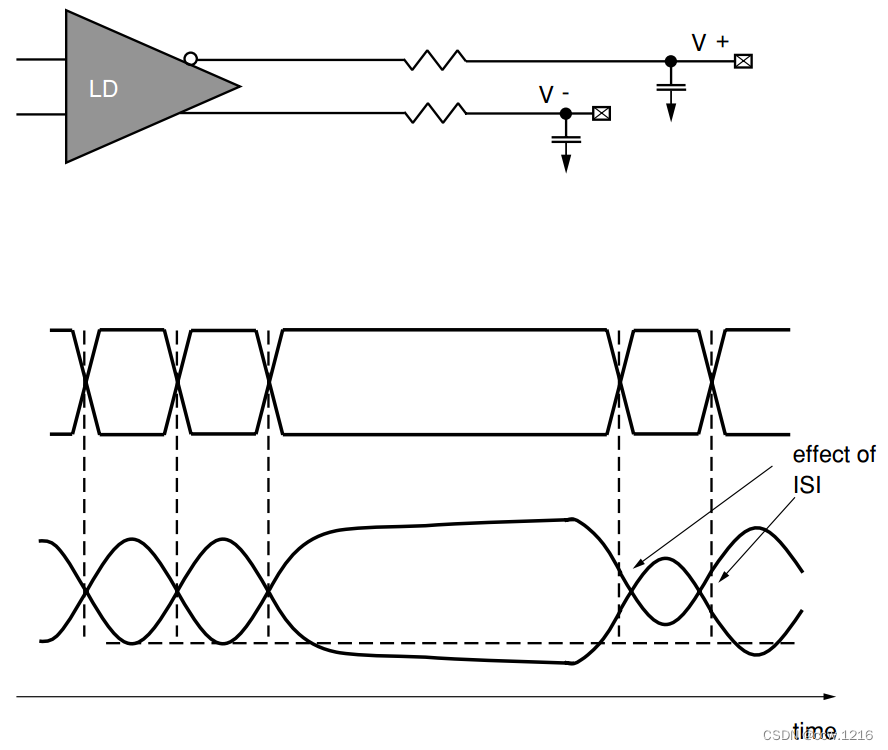
在符号间干扰的情况下,长时间的恒定值将通道中的等效电容完全的充电,在紧接着的相反数据数值位时间内无法反相补偿。所以,相反数据的电压值有可能不会被检测到。这个问题的解决方法是:转变开始时加入过量驱动,而在任意的连续相同数值时间内减少驱动量,这种过程有时也称作去加重。
2.10 差分传输
数字设计工程师和PCB设计师们曾经一度认为布线只不过是简单的互连或连线。实际上,原型建造时通常采用一种叫做蛇行布线的技术。实际中并不是一定要运用传输线和传输线理论。如果线路的传输延时只是信号上升时间中的很小一部分,我们可以不使用传输线理论。
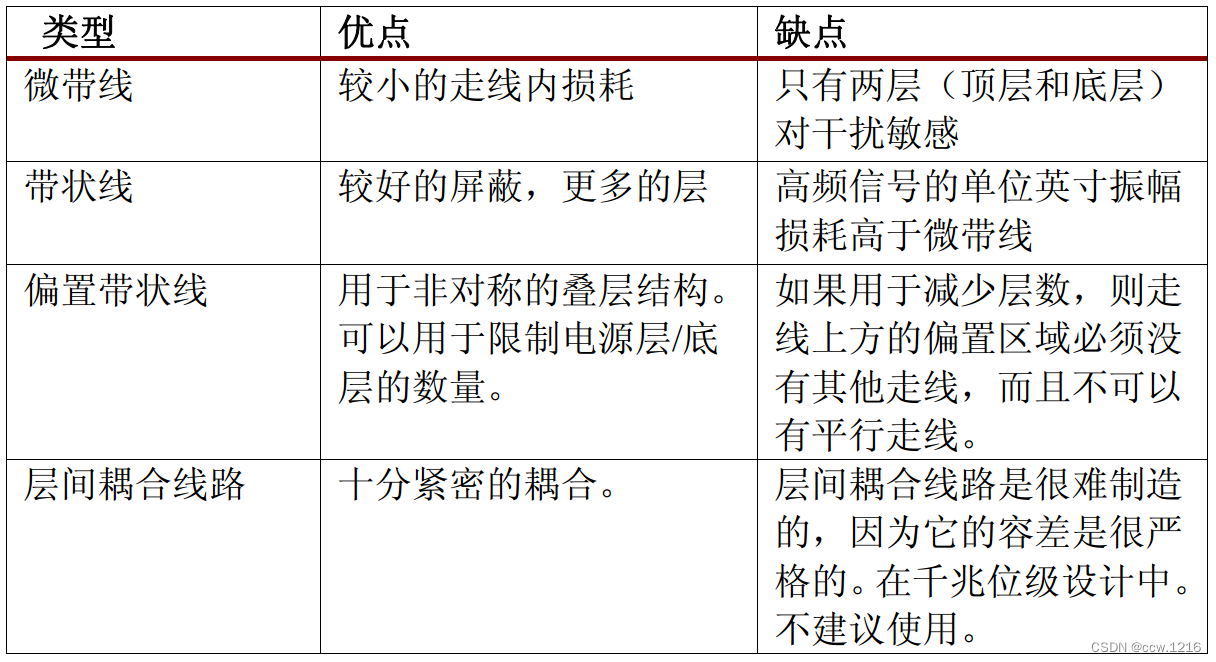
但是随着信号的传输速率的增大,PCB设计过程中就必须使用传输线理论。对于千兆位级操作而言,不仅包括传输线和阻抗控制,还包括差分线路对的阻抗控制。差分线路对阻抗匹配的两条线路是相邻的。两条线路之间的间隔使得两线路相互耦合。如果两线路相隔较远,则称作弱耦合。如果相隔较近,则为强耦合。
如果给定线路的长度以及叠层结构(会带来给定的阻抗),耦合还会影响线路的阻抗。相同几何形状的差分线路对也会有不同的阻抗。阻抗的精确大小因材料而异,但是板制作厂商通常会提供精确的数据。下表给出了受控阻抗差分线路的各种类型。
2.11 线路均衡
均衡主要用于补偿由频率不同而引起的阻抗/衰减差异。均衡器有很多种形式,但总体上可以分为有源和无源两种。
无源均衡器是无源电路,其频率响应可以补偿传输衰减。无源均衡器可以认为是一个滤波器。如果我们的滤波器可以使传输线所使用的各频率通过,而将传输线没有使用的其他频率滤除,那么整体的频率响应就会变得平坦许多。
有源均衡器可以认为是依赖频率的放大器/衰减器。有源均衡器主要有两种:固定形式有源均衡器和自适应有源均衡器。对于任意的输入数据流,固定形式有源均衡器的频率响应都是一样的。
固定形式均衡器的增益/衰减量通常是用户可选择的,或者可编程的。部分均衡器有一个简单的控制参数—n 用于设置高增益或低增益,类似于简单音响系统中的低音设置。还有一些均衡器可以独立设置不同频率的增益/衰减量,这和复杂音响系统中的均衡设置是类似的。
自适应均衡器(也称学习型均衡器)要复杂的多,自适应均衡器需要分析输入信号并检测哪些频率在传输通道中被削弱。测量和调节是以闭环形式实现的。自适应均衡器的频率响应取决于输入的比特流。
自适应均衡器通常和特殊形式的线路编码机制协同工作。自适应均衡器对于可变通道的链路来说是最合适的,可变通道可以是可变的电缆长度,或是显著的位置依赖的背板系统。固定形式均衡器比较适合于不变系统中,例如:芯片到芯片,平衡化的背板系统以及固定长度电缆的系统。均衡器通常包含在SERDES的模拟前端,或者作为系统的一个独立部分。
2.12 光解决方案
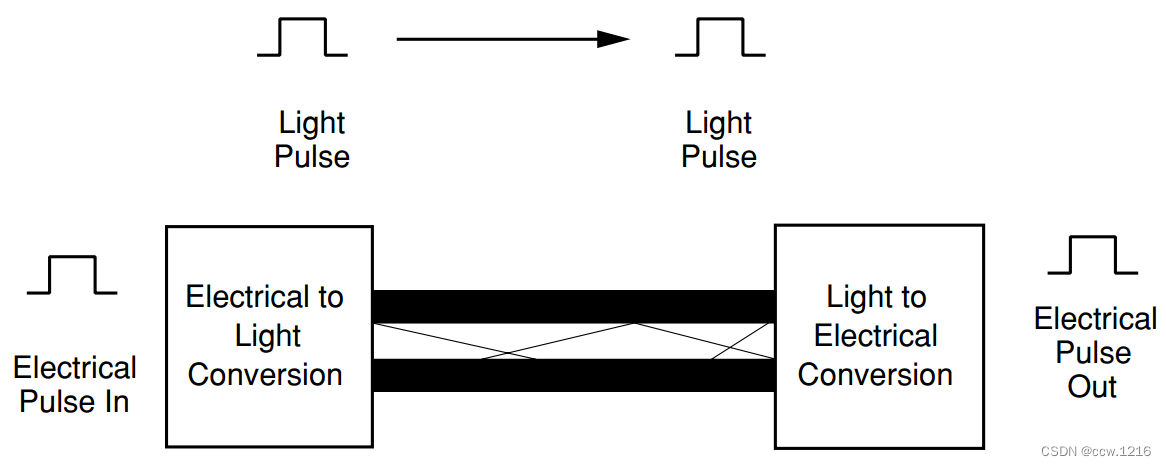
如果系统中电缆要传输的距离很远(远大于相邻底板的距离),那么通常采用光解决方案。使用光纤可以实现多种长距离传输,例如:楼下到楼上,楼与楼之间,街区之间或者城镇之间。
光纤系统使用光信号取代电信号来传输信息。最基本的光纤系统包括发送器或信号源、光纤以及接收器,接收器将光脉冲重新转变为电信号。信号源通常是注入型激光二极管(ILD)或者发光二极管(LED),如下图所示。
光纤中的光脉冲传输是基于全反射定理的。全反射定理:如果入射角大于临界值,则光线不会透射而会全部反射回来。简单的说,光纤可以看作是一个内部全是镜子的弹性管线。光线在管道中不停反射前进,就算管道发生了弯曲,光线也能一直前进到达末端。
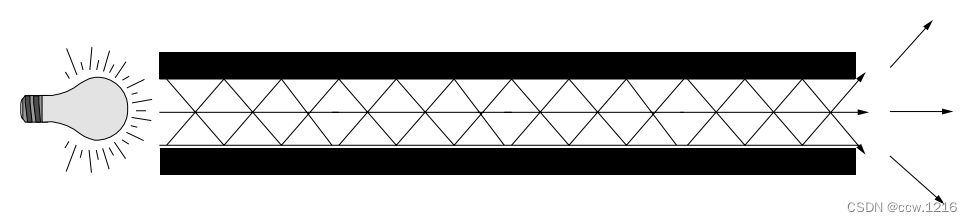
光线有两种类型——单模光纤和多模光纤。单模的价格较高,可以传输的距离也较长。多模光纤的价格较低,只能用于短距离传输。
单模光纤的示意图如下图所示

多模光纤的示意图如下图所示
基本的光连接器如下图所示

2.13 循环冗余校验码(CRC)
设计师还是需要设计一个稳健的系统。首先,他需要检查系统的要求,看是否能够使用常用的方法来解决问题。
一种方法是错误检测数据重传。检查输入数据中是否有错。如果发现错误,则发送信息给发送者要求重传数据。错误检测的首选方法是CRC。因为CRC十分常用,所以许多SERDES内部都有CRC发生器和检测逻辑。通常重传请求是由上层协议定义的。如果协议支持CRC和重传,或者数据要求正是其所能满足的,那么这种方法将会是最好的选择。
如果情况不是这样的话,设计师还可以有其他的选择。设计师可以建造并测试所设计的系统,以观察其能否正常工作。SERDES发布的BER可以用来确定测试需要进行到什么程度,所以设计师还是有一些机动空间的。设计师不可能设计出一个远优于发布数据的系统。除了持续测试直到达到发布的BER,设计师还需要在各种极限情况下进行测试(例如,输入抖动十分靠近容限)。如果给系统设计提供更好的输入流,那么结果会更好。
数据还提供了另一种值得考虑的选择。多数的数据流都是有模式的,和用于BER测试的伪随机比特流相比,数据流更容易预测。这一点可能是好处也可能是坏处,这取决于传输通道和均衡器适配数据流的情况。所以必须进行测试和调整。所以建造一个系统并观察其能否正常工作,这种方法并不是十分牵强的。尽管如此,如果这种方法会出现操作上的问题,那么前向纠错(FEC)可能会有所帮助。
2.14 前向纠错(FEC)
由于设计师知道可能会发生错误,所以可以通过提供冗余数据位来恢复这些错误。常用的方法就是利用一些前向纠错码来对数据流中的错误进行纠正。
前向纠错的定义:添加额外的位,用于帮助恢复错误数据。
考虑一个待传输的数据块,其大小为NxR字节,分为R行,每行N字节。现在给矩阵的每一行附加额外的一个字节,并给矩阵附加额外的一行。这些地方就是额外的位置。
数据块的附加信息就保存在这些额外的位置中。此例中,额外的信息是奇偶位。附加字节的每一位代表此行中各字节对应位的奇偶性。也就是说,P[1][0]是D[1.1][0] D[1.2][0]D[1.3][0] …. D[1.N][0]的奇偶性。而对于额外的行而言,其中的每一位就是对应列中各位的奇偶性。也就是说, P[R+1.0][0]是 D[0.0][0], D[1.0][0] D[2.0][0] ….D[N.0][0]的奇偶性。矩阵的示意图如下图所示。
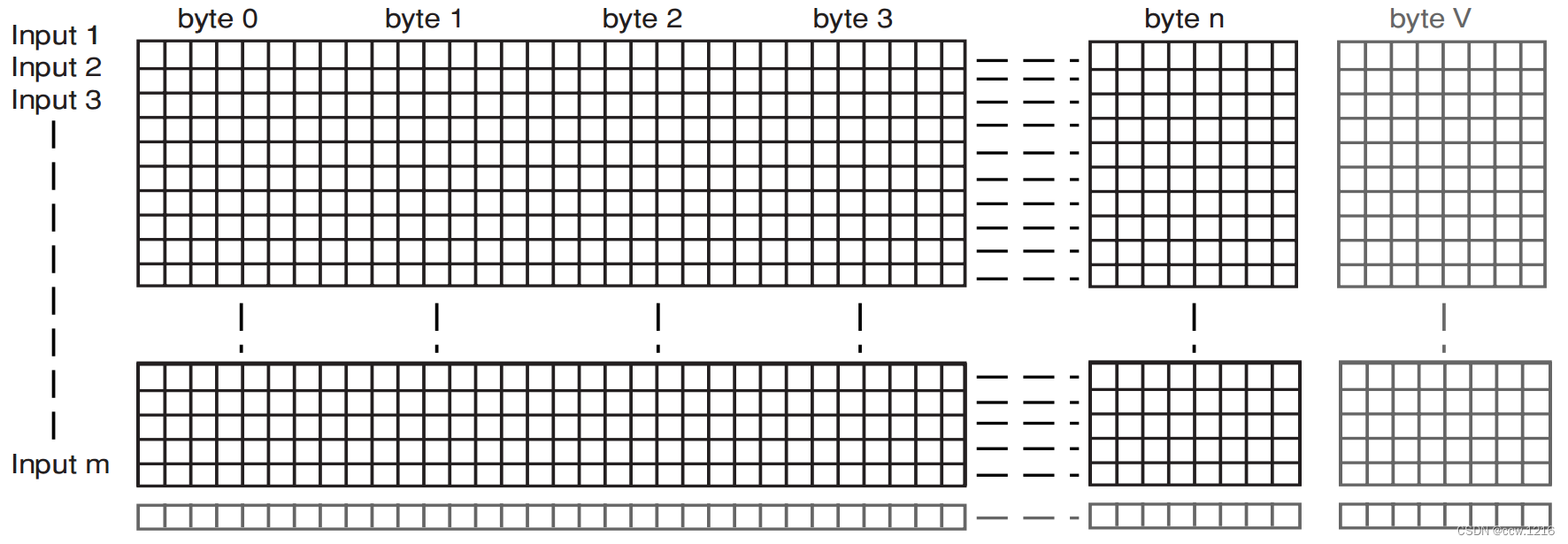
数据和附加位同时通过链路传输。在另一侧,接收器会检查矩阵的奇偶性。如果数据的任一位是错误的,那么它会标记出来,并通过行值和列值来确定位置。只需要简单的取反,即可纠正该位的错误。多位的错误即可能被纠正,也可能会导致混乱而且会阻止其他错误的纠正,这取决于错误发生的位置。
这种方法通常称作简单矩阵奇偶性法,而且也是FEC的最初类型。这也是多数FEC方法基本模块。这个例子是简单易懂的,但是它有局限性。针对恶劣环境和性能不好的传输通道,已经开发出多种FEC 方法,例如Viterbi,Reed-Soloman 和 Turbo 编码。所有这些方法都有强大的纠错能力,但是纠错也是有代价的:
1、运行速度不够快: 与大多数可以在常规结构下发挥作用的方法相比,千兆位级 SERDES的速度较快。
2、编解码器太过庞大: 编码器和解码器的电路逻辑数量可能会是MGT及其剩余部分的十倍。
3、编码开销过大: 编码开销就是那些附加的位。编码开销过大常常可以使一种 FEC方法不可行。

